
pandas備忘録(文字列置換・データ分割編)

pandasを使ったデータ加工を見ていきます。
文字列置換

dmデータフレームgenderの"Male"を”Man”に置き換えます。
dm["gender"].str.replace("Male","Man")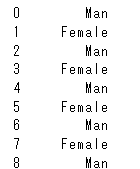

これだとまだ元のデータフレームは置き換わっていません。データフレームの中を書き換えるにはこのようにします。
dm["gender"]=dm["gender"].str.replace("Male","Man")
dm
ちなみにreplaceでは、文字の一部の置換もできます。
dm["gender"].str.replace("Fe","fe")
データフレームの分割

dmデータフレームをgenderがFemaleだけにしてみます。
dm[dm["gender"]=="Female"]
体重が60キロより大きい人を抽出します。
dm[dm["weight"]>60]

Excelのフィルターみたいなものですね。
では、複数条件でフィルタリングしましょう。
dm[(dm["gender"]=="Male")&(dm["weight"]>=50)]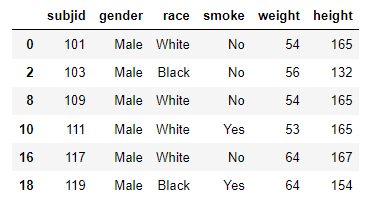
dm[(dm["race"]=="Asian")|(dm["smoke"]=="Yes")]
このようにフィルタリングした場合、indexがおかしくなっています。
例えば、subjid=119のraceをilocで取ろうとするとエラーが出ます。
dm[(dm["race"]=="Asian")|(dm["smoke"]=="Yes")].iloc[18,2]IndexError: index 18 is out of bounds for axis 0 with size 9
9行しかないよ、って言ってますね。
そこでindexを振り直してあげます。
dm[(dm["race"]=="Asian")|(dm["smoke"]=="Yes")].reset_index(drop=True)こうすると新たにindexがふられます。drop=Trueとすると元のindexは削除されます。


では、このフィルター機能を使って、人種(race)ごとに別々のExcelに保存します。
race_list=dm["race"].unique()
for jinsyu in race_list:
dm_race=dm[dm["race"]==jinsyu]
dm_race.to_excel("dm_{}.xlsx".format(jinsyu),index=False)race_listに人種のリストを入れます。
そして、これを順々にフィルタリング、保存としていきます。
こんな感じにファイルができました。

Excelの中身はこんな感じです。(dm_Asian.xlsx)

