
pandas備忘録(データ表示・要約統計量)

pandasでデータを表示・置換する方法を見ていきましょう。要約統計量も出します。
列の選択
特定の1列を抽出します。
dm["subjid"]こんな感じでsubjidのみが表示されます。
0 101
1 102
2 103
3 104
. ……

2列以上表示するにはdm["subjid","gender"]としたいところですが、こうするとエラーがでます。2列以上のときは、listとして渡してあげなければなりません。
dm[["subjid","gender"]]
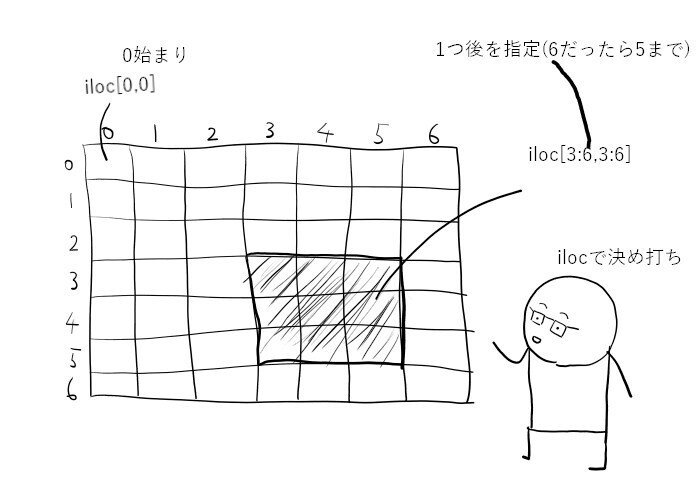
セル指定、範囲指定(iloc)
セルを指定するにはilocを使います。
左上端は[0,0]です。openpyxlは1始まりなので間違えやすいです。
dm.iloc[5,2]Whiteが抽出されます。

範囲指定にもilocを使います。
1行目から3行目を指定するには[0:3]とします。0から3の前(つまり2)までです。
#1-3行目
dm.iloc[0:3]
さらに1列目から3列目にしぼります。
#1-3行目、1列目-3列目
dm.iloc[0:3,0:3]
行や列を飛び飛びで指定してみます。
この場合は、行・列をlistで指定します。
#範囲指定4,7行目、1,5列目
dm.iloc[[3,6],[0,4]]
行、列の片方を省略すると、省略された方はすべて出力されます。
#範囲指定1-3行目、列は全部
dm.iloc[0:3,:]
#範囲指定1-3列目、行は全部
dm.iloc[:,0:3]
要約統計量など
pandasでは要約統計量を出すこともできます。
print("合計:",dm["weight"].sum())
print("平均:",dm["weight"].mean())
print("カウント:",dm["weight"].count())
print("標準偏差:",dm["weight"].std())
print("最小値:",dm["weight"].min())
print("最大値:",dm["weight"].max())
print("中央値:",dm["weight"].median())合計: 997
平均: 49.85
カウント: 20
標準偏差: 14.32434438657711
最小値: 23
最大値: 75
中央値: 53.5
describe()を使えばこれらがすべて出せます。
dm["weight"].describe()

カテゴリーデータにはどんな種類があるのか知りたいときがありますよね。一意の要素を取り出すにはunique()を使います。
print("一意な要素:",dm["race"].unique())一意な要素: ['White' 'Asian' 'Black' 'Hispanic']
この要素ごとにカウントしてみます。
dm.groupby("race").size()
最頻値はmode()で出せます。
dm[["race","gender", "smoke"]].mode()raceは”White”が一番多い、genderは”Female”と"Male"が同数、smokeは"No"が一番多い、と出ました。

