
pandas備忘録(縦結合、横結合)

SASのsetやmergeに該当するファイルの縦結合や横結合をしてみます。
別々のExcelファイルの縦結合
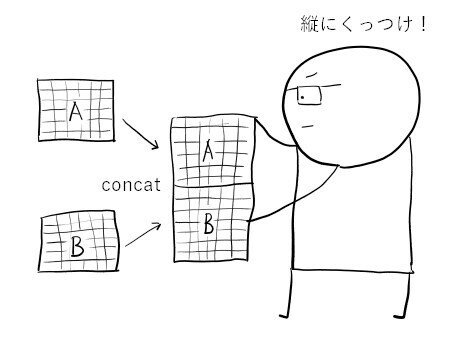
縦結合はconcatを使います。まずは、複数のExcelファイルの縦結合です。
import pandas as pd
dm_Asian=pd.read_excel("dm_Asian.xlsx",sheet_name="Sheet1")
dm_Black=pd.read_excel("dm_Black.xlsx",sheet_name="Sheet1")
dm_conc=pd.concat([dm_Asian,dm_Black])
dm_concdm_Asianとdm_Blackのデータが縦に結合したdm_concができます。

for文を使って複数のファイルを一気にまとめましょう。

まずはフォルダ内の特定のExcelファイルのファイル名をlist化します。
from glob import glob
files=glob("dm_*.xlsx")
filesdm_*.xlsxにヒットするファイルが抽出できました。
['dm_Asian.xlsx', 'dm_Black.xlsx', 'dm_Hispanic.xlsx', 'dm_White.xlsx']
これを使ってファイルを縦結合します。
from glob import glob
import pandas as pd
#必要なExcelファイルをlist化
files=glob("dm_*.xlsx")
#空のデータフレームを作る
dm_conc=pd.DataFrame()
#dm_concに足していく
for file in files:
dm_temp=pd.read_excel(file,sheet_name="Sheet1")
dm_conc=pd.concat([dm_conc,dm_temp])
#subjidでsortしてからExcel変換
dm_conc.sort_values("subjid").to_excel("dm_結合.xlsx",index=False)
pandasはopenpyxlと違い、書式が継承されません。そのためpandasでは後で体裁を調整することになります。
同一Excel内の複数シートの縦結合

これも色々と組み合わせるとできます。まずはシート名の取得です。
openpyxlでもws_list=wb.sheetnamesのような感じで取れますが、ここではpandasでやってみます。
import pandas as pd
file=pd.ExcelFile("Adverse Event.xlsx")
sheet_names=file.sheet_names
sheet_namesopenpyxlと同じようなやり方ですね。
['AE', 'AE2', 'Sheet3']というリストができます。このリストから"AE"が頭についた要素だけ取り出します。
import pandas as pd
file=pd.ExcelFile("Adverse Event.xlsx")
sheet_names=file.sheet_names
ae_sheet=[s for s in sheet_names if s.startswith("AE")]
ae_sheetここではstartswith関数を内包表記の中で使ってみました。内包表記はまた今度詳しくやります。
['AE', 'AE2']
ここまでできれば、複数のシートを縦結合する方法はファイルごとの縦結合とほぼ同じです。
import pandas as pd
filename="Adverse Event.xlsx"
file=pd.ExcelFile(filename)
sheet_names=file.sheet_names
ae_sheet=[s for s in sheet_names if s.startswith("AE")]
#空のデータフレームを作る
ae_conc=pd.DataFrame()
for i in ae_sheet:
ae_temp=pd.read_excel(filename,sheet_name=i)
ae_conc=pd.concat([ae_conc,ae_temp],ignore_index=True)
ae_concconcatにignore_index=Trueを入れました。こうすることで、indexを振り直してくれます。

横結合

SASと同じでmergeという関数です。どちらかというとsqlに近いですね。
dmというデータフレームとae_concというデータフレームをsubjidをキーとして横に結合します。
dm_ae=pd.merge(dm,ae_conc,on="subjid")
dm_aeデータフレームの変数の並びを変えて、ついでにsubjidで並び替えをします。
dm_ae.iloc[:,[0,6,7,1,2,3,4,5]].sort_values("subjid")
結合とは少し離れますが、変数名のrenameをしてみます。
aeconc2=ae_conc.rename(columns={"subjid":"被験者番号"})
aeconc2
では、このae_conc2とdmを横にくっつけてみます。キー変数が異なる場合の結合方法です。
#変数名違いのmerge
dm_ae2=pd.merge(dm,ae_conc2,left_on="subjid",right_on="被験者番号")
dm_ae2
被験者番号の列はもう不要なので削除します。列の削除はこちらで紹介しています。
dm_ae3=dm_ae2.drop("被験者番号", axis=1) dm_ae3外部結合、左側結合、右側結合
通常の結合では、両方のdataframeでキー変数が一致するレコードだけが出力されます。inner結合です。
外部結合するにはhow=”outer”とします。howは省略するとinnerです。
dm_ae2=pd.merge(dm,ae_conc,on="subjid",how="outer",indicator=True)
dm_ae2ついでにindicatorオプションもつけました。これをTrueにすると、どっちにあるレコードなのかがわかります。ファイル同士の差分比較をするときに便利ですね。

左側結合はhow="left"です。
dm_ae3=pd.merge(dm,ae_conc,on="subjid",how="left",indicator=True)
dm_ae3
もちろん右側結合はhow="right"
dm_ae4=pd.merge(dm,ae_conc,on="subjid",how="right",indicator=True)
dm_ae4
この記事が気に入ったらサポートをしてみませんか?