
機械学習の正則化について

正則化って聞いたことあるけどなんだろって方に
正則化は簡単に言うとモデルの過学習を抑える為に行うもの。
過学習とはモデルが学習データを分類するのに適しすぎてしまいテストデータを分類する際にうまく分類できないというものである。
学習の重みについて
機械学習のモデルは
1.重みをランダムに作成
2.重みを元に学習データを入力
3.出力データと真値の誤差の分だけ重みを修正する
この作業を繰り返して重みを更新し続ける事で分類したいデータをうまく分類できるようにします。しかしこの学習データに大きな外れ値が紛れていた場合、そのデータを分類するために重りに偏りが出てしまい他のデータを分類できなくなってしまいます。
これを避けるために重みの変化時に極端な重みに対してペナルティを課して重みを小さくすればいいという考え方が正則化です。
L2正則化について
正則化の中で最も一般的とされるのはL2正則化です。下の式になります。
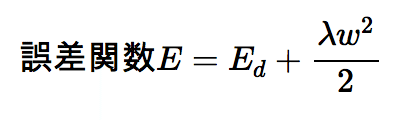
wは重み、Eは誤差関数である。そしてλが我々が調整できるパラメータで正則化パラメータという。
式を見ると誤差関数に対して
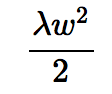
の罰則が加わっている。
λを制御することで重みを小さく保ちながら学習モデルにどの程度フィットさせるかを制御できる事がわかるだろう。
正則化を強めるにはλを大きくすれば良い。
ちなみにロジスティック回帰のモデルに与えるハイパパラメータCはλの逆数である。
LogisticRegression(C=10,random_state=1)
上のコードのC=10の部分。Cの値を変えることで正則化の強さを変えることができる。
この記事が気に入ったらサポートをしてみませんか?