
【音声APIを使い倒せ】音声ファイルを自動で文字起こし&文字を自然に自動読み上げ

こんにちは。
音楽家育成塾のこうたろうです。
本日の記事では音声ファイルを自動で文字起こしするプログラムについてお届け。
すでに既存のアプリでも文字起こしの無料ツールはたくさんでていますが、プログラムでできれば、自分だけの制作環境が出来上がりますし、他の技術との統合もできるので、やはり自作がベストであります。
例えば、文字起こししてsrtファイルにするのもいいですし、動画に自動で字幕を生成するのもいいですし、文字起こししたものをそのままWordPressのAPIを使って投稿すれば、ポッドキャストの収録と記事の投稿が同時にできちゃうなんてことも可能になってきます。
今回はMicrosoft Azureを使ってみます。
他にもIBMのAPIや、GoogleのAPIなどが有名ですね。
Microsoft Azure音声サービス
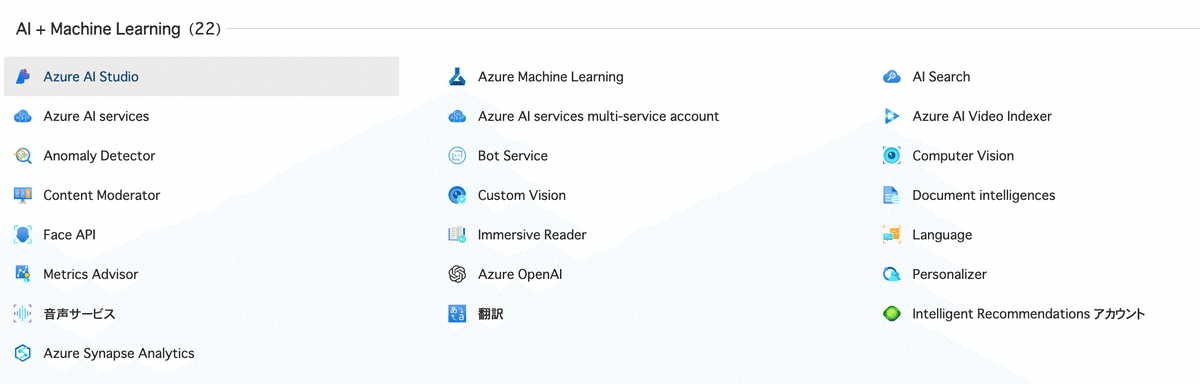
azureのすべてのサービスから音声サービスを選択し、作成します。
ちなみに翻訳APIも作成しておくと便利です。
ちなみに筆者は翻訳APIはDEEPLが自然で気に入っていておすすめです。
無料枠で使える範囲をしっかりと管理しながら使用するようにしてください。
例えばテキストから音声を生成する際のコストとしては、次のような計算が成り立ちますので、参考になれば幸いです。
Azure Speech Serviceの価格は、音声合成(Text-to-Speech)のリクエスト数と合成された音声の長さに基づいて計算されます。
具体的には、Azureの音声合成は文字数や時間単位で課金されますが、最も一般的なのは1百万文字あたりの料金です。
価格の概算方法
標準音声: 1百万文字あたり約 $4 USD(日本円ではその日の為替レートによります)。
ニューラル音声(自然な音声): 1百万文字あたり約 $16 USD。
具体例: 「こんにちは」を音声にした場合の価格
「こんにちは」は5文字です。この文字数を基に、価格を計算します。
ニューラル音声(自然な音声)の場合:
1百万文字あたり $16 USD
1文字あたりのコストは: $16 / 1,000,000 = $0.000016
5文字の場合: 5 × $0.000016 = $0.00008 USD
標準音声の場合:
1百万文字あたり $4 USD
1文字あたりのコストは: $4 / 1,000,000 = $0.000004
5文字の場合: 5 × $0.000004 = $0.00002 USD
結論
ニューラル音声で「こんにちは」を合成する場合、コストは**$0.00008 USD**(約0.01円未満)。
標準音声の場合、コストは**$0.00002 USD**(約0.001円未満)。
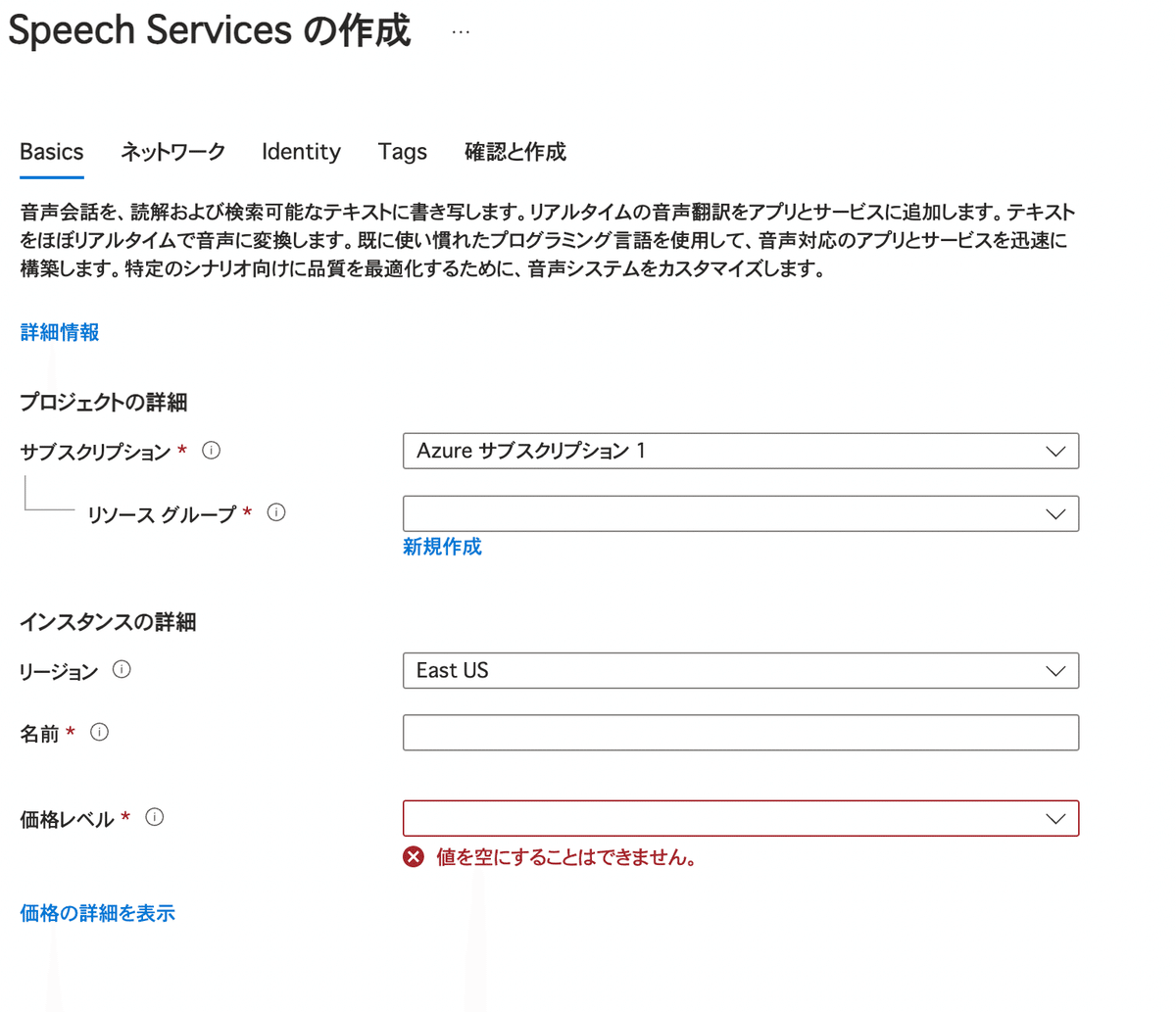
音声サービスの作成をクリックすると、このような作成画面に移行します。
サブスクリプションはお使いのものを、リソースグループですが、管理しやすいようにしてください。
カテゴリーや、フォルダのような存在でるとり理解して問題ありません。
リージョンは基本的にはひとつでOKなので、もし他のアプリ等で使っているものであればそれを指定し、はじめて設定するのであれば、東日本か西日本のどちらかでOK。
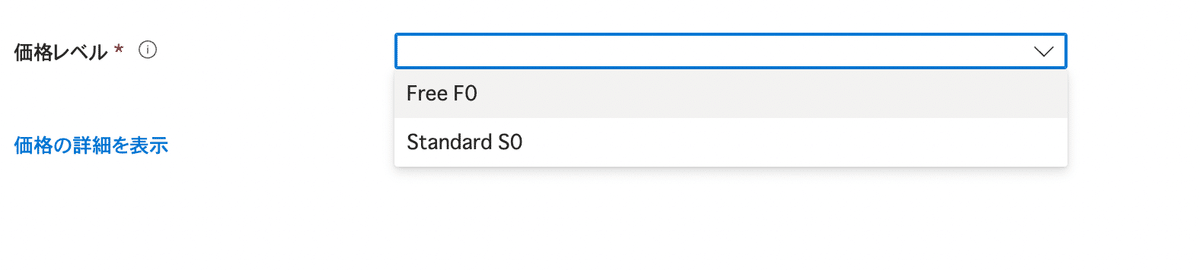
価格レベルはFreeが従量課金制。
完全無料じゃないので注意です。
従量課金制や、無料枠などの管理がよくわからないという方は、既存のツールやアプリを使うといいと思います。
アプリの名前は管理しやすいものにしてください。
必要なのはAPIキーとエンドポイント
セキュリティーの関係で画像のシェアができませんが、音声サービスを作成すると、概要の右側に
エンドポイント
キーの管理
という二つがあります。
キーは二種類発行されますが、どちらを使用してもOK。
ただし、どちらを使用しても従量課金制で契約している場合それぞれに発生しますので、注意です。
テキストから自然な音声の生成
PythonでAzure Speech Serviceを利用するために、azure-cognitiveservices-speechライブラリをインストールします。
pip install azure-cognitiveservices-speech
Python SDKをインストールする
pip install azure-cognitiveservices-speech
音声合成の設定(Pythonでの例)
以下は、入力テキストを日本語の自然な音声で合成し、**音声ファイル(.wav 形式)**として保存するコードです。
ニューラル音声を使用し、日本語テキストを音声に変換します。
import azure.cognitiveservices.speech as speechsdk
# Azureのキーとリージョン
subscription_key = "YOUR_SUBSCRIPTION_KEY"
region = "YOUR_REGION"
# 音声合成の設定
speech_config = speechsdk.SpeechConfig(subscription=subscription_key, region=region)
# 日本語音声の設定(自然なニューラル音声を使用)
speech_config.speech_synthesis_voice_name = "ja-JP-NanamiNeural" # 例: Nanamiさんのニューラル音声
# 出力する音声ファイルのパス
output_filename = "output.wav"
# 音声ファイルとして保存する設定
audio_config = speechsdk.AudioConfig(filename=output_filename)
# SpeechSynthesizerの作成
speech_synthesizer = speechsdk.SpeechSynthesizer(speech_config=speech_config, audio_config=audio_config)
# 変換したい日本語のテキスト
text = "こんにちは、今日はどんな一日でしたか?"
# テキストを音声ファイルに変換して保存
result = speech_synthesizer.speak_text_async(text).get()
# 成功か確認
if result.reason == speechsdk.ResultReason.SynthesizingAudioCompleted:
print(f"Speech synthesized for text and saved to [{output_filename}]")
elif result.reason == speechsdk.ResultReason.Canceled:
cancellation_details = result.cancellation_details
print(f"Speech synthesis canceled: {cancellation_details.reason}")
if cancellation_details.reason == speechsdk.CancellationReason.Error:
print(f"Error details: {cancellation_details.error_details}")
使用可能な日本語音声
Azure Speech Serviceでは、標準音声とニューラル音声の両方が提供されています。ニューラル音声は、より自然な発音や抑揚を実現しており、公式ドキュメントで確認できる複数の日本語音声が利用可能です。
ja-JP-AyumiNeural: 女性の自然な日本語音声
ja-JP-DaichiNeural: 男性の自然な日本語音声
ja-JP-NanamiNeural: 別の女性の自然な日本語音声
これらの音声を使って、日本語テキストを自然に読み上げることができます。
重要なポイント
音声ファイルの保存: audio_config = speechsdk.AudioConfig(filename=output_filename) で音声ファイルの保存先を指定しています。ここでは、output.wavという名前でファイルが保存されます。
音声の種類: speech_config.speech_synthesis_voice_name で日本語のニューラル音声を指定しています。例えば、"ja-JP-NanamiNeural" や "ja-JP-AyumiNeural" などの音声モデルを選べます。
音声フォーマット: デフォルトでは .wav 形式で保存されますが、他のフォーマット(例えば MP3)もサポートされています。
また、プログラムコードの中のregion部分は、エンドポイントとは違うので注意してください。
実用的な活用アイデア
日本語ニュースの読み上げ: テキストベースのニュース記事を音声に変換し、ポッドキャストやラジオ配信などに利用。
音声ナビゲーション: カーナビやスマートアシスタントで、自然な日本語音声で案内を提供。
教育用途: 言語学習アプリでの発音サンプルの提供や、テキスト教材の音声化。
Azure Speech Serviceは、日本語を含む様々な言語での自然な音声合成を提供しているため、あなたのアプリケーションやサービスに簡単に取り入れることができます。
音声ファイルからテキストを生成
pip install pyodbc
pip install azure-cognitiveservices-speech
conda環境で実行している場合には、condaでpyodbcをインストールしてから再試行してみてください。
conda install pyodbc
もしエラーが続く場合は、全体をインストールしてもいいかもしれません。
pip install azure
以下は、Pythonを使って音声ファイルをテキストに変換する方法です。
pip install azure-cognitiveservices-speech
import azure.cognitiveservices.speech as speechsdk
# Azureのキーとリージョンを設定
subscription_key = "YOUR_SUBSCRIPTION_KEY"
region = "YOUR_REGION"
# 音声認識の設定
speech_config = speechsdk.SpeechConfig(subscription=subscription_key, region=region)
# 音声ファイルのパスを指定
audio_filename = "/Users/kotaro/Documents/audiofile.wav"
audio_config = speechsdk.AudioConfig(filename=audio_filename)
# Speech Recognizer(音声認識器)を作成
speech_recognizer = speechsdk.SpeechRecognizer(speech_config=speech_config, audio_config=audio_config)
# 音声を認識してテキストに変換
def recognize_from_audio():
print("Recognizing speech from the audio file...")
# 音声ファイルから1つの文を認識する
result = speech_recognizer.recognize_once()
# 認識結果の処理
if result.reason == speechsdk.ResultReason.RecognizedSpeech:
print("Recognized: {}".format(result.text))
elif result.reason == speechsdk.ResultReason.NoMatch:
print("No speech could be recognized.")
elif result.reason == speechsdk.ResultReason.Canceled:
cancellation_details = result.cancellation_details
print("Speech Recognition canceled: {}".format(cancellation_details.reason))
if cancellation_details.reason == speechsdk.CancellationReason.Error:
print("Error details: {}".format(cancellation_details.error_details))
# 関数を呼び出して音声ファイルをテキストに変換
recognize_from_audio()
サポートされるファイル形式
Azure Speech-to-Textは、以下のファイル形式をサポートしています。
WAV(PCM符号化)
MP3
OGG
音声ファイルが他の形式の場合、変換が必要です。
ローマ字から自然な日本語へ
Azure Speech-to-Textで音声をテキストに変換する際、ローマ字ではなく自然な日本語のテキストを生成することができます。
通常、Azure Speech-to-Textは音声認識を行う際に、言語設定が適切に指定されていれば、その言語(日本語など)の文字でテキストを出力します。
日本語での音声認識設定
音声ファイルを日本語で認識させるためには、以下のように日本語の言語コードを設定する必要があります。
import azure.cognitiveservices.speech as speechsdk
# Azureのキーとリージョンを設定
subscription_key = "YOUR_SUBSCRIPTION_KEY"
region = "YOUR_REGION"
# 日本語の音声認識設定(ja-JP)
speech_config = speechsdk.SpeechConfig(subscription=subscription_key, region=region)
speech_config.speech_recognition_language = "ja-JP" # 日本語の言語コード
# 音声ファイルのパスを指定
audio_filename = "/path/to/your/audiofile.wav"
audio_config = speechsdk.AudioConfig(filename=audio_filename)
# Speech Recognizer(音声認識器)を作成
speech_recognizer = speechsdk.SpeechRecognizer(speech_config=speech_config, audio_config=audio_config)
# 音声を認識してテキストに変換
def recognize_from_audio():
print("Recognizing speech from the audio file...")
# 音声ファイルから1つの文を認識する
result = speech_recognizer.recognize_once()
# 認識結果の処理
if result.reason == speechsdk.ResultReason.RecognizedSpeech:
print("Recognized: {}".format(result.text)) # 結果が自然な日本語で出力される
elif result.reason == speechsdk.ResultReason.NoMatch:
print("No speech could be recognized.")
elif result.reason == speechsdk.ResultReason.Canceled:
cancellation_details = result.cancellation_details
print("Speech Recognition canceled: {}".format(cancellation_details.reason))
if cancellation_details.reason == speechsdk.CancellationReason.Error:
print("Error details: {}".format(cancellation_details.error_details))
# 関数を呼び出して音声ファイルをテキストに変換
recognize_from_audio()
ポイント:
日本語の言語コード: 日本語を指定するために、speech_config.speech_recognition_language = "ja-JP" を設定します。これにより、Azure Speech-to-Textは日本語の音声を認識し、日本語のテキストとして出力します。
音声ファイルの形式: WAV、MP3、OGGなど、Azureがサポートする音声形式を使用してください。
これで、日本語音声からローマ字ではなく自然な日本語テキストが生成されるはずです。
WordPressに投稿した日記を音声に自動変換
WordPressの記事のIDを指定して、その内容を自然な音声ファイルに変換するには、次のステップを踏む必要があります。
手順:
WordPress REST APIを使って記事の内容を取得: WordPressにはREST APIが提供されており、記事のIDを使って特定の記事の内容を取得できます。
Azure Speech Serviceを使ってテキストを音声に変換: 取得した記事のテキストをAzureのText-to-Speech(TTS)機能を使って音声ファイルに変換します。
以下が、WordPressの特定の記事IDを指定して、その記事を音声ファイルに変換するPythonコードの例です。
保存場所を指定して音声ファイルを作成
必要なライブラリをインストール
pip install requests azure-cognitiveservices-speech
import requests
import azure.cognitiveservices.speech as speechsdk
import os
# Azure Speech Service の設定
subscription_key = "YOUR_AZURE_SUBSCRIPTION_KEY"
region = "YOUR_AZURE_REGION"
# WordPress REST APIのURLと記事ID
wordpress_url = "https://yourwordpresssite.com/wp-json/wp/v2/posts/"
post_id = 123 # 取得したいWordPress記事のID
# WordPress APIを使って記事内容を取得する関数
def get_post_content(post_id):
try:
response = requests.get(wordpress_url + str(post_id))
response.raise_for_status()
post_data = response.json()
return post_data['content']['rendered'] # 記事の本文を取得
except requests.exceptions.RequestException as e:
print(f"Error fetching post: {e}")
return None
# Azure Speech Serviceでテキストを音声ファイルに変換する関数
def text_to_speech(text, output_filename):
# 音声合成の設定
speech_config = speechsdk.SpeechConfig(subscription=subscription_key, region=region)
speech_config.speech_synthesis_voice_name = "ja-JP-NanamiNeural" # 日本語の自然な音声を設定
audio_config = speechsdk.AudioConfig(filename=output_filename)
# SpeechSynthesizer の作成
synthesizer = speechsdk.SpeechSynthesizer(speech_config=speech_config, audio_config=audio_config)
# テキストを音声に変換
result = synthesizer.speak_text_async(text).get()
# 成功か確認
if result.reason == speechsdk.ResultReason.SynthesizingAudioCompleted:
print(f"Speech synthesized and saved to {output_filename}")
elif result.reason == speechsdk.ResultReason.Canceled:
cancellation_details = result.cancellation_details
print(f"Speech synthesis canceled: {cancellation_details.reason}")
if cancellation_details.reason == speechsdk.CancellationReason.Error:
print(f"Error details: {cancellation_details.error_details}")
# 特定のディレクトリに音声ファイルを保存するためのパスを指定
output_directory = "/Users/kotaro/Documents/"
output_filename = os.path.join(output_directory, "wordpress_post_audio.wav")
# WordPressの記事を取得して音声ファイルに変換
post_content = get_post_content(post_id)
if post_content:
print(f"Post content fetched: {post_content[:100]}...") # 記事の最初の100文字を表示
text_to_speech(post_content, output_filename)
コードの説明:
WordPress記事の取得:
get_post_content 関数は、WordPress REST APIを使って特定の記事の本文を取得します。記事のIDは変数post_idで指定します。
WordPressのAPI URLは https://yourwordpresssite.com/wp-json/wp/v2/posts/ に記事IDを付けてリクエストします。
Azure Speechで音声ファイルを生成:
text_to_speech 関数は、取得した記事のテキストをAzureのText-to-Speech機能を使って音声に変換し、WAVファイルとして保存します。
speech_config.speech_synthesis_voice_name = "ja-JP-NanamiNeural" で日本語の自然な音声モデルを指定しています。必要に応じて他の音声モデルも利用できます。
ファイル名:
音声ファイルは "wordpress_post_audio.wav" という名前で保存されます。必要に応じてファイル名を変更してください。
ただしこの方法だとHTMLをそのまま取得してしまうので、読み上げが異常なことになってしまいます。
HTML情報を除去して純粋な本文だけを抽出する場合は別のライブラリを併用してください。
BeautifulSoupで本文だけを抽出
pip install beautifulsoup4
HTMLタグを除去してテキストのみを取得するコード
以下のように、BeautifulSoupを使ってHTMLタグを除去し、テキストだけを読み上げるように修正します。
import requests
from bs4 import BeautifulSoup
import azure.cognitiveservices.speech as speechsdk
import os
# Azure Speech Service の設定
subscription_key = "YOUR_AZURE_SUBSCRIPTION_KEY"
region = "YOUR_AZURE_REGION"
# WordPress REST APIのURLと記事ID
wordpress_url = "https://yourwordpresssite.com/wp-json/wp/v2/posts/"
post_id = 123 # 取得したいWordPress記事のID
# WordPress APIを使って記事内容を取得する関数
def get_post_content(post_id):
try:
response = requests.get(wordpress_url + str(post_id))
response.raise_for_status()
post_data = response.json()
return post_data['content']['rendered'] # 記事の本文を取得
except requests.exceptions.RequestException as e:
print(f"Error fetching post: {e}")
return None
# HTMLタグを除去する関数
def clean_html(html_content):
soup = BeautifulSoup(html_content, "html.parser")
return soup.get_text()
# Azure Speech Serviceでテキストを音声ファイルに変換する関数
def text_to_speech(text, output_filename):
# 音声合成の設定
speech_config = speechsdk.SpeechConfig(subscription=subscription_key, region=region)
speech_config.speech_synthesis_voice_name = "ja-JP-NanamiNeural" # 日本語の自然な音声を設定
audio_config = speechsdk.AudioConfig(filename=output_filename)
# SpeechSynthesizer の作成
synthesizer = speechsdk.SpeechSynthesizer(speech_config=speech_config, audio_config=audio_config)
# テキストを音声に変換
result = synthesizer.speak_text_async(text).get()
# 成功か確認
if result.reason == speechsdk.ResultReason.SynthesizingAudioCompleted:
print(f"Speech synthesized and saved to {output_filename}")
elif result.reason == speechsdk.ResultReason.Canceled:
cancellation_details = result.cancellation_details
print(f"Speech synthesis canceled: {cancellation_details.reason}")
if cancellation_details.reason == speechsdk.CancellationReason.Error:
print(f"Error details: {cancellation_details.error_details}")
# 特定のディレクトリに音声ファイルを保存するためのパスを指定
output_directory = "/Users/kotaro/Documents/"
output_filename = os.path.join(output_directory, "wordpress_post_audio.wav")
# WordPressの記事を取得してHTMLタグを除去してから音声ファイルに変換
post_content = get_post_content(post_id)
if post_content:
clean_content = clean_html(post_content) # HTMLタグを除去
print(f"Cleaned post content fetched: {clean_content[:100]}...") # 記事の最初の100文字を表示
text_to_speech(clean_content, output_filename)
説明:
clean_html 関数:
BeautifulSoup を使用して、HTMLタグを削除し、純粋なテキスト部分を抽出します。
soup.get_text() で、HTMLタグを除去してテキストだけを取得しています。
記事の内容を処理:
get_post_content で取得した記事のHTMLを clean_html に渡して、HTMLタグを取り除きます。
その後、テキストだけを text_to_speech 関数に渡して音声に変換します。
音声ファイルからWordPressへ自動投稿
pip install requests azure-cognitiveservices-speech
以下は、音声ファイルからテキストを起こし、そのテキストをWordPressに新しい記事として投稿するPythonコードです。
import requests
import azure.cognitiveservices.speech as speechsdk
# Azure Speech Service の設定
subscription_key = "YOUR_AZURE_SUBSCRIPTION_KEY"
region = "YOUR_AZURE_REGION"
# WordPress APIの設定
wordpress_url = "https://yourwordpresssite.com/wp-json/wp/v2/posts"
wordpress_user = "YOUR_WORDPRESS_USERNAME"
wordpress_password = "YOUR_WORDPRESS_PASSWORD"
# Azure Speech-to-Textで音声ファイルからテキストを抽出する関数
def speech_to_text(audio_filename):
# 音声認識の設定
speech_config = speechsdk.SpeechConfig(subscription=subscription_key, region=region)
audio_config = speechsdk.AudioConfig(filename=audio_filename)
# SpeechRecognizer の作成
speech_recognizer = speechsdk.SpeechRecognizer(speech_config=speech_config, audio_config=audio_config)
# 音声をテキストに変換
print(f"Transcribing audio from {audio_filename}...")
result = speech_recognizer.recognize_once()
if result.reason == speechsdk.ResultReason.RecognizedSpeech:
print(f"Transcription: {result.text}")
return result.text
elif result.reason == speechsdk.ResultReason.NoMatch:
print("No speech could be recognized.")
return None
elif result.reason == speechsdk.ResultReason.Canceled:
cancellation_details = result.cancellation_details
print(f"Speech Recognition canceled: {cancellation_details.reason}")
if cancellation_details.reason == speechsdk.CancellationReason.Error:
print(f"Error details: {cancellation_details.error_details}")
return None
# WordPressに新しい記事を投稿する関数
def post_to_wordpress(title, content):
# WordPressに記事を投稿するための認証情報
auth = (wordpress_user, wordpress_password)
# 投稿内容
post = {
"title": title,
"content": content,
"status": "publish" # 投稿ステータス ("draft", "publish"など)
}
# WordPress API に POST リクエストを送信
response = requests.post(wordpress_url, json=post, auth=auth)
if response.status_code == 201:
print(f"Post created successfully: {response.json()['link']}")
else:
print(f"Failed to create post: {response.status_code}")
print(f"Response: {response.content}")
# メイン処理
def main(audio_filename, post_title):
# 1. 音声ファイルからテキストを抽出
transcribed_text = speech_to_text(audio_filename)
# 2. テキストをWordPressに投稿
if transcribed_text:
post_to_wordpress(post_title, transcribed_text)
# 実行部分(音声ファイルと投稿タイトルを指定)
audio_file_path = "/path/to/your/audiofile.wav"
article_title = "Transcribed Article from Audio"
# メイン処理の呼び出し
main(audio_file_path, article_title)
日本語の場合はこちら
import requests
import azure.cognitiveservices.speech as speechsdk
import os
# Azure Speech Service の設定
subscription_key = "YOUR_AZURE_SUBSCRIPTION_KEY"
region = "YOUR_AZURE_REGION"
# WordPress APIの設定
wordpress_url = "https://yourwordpresssite.com/wp-json/wp/v2/posts"
wordpress_user = "YOUR_WORDPRESS_USERNAME"
wordpress_password = "YOUR_WORDPRESS_PASSWORD"
# Azure Speech-to-Textで音声ファイルから日本語のテキストを抽出する関数
def speech_to_text(audio_filename):
# 音声認識の設定
speech_config = speechsdk.SpeechConfig(subscription=subscription_key, region=region)
speech_config.speech_recognition_language = "ja-JP" # 日本語を指定
audio_config = speechsdk.AudioConfig(filename=audio_filename)
# SpeechRecognizer の作成
speech_recognizer = speechsdk.SpeechRecognizer(speech_config=speech_config, audio_config=audio_config)
# 音声をテキストに変換
print(f"Transcribing audio from {audio_filename}...")
result = speech_recognizer.recognize_once()
if result.reason == speechsdk.ResultReason.RecognizedSpeech:
print(f"Transcription: {result.text}")
return result.text
elif result.reason == speechsdk.ResultReason.NoMatch:
print("No speech could be recognized.")
return None
elif result.reason == speechsdk.ResultReason.Canceled:
cancellation_details = result.cancellation_details
print(f"Speech Recognition canceled: {cancellation_details.reason}")
if cancellation_details.reason == speechsdk.CancellationReason.Error:
print(f"Error details: {cancellation_details.error_details}")
return None
# WordPressに新しい記事を投稿する関数
def post_to_wordpress(title, content):
# WordPressに記事を投稿するための認証情報
auth = (wordpress_user, wordpress_password)
# 投稿内容
post = {
"title": title,
"content": content,
"status": "publish" # 投稿ステータス ("draft", "publish"など)
}
# WordPress API に POST リクエストを送信
response = requests.post(wordpress_url, json=post, auth=auth)
if response.status_code == 201:
print(f"Post created successfully: {response.json()['link']}")
else:
print(f"Failed to create post: {response.status_code}")
print(f"Response: {response.content}")
# メイン処理
def main(audio_filename, post_title):
# 1. 音声ファイルからテキストを抽出
transcribed_text = speech_to_text(audio_filename)
# 2. テキストをWordPressに投稿
if transcribed_text:
post_to_wordpress(post_title, transcribed_text)
# 実行部分(音声ファイルと投稿タイトルを指定)
audio_file_path = "/path/to/your/audiofile.wav"
article_title = "Transcribed Article from Audio"
# ファイルが存在するか確認
if not os.path.isfile(audio_file_path):
print(f"Error: File '{audio_file_path}' not found or cannot be opened.")
else:
main(audio_file_path, article_title)
プログラムはツールです。
これをどう使うか?
アイディアはあなた次第です。
外国語の音声ファイルを翻訳してWordPressに投稿
インタビューの文字起こしなどに便利です。
プログラムボタンをポンで投稿まで全部できたらかなり時短になりますよね。
ただし、著作権を守り、引用などに注意してください。
音声ファイルからテキストを文字起こしし、その後に翻訳してWordPressに投稿するプログラムは、Speech-to-Text機能で音声からテキストを抽出し、Translator Text APIで翻訳する機能を使います。
このプロセスをステップに分けて説明し、プログラムの例を提供します。
こちらは、deepLAPIを使ってもいいですが、 Azureで固めた方が従量課金枠などの管理がしやすいと思いますので、Azureで翻訳のAPIを取得しています。
ステップ:
音声ファイルから英語テキストを抽出(Speech-to-Text)。
抽出された英語テキストを日本語に翻訳(Translator Text API)。
両方の結果(英語と日本語)をWordPressに投稿。
pip install requests azure-cognitiveservices-speech
import requests
import azure.cognitiveservices.speech as speechsdk
import os
# Azure Speech-to-Text の設定
speech_subscription_key = "YOUR_SPEECH_SUBSCRIPTION_KEY"
speech_region = "YOUR_SPEECH_REGION"
# Azure Translator の設定
translator_subscription_key = "YOUR_TRANSLATOR_SUBSCRIPTION_KEY"
translator_endpoint = "https://api.cognitive.microsofttranslator.com/"
translator_region = "YOUR_TRANSLATOR_REGION"
# WordPress APIの設定
wordpress_url = "https://yourwordpresssite.com/wp-json/wp/v2/posts"
wordpress_user = "YOUR_WORDPRESS_USERNAME"
wordpress_password = "YOUR_WORDPRESS_PASSWORD"
# Azure Speech-to-Textで音声ファイルから英語のテキストを抽出する関数
def speech_to_text(audio_filename):
speech_config = speechsdk.SpeechConfig(subscription=speech_subscription_key, region=speech_region)
speech_config.speech_recognition_language = "en-US" # 英語の音声を認識
audio_config = speechsdk.AudioConfig(filename=audio_filename)
speech_recognizer = speechsdk.SpeechRecognizer(speech_config=speech_config, audio_config=audio_config)
print(f"Transcribing audio from {audio_filename}...")
result = speech_recognizer.recognize_once()
if result.reason == speechsdk.ResultReason.RecognizedSpeech:
print(f"Transcription (English): {result.text}")
return result.text
elif result.reason == speechsdk.ResultReason.NoMatch:
print("No speech could be recognized.")
return None
elif result.reason == speechsdk.ResultReason.Canceled:
cancellation_details = result.cancellation_details
print(f"Speech Recognition canceled: {cancellation_details.reason}")
if cancellation_details.reason == speechsdk.CancellationReason.Error:
print(f"Error details: {cancellation_details.error_details}")
return None
# Azure Translatorで英語テキストを日本語に翻訳する関数
def translate_text(text, target_language="ja"):
path = '/translate'
constructed_url = translator_endpoint + path
params = {
'api-version': '3.0',
'to': target_language
}
headers = {
'Ocp-Apim-Subscription-Key': translator_subscription_key,
'Ocp-Apim-Subscription-Region': translator_region,
'Content-type': 'application/json'
}
body = [{
'text': text
}]
request = requests.post(constructed_url, params=params, headers=headers, json=body)
response = request.json()
if response:
translated_text = response[0]['translations'][0]['text']
print(f"Translated (Japanese): {translated_text}")
return translated_text
else:
print("Translation failed.")
return None
# WordPressに記事を投稿する関数
def post_to_wordpress(title, content):
auth = (wordpress_user, wordpress_password)
post = {
"title": title,
"content": content,
"status": "publish"
}
response = requests.post(wordpress_url, json=post, auth=auth)
if response.status_code == 201:
print(f"Post created successfully: {response.json()['link']}")
else:
print(f"Failed to create post: {response.status_code}")
print(f"Response: {response.content}")
# メイン処理: 音声ファイルからテキスト抽出、翻訳、WordPressに投稿
def main(audio_filename, post_title):
# 1. 英語の音声ファイルから文字起こし
english_text = speech_to_text(audio_filename)
if english_text:
# 2. 英語のテキストを日本語に翻訳
japanese_text = translate_text(english_text, target_language="ja")
if japanese_text:
# 3. WordPressに英語と日本語を投稿
content = f"<h2>Original (English)</h2>\n<p>{english_text}</p>\n<h2>Translation (Japanese)</h2>\n<p>{japanese_text}</p>"
post_to_wordpress(post_title, content)
# 実行部分
audio_file_path = "/path/to/your/english_audiofile.wav"
article_title = "Transcribed and Translated Article"
# ファイルの存在を確認してメイン処理を実行
if not os.path.isfile(audio_file_path):
print(f"Error: File '{audio_file_path}' not found or cannot be opened.")
else:
main(audio_file_path, article_title)
説明:
speech_to_text関数:
英語の音声ファイルからテキストを抽出します。speech_config.speech_recognition_language = "en-US"により、英語での音声認識が行われます。
translate_text関数:
Azure Translator Text APIを使って、英語のテキストを日本語に翻訳します。target_language="ja"により、翻訳先言語が日本語に設定されています。
post_to_wordpress関数:
WordPress REST APIを使って、記事を投稿します。英語の原文と日本語の翻訳結果を1つの記事にまとめ、投稿します。
main関数:
音声ファイルのパスを指定して、英語テキストの抽出、日本語翻訳、WordPressへの投稿を順次行います。
投稿内容の構成:
WordPressの記事は次のようなフォーマットで投稿されます。
日本語音声から外国語へ翻訳して投稿
逆も然りですね。
例えば、日本語の音声をスペイン語に翻訳し、WordPressに投稿するコードも同じフレームワークを使って構築できます。
ここでは、日本語の音声ファイルをAzure Speech-to-Textで文字起こしし、そのテキストをスペイン語に翻訳して、WordPressに投稿します。
import requests
import azure.cognitiveservices.speech as speechsdk
import os
# Azure Speech-to-Text の設定
speech_subscription_key = "YOUR_SPEECH_SUBSCRIPTION_KEY"
speech_region = "YOUR_SPEECH_REGION"
# Azure Translator の設定
translator_subscription_key = "YOUR_TRANSLATOR_SUBSCRIPTION_KEY"
translator_endpoint = "https://api.cognitive.microsofttranslator.com/"
translator_region = "YOUR_TRANSLATOR_REGION"
# WordPress APIの設定
wordpress_url = "https://yourwordpresssite.com/wp-json/wp/v2/posts"
wordpress_user = "YOUR_WORDPRESS_USERNAME"
wordpress_password = "YOUR_WORDPRESS_PASSWORD"
# Azure Speech-to-Textで音声ファイルから日本語のテキストを抽出する関数
def speech_to_text(audio_filename):
speech_config = speechsdk.SpeechConfig(subscription=speech_subscription_key, region=speech_region)
speech_config.speech_recognition_language = "ja-JP" # 日本語の音声を認識
audio_config = speechsdk.AudioConfig(filename=audio_filename)
speech_recognizer = speechsdk.SpeechRecognizer(speech_config=speech_config, audio_config=audio_config)
print(f"Transcribing audio from {audio_filename}...")
result = speech_recognizer.recognize_once()
if result.reason == speechsdk.ResultReason.RecognizedSpeech:
print(f"Transcription (Japanese): {result.text}")
return result.text
elif result.reason == speechsdk.ResultReason.NoMatch:
print("No speech could be recognized.")
return None
elif result.reason == speechsdk.ResultReason.Canceled:
cancellation_details = result.cancellation_details
print(f"Speech Recognition canceled: {cancellation_details.reason}")
if cancellation_details.reason == speechsdk.CancellationReason.Error:
print(f"Error details: {cancellation_details.error_details}")
return None
# Azure Translatorで日本語テキストをスペイン語に翻訳する関数
def translate_text(text, target_language="es"):
path = '/translate'
constructed_url = translator_endpoint + path
params = {
'api-version': '3.0',
'to': target_language # スペイン語に翻訳
}
headers = {
'Ocp-Apim-Subscription-Key': translator_subscription_key,
'Ocp-Apim-Subscription-Region': translator_region,
'Content-type': 'application/json'
}
body = [{
'text': text
}]
request = requests.post(constructed_url, params=params, headers=headers, json=body)
response = request.json()
if response:
translated_text = response[0]['translations'][0]['text']
print(f"Translated (Spanish): {translated_text}")
return translated_text
else:
print("Translation failed.")
return None
# WordPressに記事を投稿する関数
def post_to_wordpress(title, content):
auth = (wordpress_user, wordpress_password)
post = {
"title": title,
"content": content,
"status": "publish"
}
response = requests.post(wordpress_url, json=post, auth=auth)
if response.status_code == 201:
print(f"Post created successfully: {response.json()['link']}")
else:
print(f"Failed to create post: {response.status_code}")
print(f"Response: {response.content}")
# メイン処理: 音声ファイルからテキスト抽出、翻訳、WordPressに投稿
def main(audio_filename, post_title):
# 1. 日本語の音声ファイルから文字起こし
japanese_text = speech_to_text(audio_filename)
if japanese_text:
# 2. 日本語のテキストをスペイン語に翻訳
spanish_text = translate_text(japanese_text, target_language="es")
if spanish_text:
# 3. WordPressに日本語とスペイン語を投稿
content = f"<h2>Original (Japanese)</h2>\n<p>{japanese_text}</p>\n<h2>Translation (Spanish)</h2>\n<p>{spanish_text}</p>"
post_to_wordpress(post_title, content)
# 実行部分
audio_file_path = "/path/to/your/japanese_audiofile.wav"
article_title = "Transcribed and Translated Article (Japanese to Spanish)"
# ファイルの存在を確認してメイン処理を実行
if not os.path.isfile(audio_file_path):
print(f"Error: File '{audio_file_path}' not found or cannot be opened.")
else:
main(audio_file_path, article_title)
翻訳のAPIでもリージョンは同様にしてください。
これでばっちりですね。
あとは表示方法などを微調整すればOKです。

この記事が気に入ったらチップで応援してみませんか?