
日本語に特化したOCR、文書画像解析Pythonパッケージ「YomiToku」を公開しました

はじめに
最近、LLMへのRAGを用いた文書データの連携等を目的に海外を中心にOCRや文書画像解析技術に関連する新しいサービスが活発にリリースされています。
しかし、その多くは日本語をメインターゲットに開発されているわけではありません。日本語文書は、英数字に加えて、ひらがな、漢字、記号など数千種類の文字を識別する必要があったり、縦書きなど日本語ドキュメント特有のレイアウトに対処する必要があったりと日本語特有の難しさがあります。
ですが、今後、海外の開発者がこれらの課題に対処するため、日本のドキュメント画像解析に特化したものをリリースする可能性は低く、やはり自国の言語向けのサービスは自国のエンジニアが開発すべきだと筆者は考えています。
もちろん、Azure Document Intelligenceをはじめとした、クラウドサービスのドキュメント解析サービスはありますが、クラウドを利用できないユースケースも多くありますので、ローカルサーバーで実行できるサービスも必要だと思います。
そこで、ローカルサーバーで実行可能かつ、日本語文書に特化したOCR,ドキュメント画像解析を行うPythonパッケージ「YomiToku」を開発しました。YomiTokuの名前は日本語の"読み解く"から来ています(安直ですね笑)。
"読み解く"のという言葉の意味通り、ただ文書内の文字起こしを行うだけでなく、文書のレイアウト構造や図表の解析機能など、文書画像を解析するための包括的な機能を搭載しています。次節でYomiTokuの詳細を紹介したいと思います。
YomiTokuの紹介
YomiTokuはPDFやカメラで撮影された文書画像を解析するためのPythonパッケージです。以下のGitHubのリポジトリに公開されています。
以下のようなユースケースを想定して開発しています。
LLMでRAGを利用する際の、ドキュメント解析結果の連携
PDFなどの表のデータからのデータの転記作業の効率化
その他、文書画像からの情報抽出を伴う、作業の半自動化
機密情報が記載された文書画像のローカルサーバー内での解析
YomiTokuに搭載されている機能の概要を紹介します。
AI-OCR
文書画像に対して、全文OCRを行い、文書画像から文字の位置と認識結果を取得可能です。搭載されているモデルは筆者が独自に構築したデータセットで学習したAIモデルです。インターネット上で公開されている文書データや合成データを生成し、学習に利用しています。また、最新の論文や学会の情報、ライセンスなどの制約を考慮した上で、内部のモデルの選定を行っています。
YomiToku内のAI-OCRは、おおよそ7000種類の文字の識別に対応、また、縦書きにも対応しています。以下はYomiTokuに搭載したAI-OCRモデルの認識結果を可視化したものです。

緑枠はテキスト検出モデルが検出した文字の予測位置、青文字は文字の読み取り結果です。PDF以外にもカメラで撮影した文書のカメラ画像の読み取りも可能です。ちなみに日本語特化と説明していますが、英語の文書画像にも対応しています。
レイアウト解析
文書画像のページレイアウトを解析します。レイアウト解析機能は、文書内の段落などテキストのまとまりを予測したり、文書に含まれる図表、画像のを抽出したり、表の構造を解析することが可能です。また、文書に含まれる文章の読み順推定をヒューリスティックなアルゴリズムで解析します。ここに搭載されているAIモデルも開発者が独自に構築したデータセットで学習したAIモデルです。
YomiTokuによるレイアウトの解析結果の例です。
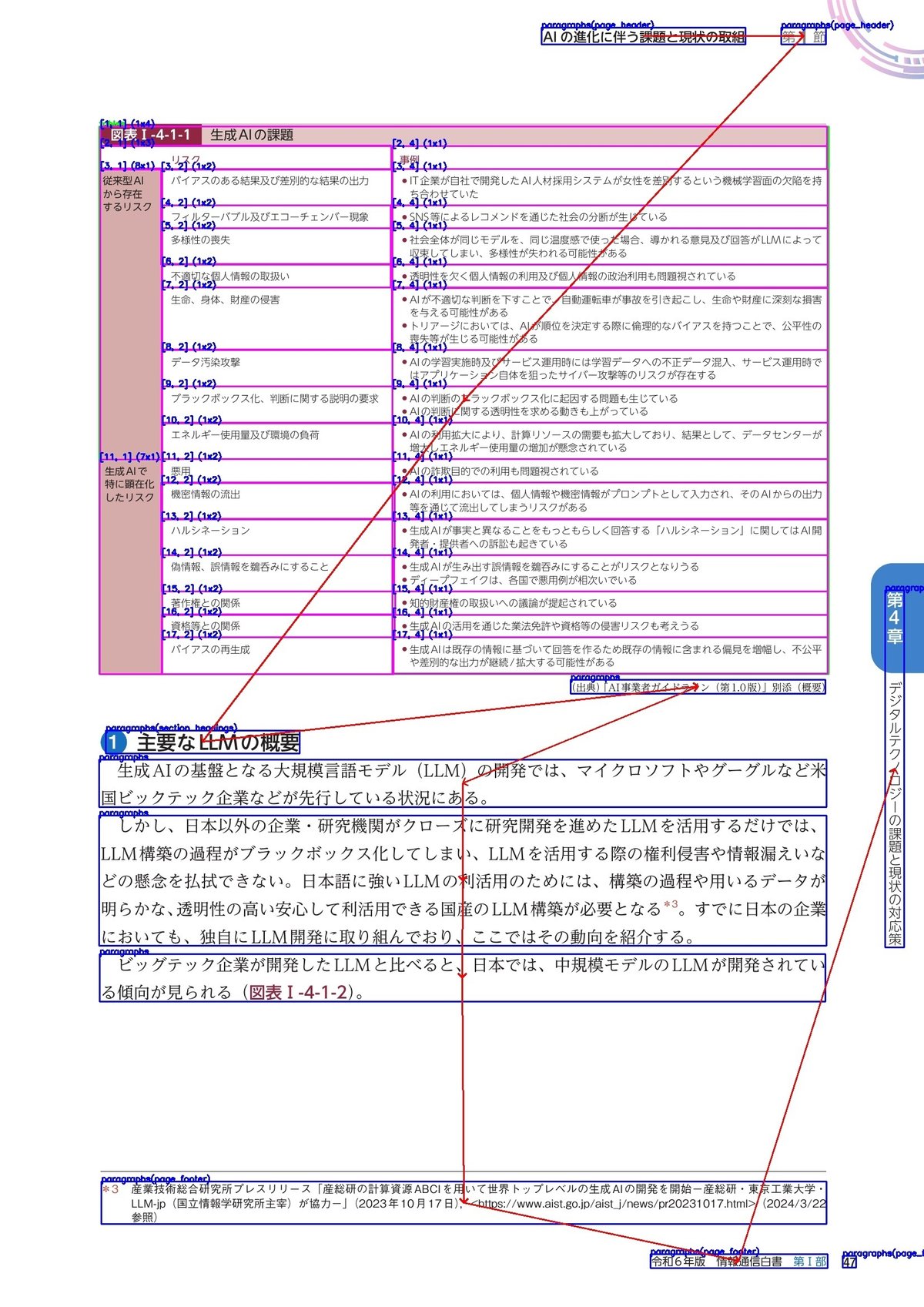

青枠は段落などテキストのまとまりを予測した結果です。
赤枠は図や画像の位置を予測した結果です。
ピンクの枠線は、表の構造の解析結果を示します。表に含まれる各セルの位置や行、列番号、何行何列に渡りセルが結合されているかなどの情報を取得します。
赤矢印は文書の読み順を推定した結果です。段組みレイアウトや縦書きのレイアウトであっても推定することが可能です。(ただし、現状、ヒューリスティックアルゴリズムで予測しているため、新聞などあまりにも複雑なレイアウトだとうまく行かない場合もあります)
また、罫線が存在しない表画像の解析や日本語の文書画像に多く含まれる複雑なセル結合が含まれる表の構造の解析も可能です。以下がその例です。
テーブル構造の認識モデルによって、罫線がない表の区切り位置も自動で予測します。
エクスポート機能
YomiTokuで解析した結果は、JSONに加え、CSV, HTML, Markdownなどのファイルフォーマットで出力することが可能です。また、検出した図や画像を切り出し別のファイルとして保存を行うことが可能です。また、htmlとmarkdownであれば、画像の情報をファイルに埋め込んで出力することも可能です。
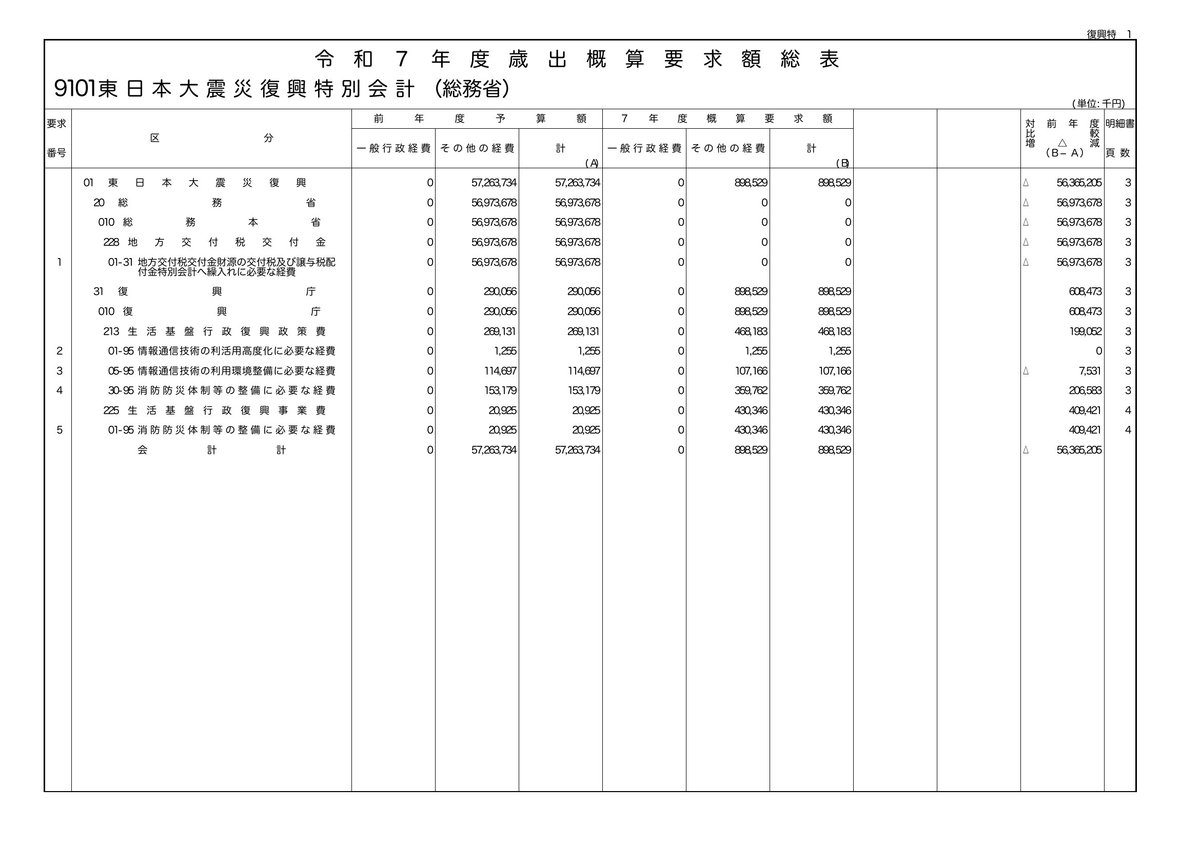
以下の画像をYomiTokuの解析エンジンに入力します。

以下のようにHTMLで出力されます。
<html>
<body>
<p>Al の進化に伴う課題と現状の取組</p>
<p>第1節</p>
<table border="1" style="border-collapse: collapse">
<tr>
<td rowspan="1" colspan="4">図表 I-4-1-1<br/>生成AIの課題</td>
</tr>
<tr>
<td rowspan="1" colspan="3">リスク</td>
<td rowspan="1" colspan="1">事例</td>
</tr>
<tr>
<td rowspan="8" colspan="1">従来型AI<br/>から存在<br/>するリスク</td>
<td rowspan="1" colspan="2">バイアスのある結果及び差別的な結果の出力</td>
<td rowspan="1" colspan="1">●IT企業が自社で開発したAI人材採用システムが女性を差別するという機械学習面の欠陥を持<br/>ち合わせていた</td>
</tr>
<tr>
<td rowspan="1" colspan="2">フィルターバブル及びエコーチェンバー現象</td>
<td rowspan="1" colspan="1">●SNS等によるレコメンドを通じた社会の分断が生じている</td>
</tr>
<tr>
<td rowspan="1" colspan="2">多様性の喪失</td>
<td rowspan="1" colspan="1">●社会全体が同じモデルを、同じ温度感で使った場合、導かれる意見及び回答がLLMによって<br/>収束してしまい、多様性が失われる可能性がある</td>
</tr>
<tr>
<td rowspan="1" colspan="2">不適切な個人情報の取扱い</td>
<td rowspan="1" colspan="1">●透明性を欠く個人情報の利用及び個人情報の政治利用も問題視されている</td>
</tr>
<tr>
<td rowspan="1" colspan="2">生命、身体、財産の侵害</td>
<td rowspan="1" colspan="1">●Alが不適切な判断を下すことで、自動運転車が事故を引き起こし、生命や財産に深刻な損害<br/>を与える可能性がある<br/>●トリアージにおいては、Alが順位を決定する際に倫理的なバイアスを持つことで、公平性の<br/>喪失等が生じる可能性がある</td>
</tr>
<tr>
<td rowspan="1" colspan="2">データ汚染攻撃</td>
<td rowspan="1" colspan="1">●AIの学習実施時及びサービス運用時には学習データへの不正データ混入、サービス運用時で<br/>はアプリケーション自体を狙ったサイバー攻撃等のリスクが存在する</td>
</tr>
<tr>
<td rowspan="1" colspan="2">ブラックボックス化、判断に関する説明の要求</td>
<td rowspan="1" colspan="1">● AIの判断のブラックボックス化に起因する問題も生じている<br/>●AIの判断に関する透明性を求める動きも上がっている</td>
</tr>
<tr>
<td rowspan="1" colspan="2">エネルギー使用量及び環境の負荷</td>
<td rowspan="1" colspan="1">●AIの利用拡大により、計算リソースの需要も拡大しており、結果として、データセンターが<br/>増大しエネルギー使用量の増加が懸念されている</td>
</tr>
<tr>
<td rowspan="7" colspan="1">生成AIで<br/>特に顕在化<br/>したリスク</td>
<td rowspan="1" colspan="2">悪用</td>
<td rowspan="1" colspan="1">● Alの詐欺目的での利用も問題視されている</td>
</tr>
<tr>
<td rowspan="1" colspan="2">機密情報の流出</td>
<td rowspan="1" colspan="1">●AIの利用においては、個人情報や機密情報がプロンプトとして入力され、そのAIからの出力<br/>等を通じて流出してしまうリスクがある</td>
</tr>
<tr>
<td rowspan="1" colspan="2">ハルシネーション</td>
<td rowspan="1" colspan="1">●生成Alが事実と異なることをもっともらしく回答する「ハルシネーション」に関してはAI開<br/>発者·提供者への訴訟も起きている</td>
</tr>
<tr>
<td rowspan="1" colspan="2">偽情報、誤情報を鵜呑みにすること</td>
<td rowspan="1" colspan="1">●生成AIが生み出す誤情報を鵜呑みにすることがリスクとなりうる<br/>●ディープフェイクは、各国で悪用例が相次いでいる</td>
</tr>
<tr>
<td rowspan="1" colspan="2">著作権との関係</td>
<td rowspan="1" colspan="1">●知的財産権の取扱いへの議論が提起されている</td>
</tr>
<tr>
<td rowspan="1" colspan="2">資格等との関係</td>
<td rowspan="1" colspan="1">●生成AIの活用を通じた業法免許や資格等の侵害リスクも考えうる</td>
</tr>
<tr>
<td rowspan="1" colspan="2">バイアスの再生成</td>
<td rowspan="1" colspan="1">●生成AIは既存の情報に基づいて回答を作るため既存の情報に含まれる偏見を増幅し、不公平<br/>や差別的な出力が継続/拡大する可能性がある</td>
</tr>
</table>
<p/>
<h1>1 主要なLLMの概要</h1>
<p>(出典)「AI事業者ガイドライン(第1.0版)」別添(概要)</p>
<p>生成AIの基盤となる大規模言語モデル(LLM) の開発では、マイクロソフトやグーグルなど米<br/>国ビックテック企業などが先行している状況にある。</p>
<p>しかし、日本以外の企業·研究機関がクローズに研究開発を進めたLLM を活用するだけでは、<br/>LLM構築の過程がブラックボックス化してしまい、LLMを活用する際の権利侵害や情報漏えいな<br/>どの懸念を払拭できない。日本語に強いLLMの利活用のためには、構築の過程や用いるデータが<br/>明らかな、透明性の高い安心して利活用できる国産のLLM構築が必要となる*3。すでに日本の企業<br/>においても、独自にLLM開発に取り組んでおり、ここではその動向を紹介する。</p>
<p>ビッグテック企業が開発したLLMと比べると、日本では、中規模モデルのLLMが開発されてい<br/>る傾向が見られる(図表1-4-1-2)。</p>
<p>*3 産業技術総合研究所プレスリリース「産総研の計算資源ABCIを用いて世界トップレベルの生成AIの開発を開始一産総研·東京工業大学·<br/>LLM-jp (国立情報学研究所主宰)が協力ー」(2023年10月17日),<https://www.aist.go.jp/aist_j/news/pr20231017.html> (2024/3/<br/>参照)</p>
<p>令和6年版 情報通信白書 第1部 47</p>
<p>デジタルテクノロジーの課題と現状の対応策<br/>第4章</p>
</body>
</html>
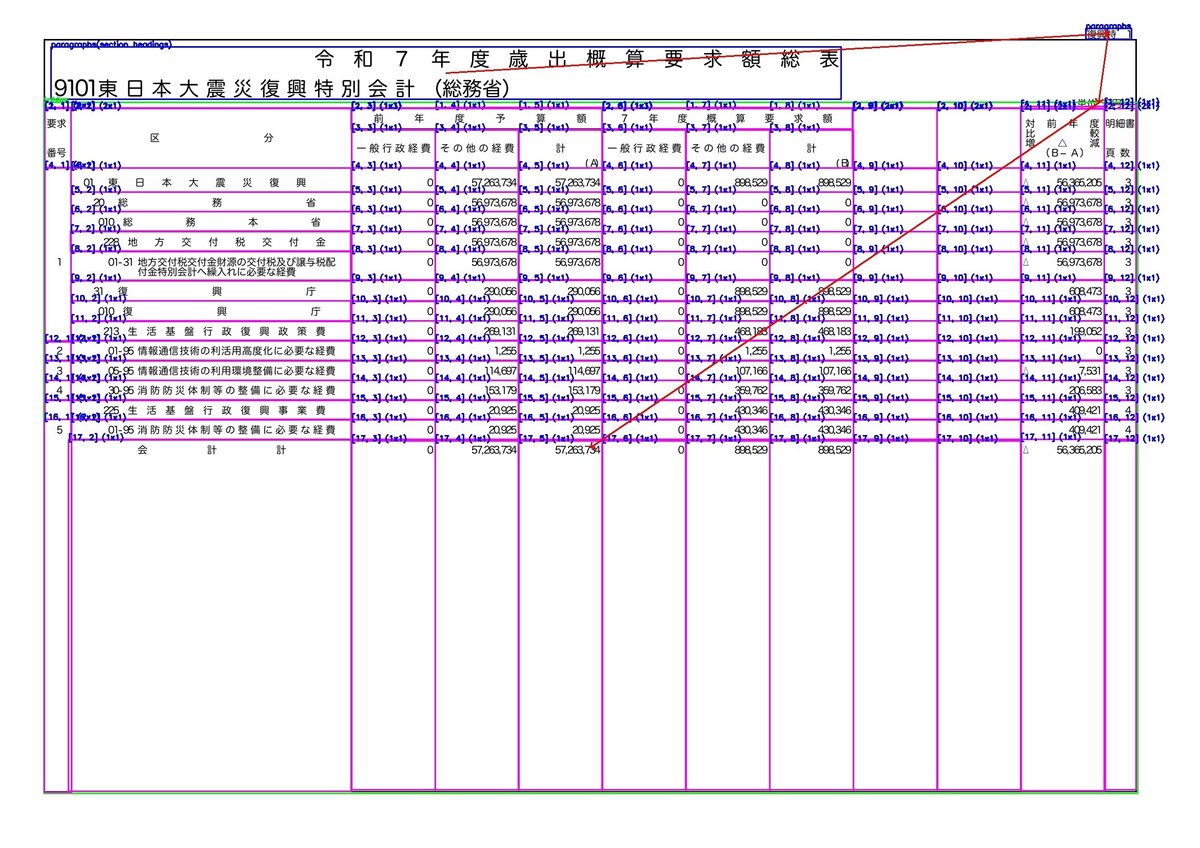
このHTMLをブラウザで開き、スクリーンショットを撮影した結果が以下の画像です。一部、認識間違いはありますが、入力した文書画像の文書構造を解析し、レイアウトや文書の意味的な構造を壊さずに解析できています。

実行方法
実行環境について
OSはWindows, Mac OS, Linuxで動作検証を行い、動作することを確認しています。CPUでも動作しますが、CPU用にモデルが最適化されておらず、低速なため、GPUの使用を推奨します。モデルはすべてPytorchで開発されており、実行のためにCUDA11.8以上のバージョンが必要な点に注意してください。GPUのスペックに関してはVRAMが8GB程度搭載されているものであれば問題なく動作可能です。
インストール
YomiTokuはPYPIに公開されているため、pipでインストール可能です
pip install yomitokupytorch はご自身の CUDAのバージョンにあったものをインストールしてください。デフォルトではCUDA12.4に対応したものがインストールされます。
pytorch は2.5以上のバージョンに対応しています。その関係でCUDA11.8以上のバージョンが必要になります。対応できない場合は、リポジトリ内のDockerfileを利用してください
利用方法
YomiTokuはCLIで実行可能なコマンドを提供しています。
yomitoku $(path_data) -f md -o results -v --figure$(path_data) 解析対象の画像が含まれたディレクトリか画像ファイルのパスを直接して指定してください。ディレクトリを対象とした場合はディレクトリのサブディレクトリ内の画像も含めて処理を実行します。
-f, --format 出力形式のファイルフォーマットを指定します。(json, csv, html, md をサポート)
-o, --outdir 出力先のディレクトリ名を指定します。存在しない場合は新規で作成されます。
-v, --vis を指定すると解析結果を可視化した画像を出力します。
-d, --device モデルを実行するためのデバイスを指定します。gpu が利用できない場合は cpu で推論が実行されます。(デフォルト: cuda)
--ignore_line_break 画像の改行位置を無視して、段落内の文章を連結して返します。(デフォルト:画像通りの改行位置位置で改行します。)
--figure_letter 検出した図表に含まれる文字も出力ファイルにエクスポートします。
--figure 検出した図、画像を出力ファイルにエクスポートします。(html と markdown のみ)
その他のオプションに関しては、ヘルプを参照
プログラム内に組み込みたい場合はGitHubのリポジトリ内で公開しているドキュメントを参照してください。
利用制限
ライセンスに関しては、CC BY-NC-SA 4.0に設定しています。個人や研究、検証目的での利用は問題ありません。商用利用は別途、商用ライセンスが必要になります。YomiTokuはOSSではないので、その点に注意してください。
終わりに
YomiTokuは現在(2024/11/26)、ベータ版として公開しています。不具合やバグがある可能性が高いと思いますので、不具合があれば、issueで開発者に報告をお願いします。フィードバックや追加機能のご意見もあれば、コメントお願いします。
あとがき
今回、YomiTokuを公開する理由の一つとして、国内のAIの研究開発の活性化があります。OCRや文書画像解析は地味で古典的な技術分野で(研究が)終わった技術だと思われることもありますが、海外では、未だに活発に研究開発が行われている分野です。また、筆者自身、紙文化が根強い日本でのニーズは大きいと考えています。しかし、国内でこのような研究開発が行われているという話を耳にする機会は少ないです。実際、筆者が認識している範囲だと、研究用途で日本語OCRデータセットは存在しないです。(もし、あれば教えてください)
OCRや文書画像解析は、将来的はVLMなど"基盤モデル"と呼ばる大規模モデルに統合されていくタスクだと思いますが、文書画像解析に対応した大規模モデルを開発するためには、高精度OCRモデルが必要な可能性が高いです。例えば、汎用的な文書解析タスクの事前学習モデルであるLayoutLMなどは前段にOCR処理を行うことが前提となっていたりします。
AIの研究開発において、下積みのモデルが存在するからこそ、汎用性を高めたりといった次の課題解決可能になるようなケースは多いと思います。しかし、あらゆるタスクにおいて、日本語向けに学習、公開されているモデルは少ない印象があります。公開の影響は微々たるものかもしれませんが、日本のAI分野における研究開発の進展に貢献できたらと思います。