
【画像認識を利用したAIアプリ】LINEに画像を送ったら自動で判定してくれる機械学習アプリをPythonで作ろう

2月14日といえば、バレンタインデーですね。
皆さん、バレンタインデー当日ってすごくそわそわしますよね。下駄箱とか机の中とか意味もないのに探ったりした経験があるのを覚えています。
幸運にも女の子からチョコを貰えたあなた。
そんな時にこう思った経験はありませんか??
このチョコは義理チョコ?本命チョコ?と。
今回はそんなバレンタインデーにおける男性にとって重大な問題を解決するAI Line Bot「バレンタイン先生」を作ってみました。
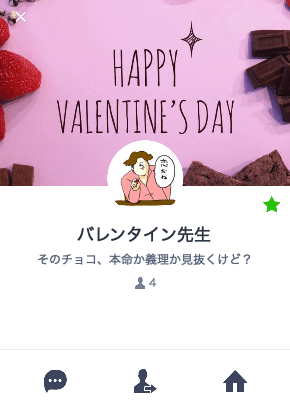
送ったチョコの画像から、そのチョコが義理か本命かの判定とその確率を出してくれるというシンプルなアプリとなっています。
このチュートリアルで、できるようになること
このチュートリアルに沿って勉強して頂ければ、以下のことができるようになります。
・Pythonのスクレイピングを利用して自動でネットから膨大なデータを取得すること
・画像認識の機械学習API Google Cloud AutoML Visionを使用したノンプログラミングでの学習からAPIでの使用
・Herku上でPythonを使用したアプリケーションの構築
・Line Botの作成から、自動でメッセージを返せる仕組みの構築
・0からのアプリケーション作成経験を通して、一連の流れの理解
これらを学ぶことにより、このチュートリアルを応用して自分オリジナルのアプリケーションを作成することができます。これを使うことで自分オリジナルのLINE Botを作成できます。例えばラーメン二郎のラーメンの画像を送ってそれがどの店舗のかを判定してくれたり、メルカリのブランド品査定でも使われているみたいです。欅坂46が好きなら誰に似てるか判定するなんてこともできます。
読者の対象
完全なプログラミング初心者はやめたほうがいいと思います。基本的にはプログラミング学習サイト(Progate)で学んだけど、次に何をやればいいの?みたいな人にちょうどいいかもしれないです。機械学習部分はプログミングなしで出来るためそこまで難しくないかもしれないです。
読むために最低限必要なスキルは以下です。
・基本的なPythonの知識(Pythonの実行環境の解説はないため、そこは自分でできる人。簡単な文法がわかる。もしくはPythonは触ったことがなくても他の言語を触ったことがある人。)
・基本的なHtml,CSSの知識(今回は知識がなくても実装は出来るが、スクレイピングの理解を深めるためには必要です。)
・Webアプリケーションの基礎知識(なくてもプログラミングできればググりながらで理解できます)
・とにかくどんな困難が起きてもでもやり抜く力。(これが一番大事)
最後の「とにかくどんな困難が起きてもでもやり抜く力。」が一番大事です。すんなり行くかもしれませんが、どこかしらハマった時にこの力が必要です。ここに自信のある方はググりながら実装できるはずです。
全くプログラミングをやったことない、もしくは自信のない人へ
プログミング未経験だけど、バレンタイン先生みたいなアプリを作ってみたいという思い、素晴らしいと思います。ただ、今は難しいかもしれないので一旦、以下のProgateとというプログラミング学習サイトで学習されることをお勧めします。今回ですと、Python,コマンドライン, Html CSSを勉強し、Pythonの実行環境を整えられれて、あとはやる気さえあれば今回のチュートリアルは可能かと思われます。また余裕があればPyQというサイトでスクレイピングを学んでおくといいかもしれないです。
目次
バレンタイン先生とは
バレンタイン先生を構成する技術
実装したアプリの全体像
Pythonで「本命チョコ」と「義理チョコ」の画像をスクレイピングしよう
スクレイピングに必要なPythonの知識
スクレイピングのコードの解説
Pythonによる画像水増しの解説
プログミングなし!Google Cloud AutoML Visionに学習させよう
LineからGoogle Cloud AutoML Visionでチョコ判定してみよう
バレンタイン先生とは
Lineにチョコ画像を送ると、そのチョコが義理か本命かを返してくれるLine Botです。こちらは一目で義理とわかるチョコ「ブラックサンダー」の画像を送った時の判定結果となります。
すごくシンプルな機能ですが、この裏では画像認識の技術を利用したAIで動いています。AIによると99.999%の確率でブラックサンダーは義理ですね。

バレンタイン先生を構成する技術
以下の技術でAI Line Botが構成されています。
・Python(スクレイピング・画像処理・フレームワーク)
・Heroku(プラットフォーム)
・Google Cloud AutoML Vision(画像認識AI)
・Line Messaging API(メッセージのやり取り)
を利用しています。人工知能の部分は、Google Cloud AutoML Visionでプログラミングなしで作れちゃいます(これはすごい。。)。今回でいえば、チョコの画像を学習させてそれをAPIとして利用することで、複雑な画像認識の技術を簡単に実装することができます。
実装したアプリの全体像
STEP1 チョコ画像の取得・水増しから学習まで
SETP1ではバレンタイン先生の脳みそ(AI)を作っていきます。脳みそ(Google AutoML Vision)は今は何もチョコの情報を知らない状態です。なのでそのチョコが義理か本命かを覚えさせないといけません。そのために大量のチョコ画像データが必要です。このことを学習データと呼びます。
まず学習データを用意するために、Pythonのスクレイピングという技術を使います。この技術により、Goolgle画像検索で「義理チョコ」と「本命チョコ」と検索した結果から、各400枚程度を取得できます。その次に、画像の水増しをpythonの画像処理ライブラリ(OpenCV)を使用して行い各3000枚程度に増やします。ここまでで義理チョコと本命チョコそれぞれの画像が3000枚程度となり、その画像をGoogle Cloud AutoML Visionに学習させます。

これにより、バレンタイン先生の脳みそに本命チョコと義理チョコの違いを覚えさせました。ここまでがチョコ画像の取得・水増しから学習となります。
STEP2 LINEで画像を送ったらチョコ判定できるようにする
STEP1でバレンタイン先生が義理チョコか本命チョコかを判定できるようになりました。ただし、これではLINEと繋がっていないので、STEP2ではLineから画像を送ったら本命か義理を判定できるようにします。
Lineから①チョコの画像を送るとそれが、Herokuに送信されます。それをHerokuで上で受け取り②の通りGoogle Cloud AutoML Visionに画像を渡します。③でGoogle Cloud AutoML Visionはチョコ画像が義理か本命かを確率で返してくれるので、それをHeroku上で受け取ります。④ではその返ってきた結果をメッセージにしてLINEに渡して、LINE上でメッセージを返すという流れになっています。
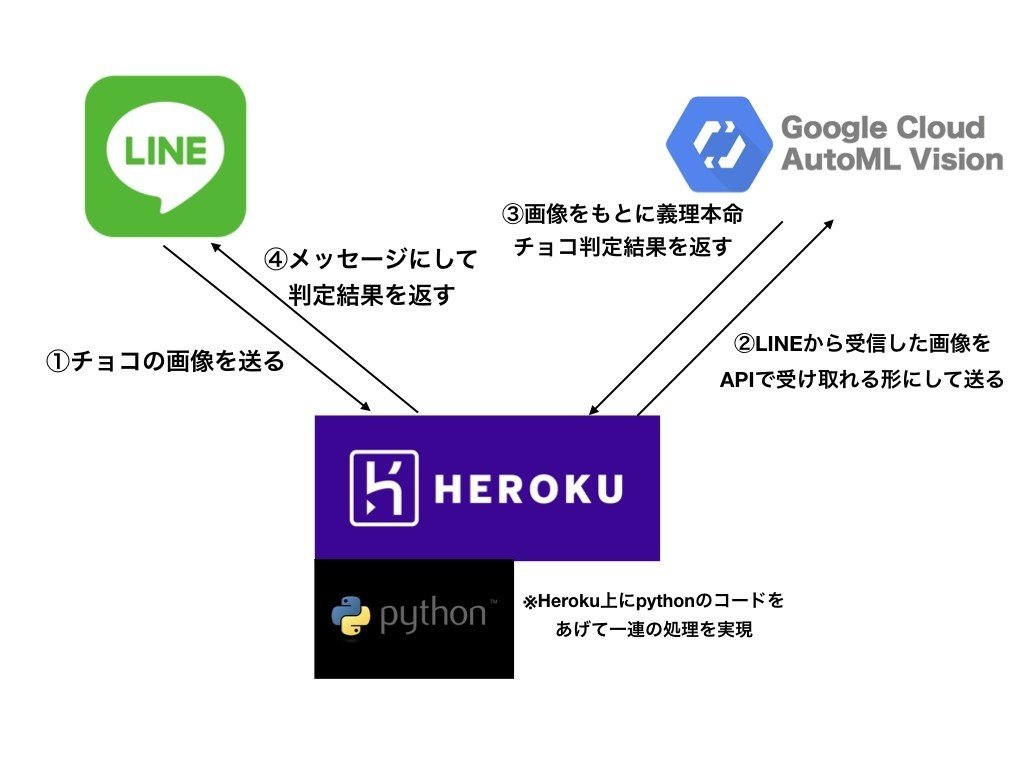
このような流れで、チョコ画像を送ると、義理チョコか本命チョコかを判定してくれる処理を実行しています。
Pythonで「本命チョコ」と「義理チョコ」の画像をスクレイピングしよう
では、さっそくスクレイピングしてみましょう。
本命チョコと義理チョコを学習させるためには、大量の各画像データが必要となります。そこでスクレイピングを利用して、Google検索で「本命チョコ」「義理チョコ」と検索した結果の画像を取得していきます。
例えば、以下は「本命チョコ」の例となります。自動で以下の赤枠の部分の画像URLを取得し、ローカルフォルダにダウンロードすることで画像を収集します。

これらのチョコ画像一覧から、全てのデータを取得します。実際にスクレピングしている様子です。

そして、スクレイピングした結果は以下のようにフォルダに保存されていきます。

スクレイピングに必要なPythonの知識
スクレイピングに使えるものは沢山ありますが、今回は以下の3つ主に使います。
・BeautifulSoup
・urllib
・requests
BeautifulSoupはPythonのスクレイピングをする時によく使うライブラリです。これにより取得したHtml等のファイルからタグ等の指定することでその要素が取得できます。urllibとrequestsを使用することでWeb上のデータを簡単に取得することができます。
BeautifulSoupとrequestsはインストールが必要です。
例えば、”BeautifulSoup インストール mac” などと検索すればインストール方法はわかると思います。他にもお使いの環境によりライブラリがないなどのエラーが出た場合はその都度インストールして頂ければと思います。
スクレイピングのコードの解説
全体のコードはこちらになります。
import json
import os
import sys
import urllib
from bs4 import BeautifulSoup
import requests
class Google:
def __init__(self):
self.GOOGLE_SEARCH_URL = 'https://www.google.co.jp/search'
self.session = requests.session()
self.session.headers.update(
{'User-Agent': 'Mozilla/5.0 (X11; Linux x86_64; rv:10.0) Gecko/20100101 Firefox/10.0'})
def search(self, keyword, maximum):
print('begin searching', keyword)
query = self.query_gen(keyword)
return self.image_search(query, maximum)
#検索キーワードからクエリ付与したURLを生成
def query_gen(self, keyword):
# search query generator
page = 0
while True:
params = urllib.parse.urlencode({
'q': keyword,
'tbm': 'isch',#画像検索を指定
'ijn': str(page)})
yield self.GOOGLE_SEARCH_URL + '?' + params
page += 1
#画像検索のURL(query_gen)と画像取得枚数(maximum)を指定
def image_search(self, query_gen, maximum):
# search image
result = []
total = 0
while True:
# search
html = self.session.get(next(query_gen)).text #画像検索結果ページのhtmlを取得
soup = BeautifulSoup(html, 'lxml')
elements = soup.select('.rg_meta.notranslate') #指定したクラスを全て取得
jsons = [json.loads(e.get_text()) for e in elements] #取得したクラスから要素を取得しjson→辞書形式に変換
imageURLs = [js['ou'] for js in jsons] #画像のURLを取得
# add search result
if not len(imageURLs):
print('-> no more images')
break
elif len(imageURLs) > maximum - total:
result += imageURLs[:maximum - total]
break
else:
result += imageURLs
total += len(imageURLs)
print('-> found', str(len(result)), 'images')
return result
def main():
google = Google()
# error
if len(sys.argv) != 3:
print('invalid argment')
print('> ./image_collector_cui.py [target name] [download number]')
sys.exit()
else:
# save location
name = sys.argv[1]
data_dir = 'data/'
os.makedirs(data_dir, exist_ok=True)
os.makedirs('data/' + name, exist_ok=True)
# search image
result = google.search(
name, maximum=int(sys.argv[2]))
# download
download_error = []
for i in range(len(result)):
print('-> downloading image', str(i + 1).zfill(4))
try:#画像をダウンロードしてローカルに保存
urllib.request.urlretrieve(
result[i], data_dir + name + '/' + str(i + 1).zfill(4) + '.jpg')
except:
print('--> could not download image', str(i + 1).zfill(4))
download_error.append(i + 1)
continue
print('complete download')
print('├─ download', len(result)-len(download_error), 'images')
print('└─ could not download', len(
download_error), 'images', download_error)
if __name__ == '__main__':
main()処理の流れは
1. Google検索でキーワード画像(義理チョコ、本命チョコ)検索
2. 「指定した枚数分に到達」もしくは「検索結果数に到達」まで処理を実行
・検索結果の画像のURLを取得
・表示してない画像の読み込み
3.「指定した枚数分に到達」もしくは「検索結果数に到達」したら処理をやめる
・取得したURLから画像をダウンロード
・ダウンロードした画像をファイルに保存
という形です。
まずは必要なライブラリをインポートします。
import json
import os
import sys
import urllib
from bs4 import BeautifulSoup
import requestsここから先は有料エリアとなります。有料エリアを全て実装することで、バレンタイン先生を実装することができるようになっています。もしご質問があれば以下からコメントお願い致します。(ただしすべてには答えられませんので、可能な範囲でお答えいたします。)
基本的にこのソースコードで自分で設定する必要のある箇所はないので必要な環境が揃っていればコピペでも動くはずですが一応解説しておきます。
実行例:python ファイル名.py 本命チョコ 500
コマンドラインの第一引数に検索ワード、第二引数に取得枚数を指定し実行
次にGoogleクラスの中身を説明します。
class Google:
#処理記述Google検索URLの指定とセッションの設定を行っています。スクレイピング前の準備段階です。
def __init__(self):
self.GOOGLE_SEARCH_URL = 'https://www.google.co.jp/search'
self.session = requests.session()
self.session.headers.update(
{'User-Agent': 'Mozilla/5.0 (X11; Linux x86_64; rv:10.0) Gecko/20100101 Firefox/10.0'})検索キーワードからクエリ付与したURLを生成するメソッドです。先ほどのGOOGLE_SEARCH_URLに対してパラメータを付与しています。
・'q': keyword→検索キーワード
・'tbm': 'isch'→ischを指定することで画像検索ができます。
#検索キーワードからクエリ付与したURLを生成
def query_gen(self, keyword):
# search query generator
page = 0
while True:
params = urllib.parse.urlencode({
'q': keyword,
'tbm': 'isch',#画像検索を指定
'ijn': str(page)})
yield self.GOOGLE_SEARCH_URL + '?' + params
page += 1ここでは画像検索のURL(query_gen)と画像取得枚数(maximum)を指定して、スクレイピングにより、画像のURLを取得していきます。流れはコメントの通りとなっています。「指定した枚数分に到達」もしくは「検索結果数に到達」したら処理をやめて取得した結果を返します。
#画像検索のURL(query_gen)と画像取得枚数(maximum)を指定
def image_search(self, query_gen, maximum):
# search image
result = []
total = 0
while True:
# search
html = self.session.get(next(query_gen)).text #画像検索結果ページのhtmlを取得
soup = BeautifulSoup(html, 'lxml')
elements = soup.select('.rg_meta.notranslate') #指定したクラスを全て取得
jsons = [json.loads(e.get_text()) for e in elements] #取得したクラスから要素を取得しjson→辞書形式に変換
imageURLs = [js['ou'] for js in jsons] #画像のURLを取得
# add search result
if not len(imageURLs):
print('-> no more images')
break
elif len(imageURLs) > maximum - total:
result += imageURLs[:maximum - total]
break
else:
result += imageURLs
total += len(imageURLs)
print('-> found', str(len(result)), 'images')
return resultここで以下のようにクラスを指定して
elements = soup.select('.rg_meta.notranslate') #指定したクラスを全て取得画像のURLを取得しています。
imageURLs = [js['ou'] for js in jsons] #画像のURLを取得Chromeのデベロッパーツールを開くとわかりますが、最初の黄色で囲った部分のクラスを指定し、次の黄色い枠の赤線の"ou":http://〜〜〜の部分の画像をURLを取得しています。

でこれらの関数を呼び出すことで検索からスクレイピングを行います。
def search(self, keyword, maximum):
print('begin searching', keyword)
query = self.query_gen(keyword)
return self.image_search(query, maximum)次にmain関数の主な部分について説明します。
sys.argv[1]でコマンドラインの引数から検索ワードを取得し、その名前でフォルダを作成します。(「自分の今いるフォルダ/data/name」となる)
実行例:python ファイル名.py 本命チョコ 500
この場合、sys.argv[1]は本命チョコに当たります。
# save location
name = sys.argv[1]
data_dir = 'data/'
os.makedirs(data_dir, exist_ok=True)
os.makedirs('data/' + name, exist_ok=True)下の実行例でいくとsearch関数にname=本命チョコとmaximum=500を設定し、本命チョコの画像を500枚取得という風になります。
実行例:python ファイル名.py 本命チョコ 500
# search image
result = google.search(
name, maximum=int(sys.argv[2]))スクレイピングで取得した画像をurllib.request.urlretrieveを使用してダウンロードして保存していきます。第一引数に画像のURL、第二引数に保存する場所と名前を指定します。
# download
download_error = []
for i in range(len(result)):
print('-> downloading image', str(i + 1).zfill(4))
try:#画像をダウンロードしてローカルに保存
urllib.request.urlretrieve(
result[i], data_dir + name + '/' + str(i + 1).zfill(4) + '.jpg')
except:
print('--> could not download image', str(i + 1).zfill(4))
download_error.append(i + 1)
continueこれで、それぞれ以下を実行します。
実行例:python ファイル名.py 本命チョコ 500
実行例:python ファイル名.py 義理チョコ 500
指定したフォルダを確認してみてください。
これでチョコの画像を集めることが出来ました。
最後ですが、集めた画像から明らかにチョコではない画像を削除しないと学習の段階で精度に影響が出てしまいます。なので、次に入る前に削除しておきましょう。
Pythonによる画像水増しの解説
次に、画像がそれぞれ300から400枚程度集まったと思います。この状態でも学習は出来るのですが、精度が不安なために画像の水増しを行いそれぞれ約3000枚程度に増やしていきます。
※ここは必須ではないため、飛ばして次のステップに進んでいただいても大丈夫です。より精度をあげたければ試してみてください。
画像水増しのソースコードとなります。
#!/usr/bin/env python
# -*- coding: utf-8 -*-
#
# usage: ./increase_picture.py hogehoge.jpg
#
import cv2
import numpy as np
import sys
import os
# ヒストグラム均一化
def equalizeHistRGB(src):
RGB = cv2.split(src)
Blue = RGB[0]
Green = RGB[1]
Red = RGB[2]
for i in range(3):
cv2.equalizeHist(RGB[i])
img_hist = cv2.merge([RGB[0],RGB[1], RGB[2]])
return img_hist
# ガウシアンノイズ
def addGaussianNoise(src):
row,col,ch= src.shape
mean = 0
var = 0.1
sigma = 15
gauss = np.random.normal(mean,sigma,(row,col,ch))
gauss = gauss.reshape(row,col,ch)
noisy = src + gauss
return noisy
# salt&pepperノイズ
def addSaltPepperNoise(src):
row,col,ch = src.shape
s_vs_p = 0.5
amount = 0.004
out = src.copy()
# Salt mode
num_salt = np.ceil(amount * src.size * s_vs_p)
coords = [np.random.randint(0, i-1 , int(num_salt))
for i in src.shape]
out[coords[:-1]] = (255,255,255)
# Pepper mode
num_pepper = np.ceil(amount* src.size * (1. - s_vs_p))
coords = [np.random.randint(0, i-1 , int(num_pepper))
for i in src.shape]
out[coords[:-1]] = (0,0,0)
return out
if __name__ == '__main__':
# ルックアップテーブルの生成
min_table = 50
max_table = 205
diff_table = max_table - min_table
gamma1 = 0.75
gamma2 = 1.5
LUT_HC = np.arange(256, dtype = 'uint8' )
LUT_LC = np.arange(256, dtype = 'uint8' )
LUT_G1 = np.arange(256, dtype = 'uint8' )
LUT_G2 = np.arange(256, dtype = 'uint8' )
LUTs = []
# 平滑化用
average_square = (10,10)
# ハイコントラストLUT作成
for i in range(0, min_table):
LUT_HC[i] = 0
for i in range(min_table, max_table):
LUT_HC[i] = 255 * (i - min_table) / diff_table
for i in range(max_table, 255):
LUT_HC[i] = 255
# その他LUT作成
for i in range(256):
LUT_LC[i] = min_table + i * (diff_table) / 255
LUT_G1[i] = 255 * pow(float(i) / 255, 1.0 / gamma1)
LUT_G2[i] = 255 * pow(float(i) / 255, 1.0 / gamma2)
LUTs.append(LUT_HC)
LUTs.append(LUT_LC)
LUTs.append(LUT_G1)
LUTs.append(LUT_G2)
# 画像の読み込み
path1=sys.argv[1]#フォルダの読み込み
images = os.listdir(path1)#画像の読みこみ
#img_src = cv2.imread(sys.argv[1], 1)
count = 0
n=1
for image in images:#フォルダ配下の画像分回す
if(True):
img_src = cv2.imread(path1+'/giri'+str(n)+'.jpg', 1)
print(n)
trans_img = []
trans_img.append(img_src)
# LUT変換
for i, LUT in enumerate(LUTs):
trans_img.append( cv2.LUT(img_src, LUT))
# 平滑化
trans_img.append(cv2.blur(img_src, average_square))
# ヒストグラム均一化
trans_img.append(equalizeHistRGB(img_src))
# ノイズ付加
trans_img.append(addGaussianNoise(img_src))
trans_img.append(addSaltPepperNoise(img_src))
# 反転
flip_img = []
for img in trans_img:
flip_img.append(cv2.flip(img, 1))
trans_img.extend(flip_img)
# 保存
if not os.path.exists("trans_images"):
os.mkdir("trans_images")
base = os.path.splitext(os.path.basename(sys.argv[1]))[0] + "_"
img_src.astype(np.float64)
for i, img in enumerate(trans_img):
# 比較用
# cv2.imwrite("trans_images/" + base + str(i) + ".jpg" ,cv2.hconcat([img_src.astype(np.float64), img.astype(np.float64)]))
cv2.imwrite("trans_images/" + base + str(count + i) + ".jpg" ,img)
count+=1
n+=1画像の水増しにはOpenCVを使用するためインポートします。
import cv2基本的には以下の記事を参考にしているので読んでみてください。
画像の水増しとして
・コントラスト調整
・平滑化
・反転
・ガウス分布に基づくノイズ付与
・Salt & Pepperノイズ
等を使用してい水増ししていきます。
実行例は以下になります。
※ファイルサイズやファイル形式により、エラーとなる画像も数枚あるため、それらを除外する必要があるかもしれないです。
#実行例
python ファイル名.py 画像のあるフォルダへのパス指定引数からフォルダの読み込みをしています。
path1=sys.argv[1]#フォルダの読み込み'/giri'+str(n)+'の部分を自分のファルダ配下の画像名に変更する必要があります。例ではgiri1,giri2,giri3......と読み込んでいっています。
img_src = cv2.imread(path1+'/giri'+str(n)+'.jpg', 1)最後にtrans_imagesに水増しした画像を保存してくれます。
for i, img in enumerate(trans_img):
# 比較用
# cv2.imwrite("trans_images/" + base + str(i) + ".jpg" ,cv2.hconcat([img_src.astype(np.float64), img.astype(np.float64)]))
cv2.imwrite("trans_images/" + base + str(count + i) + ".jpg" ,img)
count+=1うまくいけば、これで各画像約3000枚程度集まったと思います。
プログミングなし!Google Cloud AutoML Visionに学習させよう
Google Cloud AutoML Visionはプログラミングなしでも、簡単に画像認識の機械学習が出来てしまうという優れものです。
学習部分だけでしたら、全てブラウザ上で出来てしまいます。
学習したい画像ファイルをアップロードし、ラベルづけをすることで簡単に学習モデルが作成できます。
今回はその学習モデルの作り方、それをAPIとして使用する方法を説明します。
まず、Google Cloud AutoML Visionを使用するためには登録が必要となります。下記の記事が詳しいので、以下から実際に登録してみましょう。登録が出来ましたら、引き続き先ほど集めた画像を学習させてみましょう。
これは例ですが、以下の枚数をファイルアップロードして学習させました。
義理チョコ2733枚
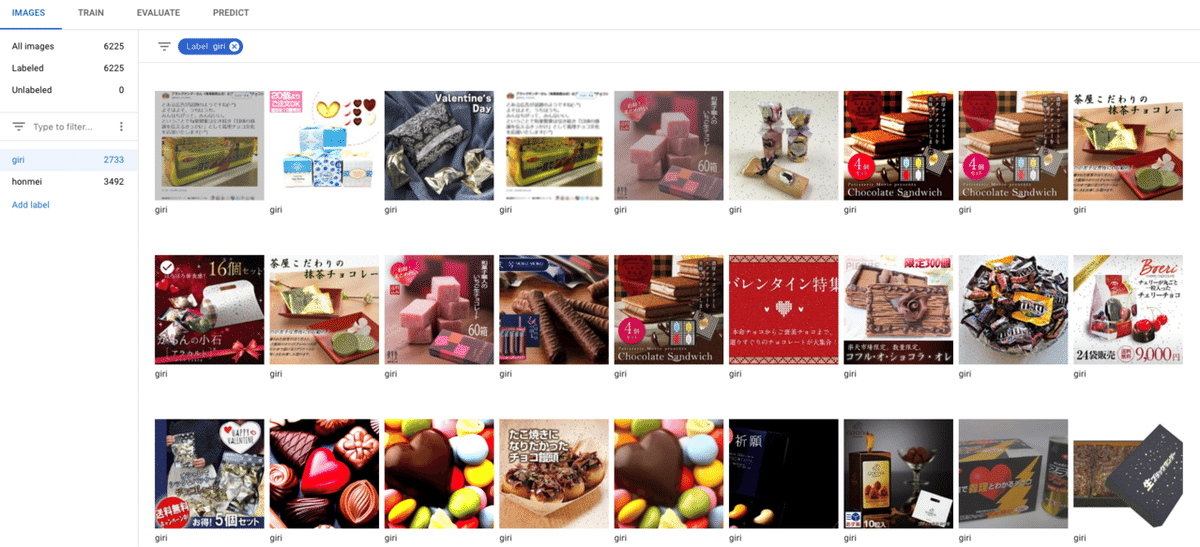
本命チョコ3492枚

義理チョコの判定結果例

本命チョコの判定結果例
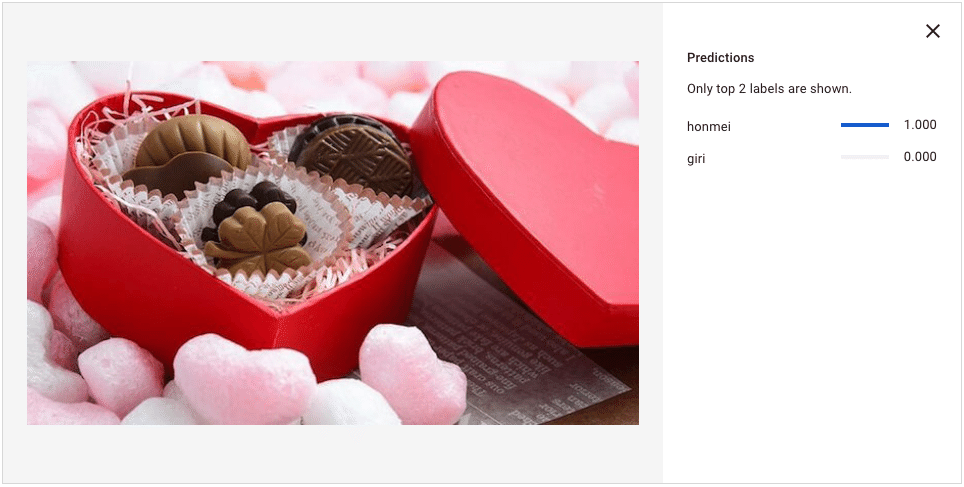
どうでしょうか?ここまでで学習モデルを生成できたと思います。
次は作成した学習モデルをAPIとして使う方法について説明します。
こちらに詳しい手順がまとまっていますので、まずは手順に沿って進めていってください。
サービスアカウントが作成されると、キーファイル(json形式)がダウンロードされますがこちらはあとで使いますので分かるところに保存しておいてください。
上記だけですと、上手くいかない場合があるので以下のコマンドも実行しておきましょう。
GCP用コマンドラインツール導入
# gcloudコマンドをインストール
$ curl https://sdk.cloud.google.com | bash
pyenv: python2: command not found
The python2 command exists in these Python versions:
2.7.11
# python2系 じゃないとインストールできないらしい
# コードは、python3でも動きます
$ pyenv global 2.7.11
# 再度インストール
$ curl https://sdk.cloud.google.com | bash
$ exec -l $SHELL
$ which gcloud
~/google-cloud-sdk/bin/gcloud
# gcp 認証
$ gcloud initgcloudを利用して、環境構築
# gcp 認証
$ gcloud auth login
# 既存のプロジェクトIDをセット
$ gcloud config set project project-id
# 新しいサービス アカウントを AutoML 編集者の IAM 役割に追加
# project-idは、前回、作成したproject-id
# 例 service-account-name -> service-account1@myproject.iam.gserviceaccount.com
$ gcloud projects add-iam-policy-binding project-id \
--member=serviceAccount:service-account-name \
--role='roles/automl.editor'
# サービス アカウントの作成時にダウンロードしたサービス アカウント キーファイルのパスに設定
$ export GOOGLE_APPLICATION_CREDENTIALS=key-fileライブラリをインストール
(ローカル環境で試さない場合はいらないが一応)
# gcp用ライブラリインストール
$ pip install google-cloud-automl参考記事
これで、APIを使用する準備は整いました。
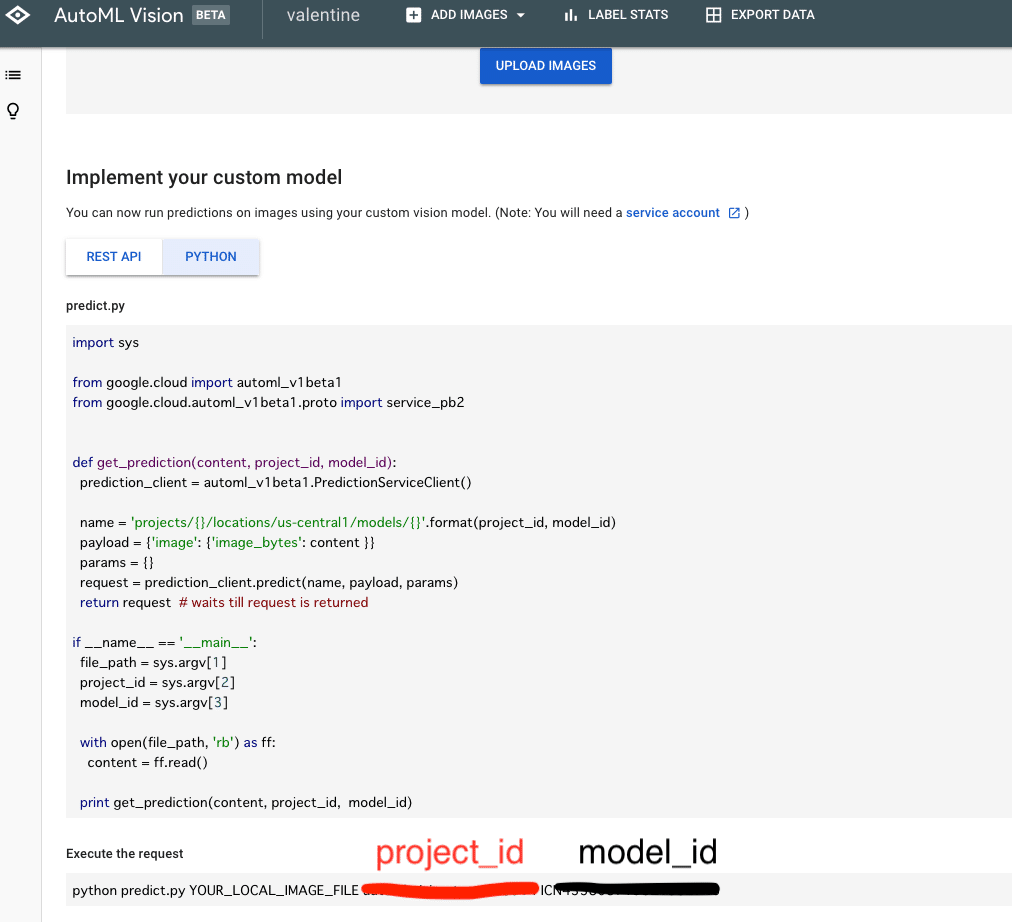
次に移る前に以下の情報が必要となるため用意しておきましょう。
PREDICTタブでPythonを選択し、下部のExecute the requestにもmodel_idとproject_idが記載されています。
・project_id(赤)
・model_id(黒)
・keyfile(ダウンロードしたjson形式の認証ファイル)
LineからGoogle Cloud AutoML Visionでチョコ判定してみよう
最後に学習させたGoogle Cloud AutoML VisionをAPIで使用して、Lineからチョコの画像を送ると判定し、その結果をメッセージとして返す部分を作成していきます。
まず最初にLINE APIの登録&設定とHerokuの登録&設定が必要となります。
以下の記事が詳しいので参考にして、Herokuの登録&設定まで完了させましょう。
LINE APIの登録&設定とHerokuの登録&設定が完了しましたら、設定ファイル&Pythonファイルの作成となります。
言語によって多少の差異はありますが、今回PythonとGoogle Cloud AutoML VisionでLINE Botを開発する時は作成すべき設定ファイルは4つあります。
・runtime.txt:Pythonのバージョンを記載
・requirements.txt:インストールするライブラリを記載
・Procfile:プログラムの実行方法を記載
・keyfile.json : AutoML Vision API使用時の認証に必要
それぞれについて説明していきます。
runtime.txt
runtime.txtは、Pythonのバージョンを記載するテキストファイルです。
そのため、runtime.txtの中に記載されているのは以下の1行だけです。
python-3.6.6requirements.txt
requirements.txtは、インストールするライブラリを記載するテキストファイルです。
importするライブラリはバージョンとともにここに記載しておきましょう。そうすると、デプロイした際に自動的にHerokuへインストールを行なってくれます。
今回は以下の3行を記載します。
Flask==0.12.2
line-bot-sdk==1.8.0
google-cloud-automlProcfile
Procfileには、プログラムの実行方法を記載します。
今回は、main.pyというpythonファイルを動かしたいので以下のように記載します。
web: python main.pykeyfile.json
(名前はそれぞれ違うためそのまま使用する)
サービスアカウントが作成時にダウンロードされたキーファイルです。
中身はそれぞれ違うので、保存したものを使いましょう。
※今回は直接あげていますが、設定として値を持たせてそれを参照した方がいいかもしれないですね。
そして、この4つの設定ファイルと同時に
main.pyもherokuにgit add, pushの流れでデプロイしますが、一部変更が必要となります。
# インポートするライブラリ
from flask import Flask, request, abort
from linebot import (
LineBotApi, WebhookHandler
)
from linebot.exceptions import (
InvalidSignatureError
)
from linebot.models import (
FollowEvent, MessageEvent, TextMessage, TextSendMessage, ImageMessage, ImageSendMessage, TemplateSendMessage, ButtonsTemplate, PostbackTemplateAction, MessageTemplateAction, URITemplateAction
)
import os
from io import BytesIO
from google.cloud import automl_v1beta1
from google.cloud.automl_v1beta1.proto import service_pb2
import random
# 軽量なウェブアプリケーションフレームワーク:Flask
app = Flask(__name__)
#環境変数からLINE Access Tokenを設定
LINE_CHANNEL_ACCESS_TOKEN = os.environ["LINE_CHANNEL_ACCESS_TOKEN"]
#環境変数からLINE Channel Secretを設定
LINE_CHANNEL_SECRET = os.environ["LINE_CHANNEL_SECRET"]
line_bot_api = LineBotApi(LINE_CHANNEL_ACCESS_TOKEN)
handler = WebhookHandler(LINE_CHANNEL_SECRET)
@app.route("/callback", methods=['POST'])
def callback():
# get X-Line-Signature header value
signature = request.headers['X-Line-Signature']
# get request body as text
body = request.get_data(as_text=True)
app.logger.info("Request body: " + body)
# handle webhook body
try:
handler.handle(body, signature)
except InvalidSignatureError:
abort(400)
return 'OK'
# MessageEvent
@handler.add(MessageEvent, message=TextMessage)
def handle_message(event):
str_list = ['チョコの写真を送ってね。。。あっ察し。。',
'義理チョコとは、一般には、恋愛感情を伴わない男性に対し、日頃の感謝の気持ちを込めて、またはホワイトデーの返礼を期待して、贈答するチョコレートのこと。',
'恋だね',
'愛、それはただ互いに見つめ合うことではなく、ふたりが同じ方向を見つめることである',
'人間が恋に落ちるのは重力のせいではない',
'恋に落ちると眠れなくなるでしょう。だって、ようやく現実が夢より素敵になったんだから',
'人は、誰かから深く愛されることで力を得て、誰かを深く愛することで勇気を得る',
'愛は約束、愛は思い出の品。一度与えられると、忘れ去られることはない。決して愛を失くしてしまわぬように',
'恋は目で見ず、心で見るもの。だから翼をもつキューピットは盲に描かれている',
'恋は踏み込むものじゃなく、落ちるものだ。真っ逆さまに。',
'バレンタインのチョコの数とモテ度は関係ない。',
'えーウソー?ウソー?今日バレンタイン?気づかなかったわー。今の今まで気づかなかったわー。',
'「バレンタイン」とかけまして、「円周率」とときます。 そのこころは、「3.14で答えが出るでしょう」',
'本命チョコとは、日本におけるバレンタインデーの日に女性が思いを寄せる男性に贈るチョコである。ボーイフレンドやその候補、夫等に贈られる。本命チョコは義理チョコと比べ、質が高く高価なものが選ばれる。本命チョコは、手作りされることも多い。']
message = random.choice(str_list)
line_bot_api.reply_message(
event.reply_token,
#TextSendMessage(text='「' + event.message.text + '」って何?')
TextSendMessage(text=message)
)
@handler.add(MessageEvent, message=ImageMessage)
def handle_image(event):
message_id = event.message.id
message_content = line_bot_api.get_message_content(message_id)
image_bin = BytesIO(message_content.content)
image = image_bin.getvalue()
request = get_prediction(image)
print(request)
score = request.payload[0].classification.score
display_name = request.payload[0].display_name
message = str(score*100)+'%の確率で、'
if display_name=='honmei':
message += '本命だね、おめでとう '
message += 'https://www.sugoren.com/search/%E6%9C%AC%E5%91%BD%E3%83%81%E3%83%A7%E3%82%B3'
send_message(event, message)
elif display_name=='giri':
message += '義理だね '
message += 'これでも読みな https://matome.naver.jp/odai/2151796984189198301'
send_message(event, message)
def send_message(event, message):
line_bot_api.reply_message(
event.reply_token,
#TextSendMessage(text='「' + event.message.text + '」って何?')
TextSendMessage(text=message)
)
def get_prediction(content):
project_id = '自分のプロジェクトID'
model_id = 'モデルID'
#prediction_client = automl_v1beta1.PredictionServiceClient()
# 環境変数にGOOGLE_APPLICATION_CREDENTIALSを設定していない場合は、以下の処理が必要
KEY_FILE = "***********.json"#自分のkeyfileを設定
prediction_client = automl_v1beta1.PredictionServiceClient.from_service_account_json(KEY_FILE)
name = 'projects/{}/locations/us-central1/models/{}'.format(project_id, model_id)
payload = {'image': {'image_bytes': content }}
params = {}
request = prediction_client.predict(name, payload, params)
return request # waits till request is returned
if __name__ == "__main__":
port = int(os.getenv("PORT"))
app.run(host="0.0.0.0", port=port)以下の部分のproject_id, model_id, KEY_FILEを自分のものに設定しておいてください。
def get_prediction(content):
project_id = '自分のプロジェクトID'
model_id = 'モデルID'
#prediction_client = automl_v1beta1.PredictionServiceClient()
# 環境変数にGOOGLE_APPLICATION_CREDENTIALSを設定していない場合は、以下の処理が必要
KEY_FILE = "***********.json"#自分のkeyfileを設定これでデプロイすることで、必要なファイルが全てHeroku上に揃ったので、うまくいけば動きます。
LINEから画像を送り、それを判定してメッセージを返す流れを説明します。
まずLINEから画像メッセージを受け取ると以下の処理が動きます。
@handler.add(MessageEvent, message=ImageMessage)
def handle_image(event):
message_id = event.message.id
message_content = line_bot_api.get_message_content(message_id)
image_bin = BytesIO(message_content.content)
image = image_bin.getvalue()
request = get_prediction(image)
print(request)
score = request.payload[0].classification.score
display_name = request.payload[0].display_name
message = str(score*100)+'%の確率で、'
if display_name=='honmei':
message += '本命だね、おめでとう '
message += 'https://www.sugoren.com/search/%E6%9C%AC%E5%91%BD%E3%83%81%E3%83%A7%E3%82%B3'
send_message(event, message)
elif display_name=='giri':
message += '義理だね '
message += 'これでも読みな https://matome.naver.jp/odai/2151796984189198301'
send_message(event, message)eventのメッセージ情報から画像データを取得しmessage_contentに入れます。
def handle_image(event):
message_id = event.message.id
message_content = line_bot_api.get_message_content(message_id)画像データをAPIに渡せるような形式に変更しget_prediction関数に引数として渡し判定します。
image_bin = BytesIO(message_content.content)
image = image_bin.getvalue()
request = get_prediction(image)判定した結果は以下のような形で返ってくるのでそこから欲しい情報を抽出します。
{
"payload": [
{
"classification": {
"score": 0.97885203
},
"display_name": "homei"
}
]
}欲しい情報(scoreとdisplay_name)の抽出は以下のように行います。
score = request.payload[0].classification.score
display_name = request.payload[0].display_name抽出した情報を元にしてメッセージを作成し、Lineに送信しています。
message = str(score*100)+'%の確率で、'
if display_name=='honmei':
message += '本命だね、おめでとう '
message += 'https://www.sugoren.com/search/%E6%9C%AC%E5%91%BD%E3%83%81%E3%83%A7%E3%82%B3'
send_message(event, message)
elif display_name=='giri':
message += '義理だね '
message += 'これでも読みな https://matome.naver.jp/odai/2151796984189198301'
send_message(event, message)Google Cloud AutoML VisionのAPIを呼ぶ関数です。最初の半分で必要な設定を行い、後半で画像をcontentとして渡すことで予測し、返ってきた判定結果をrequestとして返しています。
def get_prediction(content):
project_id = '自分のプロジェクトID'
model_id = 'モデルID'
#prediction_client = automl_v1beta1.PredictionServiceClient()
# 環境変数にGOOGLE_APPLICATION_CREDENTIALSを設定していない場合は、以下の処理が必要
KEY_FILE = "***********.json"#自分のkeyfileを設定
prediction_client = automl_v1beta1.PredictionServiceClient.from_service_account_json(KEY_FILE)
name = 'projects/{}/locations/us-central1/models/{}'.format(project_id, model_id)
payload = {'image': {'image_bytes': content }}
params = {}
request = prediction_client.predict(name, payload, params)
return request # waits till request is returnedその他、こちらは文章のメッセージが送られてきた場合の関数です。
名言をランダムで返すような処理を実装しています。
# MessageEvent
@handler.add(MessageEvent, message=TextMessage)
def handle_message(event):
str_list = ['チョコの写真を送ってね。。。あっ察し。。',
'義理チョコとは、一般には、恋愛感情を伴わない男性に対し、日頃の感謝の気持ちを込めて、またはホワイトデーの返礼を期待して、贈答するチョコレートのこと。',
'恋だね',
'愛、それはただ互いに見つめ合うことではなく、ふたりが同じ方向を見つめることである',
'人間が恋に落ちるのは重力のせいではない',
'恋に落ちると眠れなくなるでしょう。だって、ようやく現実が夢より素敵になったんだから',
'人は、誰かから深く愛されることで力を得て、誰かを深く愛することで勇気を得る',
'愛は約束、愛は思い出の品。一度与えられると、忘れ去られることはない。決して愛を失くしてしまわぬように',
'恋は目で見ず、心で見るもの。だから翼をもつキューピットは盲に描かれている',
'恋は踏み込むものじゃなく、落ちるものだ。真っ逆さまに。',
'バレンタインのチョコの数とモテ度は関係ない。',
'えーウソー?ウソー?今日バレンタイン?気づかなかったわー。今の今まで気づかなかったわー。',
'「バレンタイン」とかけまして、「円周率」とときます。 そのこころは、「3.14で答えが出るでしょう」',
'本命チョコとは、日本におけるバレンタインデーの日に女性が思いを寄せる男性に贈るチョコである。ボーイフレンドやその候補、夫等に贈られる。本命チョコは義理チョコと比べ、質が高く高価なものが選ばれる。本命チョコは、手作りされることも多い。']
message = random.choice(str_list)
line_bot_api.reply_message(
event.reply_token,
#TextSendMessage(text='「' + event.message.text + '」って何?')
TextSendMessage(text=message)
)以上で、おそらく出来たんじゃないでしょうか。
もしエラーが出てしまった場合はそのエラー文をググってぜひ解決してみてください。また修正要望等ありましたら、Twitterにご連絡頂けると幸いです。
皆さんが、これを基にしてオリジナルのアプリを作成されることを心待ちにしています。
もし何か作ってみた方がいましたらTwitterで教えていただけると嬉しいです!よろしくお願いします。