
【プログラミング初心者】が在庫を予測してみました

この記事は、週毎の在庫状況を分析、予測しまとめたものです。
前回「【プログラミング初心者】が売上を予測してみました」では週毎の売上分析・予測を、
vol.1 : データ整理編
vol.2 : 時系列解析編
vol.3 : 回帰編
3部構成でまとめました。
今回「【プログラミング初心者】が在庫を予測してみました」では在庫状況を分析し、未来の在庫を予測してみたいと思います。
【データクレンジング・成形】
excelデータの読み込み
まずは2018年から2020年までの3年分の週毎の売上データを読み込んでいきます。
import pandas as pd
df = pd.read_excel('/content/drive/MyDrive/センター各フロアー在庫状況(週末単位) (1).xlsx', sheet_name=0, header=1)
df
必要な'date'、'stock'の行だけを再度読み込みます。
df_all = pd.DataFrame( columns=['date','stock'] )
for date,stock in zip(df.iloc[:, 0],df["全フロアー計"]) :
if stock!=0:
date = df.columns[0] +"-"+ str(date)
tmp_se = pd.Series( [ date,stock ], index=df_all.columns )
df_all = df_all.append( tmp_se, ignore_index=True )
ためしに出力してみます。
df_all
2020年以前のデータも同じように読み込んでいきます。
def create_df(sheet, df_all):
df = pd.read_excel('/content/drive/MyDrive/センター各フロアー在庫状況(週末単位) (1).xlsx', sheet_name=sheet, header=1)
for date,stock in zip(df.iloc[:, 0],df["全フロアー計"]) :
if stock!=0 and str(stock)!="nan" and stock!="全フロアー計":
date = df.columns[0] +"-"+ str(date)
tmp_se = pd.Series( [ date,stock ], index=df_all.columns )
df_all = df_all.append( tmp_se, ignore_index=True )
return df_all週毎のデータのため、7日で区切ります。
df_all = pd.DataFrame( columns=['date','stock'] )
for i in range(7):
df_all= create_df(i, df_all)CSVデータに変換します。
df_all.to_csv("/content/drive/MyDrive/stock_csv")【時系列解析 / LSTMモデル作成】
LSTMモデルを用いて時系列解析をしていきます。
LSTMモデルは、アイデミープレミアムプランの「時系列解析Ⅱ(RNNとLSTM)、時系列解析Ⅲ(LSTM応用)」講座のなかで学習したモデルです。
LSTM(Long-Short Term Memory:長短期記憶ユニット)とは、RNN(Recurrent Neural Network:再帰型ネットワーク)の一つです。主に時系列データの解析に用いられ、例えば、翻訳など言語解析や音声の解析、売上予測などに多用されています。
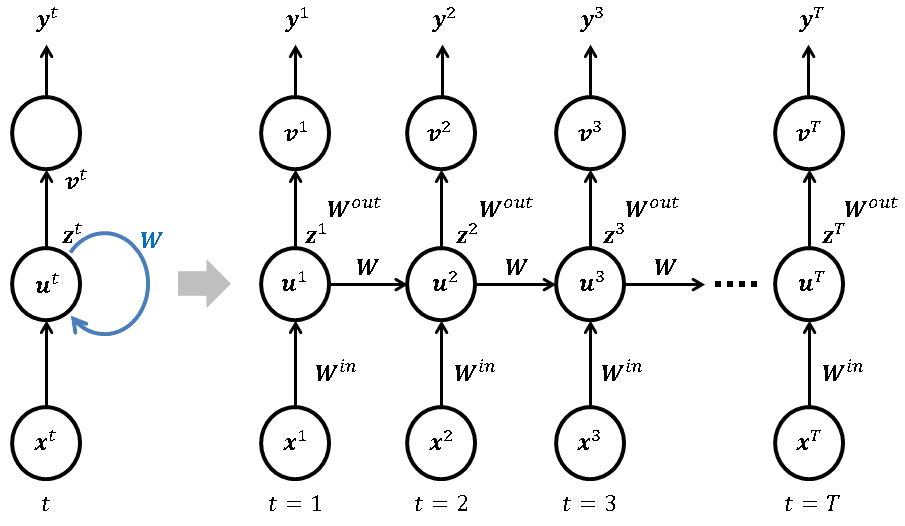
参照:https://nkdkccmbr.hateblo.jp/entry/2016/10/06/222245#%E3%83%AA%E3%82%AB%E3%83%AC%E3%83%B3%E3%83%88%E3%83%8B%E3%83%A5%E3%83%BC%E3%83%A9%E3%83%AB%E3%83%8D%E3%83%83%E3%83%88%E3%83%AF%E3%83%BC%E3%82%AFRNN
CSVデータの読み込み
CSVデータを読み込みます。
import pandas as pd
df= pd.read_csv("/content/drive/MyDrive/stock_csv", index_col=0)
df
月毎のデータにするため、4週で1セットにします。
import numpy as np
t=4
list_X=[]
list_y=[]
for idx in range(t, 358):
tmp=[]
for i in range(1, t+1):
tmp= tmp+[df.iloc[idx-i, 1]]
tmp=np.array(tmp)[:: -1]
list_X.append(tmp.tolist())
list_y.append(df.iloc[idx, 1])import numpy as np
X=np.array(list_X).reshape(354,4,1)
print(X.shape)
y=np.array(list_y).reshape((-1, 1))
y.shape(354, 4, 1)
(354, 1)
学習用データとテスト用のデータに分けます。
train_X= X[:350]
test_X= X[350:]
train_y= y[:350]
test_y= y[350:]モデル作成
モデルを作成します。
import tensorflow as tf
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense, LSTM, Dropout, BatchNormalization, Activation
from tensorflow.keras.optimizers import Adam
model = Sequential()
num_hidden_units = 128
len_sequence = 4
input_dim = 1
model.add(LSTM(
num_hidden_units,
input_shape= (len_sequence,1),
return_sequences=True))
#もう1層LSTM層を追加します
model.add(LSTM(units=30, return_sequences=False))
model.add(Dropout(0.5))
#Denseを加えます
model.add(Dense(256))
model.add(BatchNormalization())
model.add(Activation("relu"))
model.add(Dense(128, "relu"))
output_dim = 1
model.add(Dense(output_dim))
model.compile(loss="mean_squared_error", optimizer=Adam())
model.summary()
# 学習
history = model.fit( train_X, train_y, batch_size=1, epochs=64, verbose=1, validation_data=(test_X, test_y) )


二乗誤差の出力、精度確認
二乗誤差を出力し、精度を確認します。
import matplotlib.pyplot as plt
from sklearn.metrics import mean_squared_error
#予測値を出力します
y_pred = model.predict(test_X)
# 二乗誤差を出力します
mse= mean_squared_error(test_y, y_pred)
print("REG RMSE : %.2f" % (mse** 0.5))
%matplotlib inline
plt.figure()
plt.scatter(train_y,model.predict(train_X),label='Train',c='blue')
plt.scatter(test_y,y_pred,c='lightgreen',label='Test',alpha=0.8)
plt.title('Neural Network Predictor')
plt.xlabel('Measured')
plt.ylabel('Predicted')
plt.show()
loss=history.history['loss']
val_loss=history.history['val_loss']
epochs=len(loss)
plt.plot(range(epochs), loss, marker = '.', label = 'loss')
plt.plot(range(epochs), val_loss, marker = '.', label = 'val_loss')
plt.legend(loc = 'best')
plt.grid()
plt.xlabel('epoch')
plt.ylabel('loss')
plt.show()REG RMSE : 277037.21

lossもval_lossもグラフが張り付いてしまっています。
今回のデータ数350個程度ですとLSTMモデルに入れるには少なすぎたため、学習がうまく進まないようです。
【標準化】
精度が上がる可能性があるので、学習用データを標準化してみます。標準化は、アイデミープレミアムプランの「教師なし学習」講座のなかで学習した内容になります。各特徴量について平均が0、分散が1となるように変換します。こちらを標準化といいます。
標準化モデル作成
sklearnのStandardScalerのインスタンスを作成し、学習用データでfitさせます。fitさせた後、学習用データ、全データそれぞれに標準化処理を加えます。
from sklearn.preprocessing import StandardScaler
sc = StandardScaler()
train_X_sd = sc.fit_transform(train_X.reshape(-1,4))
test_X_sd = sc.transform(test_X.reshape(-1,4))学習用データとテスト用のデータに分けます。
train_X_sd = train_X_sd.reshape(-1,4,1)
test_X_sd = test_X_sd.reshape(-1,4,1)モデルを作成します。
import tensorflow as tf
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense, LSTM, Dropout, BatchNormalization, Activation
from tensorflow.keras.optimizers import Adam
model = Sequential()
num_hidden_units = 128
len_sequence = 4
input_dim = 1
model.add(LSTM(
num_hidden_units,
input_shape= (len_sequence,1),
return_sequences=True))
#もう1層LSTM層を追加します
model.add(LSTM(units=30, return_sequences=False))
model.add(Dropout(0.5))
#Denseを加えます
model.add(Dense(256))
model.add(BatchNormalization())
model.add(Activation("relu"))
model.add(Dense(128, "relu"))
output_dim = 1
model.add(Dense(output_dim))
model.compile(loss="mean_squared_error", optimizer=Adam())
model.summary()
# 学習
model.fit(
train_X, train_y,
batch_size=1,
epochs=64,
)


二乗誤差の出力、精度確認
二乗誤差を出力し、精度を確認します。
from sklearn.metrics import mean_squared_error
y_pred = model.predict(test_X_sd)
# 二乗誤差を出力します
mse= mean_squared_error(test_y, y_pred)
print("REG RMSE : %.2f" % (mse** 0.5))REG RMSE : 277041.52
標準化前の方が精度がいいという結果になりました。
【GRUモデル】
最後にもう1つ、GRUモデルを用いて時系列解析をしていきます。
GRUモデルは、アイデミープレミアムプランの講座のなかでは学習しないのですが、発展的な内容としてチューターの先生に提案いただいたモデルです。
GRUモデルとは、LSTMと同等のモデルとしての表現を保持しつつ、構造を簡単にすることで計算時間を削減することを目的に設計された手法です。
詳しく知りたい方はこちらをご覧ください。(https://keras.io/ja/layers/recurrent/)
モデル作成
from tensorflow.keras.layers import GRU
import tensorflow as tf
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense, LSTM, Dropout, BatchNormalization, Activation
from tensorflow.keras.optimizers import Adam
model_GRU = Sequential()
num_hidden_units = 128
len_sequence = 4
input_dim = 1
model_GRU.add(GRU(
num_hidden_units,
input_shape= (len_sequence,1),
return_sequences=True))
#もう1層LSTM層を追加します
model_GRU.add(GRU(units=30, return_sequences=False))
model_GRU.add(Dropout(0.5))
#Denseを加えます
model_GRU.add(Dense(256))
model_GRU.add(BatchNormalization())
model_GRU.add(Activation("relu"))
model_GRU.add(Dense(128, "relu"))
output_dim = 1
model_GRU.add(Dense(output_dim))
model_GRU.compile(loss="mean_squared_error", optimizer=Adam())
model_GRU.summary()
# 学習
model_GRU.fit(
train_X, train_y,
batch_size=1,
epochs=64,
)


二乗誤差の出力、精度確認
from sklearn.metrics import mean_squared_error
y_pred = model_GRU.predict(test_X_sd)
# 二乗誤差を出力します
mse= mean_squared_error(test_y, y_pred)
print("REG RMSE : %.2f" % (mse** 0.5))REG RMSE : 277042.54
時系列解析モデルにおいて、testデータに対しては、LSTMモデルの方が GRUモデルよりも優れているということがわかりました。
【まとめ】
「【プログラミング初心者】が在庫を予測してみました 」では、LSTMモデル・GRUモデルを用いて、時系列解析を行い、testデータに対しては、LSTMモデルの方が GRUモデルよりも優れているということがわかりました。
ただ今回時系列解析モデルに入れるにはデータ数が少なかったため、思うように学習が進まなかったのが残念です。
売上予測モデル同様に、まだまだ実務に使える精度にはなっていないので、今後さらにデータを加えたり、分析の方法をかえることで売上予測の精度を上げていきたいです。
今後は「【プログラミング初心者】が売上を予測してみました」で作成した売上予測モデルに、天候のデータを加えて、予測の精度が上がるかどうか試してみたいと思います。
「【プログラミング初心者】が在庫を予測してみました 」はこちらで終わりです。
もしよければ、「【プログラミング初心者】が売上を予測してみました(vol.1 : データ整理編)、(vol.2 : 時系列解析編)、(vol.3 : 回帰編)」もあわせてぜひご覧くださいませ。
最後まで読んでいただき、ありがとうございました。