
【画像を喋らせる】Stable Diffusion Web UIで口パク動画を作る方法【SadTalker】

今回は、Stable Diffusion Web UI (AUTOMATIC1111)で使える
画像を喋らせる拡張機能が想像以上にすごかったのでご紹介します
Stable Diffusionで使えるということは、もちろんどれだけ作っても無料です!!
私も色々喋らせるAIは触ってみましたが、有名なのは「HeyGen」とか「Creative Reality Studio」でしょうか。でも有料なんですよね・・。
私にはちょっと手が出なかったので、探してみたところ「Sadtalker」というStable Diffusion Web UI 拡張機能に出会いました。
実際触ってみて、やはり有料にはクオリティはかなわないです。
ですが、無料でいくらでも作れるメリットは大きいですね。
Youtubeでは実際にしゃべらせた動画もあるので、興味ある方は見てみてください。
注意
1.こちらは新しく出た技術のためまだ情報が少ないです。
何か問題が起こった場合、こちらでは責任は負えませんのでご注意ください。
2.アニメ系はよくエラーがでます。ハイクオリティなリアリティなイラスト画像であればエラーは出ませんでした。
今回の流れ
今回の流れは以下の通りです。
Web UI からSadtalkerをインストール
Sadtalkerモデルをダウンロード
webui-user.batを修正
FFmpegの導入
Sadtalkerを使って喋らせてみる
sadtalkerの導入
ここからはsadtalkerの導入になります。
導入にはすこし時間がかかります。
1.Web UI からSadtalkerをインストール
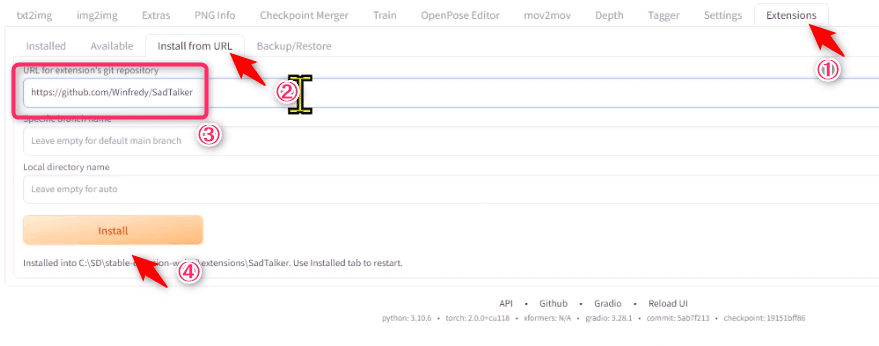
1.Stable Diffusion Web UIを起動し、「Extensions」へ移動します
2.「install from URL」タブに移動します
3.URL欄に以下のURLをコピーして貼り付けてください
4.installボタンを押してインストールしてください
下に「restart」と出れば完了です
https://github.com/Winfredy/SadTalker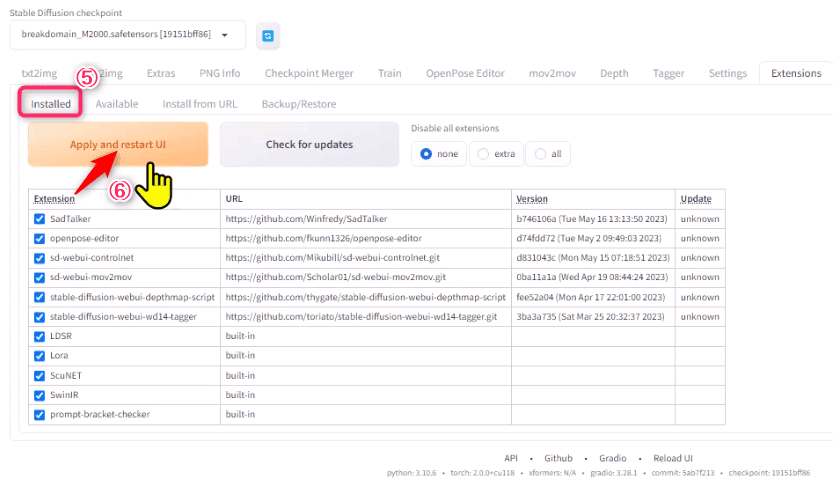
5.installedタブに移動します
6.Apply and restart UIをクリックするとWeb UIが再起動します
再起動に数分時間がかかります。
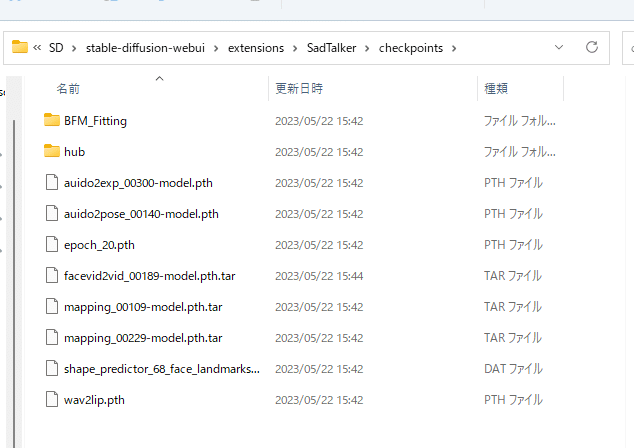
2.Sadtalkerモデルをダウンロード
まず、Sadtalkerのデータを入れるフォルダを作成します
「stable-diffusion-webui」-「extensions」-「SadTalker」フォルダ内に「checkpoints」フォルダを作成します

以下リンクからページを開き、すべてのデータをダウンロードします。
ZIPファイルが2つダウンロードされると思います。
容量が大きいので時間がかかりますが、待ってくださいね。
https://drive.google.com/drive/folders/1Wd88VDoLhVzYsQ30_qDVluQr_Xm46yHT

ダウンロードしたZipファイルを展開し、「checkpoints」フォルダにすべて入れてください。
3.webui-user.batを修正
「stable-diffusion-webui」フォルダ内にある「webui-user.bat」を開きます

以下の通り、chepointsフォルダのフォルダパスを追加します。
※自身の環境によってパスが変わるので注意してくださいね。
set SADTALKER_CHECKPOINTS=C:\stable-diffusion-webui\extensions\SadTalker\checkpoints
4.FFmpegの導入
以下リンクからFFmpegをダウンロードし、展開します。
展開したフォルダをCドライブの直下に移動し、フォルダ名を「ffmpeg」だけに変更しましょう
https://www.gyan.dev/ffmpeg/builds/ffmpeg-git-full.7z

7zファイルは特殊なので、展開するには「7-zip」というフリーソフトが必要です。
未導入の方は以下リンクからインストールしてください。
以下手順で、ffmpegのファイルパスを環境変数に登録します
System32フォルダ内にある「cmd.exe」を右クリックし管理者として実行します

コマンドプロントが起動したら、以下コマンドをコピペして実行してください
setx /m PATH "C:\ffmpeg\bin;%PATH%"成功:指定した値は保存されました。と表示されたら完了です。
5.sadtalkerを使って喋らせてみる
環境構築が終わったので、Sadtalkerを使って画像を喋らせてみましょう
StableDiffusion Web UIを起動すると「SadTalker」というタブができているので移動します
使い方を簡単に説明します
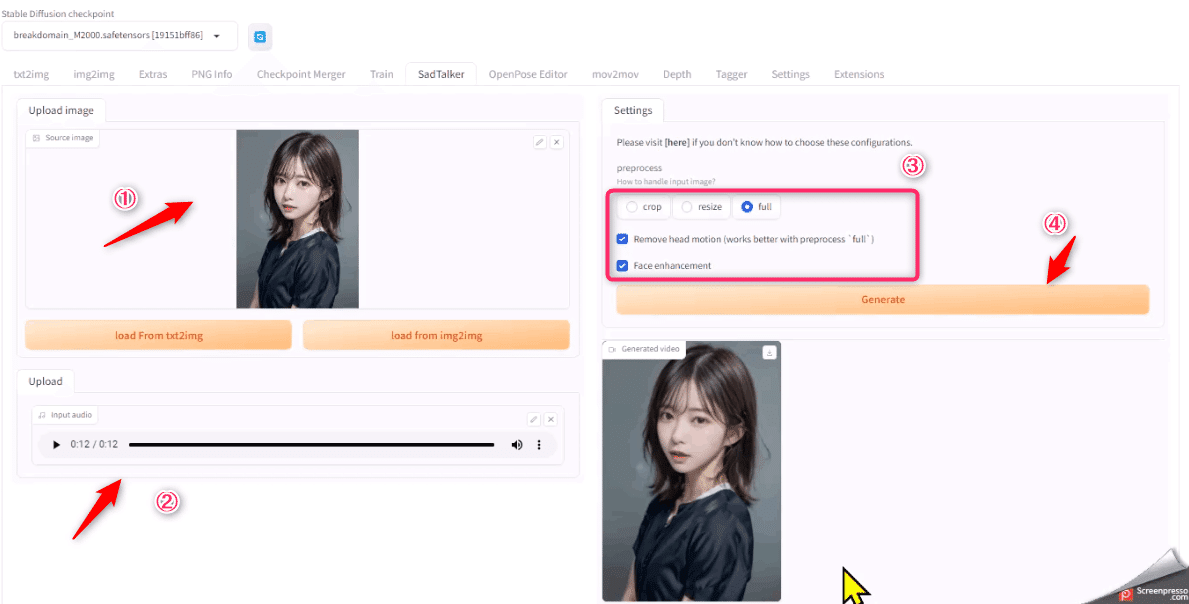
喋らせる画像をアップロードします
音声をアップロードします。※音楽などは入れないようにしてください
設定
crop,resize,fullとありますが、これは動画サイズになります。そのままのサイズで出力する場合はfullにします。
「Remove head motion…」fullを選ぶとチェックが入れられます。チェックを入れると顔の動きが少なくなります
「Face enhancement」のちぇくを入れると顔のクオリティがあがりますが、少し時間がかかります
設定ができましたら、Generateボタンで動画を生成します
TypeError: save_pil_to_file() got an unexpected keyword argument 'format
エラーが出てしまった場合は、画像が悪いかもしれません。
実写系の顔がはっきりした画像でも試してみてください。
まとめ
今回はStable Diffusion Web UI で画像を喋らせるAIをご紹介しました。
どうでしたか?
無料で使えるので、作り放題!
十秒くらいの動画であれば数分でできるので、使いどころはありそうですよね。
Youtubeでも解説しているのでよかったらのぞいてみてください。
この記事が気に入ったらサポートをしてみませんか?