Transformer

・機械翻訳の歩み:Encoder-Decoder Model ⇒ Transformer (Encoder-Decoder x Attention) ⇒ BERT
・TransformerーAttention is all you need:RNNを使わないで高い翻訳精度を達成した。Transformer主要モジュール

・Attention:二種類ある

AttentionとはQuery Q とKey K とValue V の3つのベクトルで計算される。各単語がそれぞれのQueryとKeyとValueの重みを持っている。
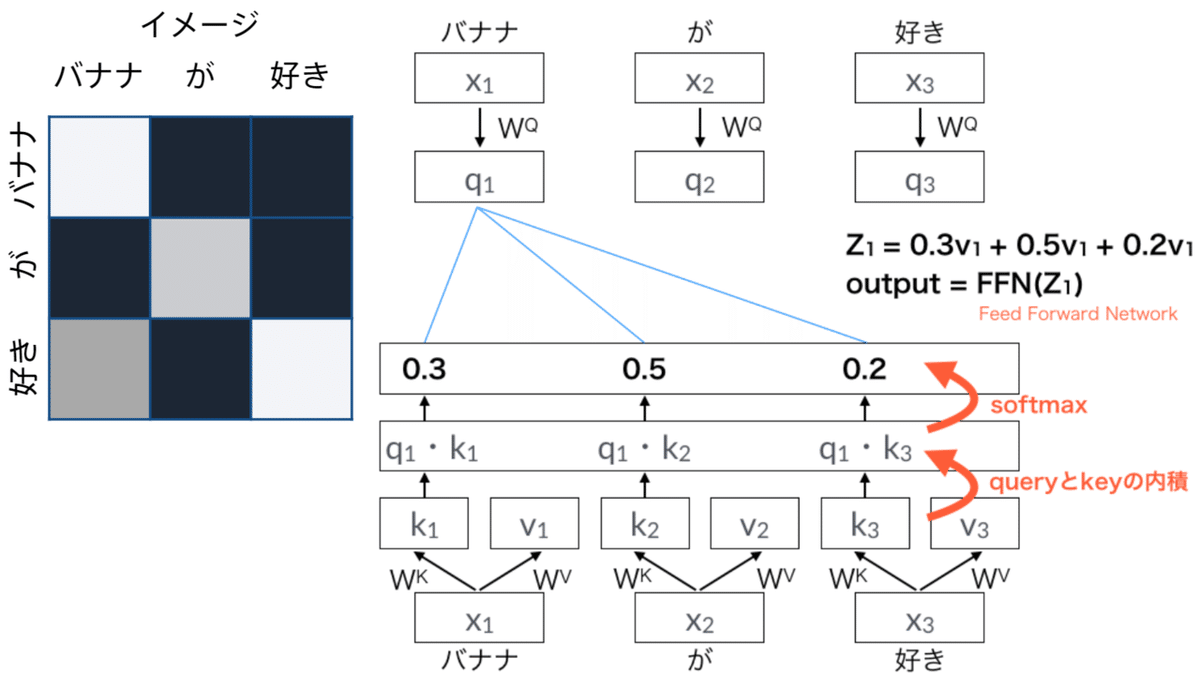
・Position Encoding:RNNを用いないので単語列の語順情報を追加する必要がある。

・Multi-Head attention:

・Scaled Dot Product Attention:

・Scale:Q と K の行列積においても平均 0 分散 1 となり、緩やかな勾配を持つソフトマックスが得られることが期待できるため、これらの行列積はKの次元数の平方根を割るだけ。
matmul_qk = tf.matmul(q, k, transpose_b=True) # (..., seq_len_q, seq_len_k)
# matmul_qkをスケール
dk = tf.cast(tf.shape(k)[-1], tf.float32)
scaled_attention_logits = matmul_qk / tf.math.sqrt(dk)・Mask(opt.):シーケンスのバッチ中のパディング(ゼロ詰め)された全てのトークンをマスクする。これにより、モデルがパディングを確実に入力として扱わないようにする。マスクは、パディング値0の存在を明記し、0の場所で1を出力し、それ以外の場所では0を出力する。

・Add & Norm:Add (Residual Connection) - Resnetの残差足し算と同じ 。Norm (Layer Normalization) - 各層においてバイアスを除く活性化関数への入力を平均0、分散1に正則化。
考察
・Transformerの基本モジュールを分解し、計算を追うことで理解が深まった。tensorflowの公式サイトにはもっと詳細な実装が載っていて非常にわかりやすい。TransformerはRNNのように時系列データ伝達をそのまま扱えないため、位置エンコーディングという手順が必要であった。Transformer自体は時系列データに特化したものではないので、CNNや画像処理にも応用できる。非常に強力なアーキテクチャーである。