
ソフトウェアのテストについて

こんにちは、フロントエンジニアのkokiです。
早速ですが、皆さんはソフトウェアが要求どおり実装できているかどうやって確認していますか?また、プログラミングする時にどんな仕様書を見ていますか?良いコード設計についてどんな基準を持っていますか?
テストツールのススメ
すべての操作パターンを動かして確認、エクセルで書かれた仕様書またはソースコードから推測、コード設計の派閥があるといった環境で働いていませんか?私もこういった労働環境を経験したことがあります。素直に言ってプロダクトを作ること以外にコミュニケーションや人間関係に疲れることがあった記憶があります。
疲れる理由
手動で要求を満たしていることを確認する
手動で行うので時間がかかり、同じ操作の繰り返しで飽きる
小さな修正でもすべての動作確認を行う必要がある(実際は面倒くさがってしていない事もあった気が…)
仕様書がエクセル等々である
納期を理由にメンテナンスされない(よくありました)
そもそもどこにあるか分からない(よくありました)
バージョン管理がプロジェクトごとに違うので、どれが最新か分からない(よくありました)
良いコード設計が人によって違う
いろんな考え・設計をキャッチアップするのは非常に大事なことですが、コードレビューする人によって意見が分かれたりすると中々進みませんよね
と言ったところでしょうか。
疲れない環境を目指す
フロントチームでは、こういった疲れを無くすためにCIによる機械的チェックを積極的に取り柄入れています。prettier、lint、テストなどのツールを導入しています。
手動で要求を満たしていることを確認する
手動で行うので時間がかかり、同じ操作の繰り返しで飽きる
→CI上でテストツールが確認するので作業しなくていい
小さな修正でもすべての動作確認を行う必要がある(実際は面倒くさがってしていない事もあった気が…)
→CI上でリリース前テストを自動化することにより、仕事が減る
仕様書がエクセル等々である
期日等の理由でメンテナンスされない
→テストツールを仕様書とするのでメンテナンスしないとマージできない
そもそもどこにあるか分からない(前職ではよくありました)
→基本的に近いところ(同じリポジトリなど)で管理しているので見つけやすい
バージョン管理がプロジェクトごとに違うので、どれが最新か分からない
→テストツールの実態は基本的にテキストベースなので、バージョン管理ができる
良いコード設計が人によって違う
いろんな考え・設計をキャッチアップするのは非常に大事なことですが、コードレビューする人によって意見が分かれたりすると中々進みませんよね
→prettier、lintでコードスタイルはほぼほぼ合わせることが出来る
→テストコードが十分に書けていればコード自体は後からリファクタリングできる
といった具合にプロダクトを届けることに必要なこと以外で疲れないようにしてますし、PRが単純(レビュワーの負担軽減)になるようにCI等の周辺環境を積極的に使っています。
今回はそういった工夫の中からテストツールについて紹介したいと思います。
テストツールの種類
※以下に紹介するコードはほとんどがJS、React, jestといったフロント界隈のものになります。あしからず。
Unitテスト
単体テストとも言われますが、主に関数単位行われるテストになります。
public class TestAdder {
public void testSum() {
Adder adder = new AdderImpl();
// 正の数を加算できる?
assert(adder.add(1, 1) == 2);
assert(adder.add(1, 2) == 3);
assert(adder.add(2, 2) == 4);
// ゼロニュートラル?
assert(adder.add(0, 0) == 0);
// 負の数を加算できる?
assert(adder.add(-1, -2) == -3);
// 正の数と負の数を加算できる?
assert(adder.add(-1, 1) == 0);
// 大きな数値の場合は?
assert(adder.add(1234, 988) == 2222);
}
}Reference: https://ja.wikipedia.org/wiki/%E5%8D%98%E4%BD%93%E3%83%86%E3%82%B9%E3%83%88
このようにinput,outputを検証することで関数の振る舞いを保証することができます。
弊社のコードで具体的に紹介すると、
// sample.ts
const isEmpty = (
value?: string | unknown[] | unknown | null
): value is
| null
| undefined
| ''
| []
// eslint-disable-next-line @typescript-eslint/ban-types
| {}
| { [key: string]: undefined } => {
return (
value == null ||
value === '' ||
(Array.isArray(value) && value.length === 0) ||
(typeof value === 'object' &&
(Object.keys(value as object).length === 0 ||
Object.values(value as object).every((value) => value === undefined)))
);
};
console.log(isEmpty("")) // true
console.log(isEmpty("test")) // false
console.log(isEmpty({})) // true
console.log(isEmpty({a: undefined})) // ①
console.log(isEmpty({a: undefined, b: null})) // ②
console.log(isEmpty(null)) // ③ trueisEmptyという非常にシンプルな関数名ですが、実装内容は結構複雑です。文字列や配列、オブジェクトなど様々なデータ型が空かを一つの関数で判定しています。
ここで問題です。①、②の出力はどうなるしょうか。
実装内容を見るといくつもの演算子が使われていますが、object型のときに、propertyキーの数と値を見て判定していることが分かりますが、てパッと見ただけでは分かりませんよね。
また、③の結果をみれば、実装コード内最後の === undefined という厳密な比較で本当にいいのでしょうか? == nullのほうが振る舞いの一貫性があるように思えますよね。これは意図して書かれているものなのでしょうか?
これらに回答できる形で弊社では以下のようにテストコードを書いています。
// jest
describe('isEmpty', () => {
it('nullの場合にtrueを返す', () => {
expect(isEmpty(null)).toBeTruthy();
});
it('undefinedの場合にtrueを返す', () => {
expect(isEmpty(undefined)).toBeTruthy();
});
describe('string', () => {
it('""の場合にtrueを返す', () => {
expect(isEmpty('')).toBeTruthy();
});
it('"foo"の場合にfalseを返す', () => {
expect(isEmpty('foo')).toBeFalsy();
});
});
describe('object', () => {
it('objectが空の場合はtrueを返す', () => {
expect(isEmpty({})).toBeTruthy(); // ①の答え
});
it('objectに中身がある場合はfalseを返す', () => {
expect(isEmpty({ a: 'a' })).toBeFalsy();
});
it('objectのvalueが全てundefinedの場合は空とみなしtrueを返す', () => {
expect(isEmpty({ a: undefined, b: undefined })).toBeTruthy();
expect(isEmpty({ a: undefined, b: 1 })).toBeFalsy();
expect(isEmpty({ a: undefined, b: null })).toBeFalsy(); // ②の答え
});
});
describe('Array', () => {
it('Arrayが空の場合はtrueを返す', () => {
expect(isEmpty([])).toBeTruthy();
});
it('Arrayに中身がある場合はfalseを返す', () => {
expect(isEmpty([1])).toBeFalsy();
});
});
});テストコードを見れば、①、②の出力結果に関して実装内容を見る事無く、答えが分かります。また、=== undefined としていたのも、意図して行われているということが②の答えから分かります。
isEmpty のように論理和演算子(||)を多用していると、どうしても可読性が低くなり必要以上に実装が複雑に見えがちですが、単体テストを書くことでPRでもレビューしやすいですし、可読性を理由にリファクタリングを要求する必要性もなさそうです。
Integrationテスト
Integrationテストとは、複数のユニットを使って構築された機能をテストするものになります。単体テストとは違いAPIでエラーが起きた時にエラーメッセージを適切に表示しているか?などをテストしていくことになります。
※非常にわかりやすい記事があったので、サンプルコードと共に転載します。
import * as React from 'react'
import {render, screen, waitForElementToBeRemoved} from 'test/app-test-utils'
import userEvent from '@testing-library/user-event'
import {build, fake} from '@jackfranklin/test-data-bot'
import {rest} from 'msw'
import {setupServer} from 'msw/node'
import {handlers} from 'test/server-handlers'
import App from '../app'
const buildLoginForm = build({
fields: {
username: fake(f => f.internet.userName()),
password: fake(f => f.internet.password()),
},
})
// integration tests typically only mock HTTP requests via MSW
const server = setupServer(...handlers)
beforeAll(() => server.listen())
afterAll(() => server.close())
afterEach(() => server.resetHandlers())
test(`logging in displays the user's username`, async () => {
// The custom render returns a promise that resolves when the app has
// finished loading (if you're server rendering, you may not need this).
// The custom render also allows you to specify your initial route
await render(<App />, {route: '/login'})
const {username, password} = buildLoginForm()
userEvent.type(screen.getByLabelText(/username/i), username)
userEvent.type(screen.getByLabelText(/password/i), password)
userEvent.click(screen.getByRole('button', {name: /submit/i}))
await waitForElementToBeRemoved(() => screen.getByLabelText(/loading/i))
// assert whatever you need to verify the user is logged in
expect(screen.getByText(username)).toBeInTheDocument()
})The test below renders the full app. This is NOT a requirement of integration tests and most of my integration tests don't render the full app. They will however render with all the providers used in my app (that's what the render method from the imaginary "test/app-test-utils" module does). The idea behind integration tests is to mock as little as possible. I pretty much only mock:
1. Network requests (using MSW)
2. Components responsible for animation (because who wants to wait for that in your tests?)
IntegrationテストのUnitテストとの違いはモックをできるだけ少なくしApp全体をテストしていくことが前提だとかかれています。またUnitテストとは違い実行時間が長時間に及ぶことがある点が特徴的です。そのため、単体テストの数^2にならないように注意する必要があります(後で記載するShift-leftパターンなどの考え方を元にテスト数は調節しましょう)
E2Eテスト
IntegrationテストはHTTPリクエストをモックして検証を行いましたが、E2EはEnd to Endの言葉通り、フロント→API→DBまですべてのリソースを含めた検証になります。そのため、ユーザーストーリーに沿ったテスト(商品Aをかごに入れて→決済→決済メールを送るなど)を十分に行うことはできません。
弊社ではCypressというオープンソースツールでE2Eテストを行っています。下記のように実際のブラウザ操作を行い検証していきます。
CypressはWebアプリケーションに特化したツールでwindowオブジェクトなどにもアクセスやリクエストのモックなどが出来るため、あらゆるテストケースに対応しやすく、書き味はjestやjQueryを書いたことある人ならほとんど混乱せずに書けるようになっています。
it('受験番号:半角英数字バリデーション', () => {
// cy.getはjQueryの$(...) と同様のセレクターでDOMを取得
cy.get('[data-testid="examinee-number-input"]').type('あああ');
cy.get('.examinee>div.errors').contains('半角英数で入力して下さい。');
});E2EテストはUnitテストでカバーできない部分に関して強いデグレーションを発揮しますが、書くべきユーザーストーリーの洗い出しやCI上での実行基盤構築、機能追加ごとにメンテナンスするコストなどUnitテストに比べて導入コストや保守コストが高いというデメリットもあります。
そのため、導入目的などを明確にしておき、メリット・デメリットをチーム内でしっかり議論しておく必要があります。
ビジュアルテスト
単体テストとE2Eテストは機能に関するデグレーションは検知しますが、スタイルのデグレーション(レイアウト崩れやpx単位のズレ)については検知してくれません。
最近のフロントエンド開発はコンポーネント化により再利用性が高まりましたが、共通化されたコンポーネントのスタイルを変更した場合の影響チェックは結構大変です。大幅なレイアウトやカラー変更ならまだしも、数px単位の微修正になると差分を確認するだけでも結構大変です。
弊社ではStorybook×Chromaticを使ったビジュアルテストを導入しています。
下記(良いサンプルが無かったので、公式から持ってきました)のように、Baseline(メインブランチ)と作業ブランチとDiffがあれば検知してくれます。

結局どのテストをやれば良いのか
いろんなテストを紹介しましたが、結局どのテストをやれば良いのか?という疑問がある方に向けて、私はまずUnitテストから試してみるのをおすすめします。
理由としてはUnitテストは導入コストと得られるメリットが大きいからです。
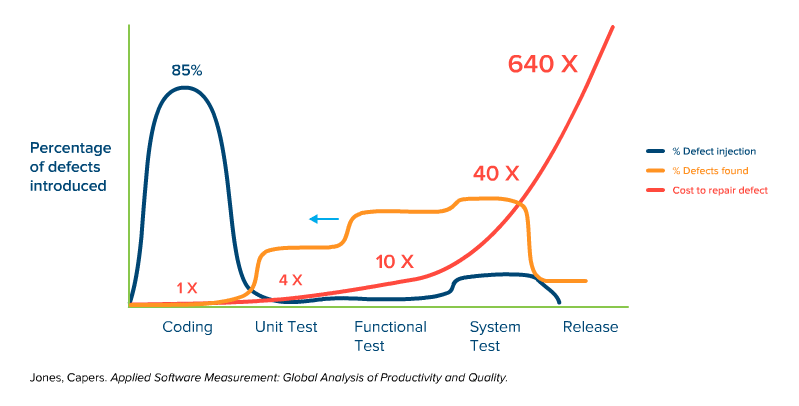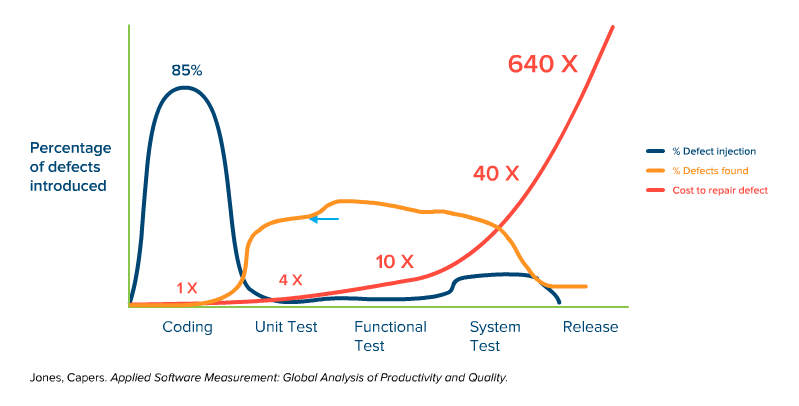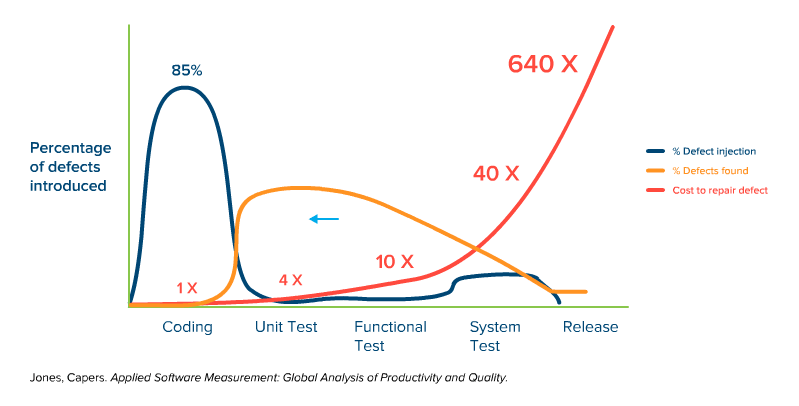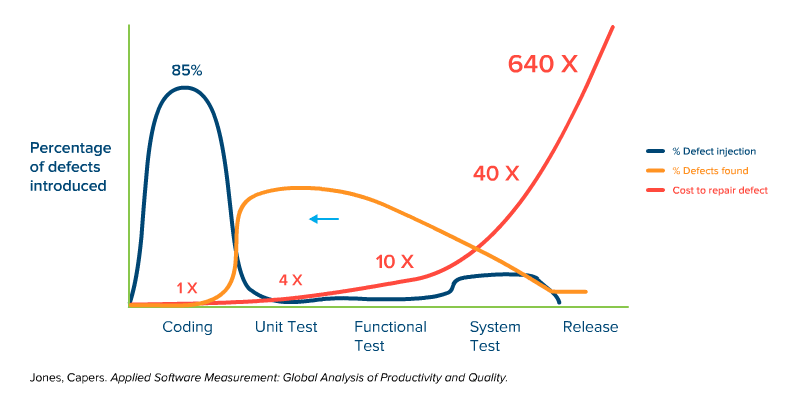
上の図はアジャイルやDevOpsといった開発手法でよく見られるShift-left testingモデルの「バグを作るタイミング(青線)とバグに気づくタイミング(オレンジ)と改修コスト(赤線)」を表したグラフです。
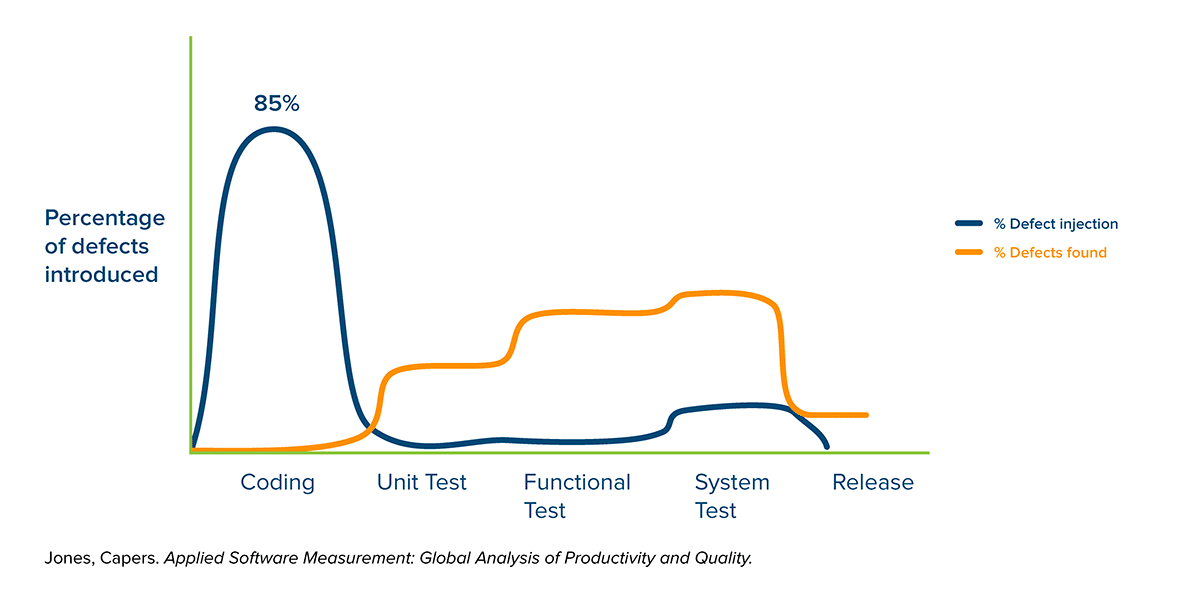
面白いことにバグは実装の初期段階で産まれますが見つけるのはSystemテスト(デモができる完成度)に旬を迎えます。

もちろん、改修コストはリリース直前に見つけるほうが高い値が付きます。リリース前は新規機能追加よりも既存コードの修正のほうが多いのではないでしょうか?Unitテストを書くことで余裕のある初期段階でコード改修ができます。逆にいうとUnitテストはプロダクトの初期から書く必要があるので注意してください。
また、Unitテスト、Integrationテスト、E2Eテストの物量は下記のピラミッド型になっていることが望ましいといわれています。

Integrationテストは詐欺という記事にも書かれていますが、IntegrationテストやE2Eテストは実行に時間がかかってしまい、Feedbackを得るのに時間がかかるだけでなく、E2Eなどはデモが出来るレベルまでプロダクトが完成していないとテストできません。E2Eを導入する予定だからUnitテストはいらない!という考え方は結局は先程のグラフと同じパターンにもなってしまうので、どこに力を入れるかのバランスはこのピラミッドを基準にすると良いと思います。
いい意味でも悪い意味でもテストはリソースを使うので、どこにどれだけリソースをあて、プロダクトにはどんなバグや不安要素があるか。Shift-left testingのようなプロダクト運営をするために、テストを書いて誰にどんな利益をもたらすかをチーム内でしっかり腹落ちさせておきましょう。
この記事が、みなさんのCodingOfLifeがより良いものになるきっかけになれば嬉しいです。