
生成AIでスピフルの英語添削を支える仕組み

こんにちは、プログリットでエンジニアをしているKokiです。
先日、「スピフル」をリリースしました!
スピフルは、口頭英作文&1分間スピーチというトレーニング方法を使ってスピーキング力を鍛える英語学習アプリです。
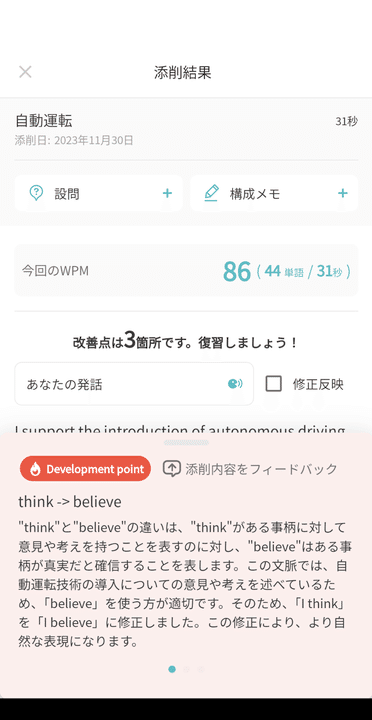
スピフルで1分間スピーチを録音して提出すると1分ほどで添削され上記のような画面で添削内容を確認でき、文法ミスやより自然な表現を提案してくれます。
1分間スピーチとは、テーマに合わせて1分間発話するアウトプットトレーニングです。スピーキングに特化してアウトプットの練習ができる上、自分のスピーチを振り返り復習することで、表現や文法などの知識の獲得も行えます。
この添削処理にOpenAIのGPT API(以下、GPT API)を使っているのですが、安定した添削を提供するには色々と工夫が必要でした。
今回は工夫した点を交えながらスピフルを紹介させてください。
裏側の仕組み
早速ですが、スピフルのアーキテクチャはこのようになっています。

WebアプリケーションをAWS上で開発するのであれば一般的なアーキテクチャかなと思いますが、変わった所としてGPT APIとやり取りする部分をLambda(Step Functions)で実装しました。
というのも、スピフルの開発期間はおよそ半年ですが、その間にもベータテストを3ヶ月ほど実施し実際に数十人のお客様に利用していただき、添削についてのフィードバックを頂きながら開発を進めました。
その頃はプロンプトの書き方の問題などで添削の精度や成功率が低いため人(CSメンバー)を介して添削を行い、一定の質を担保し失敗したときに再実行を行っていただいていました。
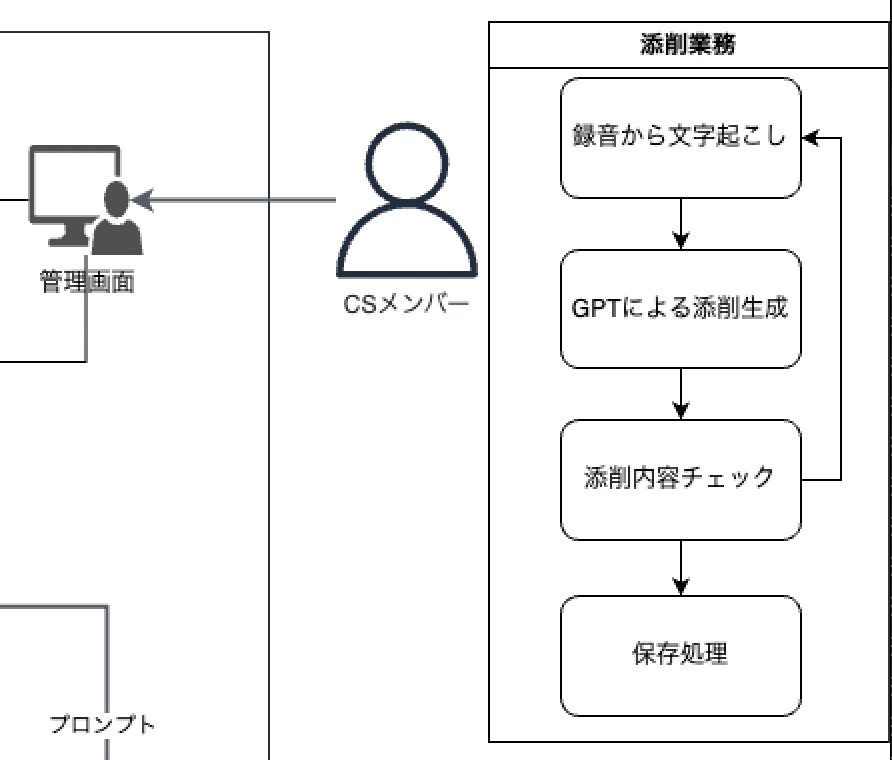
全体の流れとしては上図の通りで、お客様から1分間スピーチの録音提出→添削業務(文字起こし→GPT APIによる添削生成→チェック→保存処理)→お客様へ添削を返却。といったものです。
Lambda(Step Functions)を使ってよかったこと
人を介したおかげもあって、プロンプト改善につながるようなフィードバックを社内からたくさん頂きましたがその際にStep Functionsの実行履歴がとても役に立ちました。

このように添削生成の実行履歴を閲覧できるので、フィードバックや不具合報告時に調査に見通しが立てやすかったです。
また、Step FunctionsのNameの末尾はリトライ回数になっているのであまりにもリトライ回数が多い添削履歴を能動的に見に行けたり、事業計画の原価計算でも一役買いました。
GPT APIを用いた開発は初なのでメトリクス設計やログ設計をひとまず後回しにしたので、コード改修がし易いベータ期間でした。
GPT APIに任せっきりではない
ベータ期間にいろんな添削パターンを見ていると徐々にGPT APIが苦手とする部分が見えてきました。
実際にお客様へ届ける内容は
指摘箇所
指摘理由
の2つですが、GPT APIにすべて生成させてお客様に届けているわけではありません。

お客様に届けるまで3つのステップを踏んでおり、GPT APIを使わない箇所もあります。
上から
- CorrectText
- お客様の英語をGPT APIに添削させます
- Categorize
- 添削内容をカテゴライズ、評価してより英語学習上重要なDevelopmentポイントを3つに絞っています。
- Reason
- なぜその添削を行ったのかであったり、現状だとネイティブがどう感じてしまうかをGPT APIに生成しています
という流れでCategorizeステップではGPT APIを用いずに処理を行っています。
というのも、プロンプトに「英語学習上優先度の高い上位3つに絞ってください」と記載しても、どうしても冠詞(theやa)の抜けといったスピフルでは重要視していない箇所を返してくるためです。
詳細なロジックは割愛しますが、英語学習の核となるので細かい評価ロジックを独自に組み、効率的な学習はGPT APIを使わずに提供しています。
今のメトリクス設計

ベータ期間を経て添削サービスが安定稼働しているかを知るために必要なメトリクスは下記を取るようにしました
1添削あたりのプロンプト使用量
添削ごとのJSONバリデーション種別
1添削あたりのリトライ数
1添削あたりのプロンプト使用量
サービスの特性上、お客様のWPMが増えるほどプロンプトの使用量も増えるので、それは嬉しいことなのですが稀にGPT APIから異常文字列を返されることがあります。
例えばですが「この部分を適切な表現に修正しま修正しま修正しま…」といったようにテキストを繰り返してしまうという事象がありました。
こういった添削はお客様に返却されないようにチェック処理(Tokenizeして重複カウントに閾値を定め除くようにしています)を行っていますが、お客様に届かない分知る機会もないので、エンジニア側で目検はできるようにメトリクスを取るようにしました。
WPMとはword per minuteの略で、1分間に読めるワード(単語)数のことです。英語を読む速さの指標として広く知られています。黙読、音読どちらでも使えます。
例えば、WPM80の場合は1分間に80単語読めることを意味します。WPM250なら1分間に250単語です。
つまり、WPMが高いほど速く英語を読むことができるということです。
添削ごとのJSONバリデーション種別
添削UIで分かりやすいレイアウトを行うにはGPT APIの出力結果を構造化することが非常に重要です。
この画面を例に取るとthink -> believe は修正前箇所と修正後箇所として別々のカラムにDBに保存しており->は後付にして表現を後から変えやすくしています。
GPT APIにJSON出力させるのはLangchainのStructured output parserを使っていて、JSON文字列での出力にある程度の安定感をもたせることができましたが、細かい部分でGPT APIが100%正しい出力する保証はありません。
偶に想定外の出力により添削UIが崩れるという事象があったため、バリデーションを設定しリトライする仕組みを導入しました。 このバリデーションにはPythonのPydanicというライブラリが非常に便利だったので紹介させてください
class CategorizedCorrected(BaseModel):
index: int = Field(description="添削のインデックス")
original_text: str = Field(description="English text before correction")
original_point: str = Field(description="Corrected parts of the English text before correction")
@validator("original_point")
def original_point_must_be_in_original_text(cls, v, values):
# NOTE: 修正前後が同じ場合は指摘箇所なしと判定できる
if equal_texts(values["original_text"], values["corrected_text"]):
return ""
if (not v) or (v is None):
raise ValueError("original_point must not be empty")
if not values["original_text"]:
raise ValueError("original_text must not be empty")
if v not in values["original_text"]:
raise ValueError("original_point must be in original_text")
return v
async def generate(llm: ChatOpenAI, messages, parser: BaseOutputParser) -> CategorizedCorrected:
response = await llm.agenerate(messages=messages, response_format={"type": "json_object"})
text = response.generations[0][0].text
result = parser.parse(text)
data = CategorizedCorrected(result['data'])
return dataといった感じコードを組みバリデーションエラーがThrowされたらリトライとCloudwatchにログ出力させる仕組みを導入しました。
1添削あたりのリトライ数

今は平均で1.4回程度のリトライで添削を返却できていますが、ときより添削できないケースも存在します。
上記のバリデーションは各ステップごとで行われるバリデーションですが、それぞれ上限を設定しています。お客様が収録される英文によってはどうしても安定しないパターンもあるので、それらは包括的にリトライする仕組みを用意しました。
しかし、前述の再実行などで改善が見られず添削が行えなかったものに関しては、数十分に一回のバッチ処理で検知しエラー通知を送り人が添削を行うようにしています。
ベータ期間中は人の手で添削サービスを実行していましたが、これにより今は完全自動化で深夜にも添削をお届けすることが可能になりました。
まとめ
以上が1分間スピーチ添削を支える仕組みになります。
まずはこのシステムが構築できるまで、ベータ期間中のお客様やプロンプトアイディアなどフィードバックをたくさんの方に頂きながら作り上げたられたのが、とても楽しい一時で皆様に感謝してもしきれない思いです。
次回の予告です。リリースして間もないですが、早くも添削V2といえる改善を実装中です。半年かけてようやくGPT APIの得意不得意が分かってきて、より高品質な添削をお客様に提供できる様になりそうです。
V2には形態素解析やLCS(最長共通部分列)っぽいものであったり、複雑なロジックを実装しているので、添削V2リリース後はぜひそちらも執筆したいと思いますので、お楽しみいただければと思います。
ここまで読んでくれてありがとうございます。
プログリットの成長を加速させる開発のお仕事を担う仲間を募集しています!
プログリットでは、プロダクト開発のメンバーを募集しています!
「世界で自由に活躍できる人を増やす」というミッションに共感してくださる方、組織の中でお互いに切磋琢磨しながら成長していきたいという方は、ぜひカジュアル面談でお話しましょう!

この記事が気に入ったらサポートをしてみませんか?