
外国語英会話補助アプリをつくろうとしてGoogle Speech-to-Text APIの認識に成功したが、ChatGPT APIの扱いで挫折した件。

最近のChatGPTは、音声をオフにしないと勝手に(日本語でも英語でもなんでも)自分の返答を話し始めてしまう。また、チャット右横の音声モードを使うと、こちらが日本語を話すと日本語で返事をし、英語で話すと英語で返事をしてくる。ただ、その間、音声の文字はあらわれない。そして会話終了後はじめて、(自分の音声部分はだめだが)ChatGPTの返答部分だけは文字化されてみれる。
残念ながら、現在のところChatGPT自体には音声認識機能が直接組み込まれていないのだ。そのため、音声入力を直接この場で使うことはできない(将来的には可能になるだろう、とのこと)。
例えば、ChatGPTで英会話練習をはじめて、こちらが英語につまったとき、ChatGPTはじっと待ってくれる。ここで、英語で、こういうことを言いたいけど英語でなんというの?とか聞いてみたいのだが、それも英語ではなかなかでてこない。思わず、日本語で返答すると、ChatGPTから日本語で返答が返ってきて、英会話練習にならない。
現在のところは、外部ツールを使うことで、音声から文字に変換し、それをコピー&ペーストしてここで会話に活用する方法が現実的かもしれない。たとえば、スマホでマイクを使い、日本語を話すとその内容がテキストに変換される機能(iOSやAndroidに標準搭載)を使う。音声入力で生成されたテキストをさらに翻訳機能で翻訳し、それを読んで会話にとりいれる。これが、スムーズにおこなえるような専用アプリがあると外国語会話練習にいいなと思う。
今回、(ぼくがスマホをもたないということもあって)PC上で、①「Google Speech-to-Text API」を使って、音声データをリアルタイムで(日本語を)テキスト化し、②そのテキストをAPI経由でChatGPTに送信してその英訳をうけとるという仕組みを作ることに挑戦してみた。
① Google Speech-to-Text APIの認識
今回のプロジェクト作成にもChatGPTのお世話になった。提案された、アプリのファイル構造は、単純。
Project (ConvKojij)/
├── app.py
├── index.html
├── convkoji-xxxxxxxxx.json
├── uploads/ (自動生成されます)
ただ、app.pyには、 Flask フレームワークを使う。
その理由と必要性について。
1. フロントエンド(index.html)とバックエンド(app.py)の分離
index.html の役割: ブラウザで動作するユーザーインターフェース(UI)を提供し、マイクの音声入力や結果表示を行う。
app.py の役割: サーバーとして動作し、音声データを処理し、Google Speech-to-Text API や ChatGPT API への橋渡しを行う。
この分離により、以下の利点が得られます:
柔軟性: UI とサーバー処理を独立して開発・更新可能。
再利用性: サーバー側のロジックを他のプロジェクトやインターフェース(モバイルアプリ、他のブラウザアプリなど)に再利用可能。
2. Flask の選択理由
シンプルで軽量
Flask は軽量な Python のウェブフレームワークで、必要な機能を簡単に追加できます。本プロジェクトのように、小規模な API サーバーやプロトタイプを迅速に構築するのに適しています。
REST API の構築が容易
Flask を使うと、音声ファイルを受け取る /process エンドポイントや音声ファイルを配信する /uploads/<filename> エンドポイントのような REST API を簡単に実装できます。
Google Speech-to-Text API や ChatGPT API を扱うロジックを Flask に集中させ、フロントエンドからリクエストを送る仕組みがシンプルに構築できます。
3. Flask を使う必要性
a. ローカル環境でのサーバー構築
Google Speech-to-Text API は HTTP リクエストを介して通信します。ブラウザの JavaScript(fetch)から直接 Google Speech-to-Text API を呼び出すと、CORS(クロスオリジンリソースシェアリング)問題やセキュリティ上のリスクが発生する可能性があります。Flask を介することで、ブラウザから直接 API キーを操作せず、セキュアに処理が行えます。
b. バックエンドでの処理
フロントエンドでは音声データを収集し、それを Flask に送信。Flask で音声データの変換(LINEAR16 形式への変換)や Google Speech-to-Text API へのリクエストを行います。これにより、ブラウザでは処理が重すぎる(例えば音声変換)タスクを、Python の豊富なライブラリを使って処理できます。
4. Flask を使う利点
a. 簡単なデプロイとローカルテスト
Flask サーバーをローカルで簡単に実行でき、ブラウザからアクセスしてテスト可能。将来的にサーバーをクラウド(AWS, GCP, Herokuなど)にデプロイする際も、ほぼそのまま移行可能。
b. Python ライブラリとの統合
Python の豊富なライブラリ(google-cloud-speech, pydub, gtts など)を活用し、音声データの処理や API 呼び出しを効率的に実行できます。
Flask によるサーバー構築は、プロジェクトが拡張された場合にも対応しやすい。例えば、音声認識以外の機能(例えば翻訳機能やデータベースとの連携)を簡単に追加可能。REST API のエンドポイントを増やして機能を拡張しやすい。
*
あとは、ChatGPTとやりとりをして、ファイルの修正をしたり、不足しているモジュールをとりこんでいくだけだった。比較的苦労したのは、
1. Google Speech-to-Text API Keyについて
最初ぼくがAPIキーと勘違いしたAIza から始まるキーはGoogle Maps API Key や YouTube API Key などの単純なAPIキーだった。一方で、Google Speech-to-TextはサービスアカウントのJSONファイルを使う。
正しいキーの場合: .json ファイルで構成され、サービスアカウントの認証情報が含まれます。
サービスアカウントJSONファイルの取得手順
Google Cloud Console にログインします。
Speech-to-Text API を有効化します。
サービスアカウント を作成します。
IAM & 管理 > サービス アカウント から作成。
サービス アカウントに「プロジェクトオーナー」または「Speech-to-Text APIユーザー」権限を付与します。
サービスアカウントのJSONファイルをダウンロードします。
App.py内で、
os.environ["GOOGLE_APPLICATION_CREDENTIALS"] = google_key_pathと記入。具体的には、次のような、絶対パスを記入 os.environ["GOOGLE_APPLICATION_CREDENTIALS"] ="C:/Users/koji3/デスクトップ/ConvKoji_1/convkoji-xxxxxxxxx.json"
2.ffmpegのインストールについて
(注)処理の途中pydub を使って音声データを LINEAR16 に変換する。そして、pydubは内部で ffmpegというライブラリを使用するので,あらかじめインストールしておく必要がある。
ステップ 1: ffmpeg のダウンロード
公式サイトからダウンロード:
FFmpeg ダウンロードページ にアクセス。
Gyan.dev FFmpeg builds のページに移動。
「Release builds」セクションで、Windows 用のビルド「ffmpeg- release-essentials.zip」(例)をダウンロード。
ステップ 2: ZIP ファイルの展開
ダウンロードした ffmpeg-release-essentials.zip を任意のフォルダに展
開します。 例: C:\ffmpeg
展開後のフォルダ構造を確認します。C:\ffmpeg\bin\ffmpeg.exe が存
在することを確認。
ステップ 3: 環境変数 PATH に追加
環境変数の設定画面を開く:Windows の検索バーで「環境変数」と入力し、「システム環境変数の編集」を選択。
PATH に ffmpeg のパスを追加:
「システム環境変数」の「環境変数」をクリック。下部の「システム環境変数」セクションで「Path」を選択し、「編集」をクリック。「新規」をクリックし、以下のパスを追加します:C:\ffmpeg\bin
(注)ぼくの設定ではkoji3の下、C:\Users\ユーザー\koji3\ffmpeg\binにファイルをおかねばならなかった。
「OK」をクリックして設定を保存。
環境変数を更新後、新しいターミナル(PowerShell またはコマンドプロ
ンプト)を開きます(必要なら再起動)
ステップ 4: ffmpeg の確認
新しいターミナルを開き、以下を実行します:
ffmpeg -version
以下のようなバージョン情報が表示されれば成功です:
ffmpeg version <バージョン番号> Copyright ...
できたアプリは下記のよう。
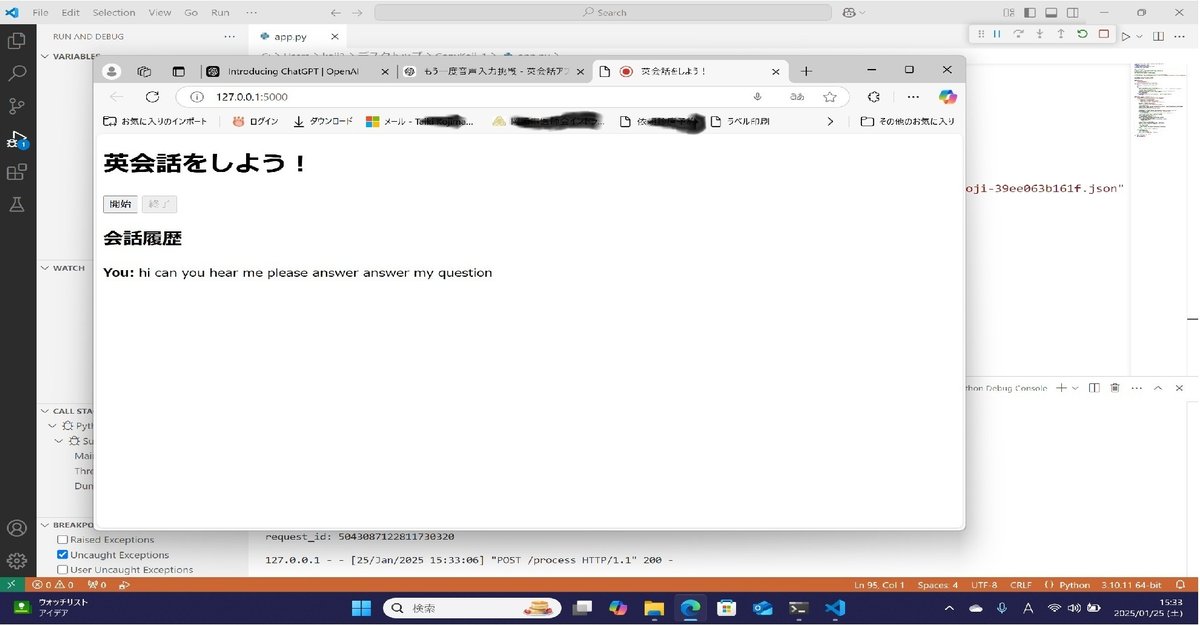
② そのテキストをAPI経由でChatGPTに送信してその英訳をうけとる
結論として、こちらは不成功。
これは、現在の openai ライブラリのバージョンが最新(1.0.0 以上)で、以前のインターフェース(例えば openai.ChatCompletion)が非対応となっているため発生。
ChatGPTみずから、最新の API インターフェース
openai.ChatCompletion.create を正しく使用する形式に変更するための修正版の app.py を作ったが、やはりエラー。
(ChatGPTでも、試行しないとChatGPT自身のことはわからない?)
旧バージョン(0.28.0)をインストールのしてOpenAI ライブラリを使用もできないわけでないが、旧バージョンの利用は、既存のコードやプロジェクトの互換性を保つための一時的な解決策。
最新バージョンでの移行が最善でAPIの互換性と新機能にアクセスできる、ということで、ここで今回は断念した。
(OpenAPIキーの取得は、比較的容易で、成書のとおりでスムーズだった)。