DiffusersベースのDreamBoothの精度をさらに上げる・augmentation編

※12/1 (v2):顔が見つからないと落ちるバグを修正しました。
はじめに
前回の記事の続きです。アニメ等のキャラクタを学習させるための記事になります。また環境整備が面倒なわりに効果は限定的ですので、それでもという方のみお試しください。
以下のツイートで紹介されていたAnime Face Detectorを使っています。
#Dreambooth #stablediffusion
— Izumi Satoshi (@izumisatoshi05) September 26, 2022
アニメ顔を認識して、いい感じに512x512に切り取ってくれるスクリプト。Dreambooth用に作った。テスト出来てないけど多分動く。余白白埋め方式と結果が変わるのかは気になるところ。
同じことができる既存の何かがあれば教えてください。https://t.co/PyZiNsbLTY pic.twitter.com/yxBbaPccaW
概要
あらかじめAnime Face Detectorを用いて教師用画像を前処理(顔検出など)します(スクリプトを用意してあります)。
顔のサイズを画像間で統一します。
顔が回転している場合、正立させます。
DreamBoothでの学習時に顔を基準にランダムに切り出し、augmentationします。
あわせて左右反転、色合いのaugmentationを行います。
顔検出を用いた画像の前処理は、DreamBooth学習用スクリプトだけでなく、他の環境での学習用の前処理も行えるようになっておりますのでどうぞご利用ください。
augmentationについて
augmentationは、ざっくりいうと学習時に学習データを微妙に変更することで見かけ上のバリエーションを増やし、より高精度、汎用的な学習を行うものです。Diffusers版のDreamBoothでは一切のaugmentationを行っていません。XavierXiao氏のStableDiffusion版DreamBoothでは左右反転のaugmentationのみ行われています。
機械学習ではaugmentationが当然のように行われているため、DreamBoothでもaugmentationを行い精度向上を狙います。
ただDreamBoothは教師データの枚数が少なくて済むことが元々の特徴でもありaugmentationは効果がない可能性があります。私の手元ではaugmentationを行うことによる悪化は特に感じられませんが、各自お試しいただければと思います。
なおaugmentationを行うと毎回VAEを用いた画像からlatentsへの変換が必要になるため、latentsのキャッシュと併用することができません。そのため使用メモリ量は増加しVRAM容量12GBでは動作しなくなります。
(事前にaugmentationを行い教師データを水増ししておく手法もあるのですが、今回は対応していません。)
環境整備
Build Tools for Visual Studio 2022のインストール
(Colab等Linux環境では不要です。)
Windows環境では、Anime Face Detectorが使用するライブラリが依存するライブラリがビルドが必要なためインストールします。ダウンロードページから下の方の「すべてのダウンロード」内の「Visual Studio 2022用のツール」を開き、「Build Tools for Visual Studio 2022」をダウンロードします。
起動するとインストーラが立ち上がりますので、「C++によるデスクトップ開発」にチェックを入れ、右側のチェックはデフォルトのままでインストールしてください(ディスク容量をかなり使います)。

仮想環境の作成とPyTorchのインストール
依存ライブラリが多いためStableDiffusionやDiffusersとは仮想環境を分けたほうが良いかもしれません。venv等で適切な仮想環境を作ります。
またAnime Face Detectorを入れる前にPyTorchとTorchvisionを入れておきます(そうしないとエラーになりました)。お使いのCUDAバージョンに合わせたバージョンを入れてください(私はCUDA 11.6、PyTorch 1.12.1、Torchvision 0.13.1で動かしています)。
Anime Face Detectorのインストール
Anime Face Detectorのページに従いインストールしてください。MS Build Toolsがインストールしてあれば無事にインストールできるはずです。
なお二番目以降はpipではなくmimですのでご注意ください。
なおスクリプト実行時に「RuntimeError: Numpy is not available」というエラーが出るときには、以下のようにnumpyを最新版にすると(警告は出ますが)動くはずです。
pip install -U numpyスクリプトのダウンロードとインストール
前処理用のスクリプトを用意しましたのでダウンロードして適切な場所にコピーしてください。
更新情報
※12/13 (v3):顔を中心とし、顔サイズからの相対サイズで、リサイズなしで切り出すcrop_ratioオプションを追加しました。元画像のサイズがまちまちな場合にお使いください。
※12/1 (v2):顔が見つからない場合に落ちていたのを、その画像をスキップするよう修正しました。複数の顔が見つかった場合、ある程度の閾値以上で最も大きな顔を対象とします。
過去のバージョン
前処理スクリプトによる教師用画像の前処理
任意のディレクトリにオリジナルの教師用画像を入れておきます。
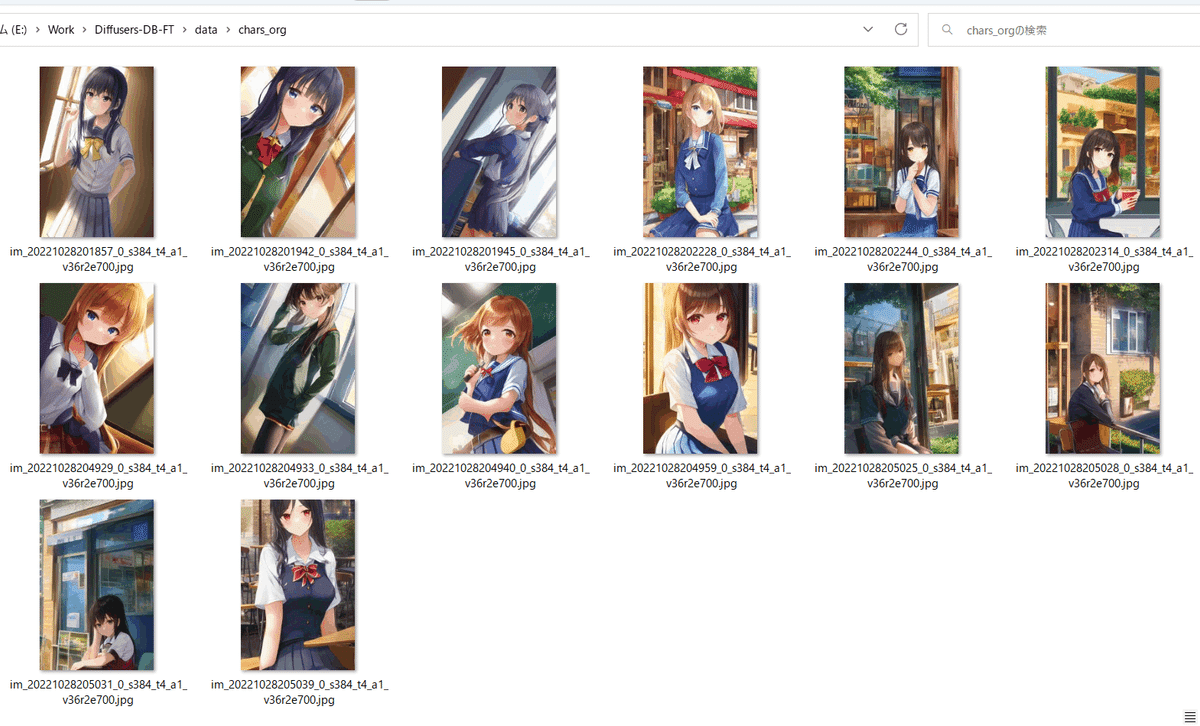
スクリプトを以下のように実行します。
python detect_face_rotate.py --src_dir <オリジナルの教師用画像のディレクトリ> --dst_dir <前処理後のディレクトリ> --rotate以下のようにキャラクタの顔が概ね正立するように画像が回転され、顔座標(中心X、中心Y、横幅、高さ)がファイル名に追加されます。DreamBooth学習スクリプトはこの情報を用いてaugmentationします。
画像を学習時の解像度にリサイズする必要はありません(自動的に切り出し、リサイズして学習します)。

見るとわかるように、回転の結果として画像内に出てくる部分は反転した画像で埋められますが、顔を中心とした学習にはあまり影響がないと思われます。
回転を行いたくない場合は--rotateオプションを外してください。
顔位置を確認したい場合は--debugオプションを付けると矩形を表示します。
なお前処理のみ行い、学習は他の環境で行う場合の使用法については記事の末尾で解説します。
これらの画像を前回の記事の学習用画像のディレクトリ(<繰り返し回数>_<プロンプト>)へ格納してください。
正則化画像は通常通り用意してください。
augmentationを行いつつ学習する
学習スクリプトの実行例
新しいオプションは末尾の3つです。
accelerate launch --num_cpu_threads_per_process 8 train_db_fixed.py
--pretrained_model_name_or_path=<Diffusers版モデルのディレクトリ>
--train_data_dir=<学習用データのディレクトリ>
--reg_data_dir=<正則化画像のディレクトリ>
--output_dir=<学習したモデルの出力先ディレクトリ>
--prior_loss_weight=1.0
--resolution=512
--train_batch_size=2
--learning_rate=1e-6
--max_train_steps=1600
--use_8bit_adam
--mem_eff_attn
--face_crop_aug_range=2.0,3.0
--flip_aug
--color_aug--face_crop_aug_rangeオプションで、教師データ切り出し時の範囲を、「顔のサイズの倍率の下限,上限」で指定します(顔サイズはAnime Face Detectorの検出した顔の横幅・高さの大きいほう)。
たとえば「2.0,3.0」なら、顔サイズの2倍の範囲(解像度が512のとき顔の大きさは256)から、3倍の範囲(同じく顔の大きさは約170)でランダムに切り出します。その後、切り出した画像は教師データサイズにリサイズされます。
(わかりにくくて申し訳ありません。debug_datasetを指定して実際に確認しながら上下させてみてください。)
下限と上限に同じ値を指定すると常に同じ大きさで切り出されます(つまりaugmentationを行わない)。
キャラではなく画風の学習を行う場合には、倍率を大きくすると背景まで含めて教師データにできます。
--flip_augを行うと左右反転のaugmentation(ランダムに左右反転する)を行います。キャラクタが左右対称でない(たとえば髪型、髪飾り等)場合には外してください。
--color_augで色合いを微妙にランダムに変更するaugmentationを行います。教師データごとの色合いの違いを吸収できる可能性があります。
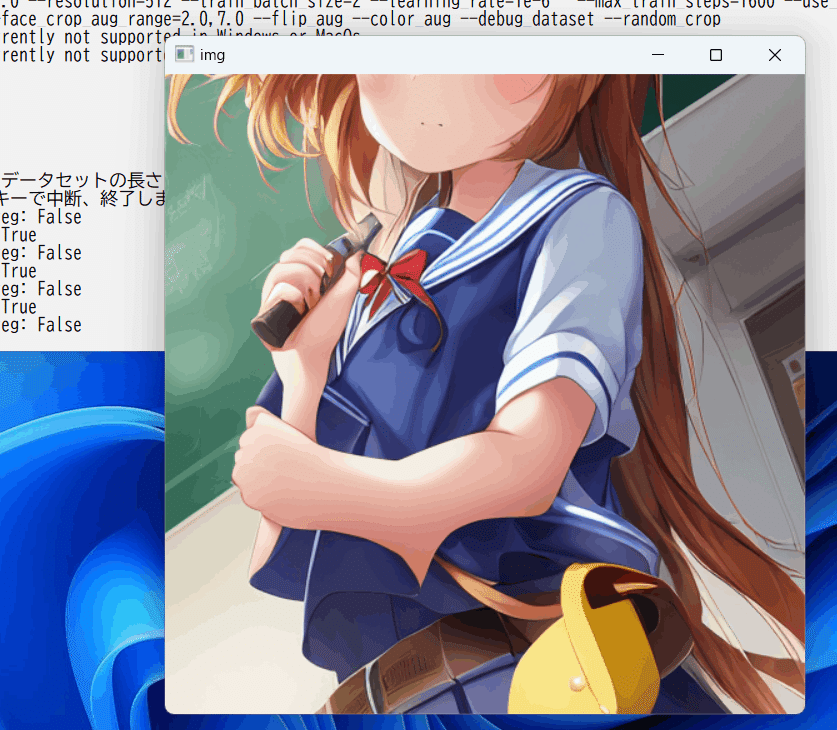
--debug_datasetオプションを付けると学習を行わずに教師データを画面に表示して確認できますので、実際の学習の前に確認してください。
(画像ウィンドウを選択した状態で何かキーを押すと次の画像、Escキーで終了。)

--random_cropオプションを指定すると、顔を中心としながらもある程度、範囲を持たせて切り出します。スタイルの学習時に指定してみてください。
前処理スクリプトで教師データ画像を準備する
他の環境で学習する場合、またはlatentsのキャッシュを行う場合などの使用方法です。
--src_dir、--dst_dir、--rotateオプションは前述と同様です。
元の画像サイズを意識した顔中心の切り出し
--crop_sizeオプションで切り出し画像サイズを指定し、--resize_fitオプションを指定すると画像の短辺が教師データサイズに合うようにリサイズされ、顔が長辺の真ん中に来るように切り出されます(顔サイズは無視)。
python detect_face_rotate.py --src_dir src --dst_dir dst --rotate --crop_size 512,512 --resize_fit
顔サイズを統一した切り出し
--crop_sizeオプションで切り出し画像サイズを指定し、--resize_face_sizeオプションで顔サイズを指定すると、顔がそのサイズになるように画像をリサイズしてから、顔を中心として指定したサイズで切り出します。
たとえば以下の例では、
python detect_face_rotate.py --src_dir src --dst_dir dst --rotate --crop_size 512,512 --resize_face_size 192画像サイズが512*512、その中で顔サイズが192になるように切り出されます。

なお画像サイズが相対的に小さい場合(顔を指定サイズになるようリサイズすると、画像が教師データサイズよりも小さくなってしまう場合)は顔が指定サイズよりも大きくなります(警告メッセージが出ます)。
画像サイズを統一した切り出し
--crop_ratioオプションで切り出す、顔を中心として、画像サイズを顔サイズからの指定倍率のサイズで切り出します。
たとえば以下の例では、
python detect_face_rotate.py --src_dir src --dst_dir dst --rotate --crop_ratio 2,3顔サイズの横2倍、縦3倍のサイズの画像が、それぞれの画像から切り出されます。倍率は「横,縦」で指定してください。小数点も使えます。
元画像のサイズがまちまちで、劣化なしで切り出したい場合にお使いください。
(サンプルはのちほど追加します。)
この記事が気に入ったらサポートをしてみませんか?