
画像を生成するAI"DALL・E2"の衝撃

今回は、世界のAIの最先端をお伝えすべく、Open-AI、そして先日ベータ版がリリースされたDALLE・2について、噛み砕いて、誰でも理解できるようにお話ししようと思います。
私は以前より、サム・アルトマンが率いるOpen-AIのベータテスターとして様々な機能を触ってきました。自然言語生成のGPT-3、テキストからプログラミングコードを生成してしまうCodexなど、そのどれもが破壊的イノベーションです。そのOpen-AIが開発する中で最も新しい機能であるDALL・E2は、テキストで指示した通りの画像を生成するというとんでもないシロモノです。
Open-AIが牽引する世界のAI研究のトレンド
まず、DALL・E2の説明に入る前の予備知識として、Open-AIを筆頭とした世界のAI研究のトレンドについてお話しします。
現在、アメリカで開花しつつあるのは、Foundation Model(基盤モデル)と命名された、大規模なデータセットを学習し、汎用的に様々な分野で即時活用できるAIです。従来は、個別の業務や用途に適したデータセットを用意し、AIに学習させることで利活用を行うのが一般的ですが、Foundation Modelは、大量のデータを学ぶ事により、何でも答えられる全知全能のAIを目指すモデルになります。
スタンフォード人間中心人工知能研究所(HAI)のFoundation Modelモデル研究センター(CRFM)は、このFoundation Modelを「AIシステム構築のパラダイム」と表現し、大量の非標識データで学習したモデルを多くのアプリケーションに適応させることができるとしています。
そしてこのFoundation Modelで形成されたAIの筆頭格となるのがOpen-AIが作ったGPT-3です。Open-AI によると、GPT-3 には 1,750 億個のパラメータが含まれており、5兆個の言語を学習しています。そのため、複数の言語での入出力に対応しています。デモについては、日本語で詳しくGPT-3を紹介している動画がありますので、そちらをぜひご覧ください。
DALLE・2とは
DALLE・2は、これまでにOpen-AIが開発した自然言語生成の機能を発展させ、言語と画像の関係性を学習することにより、テキストで指示した画像を生成する機能を持っています。例えば、「バイクに乗ったコアラ」「モナリザの顔を男性に変える」等の指示を行うだけで、その画像を生成する事ができるようになりました。以下が紹介動画になります。
実際に使ってみた
前置きはこれくらいにして、どのように使用するか、また作成した画像についてご紹介していきます。利用法は至って簡単です。
初めに、テキストで作りたい画像を指示します。
私は今回、以下の画像の通り、「Twitterのアイコンに使える、サイバーパンクスタイルのサングラスをかけた犬の3Dイメージ」を作るように指示してみました。すると、数十秒後、その通りの画像が候補として表示されました。
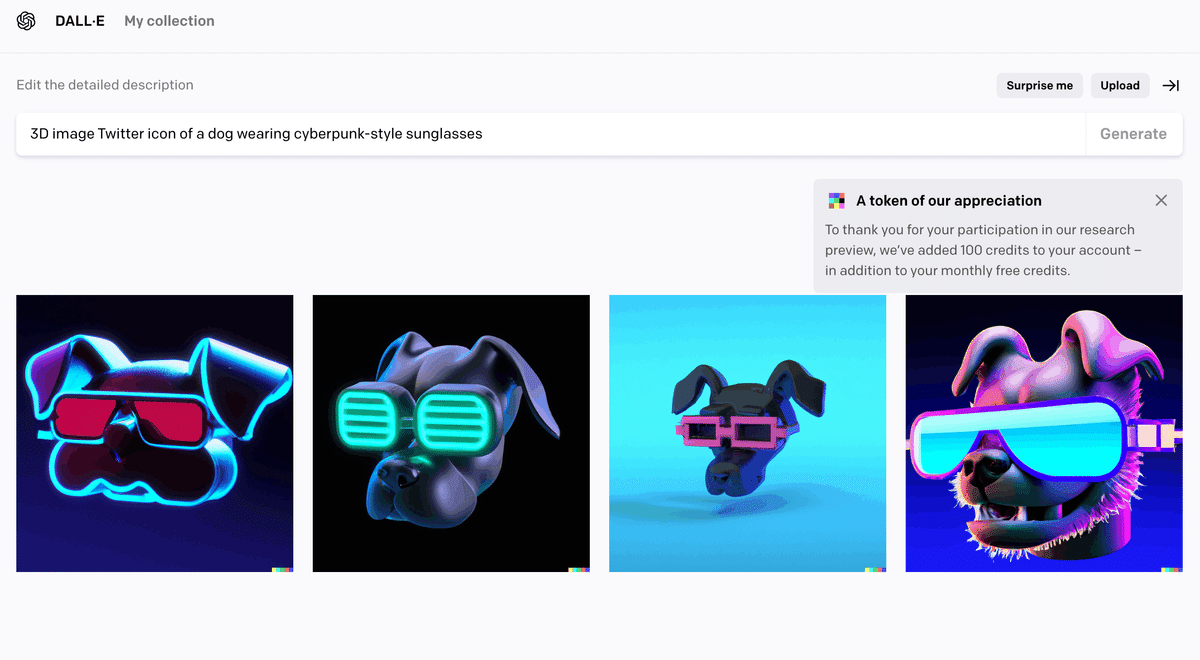
個人的に驚いたのは、デザインのテイストまで考えて生成していると思える点です。この指示を行うにあたり、「NFTでも使える今っぽいものができると良いな」と思っていたのですが、その通りの画像が出来上がりました。
次に、少し意地悪をして、Webからクローリングして得たデータを元に画像を生成しているのであれば、既存の有名な画像に似た画像を作るように指示したらどうなるのか?と考え、「ハワイアンなホテルのプールで泳ぐBored Apeのピクセルアート」と指示してみました。しかもちょっとしたスペルミスも入れてみました。その結果生成された画像がこちらです。

凄い。ちゃんと意味を読み取り、かつBAYC風の画像を避けています。
この他にも、既存の写真から、風景だけ変えたり、自分だけ抜いたりといった高度な編集もできます。
DALLE・2は、「人間がどのように世界を見ているのかを理解している」と言っていますが、私はそれも過言ではない画像のクオリティだと思いました。皆さんはどう思いますか?
これだけのクオリティの画像がテキストの指令だけで生成されてしまうとなると、今後、誰もがクリエイターになれる可能性が出てきますね。
DALLE・2はまだ招待制での利用になっており公式公開されていませんが、Open-AIの今後と共に非常に重要なAIの進化の起点になるやもしれません。また、兆円レベルの投資と、膨大なデータを読ませるという物量戦略を採用した時のアメリカの恐ろしさを思い知らされました。
Foundation Modelの延長線上には、HALのようなSFの世界の人工知能を実現する未来が見えますね。