
[Python] pandas groupbyを使って、日付毎に最も売れた商品を取得する

はじめに
pandasで、groupbyを使用し、グループ内の最大値を持つ行を取得する実装について、まとめます。
使用するサンプルデータ
売上一覧のサンプルデータを使用しました。

カラム構成は、下記です。
A列…date(日付)
B列…id(商品ID)
C列…category(商品カテゴリー)
D列…name(商品名)
E列…price(価格)
F列…quantity(個数)
なお、このデータは、下記のサイトを使用して作成しました。
使用するライブラリ
pandas
データ分析をサポートするライブラリです。
動作環境
windows11
Jupyter Notebook 6.4.5(Python 3.9.7)
実装
前準備
CSVファイルを読み込み、DataFrameオブジェクトを生成します。
import pandas as pd
file_path = r'pandas_sample_product.csv'
df = pd.read_csv(file_path, encoding='cp932')DataFrameオブジェクトのheadメソッドで、先頭から5行データを表示して確認します。
df.head()
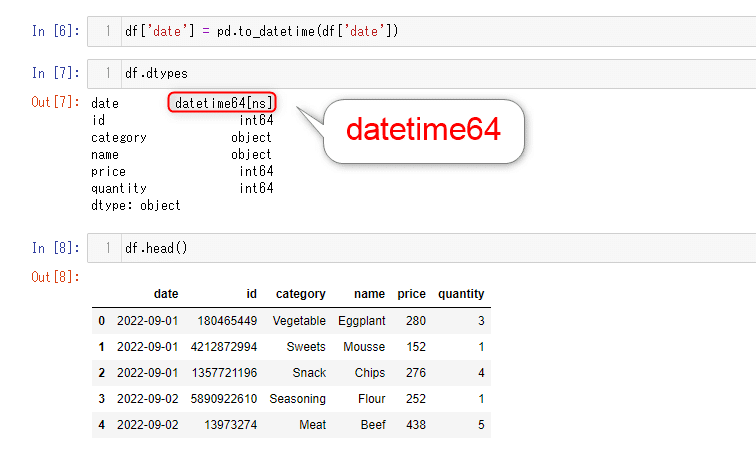
読み込んだ各カラムのデータ型を、DataFrameオブジェクトのdtypesメンバーで確認します。
df.dtypes

「date」カラムがobject型となっているため、pandasモジュールのto_datetimeメソッドを日付型に変換します。
df['date'] = pd.to_datetime(df['date'])dtypesメンバーで、各カラムのデータ型を確認します。
「date」カラムが日付型になっていることが確認できました。
データのグループ化
DataFrameオブジェクトをグループ化するには、groupbyメソッドを使用します。
今回は、「date」でグループ化します。
df_date_group = df.groupby(['date'])続いて、各日付毎に最も売れた商品をmaxメソッドで取得します。
df_date_group['quantity'].max()
この方法だと、各日付毎に最も売れた商品の行が確認できません。
そのため、groupbyオブジェクトのidxmaxメソッドを使用して、最大値の行名を取得します。
続いて、取得した行名より、DataFrameオブジェクトのlocメソッドを使用し、対象となる行を取得します。
df.loc[df_date_group['quantity'].idxmax(), :]
日付毎に最も売れた行を取得することができました!
まとめ
今回は、groupbyを使用し、グループ内の最大値を持つ行を取得する実装を、売上一覧をサンプルとして、日付毎に最も売れた行を取得する実装について、まとめました。