
[Python] PDFファイルを画像ファイルに変換する

はじめに
今回は、Pythonで、PDFファイルをページごとに画像ファイルに変換する処理を実装します。
処理概要は、下記です。
コマンドラインで渡されたPDFファイルを、画像ファイルに変換
画像ファイルは、PDFファイルと同じフォルダに作成
画像ファイル名は、PDFファイル名の拡張子なしのベースネームに対し、ページ番号を2桁で付与
例:PDFファイル名:a.pdf ページが2ページある場合、a_01.png、a_02.pngの2つの画像ファイルを作成
使用するライブラリ
pdf2image
PDFファイルを画像変換するライブラリとなります。なお、使用時にはインストールが必要です。
pip install pdf2imageまた、pdf2imageライブラリは、内部でpopplerというPDFドキュメント閲覧用のライブラリを使用します。
popplerは、OSによってインストールの仕方が異なります。詳細は、下記の「How to install」をご参照ください。
今回は、windows10で動作させるため、popplerをPCへダウンロードして使用します。
popplerのダウンロード
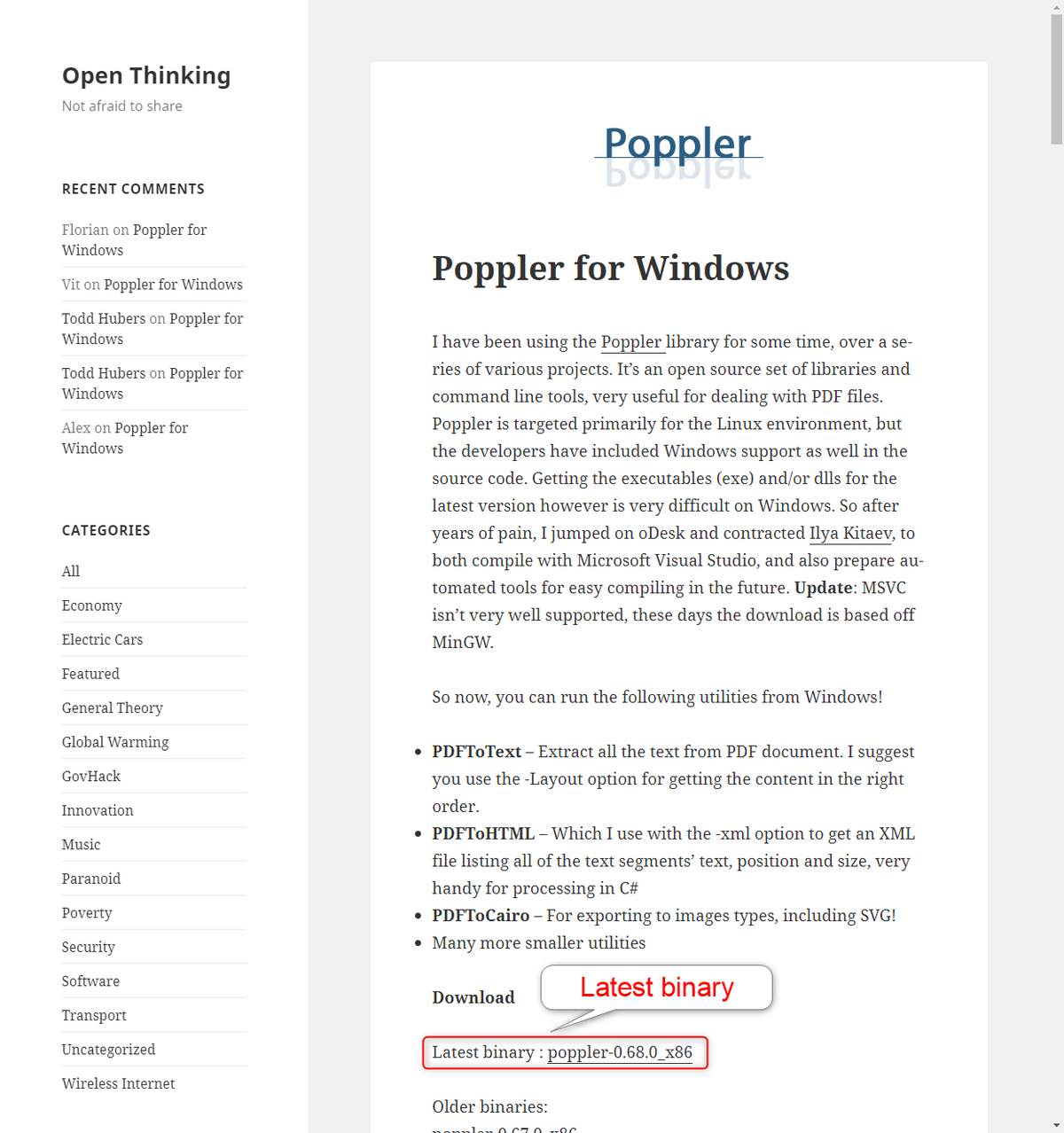
ブラウザで、下記のURLへアクセスします。
Latest binaryの隣にある最新版をダウンロードします。
ダウンロードしてきたファイルの拡張子は、.7zとなっています。この拡張子.7zのファイルは、「7-Zip」という圧縮・展開ツールを使用して、ファイルを解凍(展開)できます。
次に、ダウンロードしてきたファイルを、適宜フォルダで解凍します。解凍すると、下記のようなフォルダ構成になります。
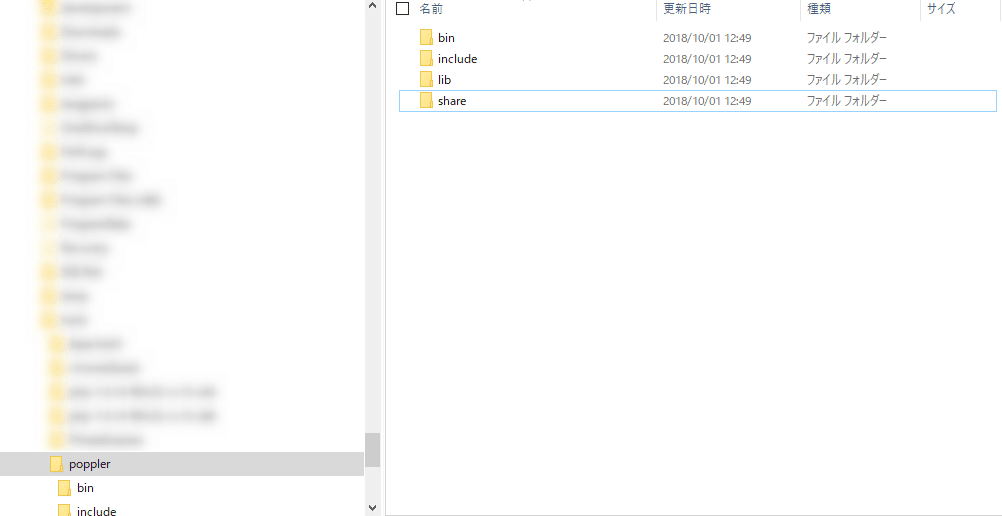
このbinフォルダのフルパスをコピーしてメモっておきます。
実行環境
・windows10
・Python 3.8.5
実装
全体の処理は、下記です。
import os
import sys
from pdf2image import convert_from_path
POPPLER_PATH = r"C:\xxxx\poppler\bin"
def main(file_path_list):
for file_path in file_path_list:
folder_name = os.path.dirname(file_path)
pdf_file_name = os.path.basename(file_path)
base_file_name = os.path.splitext(pdf_file_name)[0]
# PDFをImageに変換
pages = convert_from_path(file_path, poppler_path=POPPLER_PATH)
# 1ページずつ画像ファイルとして保存する
for i, page in enumerate(pages):
image_f_name = f'{base_file_name}_{str(i).zfill(2)}.png'
image_f_path = os.path.join(folder_name, image_f_name)
page.save(image_f_path )
if __name__ == '__main__':
args = sys.argv
# 引数2つ目以降処理する
main(args[1:])順番に処理の内容を説明します。
①コマンドラインから渡されたファイル名を取得
args = sys.argvsys.argvは、リスト型でコマンドラインから渡された引数が格納されます。リストの1番目は、実行ファイル名となるため、2番目以降をPDFファイルのパス名として処理を行います。
def main(file_path_list):
for file_path in file_path_list:②PDFファイルパスから、フォルダ名、ファイル名、ベースネームを取得
PDFファイルのパス名より、フォルダ名を取得するには、os.path.dirnameメソッドを使用します。
folder_name = os.path.dirname(file_path)次に、PDFファイルのパス名より、ファイル名を取得するには、os.path.basenameメソッドを使用します。
pdf_file_name = os.path.basename(file_path)最後に、ファイル名から拡張子を除いたベースネーム名を取得するには、os.path.splitextメソッドを使用します。
os.path.splitextメソッドの戻り値は、リスト型となります。リストの1番目は拡張子なしのベースネーム、2番目は拡張子が取得できます。
base_file_name = os.path.splitext(pdf_file_name)[0]③PDFファイルを画像オブジェクトに変換
convert_from_path関数を使用して、PDFファイルを画像オブジェクトに変換します。
convert_from_path関数で、先ほどダウンロードしたpopplerを使用するため、指定の方法が2つあります。
1.環境変数のPATHに、poppler\binのフォルダパスを追加する
2.convert_from_path関数のキーワード引数:poppler_pathにpoppler\binのフォルダパスを指定する
今回は、2つめの方法で指定しています。
pages = convert_from_path(file_path, poppler_path=POPPLER_PATH)次に、convert_from_path関数の戻り値は、PDFファイルの1ページごとの画像オブジェクトとなっています。この画像オブジェクトは、PillowライブラリのImageオブジェクトです。
この画像オブジェクトを、ファイル名を指定して保存します。
# 1ページずつ画像ファイルとして保存する
for i, page in enumerate(pages):
image_f_name = f'{base_file_name}_{str(i).zfill(2)}.png'
image_f_path = os.path.join(folder_name, image_f_name)
page.save(image_f_path)なお、画像を保存するImage.saveメソッドは、保存されるファイルのフォーマットを、引数で指定されたファイル名の拡張子から自動的に判別します。
今回は、png形式で保存しています。
まとめ
今回は、Pythonで、PDFファイルをページごとに画像ファイルに変換する処理を実装しました。
PDFを画像に変換するには、有料のPDF編集ソフト、もしくはWebサイトのサービスを使用することになります。Pythonだと無料でツールを作ることができ、かつ保存するフォーマットやファイル名のルールも自分で決められるので、便利ですね。