JanでローカルLLM Gemmaを試す

日経ソフトウェア 2024年9月号で「特集1 LLMをローカル環境で動かす方法」というとても興味深い記事があったので、記事の内容をトレースしながら、ローカルでGoogleのオープンLLM「Gemma」を実行してみます。
0. Janって何?
※Cloud 3.5 Sonnet wrote
Janは、個人のコンピューター上でローカルに大規模言語モデル(LLM)を実行できるオープンソースのアプリケーションです。
JANの特徴
ローカル実行:
クラウドサービスを介さず、ユーザーの端末上で直接LLMを動作させます。プライバシー重視:
データがローカルに保存されるため、プライバシーが確保されます。カスタマイズ可能:
様々なオープンソースのLLMモデルに対応し、ユーザーが選択できます。リソース効率:
比較的軽量なモデルを使用し、一般的なPCでも動作します。無料で利用可能:
オープンソースソフトウェアとして無償で提供されています。
1. Janの入手
以下にアクセスしてJanのインストーラをダウンロードします。

2. Janのインストール
ダウンロードしたexeファイルを実行。
以下の画面が出たらインストール完了。
Explore The Hubをクリックします。

3. ダウンロードするモデルの選択
パソコンのVRAMの容量にあわせて表示される以下タグを参考に、ダウンロードするモデルを選択します。
「Recommended」 ★基本的にはこちらから選択
「Slow on your device」
「Not enough VRAM」
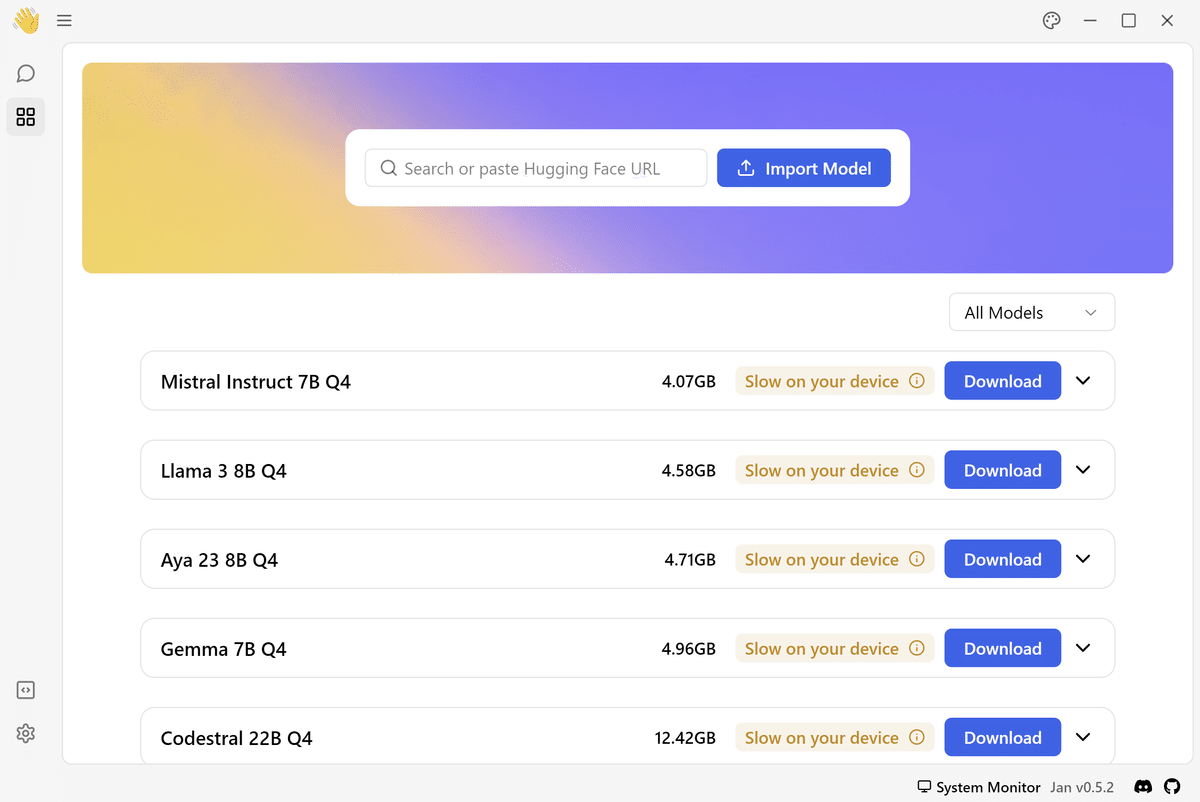
今回は Google のオープンモデルであるGemmaを利用します。
オープンモデルなので商用利用も可能です。

4. Gemmaを起動する
ダウンロードが完了したら、画面左下にあるSettingボタンを押します。

設定画面のCortexに「Inactive」状態のGemmaが確認できます。
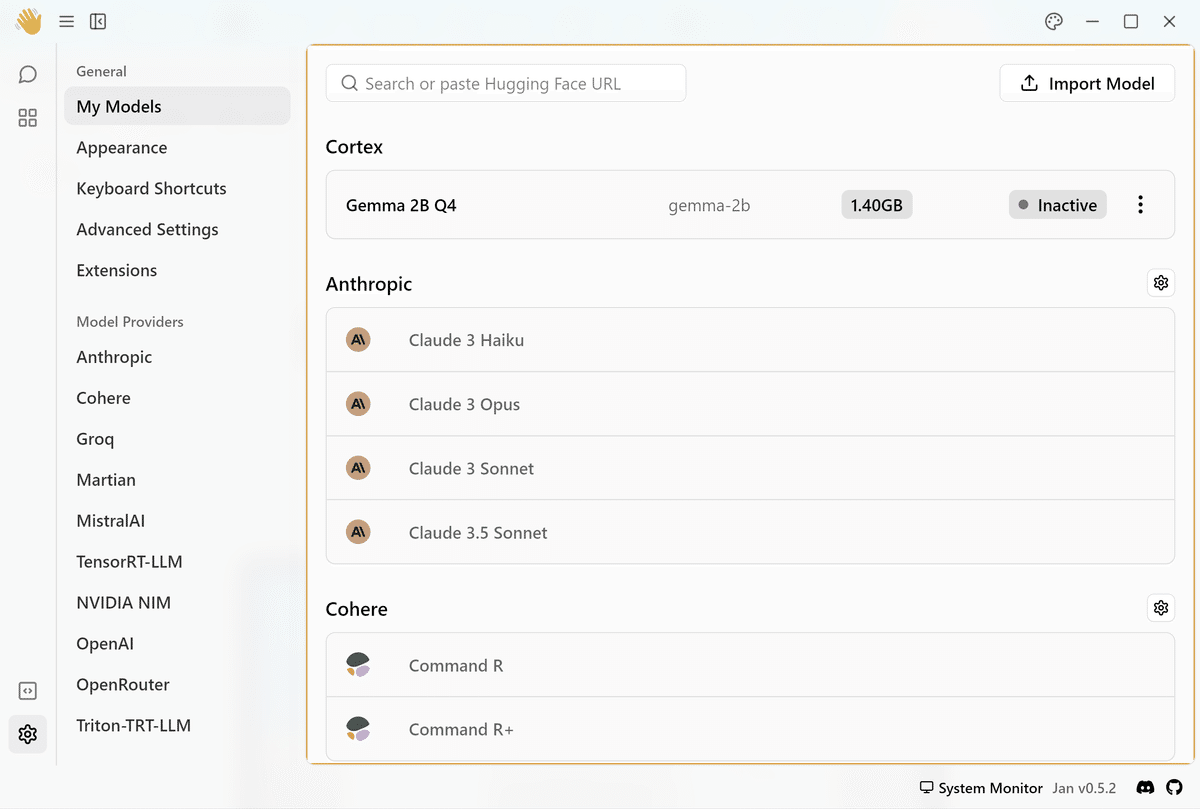
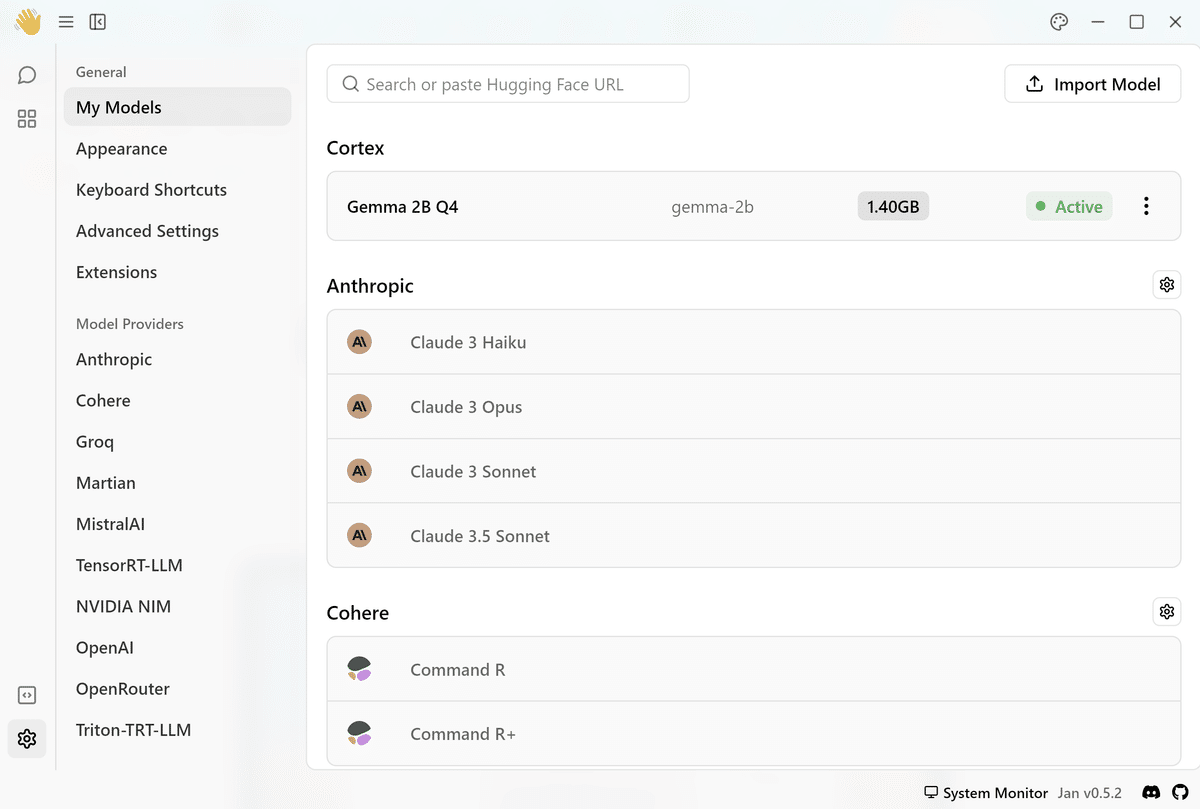
モデル名の右端にある3dot メニューから「StartModel」を選択します。

ステータスがAcviveになったら準備完了です。
5. Gemmaでチャットを試す
画面左上の「Thread」ボタンを押してチャットAIの画面に切り替えます。

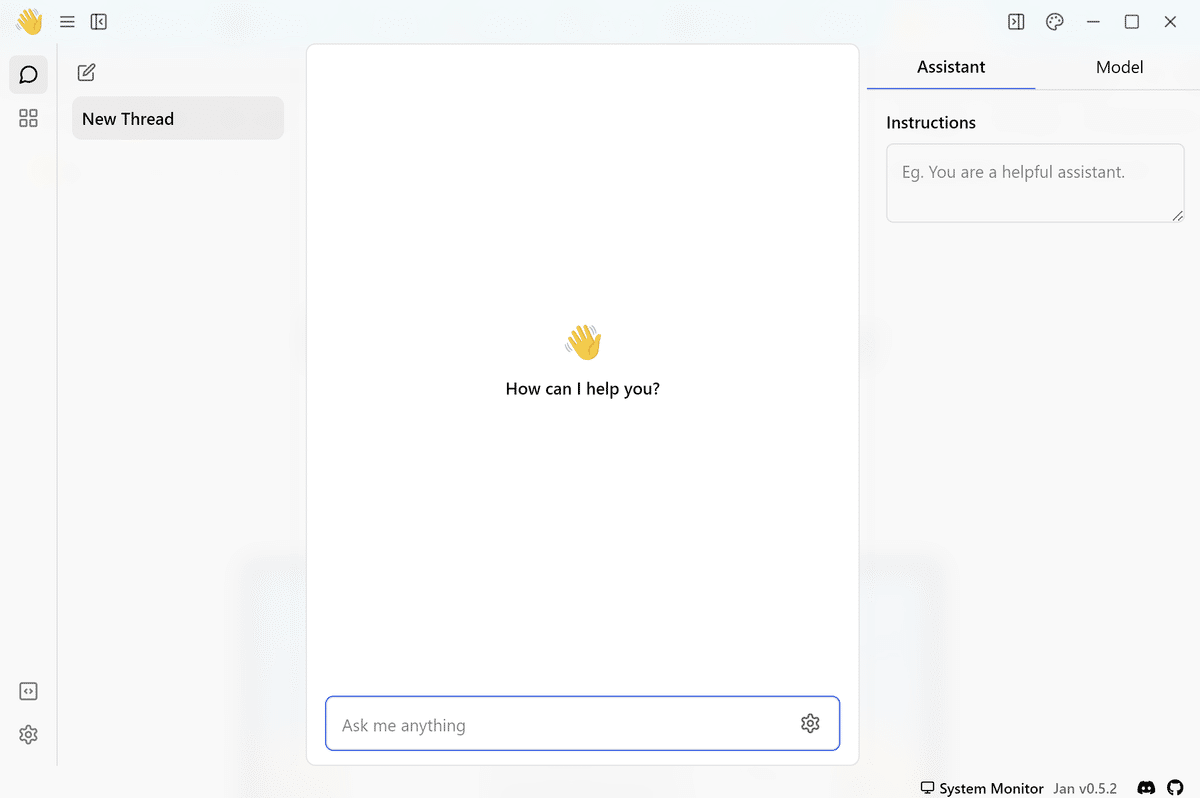
画面右上の「Model」タブで「Gemma」を選択する。

「Assisttant」タブの「Instructions」に以下を入力。
あなたは新設なアシスタントです。日本語で答えてくれます。

画面下の「Ask me anything」に質問文を入力します。

まとめ
いままでNVIDIAのGPU積んだ30万くらいのパソコンがないと縁遠いと思っていたローカルLLMが、ノートPC(Core i5 2.4GHz 16GB RAM)で動かせたことが単純に嬉しい!
Gemmaは2Bなので、Llama3 8Bとかと比較したら当然知識は劣るんだろうけど、大切なのは性能よりも使い方(使い分け)で、ローカルで使えるような小規模言語モデル(SLM:Small Language Model)は、ドメインに特化させた使い方がはまるんじゃないかと思っています。
課金を気にしないでいいのがローカルLLMの一番のメリットだと思うので、これからいろいろ試してみようと思います。