DifyでTeratermマクロのRAG構築

はじめに
Teratermマクロというニッチな(かつクセつよなコード)を、汎用的な生成AIでコード生成すると、ハルシネーションがおきまくります(経験測)。Difyのオープンチャットでお聞きしたところ、Cursor にコマンドリファレンスのドキュメントを渡してコード生成をされている方が多いようでした。
せっかくなので、DifyでRAGに出来たらいいなっていうのがきっかけで作ってみました。
参考にしたワークフロー
DiscordのDify.ai 公式サーバのチャンネル「workflow - sensei」のスレッド「Web站点同步-构建知识库」(中国語の訳:Web サイトの同期 - ナレッジ ベースの構築)@jingyuさんのワークフローを参考にさせていただきました。(こちらをグランドデザインとしてますが、既存ドキュメントありの場合を無くしたり色々変えた結果、最終的に見た目は別物になりました。。)
事前準備
実現方法の検討
本当は「firecrawlでサクッと」と思っていたのですが、取得したいコマンドが index.html と同じ階層にある(ツリー構造ではない)ところで、組み込みツールのfirecrawlを1度動かす(ツリー構造をクロールする)だけではとることができず。(もしかしたら方法はあるかもですが…)
そのため以下のような段階的な方法で実施することにしました。
index.html にあるコマンドとそのリンク情報を取得
コマンドとURLを1セットの文字列として配列に格納
配列要素をイテレーションに渡す
イテレーションの中でコマンド単位のクロールとナレッジドキュメント作成を繰り返す。
「.env」の変更
動作確認の中で気づいた点を先に記します。
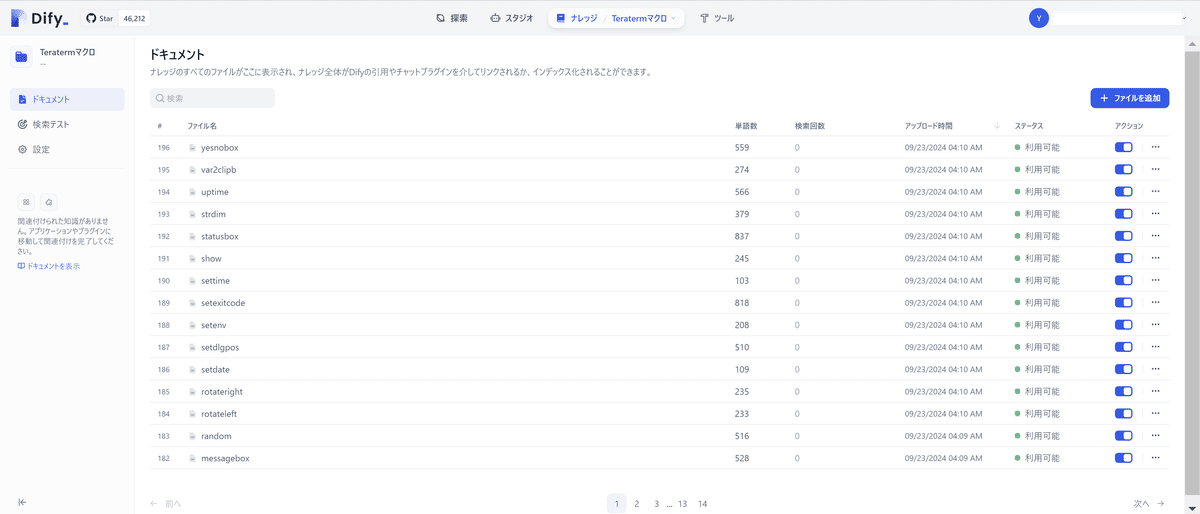
ドキュメント化する対象のコマンドが190弱あるのですが、Difyでは配列に格納出来る数に制限(デフォルト:30)があります。
今回、配列はString型ですが、Objactもついでにデフォルトの30を300に変えておきます。
CODE_MAX_STRING_ARRAY_LENGTH=300
CODE_MAX_OBJECT_ARRAY_LENGTH=300
CODE_MAX_NUMBER_ARRAY_LENGTH=1000
最大ステップ数の変更
もうひとつやってる中でわかったこと。
Difyには最大ステップ数という制限値(デフォルト:500)があります。ステップ数というのは、おそらく処理ノード数と思われます(未確認)。
Discordで質問したところ、今回の質問を契機にDocker の「.env」への外出しをPR(プルリクエスト=変更要求)していただけました!(感謝!!)なので近いうち「.env.example」に入れてくるんじゃないかなと思います。
「.env」と「docker-compose.yaml」をPRと同様に変えることで制限値の変更ができます。
変更は自己責任でお願いします。
変更するファイルはバックアップで戻せるようにしておきましょう!
変更後は「docker compose down」「docker compose up -d」も忘れずに。
注意点
Difyのパラメーターを変えていることからわかるように、コマンドの数(190弱)というかなりの回数のイテレーションが回ります。
私の場合、まずGoogle AI Studio 、command-r-plus それぞれ無料枠のAPIは呼び出し回数のLimitに引っかかり途中で止まりました。
そのため、OpenAIのアカウントでチャージして gpt-4o-mini-2024-07018 を利用しました。しつこいですが自己責任でお使いください。(参考として記事の「結果」項に、実施時間と利用Tokenを書きました)
ワークフローの使い方
DSLの読み込み
DSLをダウンロードして読み込みます。
空のナレッジの作成
空のナレッジを作成し、アドレスバーからドキュメントIDを取得します。


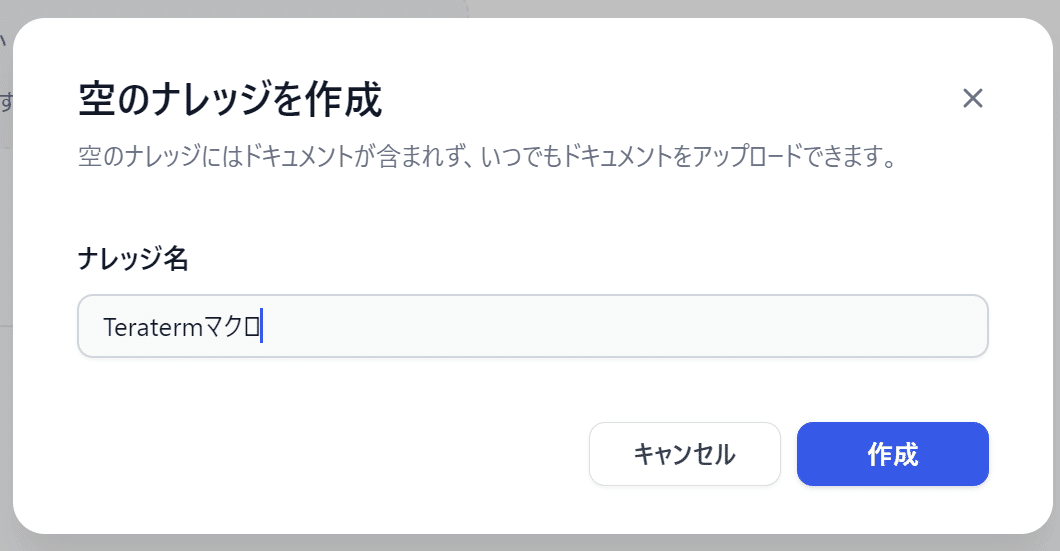
以下の画面でアドレスバーからドキュメントIDをテキストにひかえます。
https://[your-dify-server]/datasets/[ここがドキュメントID]/documents

ナレッジ一覧の画面に戻り、APIのタブを選択する。
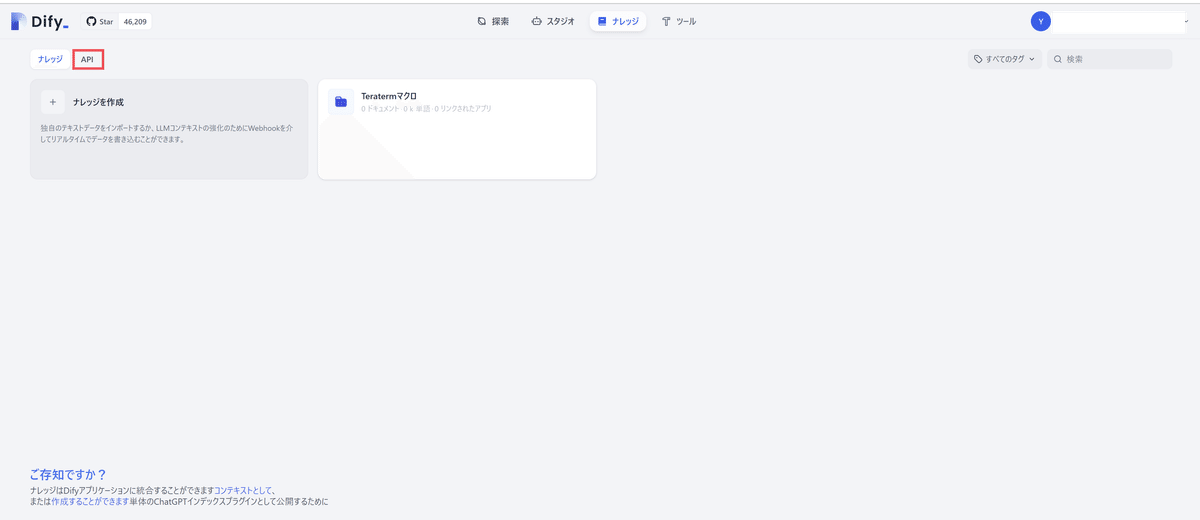
右上のボタンからAPIキーを作成・取得する。
(次のHTTPノードに設定します)
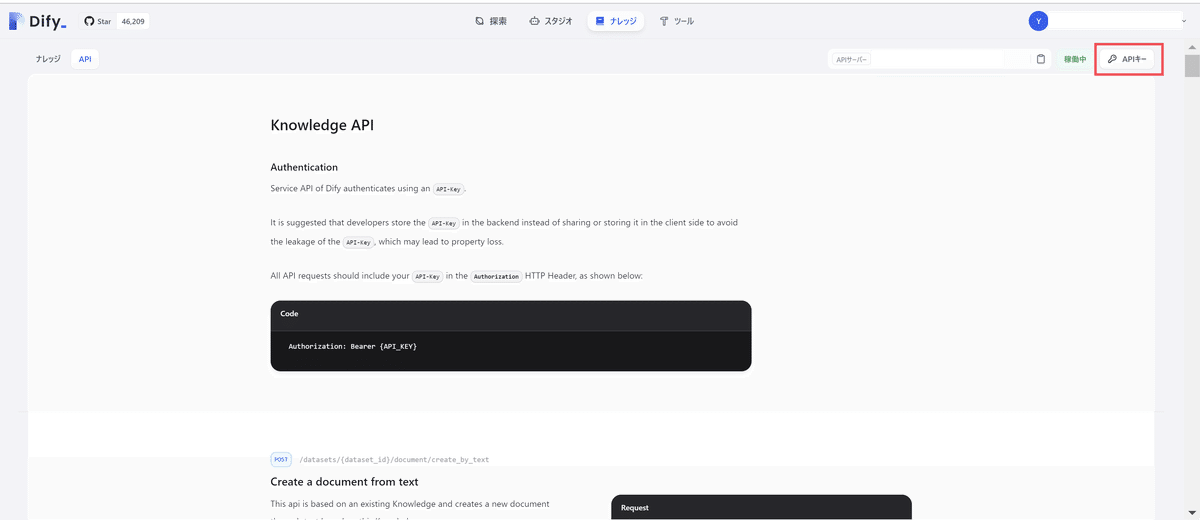
HTTPノードの設定
自分のDifyサーバのURLにあわせて、リクエストURLを設定します。
その上にある認証APIキーのボタンをクリックします。

認証APIの設定にはドキュメント作成で取得したAPIキーをBearerで設定します。
余談:
ここでのAPIキーは「ドキュメントに書き込むため」に「ナレッジで取得したAPIキー」です。ワークフローのAPIキーもあるので、ごっちゃにならないように。(ちょっとだけ間違えました)

ワークフローの実行
ワークフローの実行ボタンをクリック、フォームに以下の情報を入力してから「実行を開始」をクリック。
URL:
https://teratermproject.github.io/manual/5/ja/macro/command/index.html
※TeratermマクロのコマンドリファレンスのURL
ナレッジベースID:
※「空のナレッジの作成」で確認したドキュメントID
セグメンテーションモデル:
「text_model」を選択
ドキュメンテーション言語:
「japanese」を選択

実行結果
実測値は以下になりました。


まとめ
このナレッジでちゃんと動くマクロができるかはまだ試してないですが、Difyの設定として、いろいろデフォルト値の制限があることがわかったり、無料APIの限界?みたいなことも見えたので色々知るきっかけになりました。(むしろ勉強目的)
おまけ:モデルによるデータ抽出の違い
今回の気づき。
LLMのモデルを Gemini 1.5 Flash にして、190超のコマンドをイテレーションで繰り返していたところ Late Limmitでのエラーが出ました。
そこでモデルを command-r-plusに替えて実行したところ、LLMで取り出したあとの処理でURLの抽出が出来ないことでのエラーが発生。
確認すると、同じシステムプロンプトでもモデルによって抽出の仕方が異なることがわかりました。
結論としては、モデルが違っても出力がそろうよう、プロンプトでがんばるのはやめにして、コードで差分を吸収するようにしました。
システムプロンプト
- データからすべてのリンクコンテンツを抽出する。
- プロモーション情報、画像、改行を削除します。
- テキストコンテンツの末尾に含まれない時間情報やページング情報を削除する。例:最終更新6日前、最終更新、最終更新時間、前ページ、次ページ。
- リンクコンテンツにのみフォーカスして出力する。
データ: [Difyのデータリンク]
Gemini 1.5 Flashの場合は、「 [ リンクテキスト ] ( URL ) 」というMarkdownのリンクテキストを表現する形式でURLを抽出しているのに対して、command-r-plusでは、同じMarkdownですが「- URL」という箇条書きの形式で出力されました。
LLMモデルが Gemini 1.5 Flash の場合
{
"iterator_selector": [
"[bplusrecv](https://teratermproject.github.io/manual/5/ja/macro/command/bplusrecv.html)",
"[bplussend](https://teratermproject.github.io/manual/5/ja/macro/command/bplussend.html)",
LLMモデルが command-r-plus の場合
{
"iterator_selector": [
"抽出されたリンクコンテンツ:",
"- https://teratermproject.github.io/manual/5/ja/macro/command/bplusrecv.html",
"- https://teratermproject.github.io/manual/5/ja/macro/command/bplussend.html",
Difyのプロンプトジェネレータへの指示
固定のシステムプロンプトに、追加条件のプロンプトを加えてください。
# 固定のシステムプロンプト
- データからすべてのリンクコンテンツを抽出する。
- プロモーション情報、画像、改行を削除します。
- テキストコンテンツの末尾に含まれない時間情報やページング情報を削除する。例:最終更新6日前、最終更新、最終更新時間、前ページ、次ページ。
- リンクコンテンツにのみフォーカスして出力する。
# 追加条件
- リンクテキストは、Markdownのリンクテキストを表現する形式になるようにしてください。
## Markdownのリンクテキストを表現する形式
[リンクテキスト](URL)
作成されたシステムプロンプト
最後中途半端に切れてますが、数回試しても720文字前後で切れるのは変わらず。文字数制限とかあるのかな?
とりあえず数個の example は作られているので半端分は切り捨てで問題はなさそう。ていうかプロンプトジェネレーター初めて使いましたが、思ってたよりしっかり作ってくれたのでこれなら行けそう。
```xml
<instruction>
AIには以下のタスクを順番に実行してもらいます。
1. 入力データからすべてのリンクコンテンツを抽出します。リンクコンテンツは、ウェブページのURLやその他のリンク情報を含むテキストやデータを指します。
2. 次に、抽出したリンクコンテンツからプロモーション情報、画像、改行を削除します。これにより、リンクコンテンツのみが残ります。
3. テキストコンテンツの末尾に含まれる時間情報やページング情報を削除します。具体的には、「最終更新6日前」、「最終更新」、「最終更新時間」、「前ページ」、「次ページ」などの情報を削除します。
4. 最後に、抽出したリンクコンテンツをMarkdownのリンクテキスト形式に変換します。Markdownのリンクテキスト形式は以下のようになります:[リンクテキスト](URL)
出力結果にはXMLタグを含めないでください。
</instruction>
<example>
例えば、以下のような入力と出力のペアを考えてみましょう。
- 入力:「最新のプロモーション情報はこちら 最終更新6日前」
- 出力:「[詳細](https://example.com/promotion)」
- 入力:「新商品の画像はこちら 最終更新時間:10:00」
- 出力:「[画像](https://example.com/new_product_image)」
- 入力:「次ページへ進むにはこちらを
その結果
{
"text": "以下のリンクが抽出されました。
- [https://teratermproject.github.io/manual/5/ja/macro/command/bplusrecv.html](https://teratermproject.github.io/manual/5/ja/macro/command/bplusrecv.html)
- [https://teratermproject.github.io/manual/5/ja/macro/command/bplussend.html](https://teratermproject.github.io/manual/5/ja/macro/command/bplussend.html)
・・・違う、そうじゃない。
ということでcommand-r-plusを使うのは諦めて、コード側で対処することにしました。(やっぱりプロンプトよりコードでやるのが確実だな、というオチ)