
【JKI】035_Linkedin_Network_Graph_01_つながり申請中

【JKI_035】課題を確認
Just KNIME It! (JKI)
今回の挑戦はこちら

問題文のところだけをDeepL翻訳し少し加筆して以下に
課題35: LinkedInのネットワークグラフ
レベル: 難
説明: このチャレンジでは、あなたのLinkedInのデータを使ってネットワークグラフを作成します。以下はLinkedInのデータを請求する方法です。
アプリを開き、プロフィールアイコン(右上)をクリックします。
「設定&プライバシー」>「データプライバシー」に進みます。
"個人データの取り扱いについて"のセクションで、"データのコピーの取得"をクリックします。
LinkedInのアカウントまたはLinkedInのデータをお持ちでない場合は、以下の弊社提供のエクセルシートをご自由にお使いください。選択したデータが手元に届いたら、あなたの仕事は、連絡先の勤務先を示すネットワークを作成し、それらの連絡先を勤務先ノードにリンクすることです。簡単な例は次のとおりです。
Paolo ---- KNIME ----- Elizabeth
上記のネットワークグラフは、連絡先の両方 (Paolo と Elizabeth) が KNIME で働いていることを示しています。グラフが構築されたら、連絡先の多くが働いている上位3社を可視化します。
ヒント: グラフの作成には、「Network Creator」ノードと「Object Inserter」ノードを使用しました。
【LinkedInのデータ】
私もLinkedInのアカウントはあるにはあるんで、データは取得してみました。でも21人しかつながってないんです…。繋がってくれている皆さんありがとう。
https://www.linkedin.com/in/jp-knimest-5b5a73235/
よき友と交われ。さもなくば誰とも交わるな
なのでサンプルデータを借用します。
いつもの様にworkflow内に格納して相対パスで読み込みます。

設定:



結果:
自分も含まれていて嬉しかったです。

これ、本物のデータですね。個人情報とかええんかな。公開されてるからいいのか。
【解析対象データのETL】

【Row FilterとGroupBy】空白行を削除して集計




結果:

考察:
この後メンバー数での上位3グループをグラフで可視化するにあたり、どこまでサンプルデータを表示対象にするかを考えました。単純に一覧を見るとKNIME, Amazon, Metaですね。恥ずかしながらMetaってどんなグループかわかってなくてググりました。
で、データを見返すと、MetaのほかにFacebookの方もリストにあり、これは分けて集計してはいけないのではないかと思い至りました。
【Table CreatorとCell Replacer】所属グループという属性を付与

設定:
会社名リストを見て、同じグループにしようと思ったものをまとめるため、Table Creatorを使ってConglomerateというカラムで定義しました。
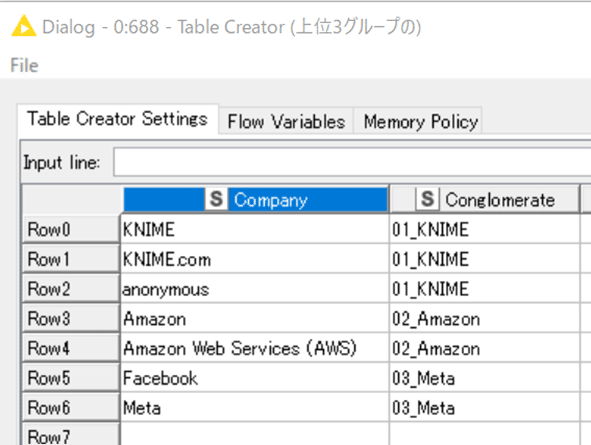
そしてCell Replacerで

元のデータテーブルにAffiliationカラムを勝手に追加しました。
結果:

多彩な業種の方がKNIMEとちながっているんだなと興味深く拝見しました。しかし、786名の全てをプロットするとグラフが見にくくなることから、今回の解析対象は3大グループの人たちだけにします。
全く課題には出ていない処理を加えていますが、後ほど紹介する通り、最近JKIの公式解答が自由奔放に楽しんでいるのを見て、見習うことにしました。もう正解探しというよりは自分ならこうするって好きにやらせてもらっています。これもまた一興。
【各種フィルターと文字列処理】データ選抜とFull_Nameデータ生成
単なるデータ整形なので設定と結果を示すのみとします。



結果:
123名に絞られました。

ん? Peter 👋 さん、絵文字がミドルネームになってる。
合ってるのかなとLinkedInでも確認し、面白そうな方だなとつながり申請もしてしまいました。承認してもらえるかなぁ。
課題にないことばかりしてますが、データ前処理はひとまず完了しました。
次回はグラフでの可視化に挑みます。
KNIME Hubに解答は上げています。
おまけ:
【JKI_034 感想戦】
先週のJust KNIME It! 第34回は任意の英文をランダムに並び替える方法を探りました。
公式解答はこちらです。
JKIのサイトに上げられたSolution Detailsを見て、度肝を抜かれました。Google翻訳し編集して一部引用します。
消費者から航空会社へのツイートのKaggle Datasetを読み込んだ後、Row Filterノードを使って最初の100行にデータをフィルタリングすることから始めた。Strings To Document」ノードで、ツイートを文字列からドキュメントに変換した。

えっ、何が始まった?
課題文からは想像しがたい展開です。
そして14640行から100行を抽出したのち1行ずつをループ処理するのですが、
各入力行に対して、Bag Of Words CreatorノードでBag of Wordsを作成し、GroupByノードで用語の総数を計算した。
GroupByノードで得られた値は、後ほどランダム値の作成に必要な数を決定するために必要となる。
この値は、Table Row to Variableノードで変数に変換される。

その後1行につき10行のランダム化した文字列を出力するループへ。
2番目のループ内では、Random Number Generatorノードを使って、任意の範囲のランダムな値を作成した。
次のステップでは、ランダムに作成された数値を項に割り当てる必要がある。
そのために、まず、RowIDノードを用いて、乱数値を含むテーブルの行IDをリセットした。
また、Bag Of Words Creatorノードで作成したテーブルに含まれる用語を、Term To Stringノードで文字列に変換し直した。
そして、Column Appenderノードを用いて、両方のテーブルを結合した。
次のステップでは、Sorterノードを用いて、ランダムに割り当てられた値に従って用語を昇順に並べ替えた。
最後に、GroupByノードの助けを借りて、用語を1つの文に連結する。

GroupByノードでのつなぎ方は効率が良かったです。
設定:

青色表示した通り、Concatenateで項を結合して文字列を作るときに、半角スペースで繋ぐ設定となっています。
Bag of Wordsの利用例を知ると言う意味でも興味深い例ではありました。
でも、ここまでする必要あります!?
公式なのに何て自由な発想だろうと感心しました。
私も結構遊ばせてもらったし、楽しい課題でしたね。
いいなと思ったら応援しよう!
