
【JKI】034_Word_Scramble_01_Shuffle

【JKI_034】課題を確認
Just KNIME It! (JKI)
今回の挑戦はこちら

問題文のところだけをDeepL翻訳し少し加筆して以下に
課題34: 単語のスクランブル
レベル: 中程度
説明: あなたの仕事上のタスクの1つは、正しい単語文脈(すなわち、文中の単語が意味のある正しい順序に従っている)を持つ文を使ってモデルを訓練することです。しかし、このようなモデルを学習するためには、間違った文脈で使われた単語のデータセットも作成する必要があります。
この課題は、有名なWord2Vecモデルを学習するための巧妙な技術であるネガティブサンプリングのバージョンの一つと考えることができます。
具体的には、この課題では、文章を受け取り、その単語の順序をスクランブルするワークフローを作成することになります。Table Creatorノードで、あなたの作品をテストするために、文の小さなサンプルを作成することができます。
Input
I like cats.
Output
cats. like I
ヒント:この単純な解法では5つのノードしか使っていないが、並べ換えは正確にはランダムではありません。
逆に,より複雑な解では,15以上のノードと2つのループ,そしてRandom Numbers Generatorノードを用いて,真の意味でのスクランブルされた文章を作成することができます.
おまけ:ループを使わずに真のランダム化を行う解を作成してください。
【Word2Vecモデルとネガティブサンプリング】
私は全くの素人なので、ひとまずWord2Vecとは何かから調べましたのでよろしければどうぞ。
Pythonでの活用例は日本語に限っても引用しきれないほどありました。
そしてKNIMEでもノードが提供されています。
さらにコンポーネントまで利用できるんだそうです。
そうはいっても今回の課題は実のところWord2Vecは使いません。
間違った文脈で使われた単語のデータセットの作成すなわちネガティブサンプリングの一手法の疑似体験として、単語の並び替えを実施します。
【解答編_01】
【おことわり】
単純な解法では5つのノードしか使っていないが、並べ換えは正確にはランダムではありません。
逆に,より複雑な解では,15以上のノードと2つのループ,そしてRandom Numbers Generatorノードを用いて,真の意味でのスクランブルされた文章を作成することができます
とのヒントを頂きましたが、上記の2つのどちらのworkflow (WF)も具体化できませんでした。公式解答を待ちたいと思います。
以下は私が単語の並び替えをランダムに実施するならこんなWFを提案しますと言った内容になります。しかも今回はおまけの課題であったループ無しでの実装検討の方を紹介します。

【Table Creator】入力データを自作
入力する文章は自分で指定していいです。

設定:

結果:

【Cell Splitter】単語(+記号)に分ける
単語と記号は今回は分けなくてよいそうです。
設定:

デリミタすなわち単語の切り分けのための区切り文字は半角スペースが1つ入っているので青色表示しています。
一方で、その下のクォーテーションすなわち引用符は何も入力していないのでご注意ください。
結果:

【Transpose】
KNIMEで並び替えをするには、縦並びが便利なので一旦データを縦持ちへ変換しました。
設定:デフォルトのままです

結果:

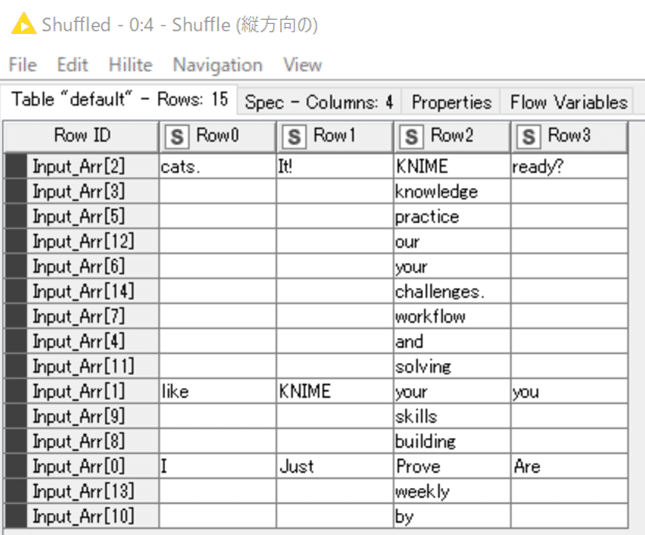
【Shuffle】行単位での並べ替え
このノードは前に一度だけJKIで利用したことがあります。
行をシャッフルします。全列まとめてですが。
設定:

実行する度に結果が変わるようにシードは設定していません。
結果:
【Transpose】2回目
上記と同じ設定ですが、今回は縦に持っていたデータを横並びへ戻します。設定は同じなので結果のみ示します。

【Column Combiner】
全ての列を対象に文字列を結合します。
上のデータテーブルで空白のところも結合されてしまいます。
設定:

またデリミタは半角スペースなので青色表示です。
一方で、Replace Delimiter byのところには何も入力されていません。
結果:

文リスト4つの中で最長の文であるRow2は並び替えが完成していますが、他はあちこちに不要な半角スペースが入ってしまっています。
【String Manipulation】stripとremoveDuplicates
String Manipulationノード自体はもうおなじみでしょう。
一方、今回の文字列処理の関数2種は初めて使いましたが不要な半角スペース記号を除去するのに便利です。
関数の説明までは日本語化されていないので、英文のまま引用します。
設定:
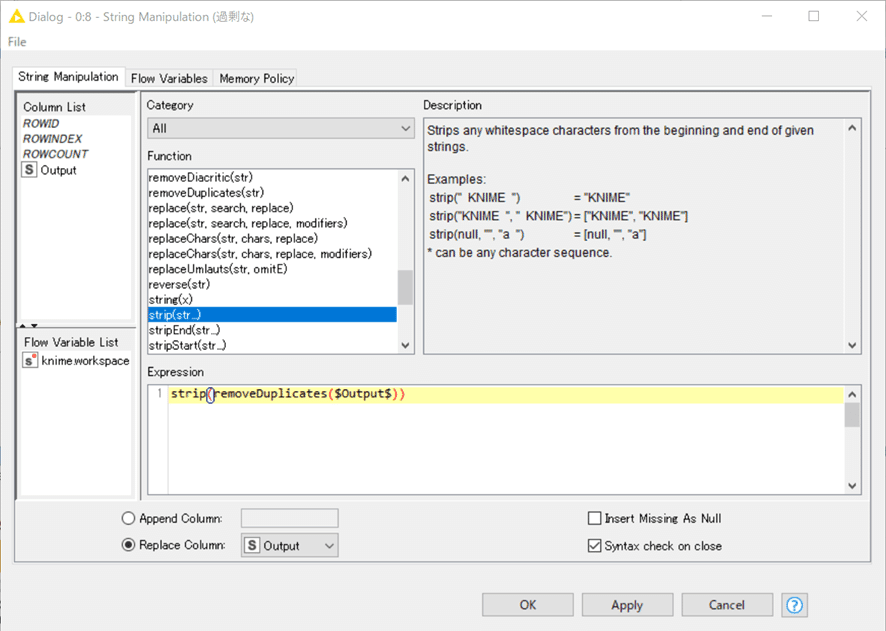
strip関数:文頭と文末の半角スペースを除去

removeDuplicates関数:2つ以上連続する半角スペースを1つだけに置換

結果:

以上で一応ランダムな並べ替えにはなっていると思います。ただし、「真の意味でのスクランブルされた文章を作成すること」が条件なので、悩みます。次回にもう少し体験を続けようと思います。
KNIME Hubに解答は上げています。
おまけ:
【JKI_033 感想戦】
先週のJust KNIME It! 第33回は日本からはデータ入手が困難です。
公式解答はこちらですが、サンプルデータが入っていない…。
各国の皆さんが無事解答を愉しめているのか心配ではありますが、以下コメントします。
一見して公式解答はWFがシンプルだなと感じました。2つの病院グループをまとめて処理するつくりになっています。

ただ、2点ほど気になった点がありました。解析対象のデータの一部しか処理していないように思うのです。
① Row Filter

設定は下記の通り、とても効率よく1ノードでOR検索をしています。
正規表現を使いこなされていてかっこいいです。

ただ、Kaiser病院グループは上記条件だと例外があるようです。
ひとつ前のノードの出力を例に見てみます。

Row30-32のデータは除去されてしまいます。
ただ、一概に間違いでもないかもと思うのです。Kaiserなんて世界中で使いそうな名前ですよね。「大阪王将」と「京都王将」のように名前が似ている別系列かもしれないです。
正直私もカイザーと聞いて全く別の人を思い浮かべましたので。
② Excel Reader

上記コンポーネントの中にExcel Readerがあります。

各Excel workbookから1つのworksheetだけを読み取っています。
本来その方がいいのかもしれないです。
一方で私の場合は各workbookの読み取れる限りの料金リストのworksheet群を読み取って集計しました。
今回価格分布の標準偏差 (SD)を見るので、読み取る対象が異なると結果が変わってしまうので上記2つの違いが気になりました。
今回はデータジャーナリストの立場でのデータ解析体験でした。こういった元データの吟味そのものも、重要な仕事の一部なのではないかと思います。
つまり上記のような迷いもまた一つの疑似体験だろうと思いました。
今回は解析対象は2つの病院グループだけにして課題を軽くしてくれていました。もともとのサンプルデータ全てだったらさらに混迷は深まったでしょう。病院ごとに千差万別な記載方法になっているかもしれないです。
リアルワールドを数値で読み解こうとしている皆様、さぞ大変なのだろうなと推察いたします。
いいなと思ったら応援しよう!
