
【JKI】038_Word_Windows_01_コンポーネント

【JKI_038】課題を確認
Just KNIME It! (JKI)
今回の挑戦はこちら

問題文のところだけをDeepL翻訳し少し加筆して以下に
課題38: 言葉の窓
レベル: 中程度
説明:
あなたは、単語がどのような文脈でどのように使われるかを研究している研究者です。
ある単語が与えられたとき、その単語の前に現れる3つの単語と、その単語の後に現れる3つの単語を抽出することがあなたの仕事の1つです、
もし可能ならばですが(例えば、ある単語はその前に何も現れません)。
この課題では、改行、大文字小文字、句読点、前後の単語がないなど、この種の検索によくあるトラップを含むさまざまな例が提示されます。
あなたのソリューションは、
(1)大文字と小文字を区別せず、
(2)ウィンドウサイズに応じた複数の単語を抽出する
ことです。
スペルミスは無視してください。
ボーナス:コンポーネントを作成し、他の人があなたの作品で遊べるようにしてください。
「eggs」をターゲットワードとした場合の入出力例:
(INPUT) Eggs are great -> (OUTPUT) Eggs are great
(INPUT) I like eggz. -> (OUTPUT) ? (empty since no exact match)
(INPUT) I really do like eggs that (line break) are covered in ketchup. -> (OUTPUT) really do like eggs that are covered
(line can be retained if preferred)
(INPUT) I love eggs, but they need salt. -> (OUTPUT) I love eggs, but they need
(INPUT) Is KNIME secretly in love with EGGS??? -> (OUTPUT) in love with EGGS
【サンプルデータはトラップだらけ】
サンプルデータ:
Excelで開いて見ます。
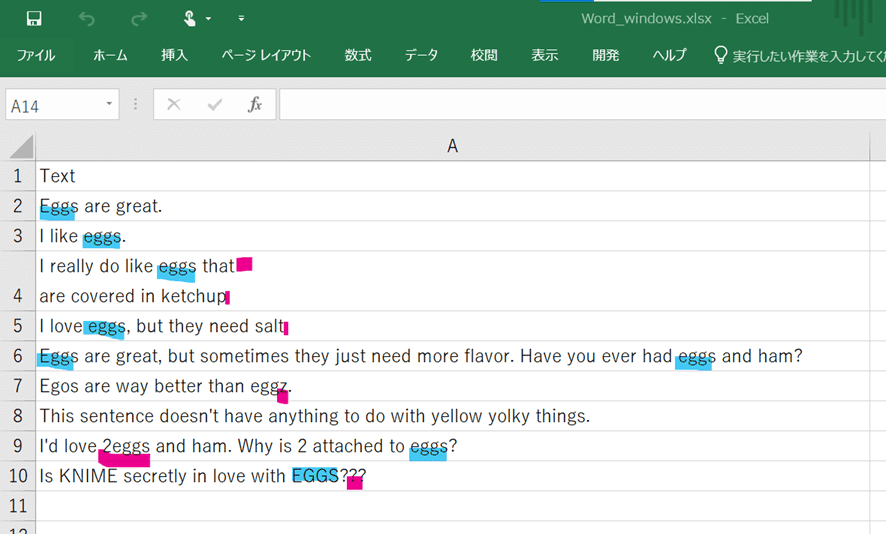
水色表示は大文字と小文字を区別しないで「eggs」の完全一致検索でヒットすべき単語を示しています。問題文で書かれている通り文頭にも文末にもありますし、2文にわたって一行で2回ヒットもあったりします。
一方で、「この種の検索によくあるトラップ」とはこれかなという個所は赤色表示しました。セル内改行はデータ処理プログラミングする時は本当に嫌ですが、人が見るだけなら便利ですよね、実際のところ。
「2eggs」はスペース入れ忘れのトラップかと思ったら、文脈からして今回は「eggs」と検索してもヒットしなくていいと判断しました。ひねってあるなぁ。
【コンポーネントの機能概要】
珍しく今回は結論である解答から紹介してみます。

右のコンポーネントを実行してViewを表示させると、
① Excelからの入力を確認し、必要ならスペルミスを修正もできる一覧。
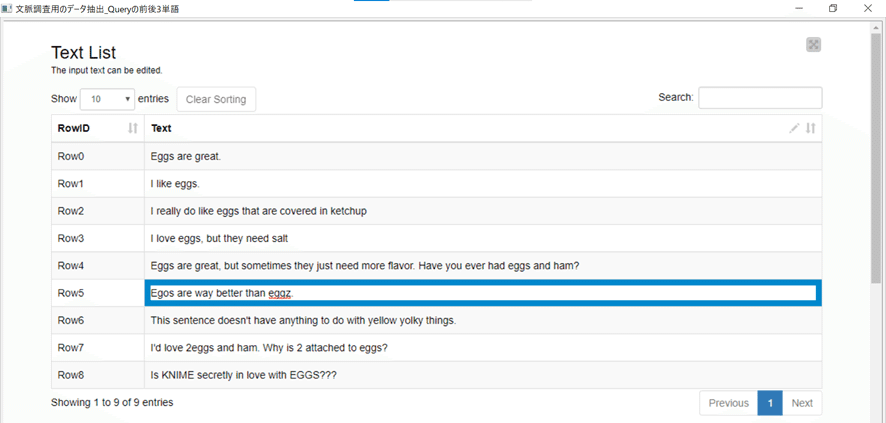
KNIMEの機能ではないですが、スペルミスかもしれないところは赤色下線が出ています。
② 検索用の単語を入力してSearchボタンで検索をかけなおせます。

③ 検索結果の一覧、一行で複数回ヒットするなら複数行に分かれて出ます。
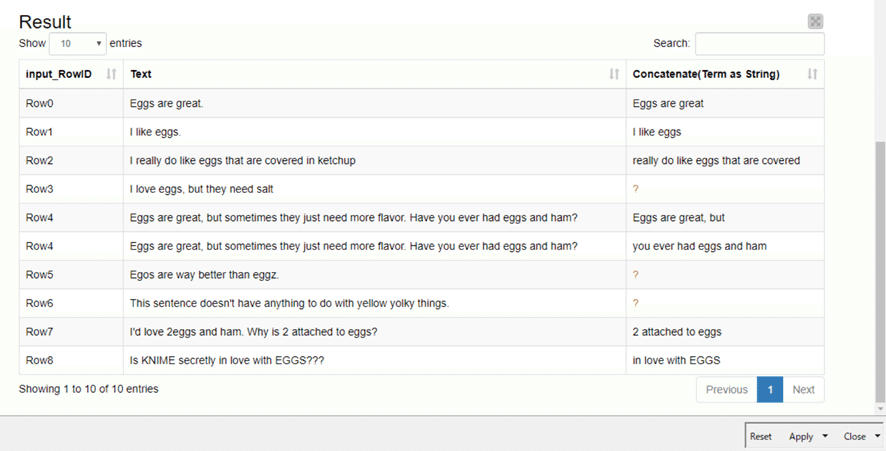
それなりにできたとは思うのですが、コンポーネント作成までの道のりは出題者の仕掛けたトラップにほぼ全てひっかかるいばらの道でした。
上記のWorkflow (WF)を見ながら下記のセリフを思い出す人は私だけかなとは思いつつ引用します。
青い水面に美しく優雅に浮かぶ白鳥は、しかし、その水中にかくれた足で絶え間なく水をかいている、けっている。だからこそ、常に美しく優雅に浮かんでいられる。
【WF紹介】
【Excel Reader】
いつも通り相対パスでの読み込みです。

結果:

Row2が目立ってトラップのように見えますが、今回の出題内容は句読点の扱いが変わっていて苦労しました。
出題された例を見ていくと、句点「.」「?」「!」は先述の例では削除対象で、読点「,」は単語にくっついたまま処理します。どうしてこのルールにしたんでしょうか。両方削除してよければ楽だった…。
(INPUT) I love eggs, but they need salt. -> (OUTPUT) I love eggs, but they need
(INPUT) Is KNIME secretly in love with EGGS??? -> (OUTPUT) in love with EGGS
【入力制御】

【検索対象データ前処理】

【完全一致検索実行と単語群抽出】

【結果の集約と可視化】

WFがかなり長くなってしまいました。トラップに引っかかってはその対策をしてと進めた結果で、効率が悪くてお恥ずかしいですが、次回に概要を紹介します。
KNIME Hubに解答は上げています。
おまけ:
【JKI_037 感想戦】
先週のJust KNIME It! (JKI)は
重複する分をいかに効率よく削除するかを問われました。
ノード 3 個で多分できました。
単なる繰り返しだったようなので、特徴のある区切り(半角スペース4連続)を見つけてただ分けただけです。
一方、公式解答はNode 5 個でしっかり重複かどうかを判定しての削除なので、より確実ですし、今回のサンプルデータ以外にも使える仕組みになっています。

KNIMEで自然言語処理をするときに、
区切り文字で分ける処理をCell Splitterですると横並びの多数の列になり、
一旦縦横変換して、
何らかの処理をして(上図は重複処理)、
GroupByのConcatenate処理で一まとめにする
っていうフローがよく使われるようです。
JKI第38回ではそれ以外の手法も使ってみたので次回にまた。
いいなと思ったら応援しよう!
