
【W2】指標による化合物フィルタリング_06_Step3_後編

【本パート(W2)の目的】
W1でChEMBLから取得した化合物群を
ルールオブファイブ(Ro5)のクライテリアに基づきChEMBLから集めた化合物をフィルタリングします。
薬らしくない分子を取り除く手法の一例を学ぶことが目的です。
(原典)
https://magattaca.hatenablog.com/entry/2020/04/12/180559
【前回までのおさらい】
「2. Molecular filtering: ADME and lead-likeness criteria」メタノードの中の
Step1~2にて
Ro5の判定に用いる、4つの化学計算結果でのフィルタリングをして、
• 分子量が500ダルトン以下
• 水素結合アクセプターが10以下
• 水素結合ドナーが5以下
• LogP (オクタノールー水 分配係数) <= 5
Step3上部では箱ひげ図を描きました。
で、前編と後編の間に閑話休題を入れて現在に至ります。

【Step3下部のworkflowの役割】
下部ワークフローでは
・平均と標準偏差の算出
・Table Vew表示
・CSVファイルへの書き出し
をしています。
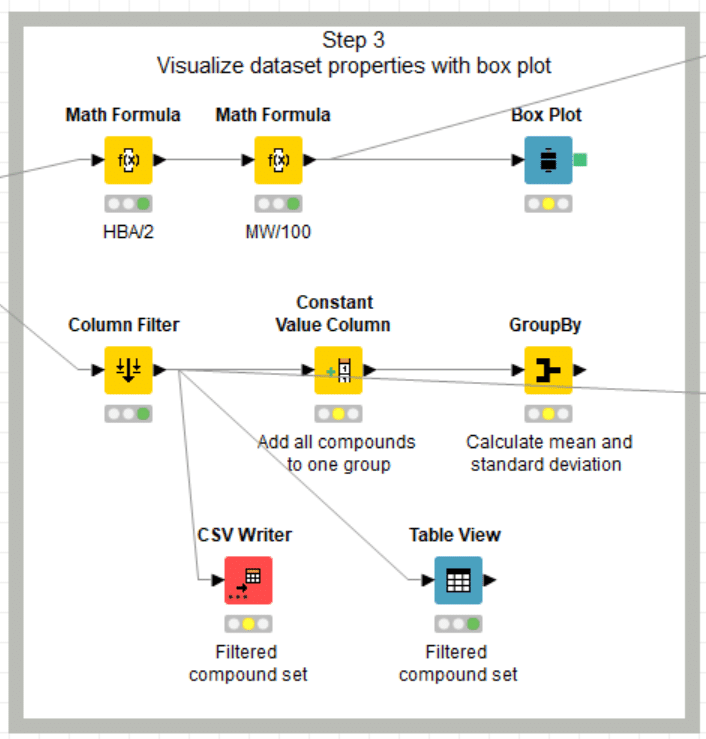
【Column Filter】
機能に関しては既出ですが、念のためまっきーさんの記事は引用しておきます。
右ウィンドウに必要なカラムだけを選択しています。
今回も開発途中の消し残しカラム群も左ウィンドウに見えますが気にしないで。

結果は

【Constant Value Column】

機能はまっきーさんの記事から引用いたします。
一定値列を挿入したいときはConstant Value Column
今回の設定は

結果は

全ての行にGroup = “1”と文字列として入力されてます。
次のGroup Byでの集計用に、全ての行に共通の値が欲しかったようです。
【Group By】

便利でよく使うノードです。そしてまっきーさん、いつもお世話になっております。どちらも本当にありがとうございます。
今回は4つのデータについて平均値と標準偏差を一気に計算しています。
設定:
Groupカラムで同じ値が入っている行(つまり今回の全ての行)を集計しています。

集計するのは、

ExactMW, SlogP, NumHBD, NumHBA
4つのカラムの平均値と標準偏差です。
結果は以下の通りでした。

【Table View】

機能が当たり前すぎるのか、日本語ではだれも説明していなさそうです。
活用例としては発展的にはこちら。
美麗です。
さて今回はとても一般的な利用法です。

メタノードの外のTable Viewも同じ設定なので、説明は割愛します。

【CSV Writer】

まっきーさんの説明の丁寧さには脱帽です!
どうでしたか?あえてものすごく細かく解説してみましたが、もはや雑学レベルで使用頻度が少ないと思います笑
次の記事もきちんと書きたいと思いますー
楽しみつつのこの高み。
「知之者不如好之者、好之者不如楽之者」
https://bunlabo.com/analects-do-fun-is-best/
との言葉を想います。
さて今回の設定ですが、下図の通りです。

前にも書きましたが、自分用ならSaveする先(URL)は変えた方が後でわかりやすいと思います。
<変更例>

以上でW2のデモデータの解説を終わりました。寄り道が多いと自覚はしています。
読み続けていただいている方、本当に感謝です。
と言ったすぐなのですが、
W3へ進める前に、下記の話題は共有させていただこうと思います。
おまけだけど大切なお話し:
【化学構造式データの前処理について】
Step2の説明時に気付いて後日話すといった件を次に扱います。
結論を言ってしまいますと、本来はRo5の判断基準の一つとなる分子量データは各化合物のフリー体に関して算出するべきです。
更に本当に細かいことを言うと、構造重複のチェックや、化学計算値でのプロファイル比較をしたい場合には、処理対象となる構造データ群は前処理を行って正規化されていることが望ましいです。
次回以降も大幅に寄り道をさせていただき、構造正規化や指標としての分子量について書いてみます。よろしければどうかお付き合いください、
いいなと思ったら応援しよう!
