
【JKI】013_Onsite and Online Transactions

【JKI_013】課題を確認
Just KNIME It! (JKI)
今回の挑戦はこちら

問題のデモデータ部分は上記を参考にするとして、問題文をGoogle翻訳とDeepL翻訳のいいとこどりに少し加筆して以下に。
課題13: オンサイトとオンライン取引
レベル 中級
説明 あなたの会社では、オンラインとオンサイトの取引に関するデータを、次のような形式の表形式データセットで管理しています。
(入力データは上図の通り)
この課題では、次のような指針のもと、(購入した製品に関連する)取引データから数字を抽出することが求められています。
(1) オンサイトでの取引データが「L」で始まる場合、その最初の12桁を取り出します。
それ以外の場合は、最初の6桁を取り出します。
(2) オンサイト取引データに欠落している値がある場合は、オンライン取引データから文字列を取得します。
このタスクを実行する最も効率的な方法は何でしょうか。上記の例では、次のような出力列を生成する必要があります。
(出力データは上図を参照、ただし1ヶ所のみ誤記有り(推定))
要するに、Onsiteというカラムのデータを「L」で始まるかどうかで分岐処理したのち空白値の処理が出来たらよいと認識しました。この問題が難しいのは最も効率的な方法を求められているからだと思います。
以下には私なりの最適解と思ったKNIME workflow (WF)を紹介します。
【入力データテーブル】
Dataset: For this challenge, create the dataset illustrated above as input with the Table Creator node.
との出題でした。
Table Creatorノードの設定は以下の通りとしました。

ここまでをWF内でまとめると下図の通り。

【条件分岐】
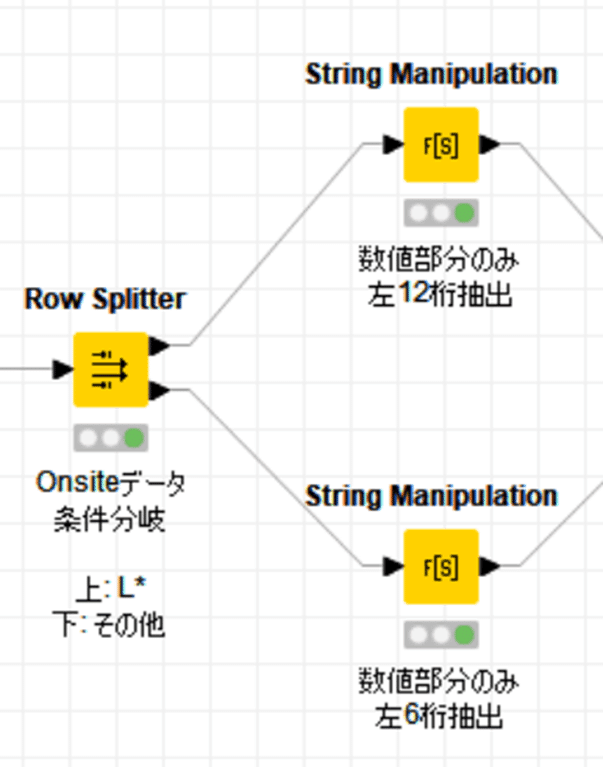
Onsiteのデータが「L」で始まるかどうかの分岐は下記の設定で実行しました。
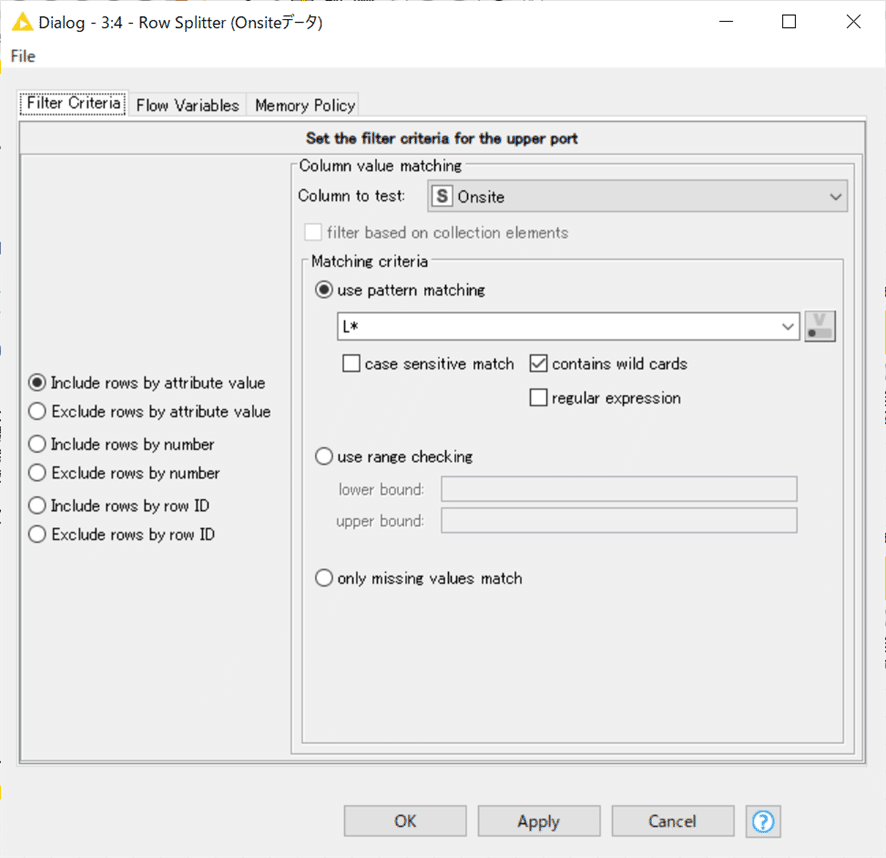
「*」はワイルドカードなので任意の文字列が該当します。
【文字列操作でデータ整形】
まっきーさんによるノード説明自体に私が加える言葉はないです。あるものですか!
ただ、今回は複数種の処理を一つのノードで実施してみますのでそこだけ少し追加説明した方がよさそうです。
課題の(1)前半
取引データから数字を抽出することが求められています。
(1) オンサイトでの取引データが「L」で始まる場合、その最初の12桁を取り出します。
を例にどのように実装したかを説明します。
実行したい操作は
A) 数字を抽出
B) 最初の12桁を取り出す
の2段階と考えます。
String Manipulationノードならもちろん両方をまとめて1ノードで処理可能です。
ただし複数の関数を組み合わせて使います。
以下でより詳しく今回の利用法に特化して追加で説明をします。
【String Manipulationはご立派すぎて】
String Manipulationノードの関数をまっきーさんやすさんがごく一部説明してくださっています。全てを説明しないのは関数の種類が多いからだけではないと思っています。
すさんが言う通り、
Descriptionにサンプル付きで全部書いてあるんだもん
ということで、日本語化されたノードのディスクリプションを見てみましょうか。
検索や置換、大文字の使用、先頭や末尾の空白の削除など、文字列を操作します。
例を挙げます。
c0 という名前の列から先頭と末尾の空白を削除するには、strip($c0$)
顧客の名前が Mr と Mister というタイトルの列に入っていて、Mr だけが使用されるようにデータを正規化したい場合は、次の式を使用できます。
replace($names$, "Mister", "Mr") または、replace(replace($names$, "Mister", "Mr"), "Miss", "Ms")
または、名前が text の列に含まれる文字列の文字数を知りたい場合は、 length($text$) 式の一部であり、入力データ (または他のラップされた関数呼び出しの結果) ではない文字列は、二重引用符 ('"') で囲む必要があることに注意してください。
また,文字列に引用符が含まれている場合は,バックスラッシュでエスケープする必要があります(「-」)。
最後に、一重引用符やバックスラッシュなどのその他の特殊文字は、バックスラッシュでエスケープする必要があります。
例えば、文字列の中にバックスラッシュが1つある場合、2つの連続したバックスラッシュ文字として記述します。
んんっ、わからん。いや頑張ればわかるんだけれども。要するにできることが多すぎてすべてを説明されても受け手がキツイのです。
今回重要なのは実は下記の記述です。
Function
1つの関数を選択すると、その説明が表示されます。
ダブルクリックすると、式編集画面にその関数が挿入されます。
現在選択しているものを置き換えるか、単に現在のキャレットの位置に挿入されます。
カテゴリーを選択すると、表示される関数のリストを絞り込むことができます。
キャレットとか普段言わないのでイメージはつかみにくいかもしれませんが、指定して入力する場所を指すと思えばいいです。
https://wa3.i-3-i.info/word11591.html
入力位置を示すキャレットについて説明します。
まずはメモ帳でもWordでもいいので開いて、ちょっくら文字を入力してください。
「ポチポチすると、ここに文字が入りますよ~」を示す縦棒がありますよね。
チカチカと点滅している「|」っぽい見た目のやつです。
【文字列処理の関数のディスクリプション】
String Manipulationはご立派すぎて詳しく説明しだすときりがないです。今回の設定に関して絞って以下続けます。
設定:

ノードの設定画面の中にさらに関数のDescriptionがあり、Functionを選ぶとExamples付きで説明してくれます。すさんがコメントしていたDescription
はこちらだと思われます。
ここ、日本語化出来たら最高です、インフォコムの皆さん!
上図ではsubstr関数を選んでます。以下具体的に見ていきましょう。
【substr関数で決まった長さの文字列を抽出】
substr(str, start, length)
と表示されているsubstr関数のDescriptionをGoogle翻訳の助けを借りて以下に訳してみました。
substr(str, start, length)
は3つの変数を入力する文字列処理用の関数なのですが、
変数の”start”で定義された場所から長さ”length”で定義された文字を取得します。
startはゼロベースです。つまり、最初から開始するにはstart=0を使用します。
startの負の値はゼロとして扱われます。 長さがゼロまたは負の長さの場合、空の文字列になります。
start + lengthが文字列の長さを超える場合、残りの文字が返されます。
例:
substr( "abcdef"、0、2)= "ab"
substr( "abcdef"、-3、2)= "ab"
substr( "abcdef"、2、10)= "cdef"
substr( "abcdef"、10、2)= ""
substr( ""、*、*)= ""
substr(null、*、*)= null
*任意の数にすることができます。
どうですかね、具体例がたくさんあってありがたいです。
変数の”str”に定義した文字列からある長さの文字列を抽出して来れます。
これ、今回の
B) 最初の12桁を取り出す
に使えそうです。その前に
A) 数字を抽出
の処理をした文字列を変数”str”に定義すればいいわけですね。
言うなれば
substr(str, start, length)については
substr(「数字を抽出した文字列データ」, 0, 12)
とすれば目的達成なわけです。
【数字のみを選択的に抽出】regexReplace関数での文字列処理
では数字を抽出するにはどうするか。
先に例示した設定ではregexReplace関数を使っています。
regexReplace関数のDescriptionを見てみます。

同様に訳してみます。
文字列に正規表現を適用し、正規表現が一致する場合はstrを置き換えます。
例:
regexReplace( "abc"、 "[a-zA-Z] {3}"、 "cba")= "cba"
regexReplace( "aBc"、 "[a-zA-Z] {3}"、 "AbC")= "AbC"
regexReplace( "abcd"、 "[a-zA-Z] {3}"、 "ABC")= "ABCd"
玄人さんはこれ見ただけで分かるのでしょうが、初見にはきつい正規表現、いよいよ説明が必要かと思います。知っている方は飛ばしていただいていいです。
【正規表現は便利だがこれまた情報量が多い】
私は自分では手に負えないと思った案件はためらわないで引用したり、割愛します。
今回は私がよく見る下記サイトの紹介から。
正規表現とはなにか?
端的に言えば、「いくつかの文字列を一つの形式で表現するための表現方法」です。
では、なぜこの表現方法が有名なのかといえば、この表現方法を利用すれば、たくさんの文章の中から容易に見つけたい文字列を検索することができるためです。
今回であれば、数字だけを残したいので数字以外を指定する正規表現ができればいいのです。

とすれば、2番目の文字は、アルファベットと数字以外の文字ということになります。
上記を参考に、Onsiteカラムから[^0-9]すなわち数字以外の文字をすべて空白に変える(“”)設定をしたのが下のExpressionで紫色に強調表示した部分です。

数字以外が消去されるので数字だけのデータに変わると言う処理になってます。
そして、さらにそのregexReplace関数で処理した結果がsubstr関数の変数”str”に入っているので、0番目(つまり左端)から12番目まで文字列を抽出してくると言う処理になっていますね。
ちなみに上記の式の入力は手入力するのは[^0-9]とか0とか12とかだけで、関数はFunctionウィンドウで望みの関数をダブルクリックでExpressionウィンドウでカーソルを合わせていた場所に入るので、自分でやってみていただけるとわかると思います。
【文字列処理の分岐処理と集計】
お疲れさまでした。上記で「L」から始まるデータの処理は出来たので、もう一方の分岐側も見ていきましょう。設定はこちら。

抽出する文字数だけ6文字に変えましたが他は同様ですので省略します。
分岐処理が終わったのでデータ統合します。
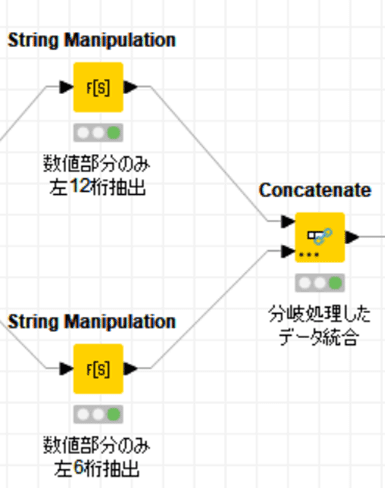
結果:

Onsiteデータがあるものは適切にProduct Codesカラムに値が入りました。
【Column Merger】

(2) オンサイト取引データに欠落している値がある場合は、オンライン取引データから文字列を取得します。
を下記設定で実施できます。
上述の通り、Onsiteデータが欠落しているとProduct Codesカラムも空白となっているからです。

結果:

【Sorterで順番をそろえて処理完了】
分岐処理などすると、しばしば行の順番が入れ替わってしまいますので、Indexカラムがついていたのを利用して元の順番にして完了としました。
設定:
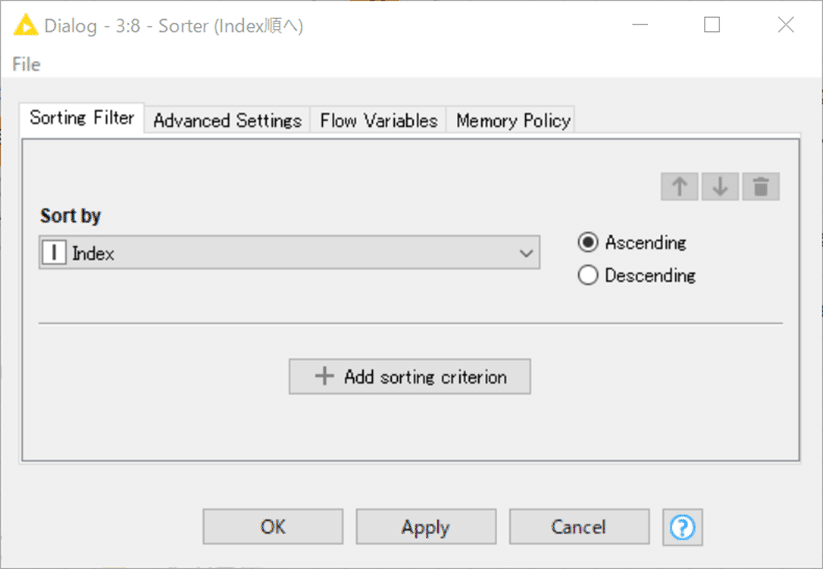
結果:

これにて解答完了。WFはKNIME Hubに上げました。
感想戦:
おまけ:
【名もなきKNinja】
何回か話題にしてきたKNIME Data Talks JAPAN 2022では日本の創薬化学者にとって注目の発表があったことは昨日の記事でも取り上げました。
アステラスの瀬尾さんはもともとは非プログラマーの研究者だったと推察しますが、いまやAIも活用したDX創薬のトッププレーヤーとなられた感があります。
連想するのは豊臣秀吉の天下取り。
その陰で名もなき忍者が暗躍していたりして。
参加して見て思ったのですが、言語の壁って私には厚かった。
このnoteを読まれた方はお気づきの通り日本語だと聞かれてもいない余計なことまでしゃべりたがる方なのですが、すっかり聞き役に回ってしまいました。
がや(ひな壇芸人)として爪痕を残すことすらなかなか立派なことなのだとあらためて知りました。
参加者の方々のKNIME愛がすごかったので、興味があればご覧ください。
Just KNIME It!は最近公式解答との答え合わせしかできていなかったのですが、今回の参加者さんたちはいったいどんな名解答を見せてくれるんだろうと今後の愉しみが増えました。
おまけ②:JKI_012公式解答を見て思うこと
前回の公式解答は、私の解答に近くて嬉しかったです。
ところが上記の公式解答が決定的に違うのが

自分でJSONとXMLどちらを処理するか選択できるとのこと。
出題者の意図がわからなかった部分はこれかと納得。
ここ、KNIME Analytic Platform (AP)のver. 4.5系じゃないと閲覧すらできなかったです。

ダイナミックデータアプリの強化
これまで「Refresh Button Widget」ノードでのみ提供されていた機能と同様に、ウィジェットに新しい再実行機能が追加されました。
データチームは、データアプリのUXをより柔軟にすることができ、以下のような特定のウィジェットの値が変更されたときに自動的に再実行を行うことができます。
・Boolean Widget
・Column Selection Widget
・Column Filter Widget
・Multiple Selection Widget
・Nominal Row Filter Widget
・Single Selection Widget
・Value Selection Widget
TeachOpenCADD-KNIMEの体験記がもうじき書きあがるので、その後は私もKNIME APを4.4.1から4.5.2以上へ上げようと思います。その時はまたこのWFのかっこよい操作性を楽しみたいものだと思いました。
記事を読んでいただきありがとうございます。 先人の智慧をお借りしつつ、みなさんに役立つ情報が届けられたらと願っています。 もしサポートいただけるなら、そのお金はKNIMEの無料勉強会の開催資金に充てようと思います。