
【W7】活性予測のための機械学習モデル_17_Step3_11_SVM_WF

【W7の目的】
ターゲット分子(EGFR)に対して新規な化合物の活性を予測するために、様々な教師あり機械学習(supervised ML)アルゴリズムを使用する方法について学習します。
前回はサポートベクトルマシン(SVM)のRBFカーネルについて勉強しました。
今回はSVMのKNIME workflow (WF)実装例を見ていきたいと思います。
【SVMのWFを見てみよう】

k-分割交差検証については既に話しました。基本構成はランダムフォレストの時と同様です。
さっくり進めたいところですが、以下ちょっと気になることはコメントしておきます。
X-Partitionerの設定ですが、

並行して実行するランダムフォレストやニューラルネットワークとはRandom seed(123456789)が違います。つまり交差検証でのデータの組み合わせが他の2つの機械学習と揃いません。
もし機械学習アルゴリズム間での精度比較をしたい場合は学習データと検証用データは同じものを用いておくべきかなと思って気になってのコメントでした。単に機械学習を体験するだけであれば大きな問題では無いかと思うので次へ。
【SVM Learner】
日本語化されたノードディスクリプションを引用します。

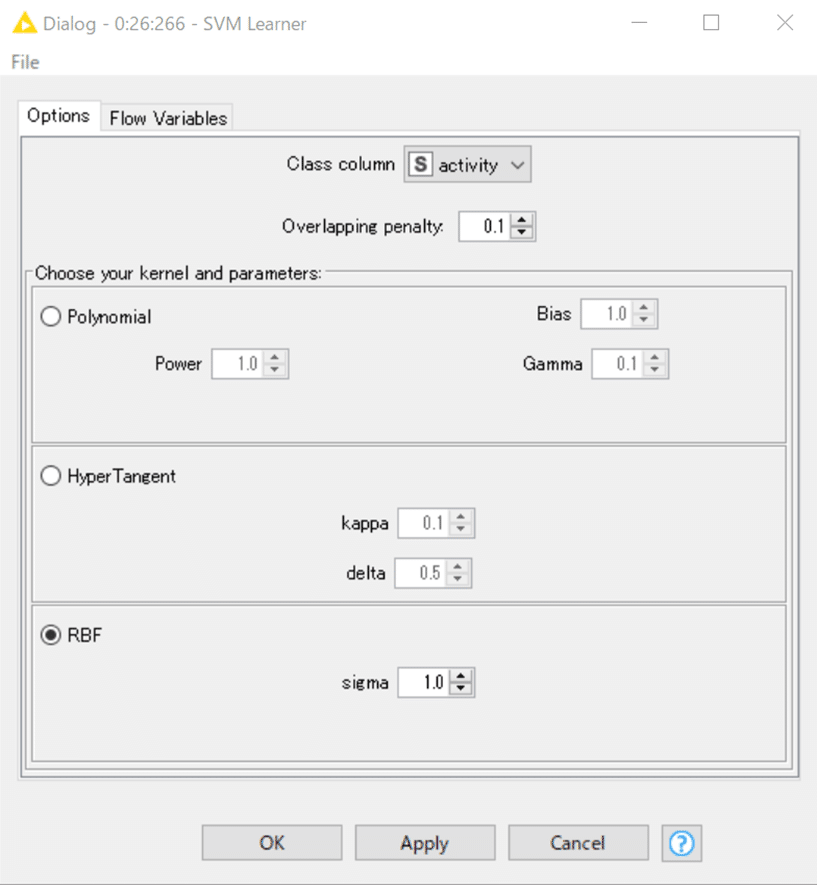
設定は既に前回までに紹介していますがもう一度。
結果;
生成したモデルが出力され、次のSVM Predictorへモデルの設定が引き継がれます。
【SVM Predictor】

設定:

ディスクリプションとは一見すると異なる画面構成になっているので戸惑いました。
ただ、機能としては書かれている通りで、予測値のカラム名を変えたり、
クラスの確率の列(正規化された分布列?)の追加も可能ということだと思います。
結果:カラムは並べ替えてあります

これまでと同様ではあるのですが、予測された結果がほとんど「1.0(活性あり)」になっているのが気にかかりました。
【集計結果】
X-Aggregatorはこれまでと全く同じ設定です。

結果:

4511化合物の結果が集計されています。
今回も予測精度の情報は先行して見ておきましょう。

Overall Accuracyが0.563
正直低いと思いました。
これはいったいどうしたことか?
【ハイパーパラメータを変えてみた】
ここからは寄り道をして、デモデータから一部を変えてしまいます。
気になったのはSVM LearnerのOverlapping penaltyでした。
そこで誤分類をどの程度許容するかを決めるOverlapping penaltyを0.1から1.0に変えてWFを走らせ直してみました。ペナルティが大きくなるので、より誤分類を許容しなくなります。SVMは計算コストが高いと言われますが、今回のパラメータ設定では小1時間かかりました。sigmaを変えてより決定境界(超平面とも言うようです)の複雑さを増すとさらに時間がかかるでしょう。

Overall Accuracyが0.775と改善しました。
どうやらハイパーパラメータを最適化することで精度は向上しそうなので、SVMの本来の能力が発揮できていなかったデモデータだったようですね。
またそもそも機械学習アルゴリズム間でOverall Accuracyを比較するにはせめてk-分割交差検証のRandomSeedも合わせておくべきかなと思います。
後学のためにいつかha-te-knimeさんの記事など参考にして最適化検討もしてみようかなと思います。
次回はStep4へ。各機械学習の精度に関する評価結果を見るパートです。
おまけ:
【KNIMEと機械学習自動化】
KNIMEでの各種機械学習アルゴリズムの並列検討と言えば、この記事が気になっています。
まあ、これKNIMEで実行できますけどPythonですよね。
サイトを一部Google翻訳して引用します。
欠落値の代入、ワンホットエンコーディング、カテゴリデータの変換、特徴エンジニアリング、さらにはハイパーパラメータチューニングなど、PyCaretはすべてを自動化します。
この記事を読まれている方々であれば、先週(2022.4.20-21)のKNIME Data Talks JAPAN 2022のアステラス製薬株式会社の瀬尾さんの発表、ご覧になった方が多いかと思います。
KNIME Serverを用いて構築した低分子創薬における化合物デザインのためのAI創薬プラットフォーム
圧巻でしたね。
DataRobotでの予測をKNIMEで実行するWFを作った方もKNIME日本コミュニティにいらっしゃったりするんですが、おそらくPython Scriptノードも利用されているのではないかと推測します。
玄人な皆さんが高度な機械学習技術を非プログラマにも利用できるようにしてくださることに感謝します。
また、KNIMEがPythonとの連携機能をどんどん強化してくれているのも本当にありがたいことですね。
従来の Python Script ノードは入力テーブルの行数が10万超えた辺りでかなり遅くなっていたのだが、劇的に改善したらしい。テーブルを入力してそのまま出力するだけの処理でベンチマークしてみた。5万行超えた辺りから明らかな性能差がみられる。
私は今回は5000行弱しか扱ってないですが、玄人さんも認める性能改善、今後もますます楽しみです。
記事を読んでいただきありがとうございます。 先人の智慧をお借りしつつ、みなさんに役立つ情報が届けられたらと願っています。 もしサポートいただけるなら、そのお金はKNIMEの無料勉強会の開催資金に充てようと思います。