
【JKI】016_Grouping_Data_into_CSV_Files

【JKI_016】課題を確認
Just KNIME It! (JKI)
今回の挑戦はこちら

問題文をGoogle翻訳し少し加筆して以下に
課題16:データをCSVファイルにグループ化する
レベル:簡単
説明:単一の販売CSVファイルを、グループ名に従って名前が付けられたグループに基づいて小さいファイルに分割するように求められました。例として、元のファイルに次のデータが含まれている場合:
Sales Group
100 b
200 a
300 a
2つのファイルを生成します。1つはGroup_aという名前で、もう1つはGroup_bという名前です。それらは次の構造になります。
Sales Group
200 a
300 a
と
Sales Group
100 b
このタスクの解決策は一般的である必要があります。つまり、任意の数のグループで機能する必要があり、グループの名前は重要ではありません。
【入力データの入手と確認】
CSVファイルへのリンクは
です。いつものようにWF内に格納して読み込んでみました。
設定:

結果:

10000行のデータですね。
分けるためのGroupはaからzまであるようです。
【Group Loop Start】

日本語化されたノードディスクリプションより
グループループを開始し、各反復で別のグループの行を処理します。
グループ化の対象となる列を指定する必要があります。
デフォルトでは、ループを開始する前に、指定された列に基づいて入力データテーブルがソートされます。
今回のデータではGroupはaからzまであるのでその順に並べ替えてから実行してくれると言うわけです。知らなかった。
また、まっきーさんのこの記事を見たらもう今回の解答のほとんどが書かれています。
設定:
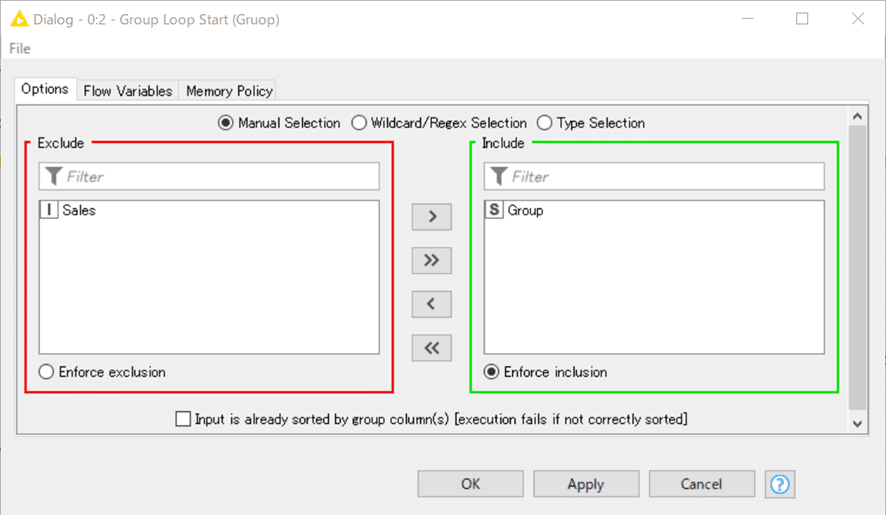
結果はループを回すので、ちょっと伝えにくいですが、Loopが終わった最後のこのノードからの出力はこちら。
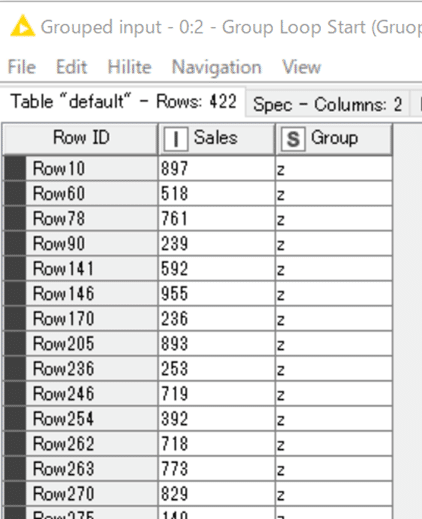
最後のGroupであるzの422行だけが残されているのが分かります。
【ファイル名と保存先を決める変数】
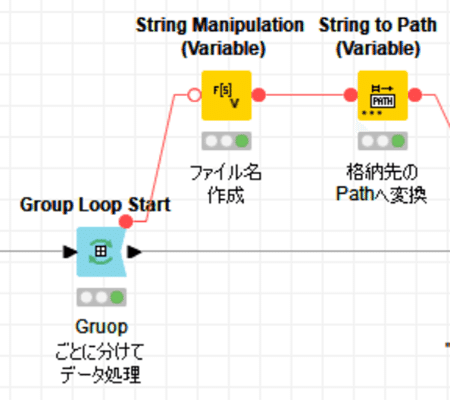
先ほどのノードは上記のデータテーブル以外に変数でどのグループを処理しているかも出力しています。

この変数を使ってファイル名と保存先を定義していくのが上図の二つのノードです。
設定:

Group_(Group名).csvというファイル名の変数(文字列型)をループごとに発生させます。

結果:
上記で作成したファイル名で、相対パスでWF内の「data」フォルダにファイル保存先を指定します。最近のKNIMEはPath型の変数として保存先データを各種Writerに渡します。

【CSV書き込み先は変数で指定】

左上から変数を受け取り、CSV書き込み先を定義します。
設定:


ちょっとどの変数に保存先を入れるか迷うかもしれませんが、上記の通りです。
Writerの後はフロー変数を使って次のLoop Endのノードに繋いで完成です。
レベルは簡単とされています。簡単というよりはとても多くの方が使いうる頻出操作だったように思いました。
KNIME Hubに解答を上げてあります。

おまけ:
【ファイル名に絵文字とか】
ファイル名に絵文字
— ほりい なおき (@hor11) April 11, 2021
約5%の方はファイル名に絵文字も使うんですね。
今回の解答WFってGroupカラムに入力された任意の文字列を使ってPathを指定します。堅牢性は大丈夫なのかな。簡単なようで考えさせられる課題でした。
ファイル名は他にもいろいろ要注意らしいですよ。
Windows一般の教養ネタです。
エクスプローラーでは閲覧も、削除も、リネームもできなくなるような悪質としか言いようが無いファイル名を取りあげて解説しています。
これらは特にWindows10で仕様が大きく変わっており、見つけにくく、削除しにくく、そのため悪用しやすくなっています。
なかなか多様で読みごたえがあるのでよろしければどうぞ。
他にもSharePointのとーっても深い階層に長―い日本語名のファイルが格納されていることに毒づいている人を見たことがあります。
人間って多様性ありますよね。
おまけ②:
【JKI_015 感想戦】
多様性と言えば、前回のJKI_015の解答は多様性の宝庫でした。初の難易度Hardだったので、正解って一つに決めきれないようでした。
公式解答も含めていくつも見た中で、これはスマートだなと思ったのがこちらです。

出色はString Manipulation一つでの高効率なデータ切出しです。
replace(substr($Content$,indexOf($Content$,"DAY MAX"),indexOf($Content$,"SUM")-indexOf($Content$,"DAY MAX")-1)," "," ")一見するだけだと何をしているかつかみきれないかもしれないです。
結果は
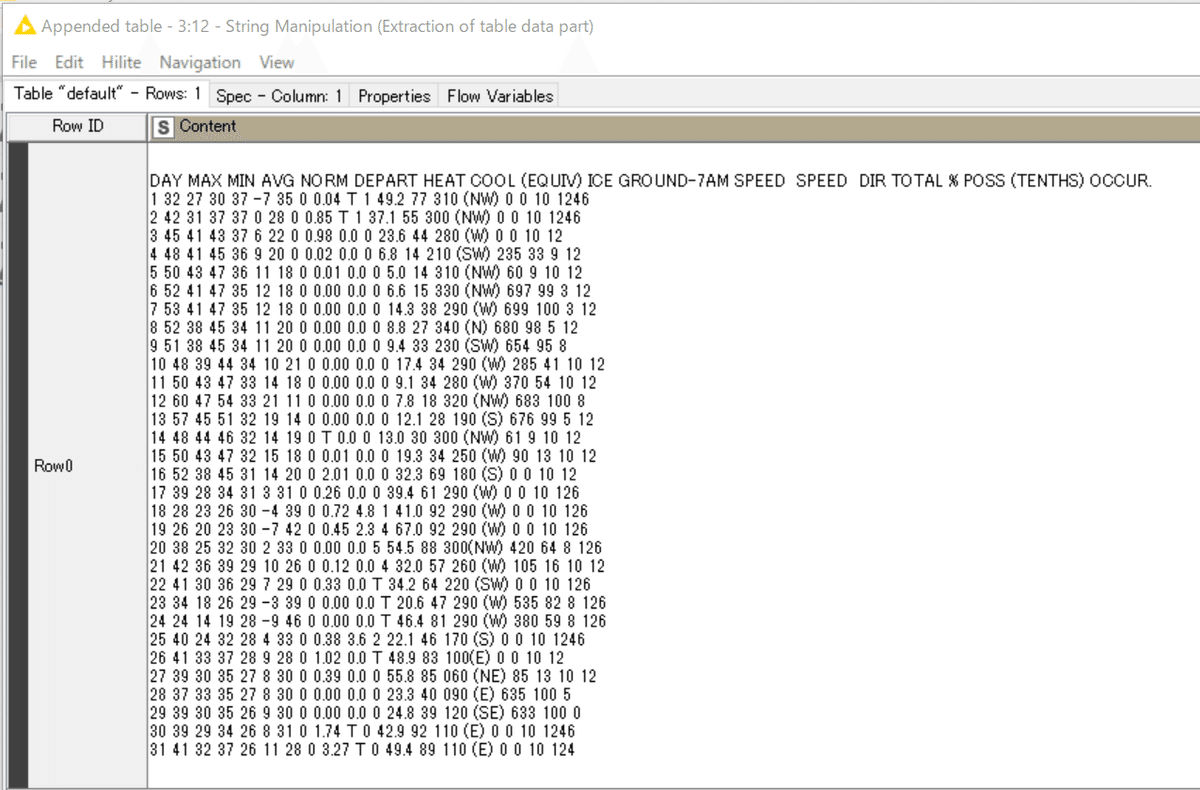
たった一つのノードの前処理で、一番欲しいデータ部分を効率よくとってきていて感心しました。
Contentsの文字列のどこからどこまでを切り取るか指定するのはうまい絞り込み方法ですね。
しかもこれ、" " (ダブルスペース) を" " (スペース)に変換する処理がしてあります。
この前処理をすることで、3つあとのCell Splitterノードでの"Split by blank"処理で必要なカラム名を取得しやすくなる伏線となっています。詰将棋のようだ。玄人のworkflowって味わい深いなと思いました。
sryuさん、難易度が低いうちは手を出さないで、JKI初の高難易度課題からの初参戦というのも渋いです。またのご参加お待ちしております。
記事を読んでいただきありがとうございます。 先人の智慧をお借りしつつ、みなさんに役立つ情報が届けられたらと願っています。 もしサポートいただけるなら、そのお金はKNIMEの無料勉強会の開催資金に充てようと思います。