
【JKI】024_Modeling_Churn_Predictions_Part_2_01_AutoML

【JKI_024】課題を確認
Just KNIME It! (JKI)
https://www.knime.com/just-knime-it
今回の挑戦はこちら

ちなみに先週の挑戦はこちら。一見すると間違い探しのようです。

ところが急激に内容は高度化しています。
問題文をGoogle翻訳し少し加筆して以下に。
課題24:チャーン予測のモデリング-パート2
レベル:簡単~中程度
説明:先週のチャレンジと同様に、通信会社は、アカウントの属性に基づいて、どの顧客が解約するか(つまり、契約をキャンセルするか)を予測することを求めています。同僚の1人は、トレーニングデータをまったく変更せずに、与えられたすべての属性をそのまま使用することで、テストデータの精度を95%以上達成できたと述べています。この場合も、予測されるターゲットクラスはチャーンです(値0はチャーンしない顧客に対応し、1はチャーンする顧客に対応します)。
テストデータセットでこの精度を得るには、トレーニングデータセットでどのモデルをトレーニングする必要がありますか?この決定は自動化できますか?
注1: この課題に対するシンプルで自動化されたソリューションは、5つのノードで構成されています。
注2:この課題では、データセット内の属性またはクラスの統計的分布を変更せず、使用可能なすべての属性を使用します。
注3:問題を理解するためにさらに助けが必要ですか?このブログ投稿をチェックしてください。
【2つのデータセット】(トレーニングとテスト)
先週のPart1と全く同じです。むしろ変えてはいけないルール。
データセット入手先:
先週と同じく処理します。
【AutoMLコンポーネント利用例】
テストデータセットでこの精度を得るには、トレーニングデータセットでどのモデルをトレーニングする必要がありますか?この決定は自動化できますか?
この課題に対するシンプルで自動化されたソリューションは、5つのノードで
ってもうコンポーネントをいかに見つけてくるかの一択ですよね。もはやコンポーネントはノードの一種という扱いになっています。
のVerified Component群がその代表格だと思います。そして、その中でも最初に紹介されているAutoMLコンポーネント。

使い方もKNIME Hubにいけばいろいろと見つかります。
私はこちらのKNIME workflow(WF)をダウンロードしてみました。
すごいなぁKNIMEコミュニティ。
しかしWFを開こうとしたら下記の通りちょっと大変なことに。

思い出したのはこの曲
それはさておき、詳細は略しますがYesを押して多数のextensionsを入れました。
このWFを見てAutoMLなど機械学習関連のコンポーネントの組み合わせでここまでできるのかと感心しました。しかしちょっとやっていることが高度過ぎたので、今回の課題にはレベル的に合いません。そこでもう一つもっとシンプルな下記WFを見てみました。

残念ながらこのWFはCASE Switch Startが私の使っているver.4.4.1では使えないのでSelect Example Datasetコンポーネント2つが動かせなかったです。
https://nodepit.com/node/org.knime.base.node.switches.caseswitch.any.CaseStartAnyNodeFactory

【作者の皆さまごめんなさい】
悔しいです!!
よーし、これからお前たちを殴る!!
ということで、一部を抜き出して使ってみました。怒られるかもしれないとは思いつつ、4.4系ユーザーの皆さんにもとKNIME Hubに上げています。


IrisデータセットだとGradient Boosted Treesが最適解だったそうです。
…スクールウォーズやWFの作者の皆さんごめんなさい。
おかげさまでAutoMLで判別モデルを作る方法は知ることができたので、次回は提出したWFの解説へ進めます。
KNIME Hubに解答は上げています。

おまけ:
【JKI_023 感想戦】
今回の公式解答はこちら。
WFの構成は同一ですので正解だったですね。そこまではまあそうでしょう。
でも実は予測性能にかなりの差が。
公式解答:

私の解答:

もちろん理由は簡単です。
公式解答:
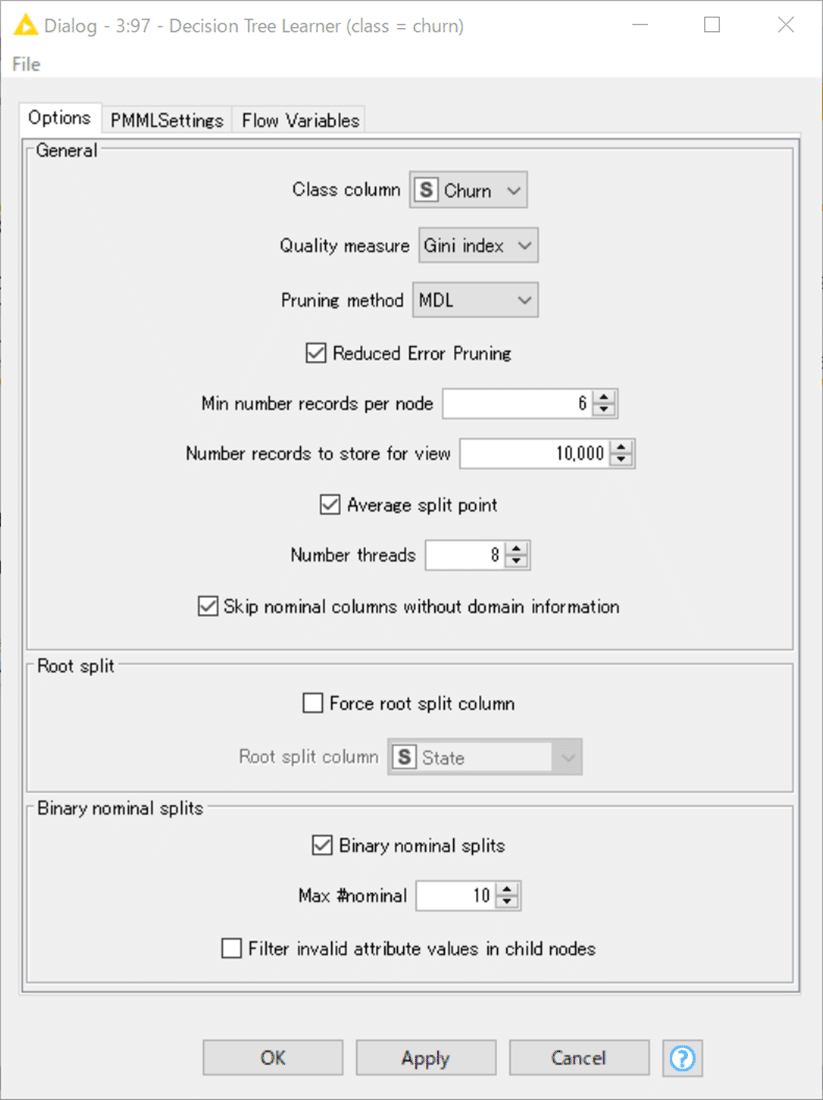
私の解答:

自分の未熟さが悔しいです。
「素人で悪いか。」って言える力が欲しい…。
いいなと思ったら応援しよう!
