
【JKI】025_Modeling_Churn_Predictions_Part_3_SMOTE

【JKI_025】課題を確認
Just KNIME It! (JKI)
今回の挑戦はこちら

問題文をGoogle翻訳し少し加筆して以下に。
課題25:チャーン予測のモデリング-パート3
レベル:難
説明:この一連の課題群の目標は、特定の通信会社のどの顧客が、アカウントの属性に基づいてチャーンする(つまり、契約をキャンセルする)かを予測することです。ここで、予測されるターゲットクラスはChurnです(値0はチャーンしない顧客に対応し、1はチャーンする顧客に対応します)。
タスクの分類モデルを自動的に選択した後、テストデータの精度は約95%に達しましたが、モデルは両方のクラスで均一に実行されません。実際、顧客が解約しない場合の予測(Churn = 0)は、解約する場合の予測(Churn = 1)よりも優れています。この不均衡は、これら2つのクラスの適合率と再現率の違いを調べるか、非常に高い精度にもかかわらず、Cohen’s Kappa係数が80%より少し低いかどうかを確認することで確認できます。
クラスChurn=1の分類予測をもう少し強力にするために、トレーニングデータを前処理して再サンプリングするにはどうすればよいですか?
注1:問題を理解するためにさらにヘルプが必要ですか?このブログ投稿をチェックしてください。
注2: この問題は難しいです。クラスChurn=1のパフォーマンスが大幅に向上することは期待できません。また、パフォーマンスの向上が統計的に有意であるかどうかを確認することは簡単ではありません。それでも...このチャレンジに最善を尽くしてください!
難問だとコメントされている通り、KNIMEのチャレンジというよりは機械学習の基礎学習になっています。
Just KNIME It!というよりJust Execute Machine Learning It!
語呂が悪いか。
【前回の予測モデルの性能評価】
今回の課題の比較対象は、前回作った上記の分類モデルとなります。
その予測結果を見てみます。

非常に高い精度にもかかわらず、Cohen’s Kappa係数が80%より少し低い
とのコメントの通りかなと思います。実際に解約したのが19+78=97名ですが、19名は予測では解約しないと誤ってクラス分けされています。
つまりChurn=1のRecall(再現率)でいうと
78÷97=0.804

実際に解約してしまう方の2割を予測できていない(擬陰性)です。通信会社としては解約しそうな顧客を事前に予測して、契約を継続してもらえるよう働きかけたりしたいでしょうから、Churn=1のクラスについての再現率を高めたいのだろうということで今回の課題設定となったかと思います。
ちなみにクラス分け予測の評価指標の色々は下記の記事で勉強しました。
【不均衡データへの対策】
でもData Explorerノードでデータ分布を見ましたが、問題文中に上記で紹介されているブログ記事でもまさに不均衡データをどう扱うかに注目しています。DeepL翻訳を一部編集して引用します。
さらに準備を進める前に、視覚的なプロットや基本的な統計量を計算することによって、データセットを探索することが重要です。
Data Explorerノード(またはStatisticsノード)は、平均、分散、歪度、尖度、およびその他の基本的な統計尺度を計算し、同時にデータセットの各特徴のヒストグラムを描画することができます。
Data Explorer ノードのインタラクティブなビューを開くと、解約サンプルはアンバランスであり、予想通り多くの結果が解約しない顧客に関係することがわかります(85%以上)。通常、解約する顧客は、解約しない顧客よりはるかに少ないです。このクラスのアンバランスに対処するために、合成例を作成することによって少数派クラスをオーバーサンプリングするSMOTEノードを使用します。
ここで、このブログ記事で紹介されているKNIME workflow (WF)を見てみましょう。
(WF抜粋)

この記事の扱うデータもおそらく今回の課題と同一のデータセット由来ですので、参考になることは間違いありません。私たちに与えられたデータも確かに不均衡です。ですから、今回はSMOTEを利用してみることにしました。
【SMOTEの実装】
トレーニングデータだけを増やすので、先週分の公式解答WFを転用し、下図のようにSMOTEノードを加えました。

SMOTEノードの日本語化されたディスクリプションを引用します。
このノードは、学習データを充実させるために、入力データをオーバーサンプリングします(つまり、人工的な行を追加します)。
決定木やニューラルネットなどの教師付き学習アルゴリズムでは、一般化するためにクラスの分布が等しいことが必要とされます。
例えば、"active "クラスのオブジェクトが少なく、"inactive "クラスのオブジェクトが多いなど、不均衡な入力データの場合、このノードは人工的に行を追加してクラス分布を調整します(例では、"active "クラスの行を追加しています)。
アルゴリズムはおおよそ次のように動作します。
与えられたクラス(上記の例では "active")の実オブジェクトと、その最近傍(同じクラス)のオブジェクトの間を外挿することで、人工的な行を作成します。
そして、この2つのオブジェクトを結ぶ線上の点を選び、このランダムに選ばれた点に基づいて新しいオブジェクトの属性(セルの値)を決定します。
ちょっとわかりにくかった方のためには下記の記事を紹介します。
このSMOTEノードですが、デフォルト設定だと下記のように多数派クラスも人工的に行を追加する仕様になっている点は注意です。

再現性が出るようにseedは”111”に固定で設定してみました。AutoMLでの予測まで実行した結果は下記の通り。

精度は95.052%から95.202%
Cohen’s Kappa係数は0.797から0.804
とどちらも微増していますが、
Churn=1のデータ群は
FN (擬陰性) : TP (真陽性、正解)= 19 : 78から18 : 79
とあまりよくなったように思えないです。
【SMOTE実施条件】
SMOTEノードの設定は下図の通りとしました。実は何種類か試して一番よかったものを記録しています。
設定:

また、AutoMLコンポーネントは下図の設定に変えました。

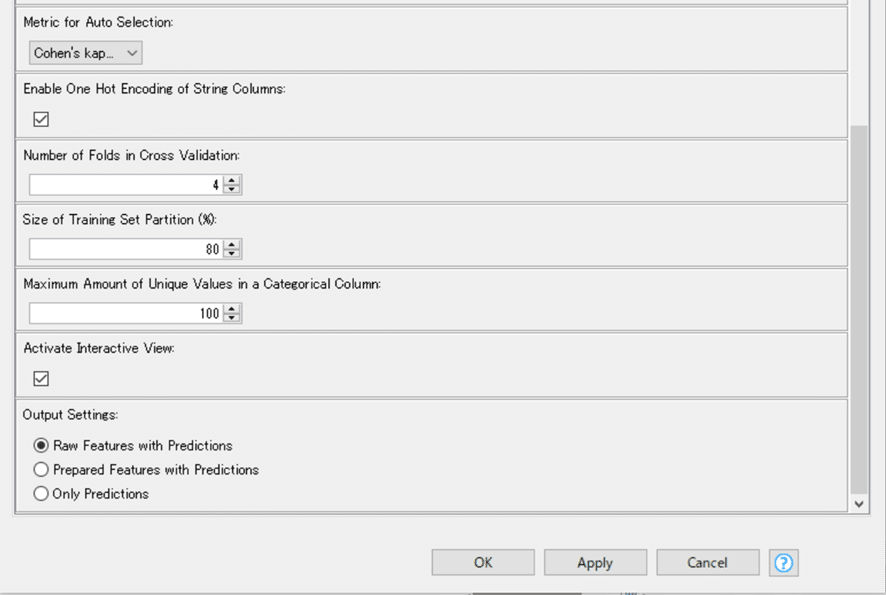
最適化の指標を精度ではなくCohen’s Kappa係数にしてみました。Recallでもいいかなとは思うのですが、Churn=0のクラスの予測性能もあまり犠牲にしてはいけないのではと考えてのことです。
結果:
AutoMLで最適解とされた機械学習モデルがGradient Boosted TreesではなくXGBoost Treesに変わりました。
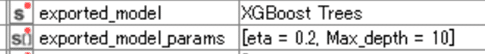


モデル全体の評価指標である精度、Cohen’s Kappa係数だけ見ると逆に微減してます。
しかし、Churn=1のデータ群に関していえば
FN (擬陰性) : TP (真陽性、正解)= 19 : 78から16 : 81
と擬陰性が減ったことを評価しました。
また、
パフォーマンスの向上が統計的に有意であるかどうかを確認すること
は私の知識ではできないので断念しました。
さらに高みを目指すのは玄人の皆さまにお任せいたします。
例えばオーバーサンプリング手法はSMOTEだけではないですが、Pythonなど無しではこの課題、これ以上は厳しい。
KNIME Hubに解答は上げています。

おまけ:
【JKI_024 感想戦】
今回の公式解答はこちら。
WFの構成は同一ですので正解だったようです。既に上記で紹介しています。週を追うごとに課題の難易度が上がっており、来週もさらに追加でチャレンジがあるそうです。
の冒頭でAline Bessaさんが
“Just KNIME It!” Challenge 25, the third part of our four-week series on data classification
と宣言されているので確実です。難易度hardの上が来るのか?
正直もうギリギリいっぱいなんです…とうとう解答連続投稿記録が止まるか!?
いいなと思ったら応援しよう!
