
【JKI】008_Wordle_Scores_on_Average_01_Player別解析

【JKI_008】課題を確認
Just KNIME It! (JKI)
今回の挑戦はこちら
Wordleで来ましたか。イメージ図のセンスがいいですね。
以下、Google翻訳に手を加えないでそのまま引用しています。
課題8:平均的なWordleスコア
レベル:中
説明:チャレンジでは、3人のプレーヤーのWordle棒グラフを再作成する必要があります。Wordleをプレイしたことがない場合は、このゲームの簡単な紹介を確認してください。このチャレンジでは、次のことを行うことが期待されています。
1.棒グラフの場合、推測の可能性のある各数(1から6)と、各プレーヤーの勝利数を表す必要があります。この例を1人のプレーヤーのデータだけで確認してください。
https://www.pinterest.com/pin/wordle-lol-in-2022--306033737189083803/
2.推測の数[1、6]をスコア[1,10]に変換しますが、推測の数が多いほどスコアは低くなることに注意してください。推測が欠落しているということは、プレーヤーが単語を推測できなかったため、0のスコアを受け取る必要があることを意味します。
3.次に、3人のプレーヤーの平均を計算します。誰が最高の平均を持っていますか?
4.言葉の難しさを考えてみましょう。英語で最も難しい306個の単語のリスト(ファイル「difficultwords.txt」)の単語に重みWを割り当て、W=2およびW=0の3人のプレーヤーの平均を再計算します。最高得点の選手は変わりましたか?
Wordleは流行っているのは知ってはいるものの、全くやったことがないしルールも知りませんでした。日本語での説明サイトを探しました。
なるほど、6回以内に5文字の単語を当てるのですね。
課題のデータはこちら。
今回は課題の問題文を正しく理解できたか自信がないですが、以下私の解答の経過を報告します。
【課題①:棒グラフ】
1. For the bar chart, each possible number of guesses (1 through 6) must be represented, as well as the number of victories by each player.
参考に示された棒グラフの例は下図の通りです。3人のプレーヤーのWordle棒グラフを別々に作るのですね。

上記の統計の見方:
今回は棒グラフ部分のみ作ればいいようです。
この課題にはサンプルデータのうち
wordle-weekly challenges.xlsx
のみが必要なようです。元データを見てみます。

必要なデータはA2から下だけのようですね。一部セルが結合しているのが読み取りにくそうですが、Excel Readerで下記の設定で読み込みました。
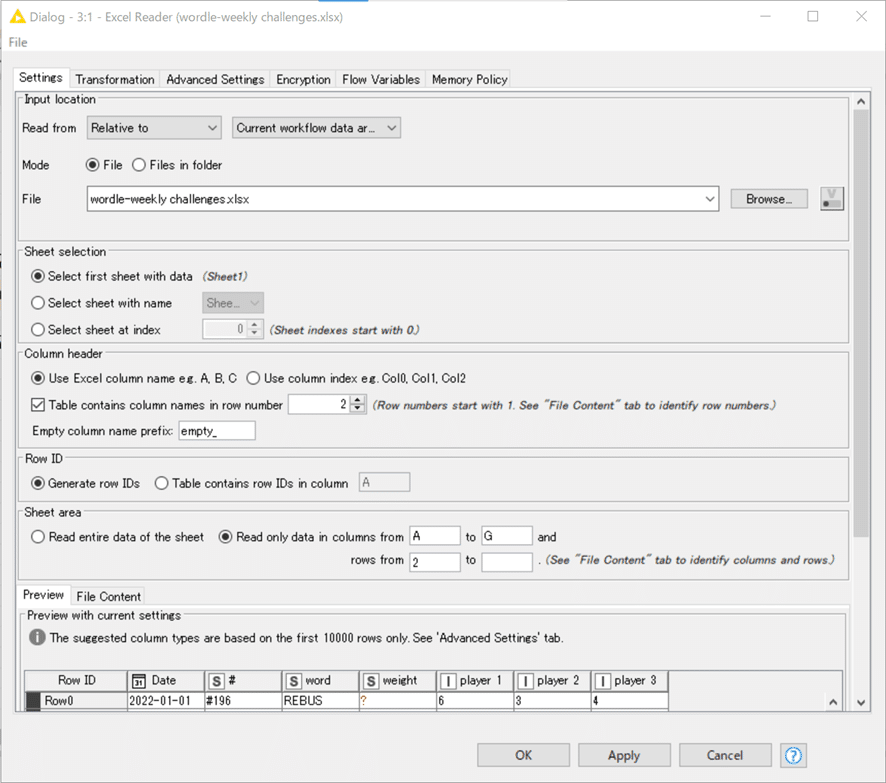
結果:

【棒グラフ化のためのデータ前処理】
後々の処理の都合を考えて、一旦TidyData型に変換することにしました。Player毎に列が分かれているところを縦に変えてみます。

Unpivotingの技術説明はまっきーさんの記事がオススメです。
設定:

Column Rename後の結果:

Player名は同じ種類のデータ「PlayerID」だと考えて縦にしました。
【推測回数の集計】
Google翻訳だと「推測の可能性のある各数(1から6)」というのが分かりにくい日本語になってます。
原文では”each possible number of guesses (1 through 6) must be represented”です。
wordleでは6回以内に正答しないといけないので、要は正解にたどり着くまでの推測回数1~6の分布がPlayerの成績比較に重要です。
ノーヒントの1回でいきなり当たることは稀でしょうが、そういうことがなかったということも棒グラフに示す必要があるようです。
そこで推測回数の各数(1から6)一覧表への集計が必要です。ここに手間取りましたが下記のように実装しました。

後で使うスコア(点数配分は私の好みで勝手につけてます)も含めて上記のようにテーブルを作りました。

メタノードへの上の入力が上記の自作のテーブルで、下の入力はTidyDataに変換したデータです。

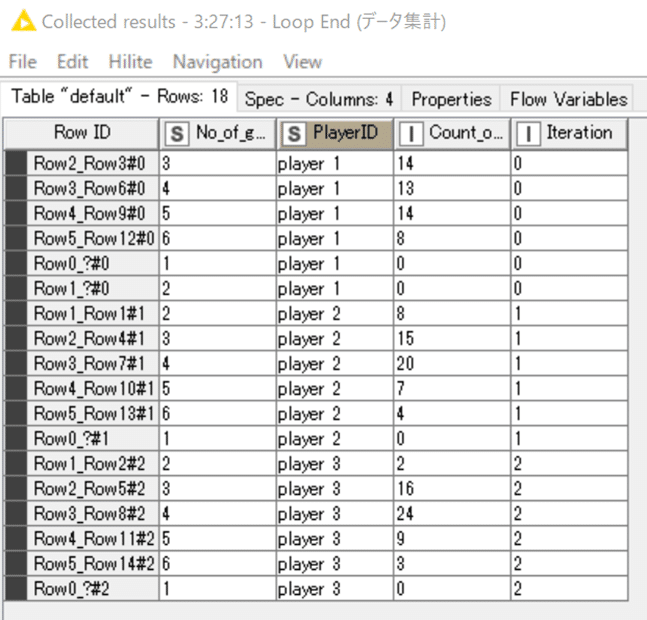
下でPlayerごとに所要回数別に挑戦数を集計して、上のテーブルに結合しました。
結果:Loop Endまで実行後
そのあとPlayer毎にRowを分けて棒グラフ表示へ。
正直いろいろ効率が悪かったように思います。皆さんの解き方に興味があります。
棒グラフの設定は1例のみお示しします。


結果:3名分


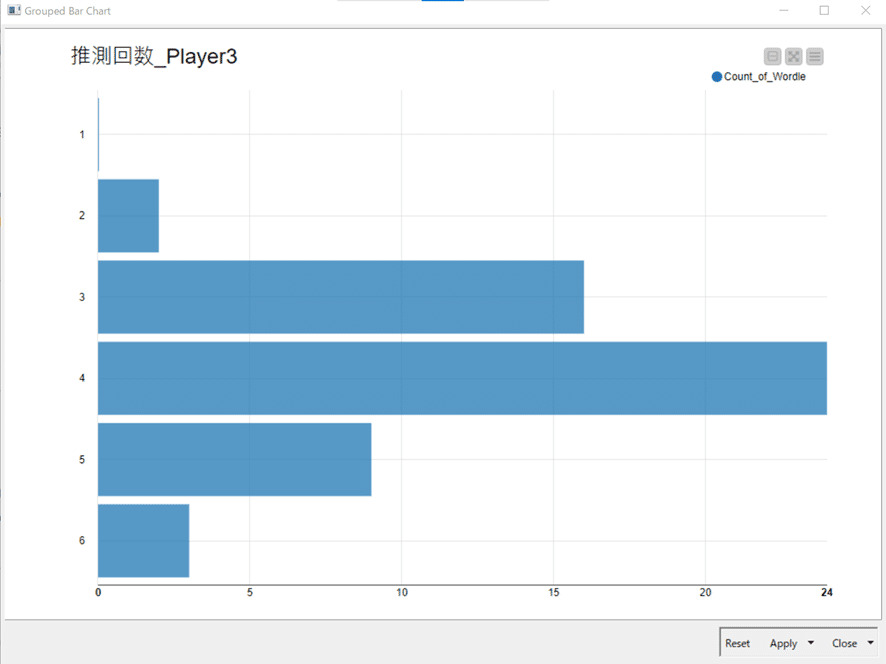
3名を並べて一つのグラフに表示し、横軸のスケールもそろえたり、色を変えたかったり、棒グラフ上に総数を表示したりと視覚化は欲が出るのですが、私では短時間での実装は出来そうにないのでここまでとしました。
皆さんだとどうされるのでしょうか?
棒グラフ上への総数表示はRのggplotにてgeom_textで指定したりすると聞いたことがありますが、KNIMEというよりはRでの実装ですよね。
【課題②:スコアへの変換】
2. Transform the number of guesses [1, 6] into a score [1,10], but remember that a higher number of guesses should result in a lower score. A missing guess means that the player did not manage to guess the word and therefore should receive a 0 score.
Transformというからには大元の推測回数カラムの数値をスコアで置換しなくてはいけないのかなと解釈しました。
最初はUnPivotする前のDataTableをかなり頑張って分解、スコアデータと集計、再集計してました。

これはこれで愛着が出たので供養のため一緒にKNIME Hubには上げてます。でも実際は、TidyData型で処理した後、Pivotで戻す方が効率が良いです。

Joinerの設定:今回はデフォルト設定から少し変えてます

データ型が違っても文字列型と見なして照合できるのは便利ですね。
結果:

スコアに空白行があります。

MissingValueで処理して推定回数データなしはスコア"0"にしたのちに、Pivot化します。私はPivot化の設定でいつもつまづくので、まっきーさんの記事はもう10回以上閲覧したと思います。
ピボットテーブルの
行をGroup
列を Pivots
値をAggregation
で指定
設定:



結果:
私が勝手に配点を決めたスコアにつけ変わっています。
【課題③:平均スコアでランク付け】
3. Next, calculate the average of the three players. Who has the best average?

設定:



結果:

Player2がベストプレーヤーでした。
【Unpivotの便利さについて】
やはりTidyData型にするとデータ処理がやりやすい印象があります。
まっきーさんがUnpivotノードの記事で強調されていました。
KNIMEは各実行ごとにConfigureを変えないことで自動化できます。つまり、Inputファイルの内容が変わっても、ファイル名やコラム名を変化させないのが非常に重要です。もしくはコラム名が変わってもConfigureを変えずに処理できるのが重要です。
今回の感想ですが、TidyData型に変形する時にUnpivotノードが便利なことを学びました。今後活用していきたいです。
さてと3000字を超えたので最後の課題は次の機会に。
WFはすでにKNIME Hubに置きました。
おまけ:
【JKI_007感想戦】
前回のJKI_007は真面目にデータを考察させていただき、勉強になりました。
では公式はどう解析するのかと興味津々だったのですが、思った以上にそぎ落とした内容で驚きました。
空白値は華麗にスルーしていますね。
私も平均値とかで埋めてしまわないようにしたので、発想の源は同じなのかもしれません。
あと、国名の名寄せもしないのでもう、ついて来れるやつだけついて来いって感じでした。信長かって思いました。
大陸間の比較時に平均値では外れ値の影響が大きく出るので、中央値(Median)を採用されていたのはその通りだったと納得でした。
記事を読んでいただきありがとうございます。 先人の智慧をお借りしつつ、みなさんに役立つ情報が届けられたらと願っています。 もしサポートいただけるなら、そのお金はKNIMEの無料勉強会の開催資金に充てようと思います。