
【JKI】027_Rare_Blood_Types

【JKI_027】課題を確認
Just KNIME It! (JKI)
今回の挑戦はこちら

問題文をGoogle翻訳し少し加筆して以下に
課題27:まれな血液型
レベル:中程度
説明:住所や血液型など、昨年献血した米国市民に関する情報を含むデータセットがあります。「ユニバーサルドナー」としても知られるO型は、ほぼすべての人に輸血できるため、世界で最も価値のある血液型の1つです。ここでのあなたの目標は、研究者のグループが米国の州ごとにO型の市民の数を見つけるのを助けることです。残念ながら、住所の列は1行で表示されるため、州の情報を抽出するためには、いくつかのデータ整理を行う必要があります。また、結果を視覚化するために、米国のコロプレスマップを作成するように依頼されました。
【サンプルデータセットの入手】
に置いてあるファイルをダウンロードしましたが、拡張子が未定義でしたので、「data.txt」とテキストファイル扱いにして今回のWorkflow(WF)のdataフォルダに入れました

File Readerで読み込むと、確かに住所の列は1行で表示されていますので前処理が必要になりますね。
設定:

結果:

【州名データの抽出】
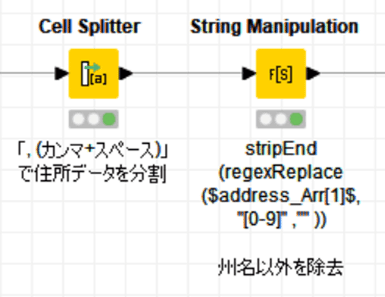
確かに住所の列は1行で表示されているので、州名の文字列のみを抽出します。
カラムaddressは幸い記載ルールが揃っています。
「州名以外の住所明細(群や市など)」+「, (カンマ+半角スペース)」+州名+「 (半角スペース)」+「郵便番号の数字5桁」
そこで、
① 「, (カンマ+半角スペース)」の前後で分ける
② 後ろの文字列の「 (半角スペース)」+「郵便番号の数字5桁」を除く
ことで州名を抽出できます。
Cell Splitterで①を、String Manipulationで②を実装しました。
設定:

デリミタは「, (カンマ+半角スペース)」を設定

正規表現を利用して数字を除去したのち、
regexReplace($address_Arr[1]$,"[0-9]" ,"" )
残った文字列の末尾の空白すなわちスペースをstripEndで除去しました。
結果:

州名が切出されていく様子が見て取れるかと思います。
【血液型指定の集計】
米国の州ごとにO型の市民の数といっても献血された方のみでの集計です。おなじみの二つのノードでのデータ処理なのでいきなり設定を以下に。
設定:



結果:

50州+ワシントンD.C.それぞれで集計されました。
【コロプレスマップ】
JKI_022でも利用しましたコロプレスマップ、今回はアメリカの州別で使います。

結果:

これまでJKIへの解答など続けてきたので、過去に使った技術の転用だけで課題を達成できたかなと思います。後でも述べますが修業の成果かなと思っています。
KNIME Hubに解答は上げています。
おまけ:
【JKI_026 感想戦】
機械学習四部作の最終回の公式解答は下記の通り。
今回は可視化の問題ではあるので本筋ではないですが、このKNIME workflow (WF)ではAutoMLで用いる特徴量をあらかじめ絞り込んであって興味を持ちました。
上記でもコメントした通り寄与度が低い特徴量などはあらかじめ除去すると予測性能が改善される可能性はあります。

結果として私の解答でも使ったScorer(JavaScript)を加えて混同行列など見てみましょう。

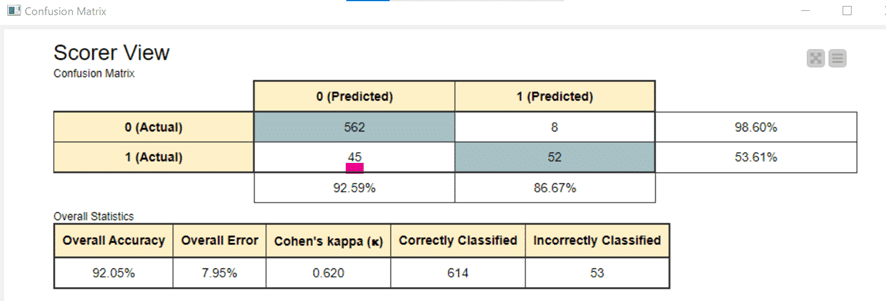
このモデルの用途が、解約してしまう人を予測して対策を講じるためだと仮定すると今回の特徴量の絞り込み方は不適切そうだなと私は考えます。
このように、AutoMLコンポーネントさえあれば良い予測モデルができるわけではないのはむしろ当然のことでしょう。一方で、より多くの人に得られた結果の調査と次の対策の検討に参画する機会を広げると言う意味で、KNIMEのコンポーネント群でのノーコードでの可視化は役に立つと期待します。
おまけ②:
【KNinjaの修業】
今回の一連の課題、挑戦者にしっかり考えるよう求める内容で、とてもよく練られていたと思うのです。
忍者にまつわるこんな物語があります。
昔、忍者の修行の中に「麻の苗木を植えてそれを毎日飛び越える」というものがありました。
麻はとても成長が早い植物で、まっすぐ伸びて3~4ヶ月で3mくらいの高さになるそうです。約100日ほどで3mですから、1日では約3cm成長するということです。忍者たちは麻を地面に植えて、その上を毎日ジャンプして修行したそうです。
1日めは3cm、2日めは6cm・・・とだんだん高くなって1日に3cmずつジャンプ力が上がり、1週間で21cm、1ヶ月で90cm、そして3~4ヶ月で何と3mもジャンプできるようになるというものです。
まさにJust KNIME It!はKNinja達の修業であるなと感じています。出題者すなわち師匠の皆さんの工夫や配慮に感謝です。
いいなと思ったら応援しよう!
