
【W7】活性予測のための機械学習モデル_05_Step2_後編

【W7の目的】
ターゲット分子(EGFR)に対して新規な化合物の活性を予測するために、様々な教師あり機械学習(supervised ML)アルゴリズムを使用する方法について学習します。
(引用元)
【データの前処理】
Ligand-based screening: machine learningメタノード

Step1で今回の問題を決めました。そして4511化合物をEGFR阻害活性pIC50 = 6.3を基準として2群に分類しました。Step2ではデータの前処理を行っています。
今回はExpand Bit Vectorノードについて豆知識付きで説明していきます。

【フィンガープリントを説明変数として使う】
フィンガープリントは下図のとおり0と1の並び、Bit Vector形式で算出されています。

MACCSキーは166種類が一般的です。
ECFP4も多用されるフィンガープリントですが、1024ビットもしくは2048ビットでの利用が多いでしょう。
Step3では機械学習用ノード群にこのフィンガープリントのデータを説明変数として渡したいのですが、多くの機械学習ノードがBit Vector形式での入力には対応しないので、この後のデータ処理が必要となります。
【Expand Bit Vector】
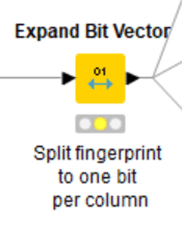
日本語での情報は少なめのこのノードですが、すさんが2018年1月にKNIMEでの機械学習を紹介した際にコメントされています。
多種多様なデータを機械学習の入力に用いたい場合の方法として、
[010]で示されているfingerprint(属性:bit vector)をExpand bit vectorノードを使ってtableのカラムとして展開しちゃえば使えると思います。多分ね。
と脚注をつけておられます。
上記の説明が多分ではなく正しいのですが、単一のfingerprintをデータテーブルのカラム群へと展開する目的でも使えますよね。
また、この記事は読んだことがある方はとても多いと推測します。KNIMEでの機械学習入門としてとてもわかりやすいと思うので次回以降も取り上げさせていただきます。すさんこそが日本でのKNIMEのエバンジェリストだとあらためて思います。
念のため日本語化されたノードディスクリプションからも引用させていただきます。
Infocom社の中の人には今年もお世話になります。
ビットベクターを整数列に分割するノードです。
…文章よりも実際どうなるかを見た方がわかりやすそうなのでデモデータを見てみましょう。
設定:
結果:
もともとのフィンガープリントの「ビットベクターを整数列に分割」しているので、ビット数だけカラムが増えていて、カラム名にはPrefixとして設定した”bitvector”のあとにindex番号”0”から始まる何番目のビットの値かを示す番号が付いています。
bitvector0から始まり、Bitbector166で最後です。


MACCSフィンガープリントの場合は166ビットだからです。
いや、ちょっと待って一つ多くないですか?いきなりミステリー。
【MACCSミステリー:解答編】この章はネタバレを含んでいます
登場人物が本来より一人多く、偽者が独り混じっていると言うミステリー、皆さんも心当たりがあるんじゃないですか?例えば冲方 丁さんの作品が2019年に映画化されたりしてました(題名がショッキング過ぎるので伏せました)。
さて、ストーリー展開も何もなく解答編です。
2017年にKNIME ForumでGregさんが説明してくれています。

もともとのMACCSキーの番号にbit番号を合わせるという配慮でしたか。
その目的でダミーデータとして加えた“Bit 0 should always be zero.”
カラムに展開しないとなかなか気づけないことですね。
【エンディアンってなんでなん?】
ちなみにしっかりチェックされた方、展開の前(Bit Vector形式)と後(データテーブルのカラム群)で並びが逆になっていると気付かれたのではないでしょうか。私は人に教えてもらうまで気づきませんでした。
仕様としてエンディアンというのが異なることで順序が逆になるそうですよ。
<参考>
「これ、豆知識な。」と言うところなのでしょうが、それよりも大事なことは、結果としてMACCSキーの順番通りにカラムが並んでいて、番号でルールを照合できます。
データをざっと眺めていただくと、最初の方のカラム(bitvector0, bitvector1, bitvector2,…)って0ばっかり入力されていますよね。
上述の通り、bitvector0は全て0です。もし他にもそんなカラムがあった場合、そのカラムって活性があろうがなかろうが同じデータしか入っていないですから、予測のための特徴量(説明変数)として無用です。
気になるところなのでデータの分布をざっくり見てみます。
【Statisticsノードで数値データ分布観察】
前にも紹介したと思いますが、複数の数値カラムのデータ分布を簡単に俯瞰するならStatisticsノードが簡便です。下図のように繋いでみてください。

右クリックして、Execute and Open Viewsを選択。
表示されたウィンドウを最上部までスクロールすると下図のようになります。

右端のHistogramを見ていただいてもいいですが、Meanをみて「0」とか「1」になっているカラムは単一の値のみが入力されています。
上図でみるとbitvector0~5で、すべて単一の値でないのはbitvector3のみですね。
次はStep3に行くと思いますよね。ところが次回は説明変数についてもう少し勉強しておこうと思います。
おまけ:
【MACCSキーのルールと照合してみた】
ここからは時間がある方だけお読みいただくことをお勧めいたします。
上記の特徴量の偏りですが、実はデモデータの4511化合物の性質を考えながら先述の下記サイトMACCSキーの定義と照合したらそりゃそうだなと納得でした。
(再掲) http://www.mayachemtools.org/docs/modules/html/MACCSKeys.html
MACCS 166 keys [ Ref 45-47 ] are defined as follows:
Key Description
1 ISOTOPE
2 103 < ATOMIC NO. < 256
3 GROUP IVA,VA,VIA PERIODS 4-6 (Ge...)
4 ACTINIDE
5 GROUP IIIB,IVB (Sc...)
(以下略)
同位体とか金属元素を含むことはまれなのは納得だと思います。
気になったのはMACCSキーのNo.3です。
今回bitvector3を降順でソートしてやると、「1」となったのは6化合物です。

Row921:
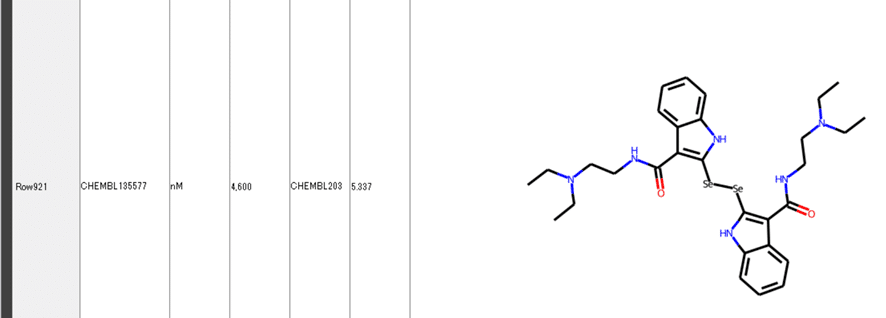
など全て含セレン化合物でした。セレンはVIB族なんですよね。
道草:
【不便益のすすめ】
いくらなんでも寄り道が過ぎました。まだ皆さん読んでくれてますかね?
正直読み飛ばしてもTeachOpenCADDの理解には全く支障がないです。
良く調べたら寄り道ではなく道草が正しそうです。
そこで(?)さらに歩みを進めますと、私は不便益という考え方に大いに共感しております。
一番好きな例が低速シミュレーターです。
最新型シミュレータが導入されたおかげで、数分で結果が出るようになった。でも、良い結果が出てくれと祈って待つ楽しみがなくなった。シミュレーション実験に数時間かかっていた頃は、まさにシミュレータを目の前にして、冷静にシミュレーション方式を考え直す時間が確保できていた。
皆さんはDataRobot、お好きですか?
機械学習の玄人の方の中には初心者こそ敢えて数学から学ぶべきだと言う方も多くいらっしゃいます。一理ある正論だと思います。
私の道草はそこまでの本質的な学習には至らないのですけれど、自分で機械学習研究の流れをおおまかになぞりながら、このnoteに書き起こすことで自分の聞きかじった知識の棚卸をしています。
あれ、まだ読んでくださってます!?次行きましょう、次!
いいなと思ったら応援しよう!
