
【JKI】026_Modeling_Churn_Predictions_Part_4_02_XAIトライアル

【JKI_026】課題を再確認
Just KNIME It! (JKI)
今回の課題はXAI技術としてKNIMEコミュニティで公開されているいくつかの技術の実装体験です。
【課題:ダッシュボード3種】
両方のクラスのパフォーマンスを示します(ここでは、適合率や再現率など、任意の指標に焦点を当てることができます)
モデルにとっての重要度に基づいて特徴量をランク付けします
Local Explanation View コンポーネントを使用して、いくつかの単一の予測、特に擬陽性(FP)と偽陰性(FN)を説明します
を順番に体験していきましょう。
【課題①: Scorer (JavaScript)】

Scorer (JavaScript)は判別モデルの混同行列や予想性能の各種指標をまとめて表示してくれる親切設計で、私はTeachOpenCADD-KNIMEのW7で初めて体験しました。
可視化のためにコンポーネントに中に入れて使いましたが、ノードだけでも同様に可視化できますので、ノードの設定のみ紹介しておきます。

設定:
入力データはJKI_025での予測結果です。
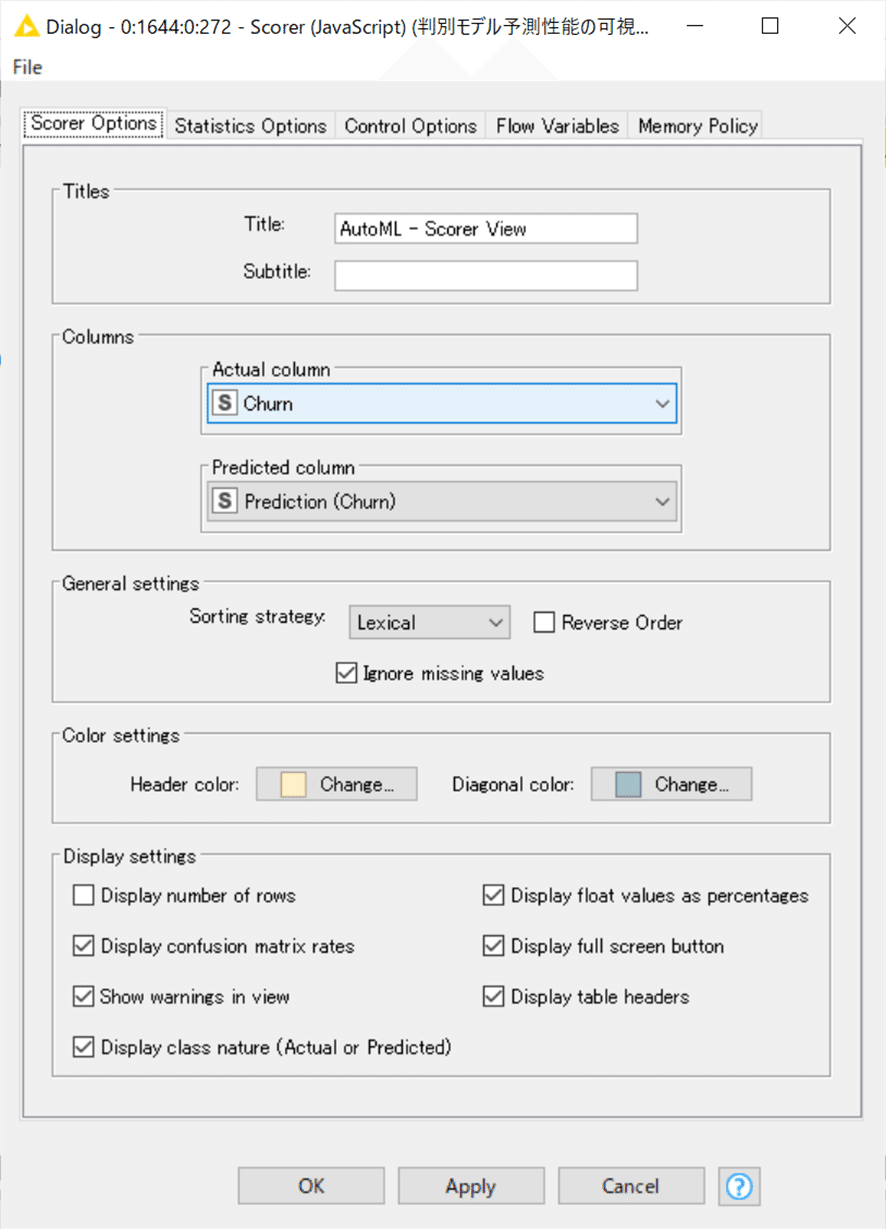
結果:

見やすいレイアウトになっていてよくできているなと思います。精度の詳細を議論できるほど機械学習の評価経験がないので、次へ行きます。
【課題②: Global Feature Importance】

の記事からGlobal Feature Importanceコンポーネントが便利だろうと思ってダウンロード(DL)して繋いでみました。
今回の入力データは、AutoMLでベストとされた機械学習モデルとテストデータ全て。WFでの繋ぎ方までは上記の記事で学ぶことができました。
悩むのはどの設定がいいかを選ぶところです。確かに機械学習初心者でも使える親切設計ですが、正しい使い方までは自動では設定されないです。
悩んでいろいろと調べて下記の記事に行き当たりました。
AutoMLならぬDataRobotの記事ですが、わかりやすい日本語での解説に感謝です。
DataRobotは機械学習初心者への手厚い支援体制を整えてくれている点も重要なサービスだと感じています。
Permutation Importance(参考:Fisher, Rudin, and Dominici(2018))は、モデルにとってのある特徴量の重要度を、「ある特徴量がどれだけモデルの予測精度向上に寄与しているのか」と解釈して計算されます。
この重要度を測るために、Permutationと呼ばれる手法を用います。非常に単純な手法で、ある特徴量をランダムに並べ替えてしまうだけです。ある特徴量を完全にランダムに並び替えたとすると、その特徴量はどんなものでももはやターゲットを説明する能力はありません。
Permutationの日本語訳を辞書で引くと「順列」や「並べ換え」とでますが、まさに並び替えて順列をばらばらにする、という操作を行っています。仮にモデルの中のある特徴量をランダムに並び替えて予測を行なった際の誤差が、もともとのモデルよりも誤差が大きかったとしましょう。その際には、大きくなってしまった誤差ぶんだけ、ランダム化された特徴量がもともとのモデルの精度に寄与していたと考えることができます。
そしてランダム化された特徴量で作ったモデルの誤差をもともとのモデルの誤差で割ったものがPermutation Importanceです。同じ手順をモデルの中の全ての特徴量に対して行えば、どの特徴量がもっともモデルの精度に寄与しているか、もしくは精度に寄与していないのかを理解することが可能です。
ではKNIMEで体験してみます。
設定:

結果:

一番寄与度が高かったのはDay Mins、昼間の通話時間ですかね。
相関の正負すなわち通話時間が長い方が解約につながるのか契約継続につながるのかは別途解析が必要ですがどの特徴量に注目して解析したらいいかがこんなに簡単に順位付けできるのは素晴らしいですね。
この機能、どうやって実装されているんだろうって知りたくなりますよね。私はすごいと思うのですがKNIMEはコンポーネントの中身を完全公開しています。

ただ、この中身をじっくり見出したら収拾つかないです。
説明可能なAIのためのXAI技術の説明はなかなか困難なのだなと思いつつ次へ。まさに巨人の肩の上に乗っていることをあらためて思います。
【課題③: Local Explanation View】
3.は指示いただいたとおりに実践するのみ。

実は実装に地味に苦労したので少し紹介しておきます。
課題として擬陽性(FP)と偽陰性(FN)の結果を一つは選び出さなくてはならないので、Row FilterとTop k Selectorで絞り込むのは出来ました。
Local Explanation View コンポーネントへの入力には3つの情報が必要です。
A) 利用した機械学習モデル
B) テストデータ
C) 予測結果の説明をさせたい1つのデータ
上記で絞り込んだデータがC)にあたるわけですが予測結果のカラムを含んだまま入力するとエラーが出てしまいました。それで不要なデータを除くためColumnFilterを加えました。そんなわけでまあまあノード数を使った解答となっています。公式解答ではもっとスマートに処理しているのではと期待します。
FP,FNの両方を説明するのは冗長と思うので、今回のモデルでは最も重要な問題となるFNを見てみることにします。通信会社にとって解約されることを予測できなかった例はより重要であると考えるからです。
設定:

予測は0(Negative,解約しない)

しかし実際は1(Positive,解約した)すなわち偽陰性の例のみに絞ります。
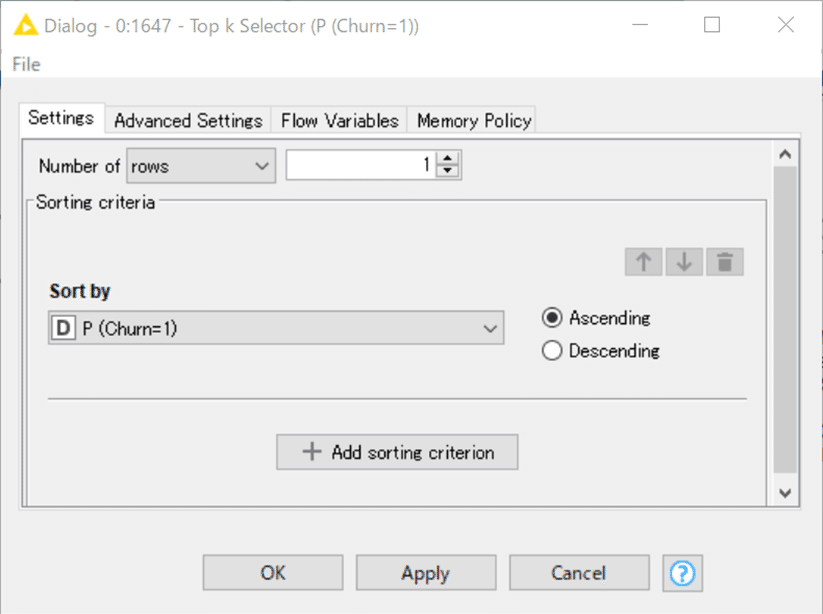
一番 P(Churn=1)が小さいもの1例のみを選ぶように設定、すなわち予測では高い確率で0であると予測したのに実際は1であった最も外れたレコードを見てみます。

先述の通り、機械学習での予測結果のカラムは不要なので削除。
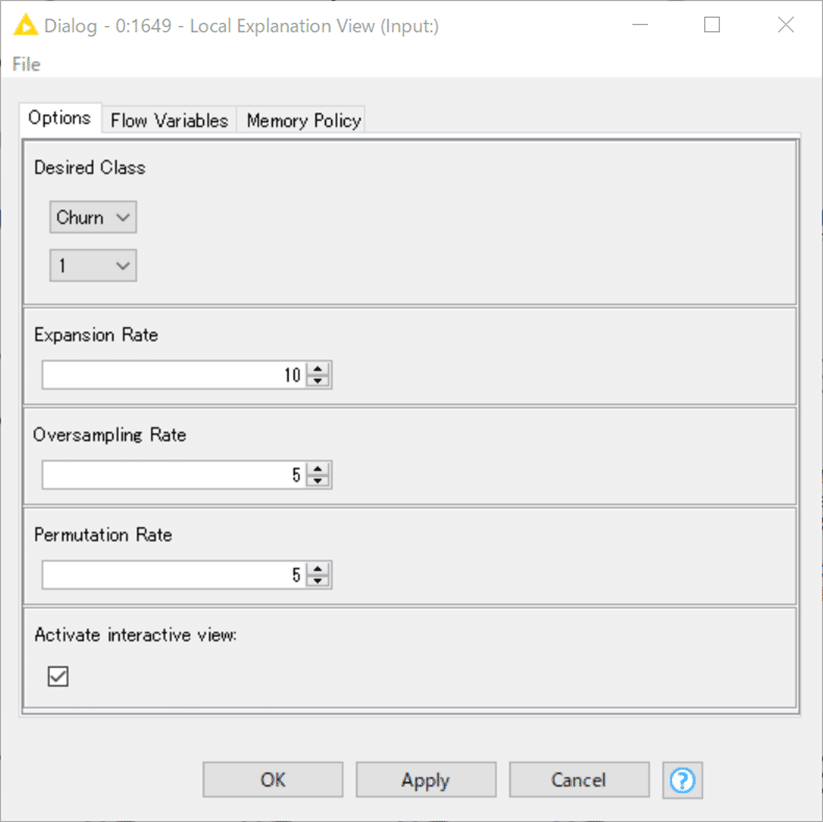
実際に期待されたクラスすなわち判定結果は「1」なので上記の設定とします。
結果:
最上部はこのViewの説明と、今回解析した1データを表示。

以下に示す左下ウィンドウの説明文をDeepL翻訳し、一部編集すると
局所的な特徴量の重要度
この棒グラフは、元のデータサンプルと類似のデータポイントに対する特徴の重要度を表示します。表示される値は、元のモデルの局所的な挙動を模倣するために類似のデータポイントの近傍で学習させたサロゲートGLMからの正規化された係数である。
うーん、サロゲートGLM(surrogate generalized linear model)って何だろうと調べると、
ローカルサロゲートモデルは、関心のあるインスタンスに関連するローカルな特徴量の重要度を算出します。
我々のケースでは、サロゲートGLMは、元のモデルの局所的な挙動を模倣するために、類似のデータポイントの近傍で学習されました。
生成された局所的な説明は、LIMEと呼ばれる別のXAI手法に似ているが、異なるタイプの近傍サンプリングが採用されました。
理解できたとはいいがたいのですが先へ進めます。実際に得られた棒グラフを見てみましょう。

正規化されているので1から-1の正負の範囲で各特徴量の寄与度が示されているわけですが、大きく外しているレコードだけあってか、先ほど課題2で見たGlobal Feature Importanceで重要な特徴量とされたものではないデータを重要視して予測しているのが気になります。
AreaCodeとか州名、電話番号で何が判別できるのかな?と思いました。
こういう結果を見て次は適切な特徴量の選抜をしてより良い機械学習ができるように工夫するのではないでしょうか。知らんけど。
右下ウィンドウも同様にして説明文を訳してみました。
反実仮想
以下は、設定ダイアログで設定された目的のモデル予測になる入力データ点です。これらは、元のサンプル点との距離によってソートされ、最も類似した反実仮想が最初に表示されます。また、各反実仮想データポイントについて、入力モデルが出力した分類確率を見ることができます。



今回0と判定された偽陰性となった1データと類似しているが、1と判定されたデータを最多で5つ表示してくれています。実際には真陽性と擬陽性が混じっています。
全ての特徴量を見比べることができますが、確かに似ていると思いました。
こういったデータ比較をすると、どうやら今回与えた特徴量ではこの局所的なデータ群のより正しい判別のためには情報量が十分ではなく、何か新たなデータ種を加えるべきではないかと考えたりできそうです。知らんけど。(知らんのかい)
さすがに生兵法は大怪我の基。よっしゃ、今日はこれくらいにしといたろ!
KNIME Hubに解答は上げています。
おまけ:
【KNIME-XAIの学習を深めるために】
四千字近くかけてXAI体験を紹介してきましたが、上っ面を撫でただけとの自覚があります。
より深く学習するには、KNIMEコミュニティを一層活用されるといいと思います。
2022年7月の最新教材はこちら。私は今から観ます。
https://www.knime.com/sites/default/files/2022-07/xai-webinar-slides.pdf
いいなと思ったら応援しよう!
