
【JKI】033_Medical_Procedure_Prices_01_データ探索

【JKI_033】課題を確認
Just KNIME It! (JKI)
今回の挑戦はこちら

問題文のところだけをDeepL翻訳し少し加筆して以下に
課題33:医療処置の価格
レベル: 難
説明: アメリカでは、医療処置の価格が大きく異なる可能性があるため、情報通のアメリカ人はかなりお得に買い物をする傾向があります。
この課題では、データジャーナリストの立場で、医療処置の価格差を調査していただきます。
具体的には、病院ごとに価格のばらつきが大きい(統計学でいうところの標準偏差が高い)上位5つの医療行為を見つけたいのです。
この調査のために手元にあるデータは一様ではないので、適切に読み取り、処理するためには検査が必要です。
簡単のために、カイザー財団病院とサター病院からのみ、病院が行う最も一般的な25の外来処置のすべての平均料金を比較します。
Kaiser Foundationでは、関連するデータはExcelファイルの名前に「...Common25...」とあり、Sutterでは、関連するExcelファイルの名前に「...CDM_All...」とあります。
隠しシートにご注意ください。
【隠されたファイル】
【隠されたサンプルデータ】
今回のサンプルデータのリンク先に行こうと上記リンクをクリックすると、

今回は何とサンプルデータが隠されてしまいました。
下記のサイトで言うとOpen Data Portalには日本からはアクセスできないみたいです。

そこでKNIME Forumでおそるおそる助けを求めたところ、今回の作者であるVictor Palaciosさんたちが助けてくださってデータ群は入手できました。ひとまず何より感謝です。
まさかサンプルデータが入手できないでJKI初のリタイアって無念ですよね。助かりました。
【木は森の中に隠せ】
入手したデータ群ですが、まさにリアルなデータ群です。フォルダが各病院に分かれ、Excelのファイル名もある程度ローカルルールはありますが統一はされていません。各病院のデータを実際に見ながら欲しいデータを探し出してくるキュレーションが必須です。
サンプルデータ群:

サンプルデータ群全体のデータ量など:

カイザー財団病院グループ:

サター病院グループ:

必要な情報がファイル群に隠されているかのようです。木は森に隠せと言う言葉を思い出しています。
でも、こんなデータの格納方法、実に一般的ですよね。私の所属する組織で使っているデータサーバもこんな感じだなと苦笑。まさにリアルデータ感があります。
幸いなことに
「簡単のために、カイザー財団病院とサター病院からのみ、病院が行う最も一般的な25の外来処置のすべての平均料金を比較します。」
と少し課題を軽くしてくれています。
そこで今回の調査対象の2つの病院グループのフォルダ群だけを対象に今回のWF編集を始めます。つまりサンプルExcelファイル群からWF実行に最低限必要な分だけを選抜してWF内のdataフォルダに格納しておきました。
出題時のサンプルデータ群と比較してデータ容量が10分の1ぐらいに削減できたので、KNIME Hubにデータ群ごとアップロードも可と判断しました。

【隠されたシート】
ここまででも十分複雑なのですが、追いうちのように
「隠しシートにご注意ください。」
との出題者からのアドバイス。
カイザー財団病院グループのExcelなど、確かに隠しシートがありました。
一例としてTop 50 Listシートが隠されていたようです。

あとでこのシートが集計の妨げになるのでまた取り上げます。リアルデータ恐るべし。
この状態から必要なファイルとその中のワークシートをどう探し出したものかと途方にくれました
【KNIMEでのデータ処理紹介_01】
【公開されたworkflow】
上記の通り、データに関してはあの手この手で隠されていて、入手と概要の理解だけでも一苦労しました。
一方で、KNIMEでのETLに関してはworkflow (WF)などが公開されているので救われます。
久しぶりにKNIME APのEXAMPLESを探り、下記のWFを見つけたので使ってみます。

下記のリンク先と同じWFです。
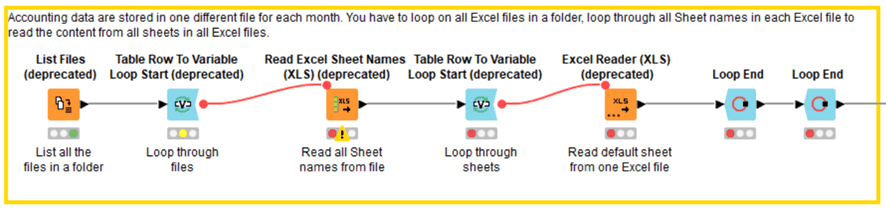
上記のパートがとても参考になるのですが、このWFは古いバージョンで作成されていたのでdeprecatedになっています。
そこで私の使っているKNIME AP ver.4.4.4のノードで再構築しながらカスタマイズしました。
【ETL①】カイザー財団病院グループ (KAISER PERMANENTE)のExcel群
今回扱う2グループのうち、より大きな医療機関のグループのようです。知らなかったけどすごい。
以下にどうやってデータ抽出したかを紹介します。

各フォルダ内に散らばって格納されているExcelファイル群から、どのファイルを取って来るかのリストをつくる必要があります。
List Files/Foldersノードで全てのファイルをリストアップし、Row Filterで絞り込みます。
この後のループ処理も含めてまっきーさんの記事はとても参考になると思います。
設定:

以下、Kaiserグループのファイルの命名規則に沿って絞り込み条件を決めました。

一つだけ一時ファイルが混じったので下記条件で削除

結果:
途中経過も見てもらった方が上記の設定にした理由はわかりやすいのですが割愛します。

36のExcelファイルが該当するようです。
【ETL②】各Excelに複数のデータシートがある場合
上記のリストから1例を見てみましょう。

各シートが各病院にあたるようです。
上記のように
医療行為名、2021年のCPT_Code(要するにID番号)、平均料金
がリストアップされていて、空白のところは「病院が行う最も一般的な25の外来処置」にあたらないので記入されていないようです。各病院で25の内訳が異なるのでデータとして欠損があるのはやむなしです。
このシートの構成がKaiserグループ内では統一されているのが救いです。
ここまでを把握するためにあちこちのフォルダの各ファイルを開いて比較してと半日くらいかけて元データの構成理解に努めました。データジャーナリストのお仕事はきっと本当に大変だろうと思います。
データ収集はこのシートたちの決まった領域から上記の3つのカラムのデータを抽出すればよいのだと理解してWFは下記のように組みました。

参考にした上述のWFと一部違うのは、隠れシートがあったので除外したり、抽出したデータから必要な部分だけに絞り込んだりしているためです。
基本的には同じ仕様で、ひとまずシートのリストを作るループが走り、その中で各シートからのデータ読み取りと整形をするループを走らせ、そのすべてをまとめて縦に並べたデータテーブルにします。
下記は各ノードの設定の列挙です。
設定:
Excelファイルごとのループ開始

シートのリストアップ


隠れシート(Top 50 List)があって集計の邪魔になるので除去

シートごとのループ処理スタート

ExcelのセルA7からC61に限定してデータを取得。カラム名はindexだけとって後で命名。


Col2は料金データなので数値すなわちDouble型へ変換

カラム名を下記に統一

料金データがない行は不要なので削除

シートごとのループ終了

Excelファイルごとのループ終了

WFを作る前の調査こそが今回の課題の難所だった気がして説明を手厚くした分、ちょっと説明はしょりすぎですかね。
結果:
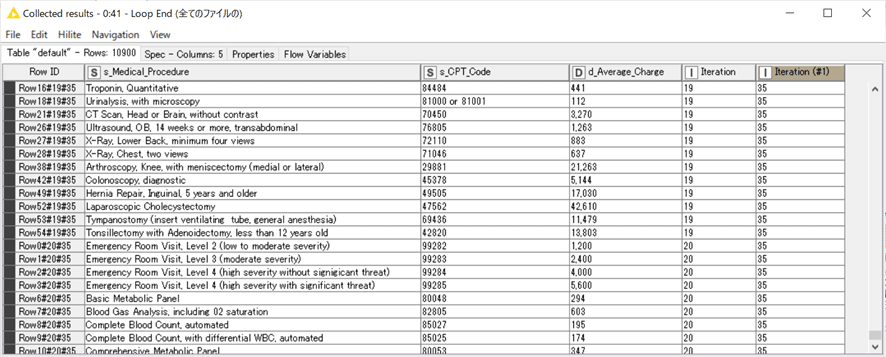
35のExcelファイルごとに20ぐらいのシート数があったりするので、総計10900行のリストができました。プログラムで自動化しなかったらさすがに集計したくない。
ここまで書いてもう3000字近いので続きは次回へ。サター病院グループの集計やその後の解析が待っています。
KNIME Hubに解答は上げています。
おまけ:
【JKI_032 感想戦】
先週のJust KNIME It! 第32回は見事に誤解してました。
嫌な予感はしていたのですが。
「JKI_032については一部制約つきだが設計上のヒントや明確な出力の指示がなかったので、皆さんの多様な解答を楽しみにしています。」
なんて言っていた自分が恥ずかしい…
公式解答はこちら。
Excelに出力しろなんて言ってないよね、確かに。
一方で下記の処理が要るとも言われてなかったので、全く同じWFを回答した人はきっといないだろうと思います。

むしろExcelで示されたデータテーブルに合わせた下記のWFを回答した方が多いようでした。
まあ単なるデータ並べ替えだけなら5ではなく3ノードで実装可能と確認したから良しとします。
いいなと思ったら応援しよう!
