
【DX12th】Day4_データの扱いとEBPM

本日の内容はデータの扱いとEBPM
合理性のある意思決定
DX= IT化 × 業務革新であり、
DXの第一段階は
機械にできることは機械がやれるようにすること
DXの第二段階は
その時間でデータに基づいた意思決定により、新しい価値創造ができること
である。
Volatility(変動性)
Uncertainty(不確実性)
Complexity(複雑性)
Ambiguity(曖昧性)
の時代には、
なにが正解か、なにを選択するとうまくいくのかがわからない
そんな変化の激しい時代の中で、高い確率で効果のある施策を行うには?
ヒューリスティックによる意思決定から、
現実に即した合理性のある意思決定へ
ヒューリスティックとは
経験則や先入観に基づいて、ある程度正解に近い解を得る思考法や手法のこと
経験則は、因果関係は不明確でありながらも、
・今までの経験から得られる事実にもどづいた法則
・経験上、おそらくそうなるだろうと考えられる法則
の2つの側面がある。
経験則からではなく、合理性のある意思決定を行うためには
EBPM(Evidence-baced policy making)ですすめる必要がある
エビデンスについて
エビデンスについてはレベルがある
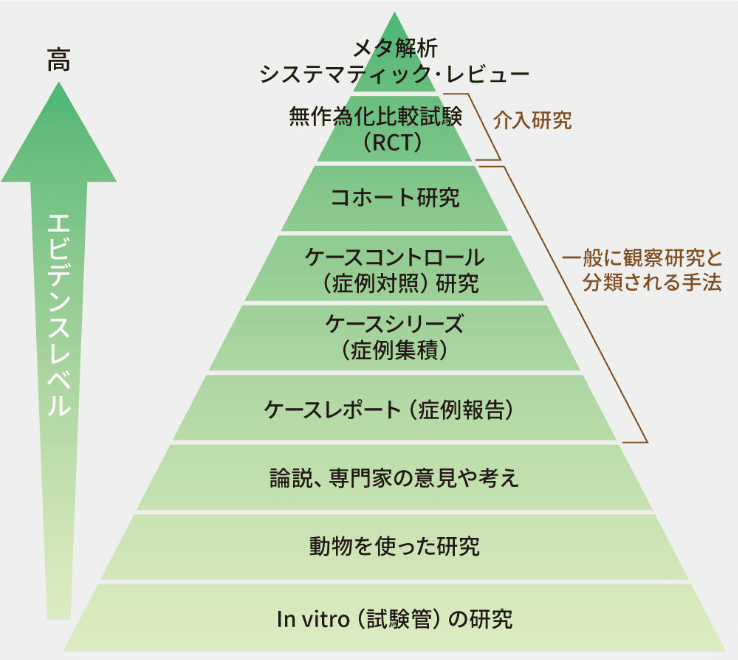
これは医療分野の研究におけるエビデンスレベルであるが、
上であるほど、エビデンスレベルが高い
例えば、ある人はこうだったから、とか、この人がこう言っているから、他でうまくいった、というのは、エビデンスレベルが低い
エビデンスをだしていくには、結果と関係があると仮説をたてている因子以外の条件を揃えていかなければいけない
そうでないと、相関関係なのか因果関係なのかは評価できない
相関関係:要因Aの変化と要因Bの変化に対応関係があること
因果関係:要因Aの変化が原因となって、要因Bの変化が結果として起きること
・不法投棄が減ったのは、ライトを設置した(相関関係)からではなく、自治会の啓蒙活動が活発であった(因果関係)から
・アイスの売り上げとビールの売り上げは相関関係があるが、因果関係があるのは気温
・ニコラスケイジが映画にでるほど、プールで溺死する人が多い(相関関係)
ただ現実的には、なかなか他の条件をすべて揃えることは難しい
そこででてくるのが、無作為化比較試験(RCT)である
無作為化比較試験(RCT)
無作為化比較試験(RCT)というのは
参加者をランダムに分類することで、他の条件が違うことででる影響をなるべく減らす方法である
医療分野でのRCTは、書類や倫理審査、患者の選定や説明、多施設でやるのかなどなど、時間も手間もお金もすごくかかる
一方、デジタルの世界では、このエビデンスレベルの高いRCTが
とても簡単にできる(無料でできることも多く、驚愕!)
バラクオバマ元大統領の寄付を募るためのメルマガの登録フォームでは、
3種類のトップ画像、動画、次に進むのボタンの表記などでABテストを行った
その結果、プロのデザイナーが当初最も効果がでるだろうと考えていたものとは、別のものが一番効果がでたらしい
詳しくはこちらのサイトに

プロのデザイナーが考えたものより、RCTによって合理的に判断していく方が、顧客に響き、より利益をもたらすものが作れることは衝撃だった
Day3で学んだロジカルにデザインする威力を感じた
データに基づく意思決定、データドリブン思考
ここからは講義の内容と、★3つのおすすめ本『データ分析・AIを実務に活かす データドリブン思考』の内容を合わせながら、まとめていこうと思う
使える状態にすることが、このnoteの目的なので
データを基に意思決定をしていく、とあるが
そもそも意思決定とは?

『現場で活用される』とは『現場の意思決定に活用される』
『意思決定に活用される』とは『意思決定プロセスに分析結果が使われる』
分析結果が使われるように『意思決定プロセスを設計する』
意思決定プロセスは、次の3段階のモジュールから構成されるFrameワークで記述できる
Step1 選択肢を集める
↓
Step2 手掛かりを得る ← データ分析
↓
Step3 選択をする
複数の選択肢の中から、"なんらかの手がかり"をもとに選択を行っている!
エビデンスベースの意思決定とは、選択の基準を形式知化(可視化)した上で関係のあう数字を用いること
(形式知とは、文章や計算式、図表などで説明できる知識のこと)
どんな情報を手がかりに、判断しているか、人間が判断する基準を言語化・可視化して、
誰でも同じように判断するようにすることで、
認識バイアスを除外して選択ができる
(誰でも同じように判断できるということは、AIにもできる可能性がある、人間と同程度・それ以上の結果をだすことができる可能性がある)

現場を観察して、問題を見つけ
どういう情報があるといいか、判断につながる要因の情報を整理し、
分析を行い、意思決定を改善していく
EBPM = 定量的なデータドリブン+定性的な調査と分析
同時に行い、使ってもらうにはどうすればいいかを考える
データの扱い方
現代ではツールを使えば、裏でデータがとられている
データをみて、正しく考えるようになることが必要
その一例としてファクトフルネスの本の内容が紹介されていた
知っている、わかっていると感じているものほど、バイアスを持ちやすい
データの種類
データときいて一番イメージができるのは、ビックデータであるが、
その他にも個人情報であるパーソナルデータや
二次利用できるオープンデータ
がある
パーソナルデータはサーバーに送るときに個人情報をなるべくそぎ落とした状態にして送るなどの工夫があるといい
オープンデータを使用して、必ずしも自社のデータだけで完結しなくてもいいと説明されていた
AI人材育成講座の大麦の発表はオープンデータを使用されていた
資産としてのデータ
データ自体はあっても、横断的に使用できなければ、データの力は発揮できない

サイロは牧場などで隔離という意味で使用されるそうだが、
課ごとにシステムが違ったり、保存されているデータの形が違うと
横断的に使用することはできない
データパイプラインなどを用いて、適切に収集・保管、必要なときに適切にとってこれる、同時に使用できる状態にしておく
サービスは使われなくなっても、データはその後も活用できる資産として残る
サービス自体は「すぐ作れる」、「すぐ捨てられる」状態であることが重要
サービスを資産にするのではなく、データを資産として残し、
サービスがなくなった後も、EBPMの高い意思決定に使用していく
とりあえず、次の授業までに書き終えることを目標にしていたので、公開
また修正すると思います
この記事が気に入ったらサポートをしてみませんか?