
Pythonフレームワーク:Pytorchによる自作Datasets/Dataloaderの作成

1.概要
本記事ではPytorchを使用して自作のDatasets/Dataloaderを作成することでミニバッチ学習のためのデータ作成を実施します。
1-1.コラム:自作Datasetsが必要な理由
色々な本やブログでは下記のようなコードを良く見ますがが、実データを使用すると通常のDataloaderだけではlabel付で出力させるのは難しいです。
よって自分のデータでもlabels付きで出力できるデータセットを自作できるようにしておきたいと思います。
[よく見る例]
DataLoader(<listのdata>)
for data, label in Dataloader():
XXXX1-2.練習用サンプルデータの取得/作成
サンプルデータは下記記事参考に画像を取得しました。今回はtrainとvalに同じデータが入りますが、サンプル用のためそのまま進めます。
[IN]
import os
import glob
from icrawler.builtin import BingImageCrawler
#フォルダ作成
def make_dirs(rootpath='./'):
if not os.path.exists(f'{rootpath}/data'): os.makedirs(f'{rootpath}/data') #データ保存用:ルート
if not os.path.exists(f'{rootpath}/data/train'): os.makedirs(f'{rootpath}/data/train') #train用データ
if not os.path.exists(f'{rootpath}/data/val'): os.makedirs(f'{rootpath}/data/val') #val用データ
def getimages(keys, maxnum, save_dir):
for keyword in keys:
bing_crawler = BingImageCrawler(storage={'root_dir': save_dir})
bing_crawler.crawl(keyword=keyword, max_num=maxnum, filters=None) #filtersでは画像のサイズやタイプを指定可
#ファイル名の書き換え
_path_imgs = glob.glob(f'{save_dir}/*') #全ての画像パスを取得
path_imgs = [i for i in _path_imgs if os.path.basename(i)[0].isdigit()] #数字で始まるファイル名のみ処理
for idx, path_img in enumerate(path_imgs):
dirname = os.path.dirname(path_img)
extension = os.path.basename(path_img).split('.')[-1]
os.rename(path_img, os.path.join(dirname, f'{keyword}_{idx}.{extension}'))
#画像の取得
keywords = ['dog', 'cat'] #検索キーワードと保存先の指定
#フォルダ作成
make_dirs()
#データ取得
getimages(keys=keywords, maxnum=2, save_dir='data/train') #train用データの取得
getimages(keys=keywords, maxnum=2, save_dir='data/val') #val用データの取得
[OUT]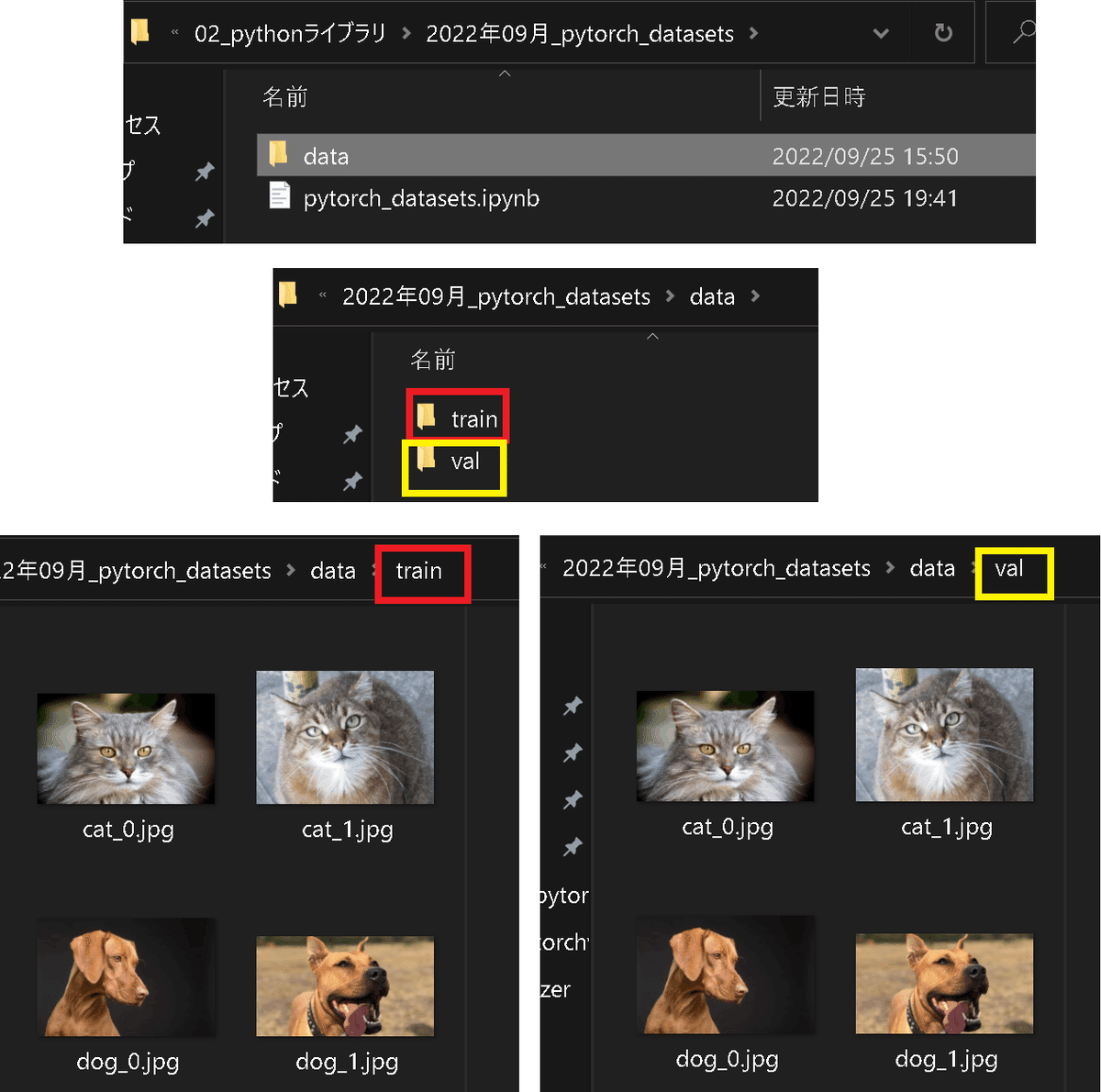
[参考:クラスパターン]
他のブラウザでの操作できるようにClass化したコードも紹介します。なお "GoogleImageCrawler"は使用できないため実装しておりません。
[IN]
import os
import glob
from icrawler.builtin import BingImageCrawler, BaiduImageCrawler, GoogleImageCrawler
#フォルダ作成
def make_dirs(rootpath='./'):
if not os.path.exists(f'{rootpath}/data'): os.makedirs(f'{rootpath}/data') #データ保存用:ルート
if not os.path.exists(f'{rootpath}/data/train'): os.makedirs(f'{rootpath}/data/train') #train用データ
if not os.path.exists(f'{rootpath}/data/val'): os.makedirs(f'{rootpath}/data/val') #val用データ
def rename_files(path_imgs, keyword):
for idx, path_img in enumerate(path_imgs):
dirname = os.path.dirname(path_img)
extension = os.path.basename(path_img).split('.')[-1]
os.rename(path_img, os.path.join(dirname, f'{keyword}_{idx}.{extension}'))
class GetImager:
def __init__(self, keys, maxnum, save_dir):
self.keywords = keys
self.maxnum = maxnum
self.save_dir = save_dir
def __call__(self, browser_name):
browsers = {'bing':BingImageCrawler, 'baidu':BaiduImageCrawler}
browser = browsers[browser_name]
for keyword in self.keywords:
crowler = browser(storage={'root_dir':self.save_dir}) #保存先の指定
crowler.crawl(keyword=keyword, max_num=self.maxnum) #画像検索
#ファイル名の修正
_path_imgs = glob.glob(f'{self.save_dir}/*')
path_imgs = [i for i in _path_imgs if os.path.basename(i)[0].isdigit()]
rename_files(path_imgs, keyword)
#画像の取得
keywords = ['dog', 'cat'] #検索キーワードと保存先の指定
#フォルダ作成
make_dirs()
#データ取得
getimages(keys=keywords, maxnum=12, save_dir='data/train') #train用データの取得
getimager = GetImager(keys=keywords, maxnum=12, save_dir='data/val')
getimager('bing')
[OUT]
同上1.基本設計
自作Datasets/Dataloaderの基本設計は下記の通りです。
【機能】
データ及びラベルリスト取得:glob()でデータのパスを取得
データの前処理:T.Compose()でTensor化、正規化やデータ拡張など実装
Datasetsの作成:PytorchのDatasetモジュールを継承したうえで、1.と2.を組みこんで(data, label)で出力できるクラスを作成
DataLoaderの作成:DataloaderはPytorchのモジュールをそのまま使用
【ポイント】
学習時(train)と検証時(val)で別処理ができるように調整
2.Datasetsの作成
2-1.データPathリストの取得
集めた画像データのパスリストを取得できる関数を作成します。関数はフォルダの構成に合わせて適宜調整します。
[IN]
def get_pathlist(root, phase='train'):
path_target_jpg = os.path.join(root, phase, '*.jpg') #JPEGファイルのパスを取得
path_target_png = os.path.join(root, phase, '*.png') #PNGファイルのパスを取得
pathlist = glob.glob(path_target_jpg) + glob.glob(path_target_png) #JPEGとPNGのパスを結合
return pathlist
path_imgs_train = get_pathlist(root='data', phase='train')
path_imgs_val = get_pathlist(root='data', phase='val')
print(path_imgs_train, path_imgs_val)
[OUT]
['data\\val\\cat_0.jpg', 'data\\val\\cat_1.jpg', 'data\\val\\cat_10.jpg', 'data\\val\\cat_11.jpg', 'data\\val\\cat_2.jpg', 'data\\val\\cat_3.jpg', 'data\\val\\cat_4.jpg', 'data\\val\\cat_5.jpg', 'data\\val\\cat_6.jpg', 'data\\val\\cat_7.jpg', 'data\\val\\cat_8.jpg', 'data\\val\\cat_9.jpg', 'data\\val\\dog_0.jpg', 'data\\val\\dog_1.jpg', 'data\\val\\dog_10.jpg', 'data\\val\\dog_11.jpg', 'data\\val\\dog_2.jpg', 'data\\val\\dog_3.jpg', 'data\\val\\dog_4.jpg', 'data\\val\\dog_5.jpg', 'data\\val\\dog_6.jpg', 'data\\val\\dog_7.jpg', 'data\\val\\dog_8.jpg', 'data\\val\\dog_9.jpg']
['data\\train\\cat_0.jpg', 'data\\train\\cat_1.jpg', 'data\\train\\cat_10.jpg', 'data\\train\\cat_11.jpg', 'data\\train\\cat_2.jpg', 'data\\train\\cat_3.jpg', 'data\\train\\cat_4.jpg', 'data\\train\\cat_5.jpg', 'data\\train\\cat_6.jpg', 'data\\train\\cat_7.jpg', 'data\\train\\cat_8.jpg', 'data\\train\\cat_9.jpg', 'data\\train\\dog_0.jpg', 'data\\train\\dog_1.jpg', 'data\\train\\dog_10.jpg', 'data\\train\\dog_11.jpg', 'data\\train\\dog_2.jpg', 'data\\train\\dog_3.jpg', 'data\\train\\dog_4.jpg', 'data\\train\\dog_5.jpg', 'data\\train\\dog_6.jpg', 'data\\train\\dog_7.jpg', 'data\\train\\dog_8.jpg', 'data\\train\\dog_9.jpg']2-2.データの前処理
データの前処理をする関数を作成します。この前処理をDatasetの中に組み込むことで前処理したデータを取得できるようにします。前処理はモデルに合わせたらよいですが今回はISLVRC用で下記を実装します。
【共通】
●ToTensor:テンソルに変換
●Normalize:標準化
【Train用】
●RandomResizedCrop:リサイズ後にランダムに切り抜き※(size×size)になる
●RandomHorizontalFlip:ランダムに水平反転
【val用】
●Resize:画像のサイズ変更※intだとHeightのみresizeされwdthはそのまま
●CenterCrop:画像の中央部を切り抜き※widthを指定サイズで切り抜く
参考用として関数とクラスの2パターン作成しました。なお前処理とは関係ないですが確認用に可視化のコードも追記しました。
train/val用の同一機能があるならクラス化した方が綺麗だと思います。
【関数】
[IN]
from PIL import Image
import torch
import torchvision.transforms as T
import matplotlib.pyplot as plt
transforms_train = T.Compose([
T.RandomResizedCrop(224, scale=(0.5, 1.0)), #画像をランダムに切り抜き 224×224にリサイズ, scaleで切り抜く画像の大きさを指定
T.RandomHorizontalFlip(), #画像をランダムに左右反転
T.ToTensor(), #Tensorに変換
T.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225]) #ImageNetの平均と標準偏差で正規化
])
transforms_val = T.Compose([
T.Resize(224), #画像をリサイズ※このままだとtorch.Size([3, 224, 358])
T.CenterCrop(224), #画像を中央で切りぬいて224x224にする
T.ToTensor(), #Tensorに変換
T.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225]) #ImageNetの平均と標準偏差で正規化
])
img = Image.open(path_imgs_train[0]) #画像の読み込み
img_train = transforms_train(img) #train用の変換
img_val = transforms_val(img) #val用の変換
print(img_train.shape, img_train.min(), img_train.max(), img_val.shape, img_val.min(), img_val.max())
[OUT]
torch.Size([3, 224, 224]) tensor(-2.1179) tensor(2.6400) torch.Size([3, 224, 224]) tensor(-2.1179) tensor(2.6400)【クラス】
[IN]
class ImageTransform():
def __init__(self, resize, mean, std):
self.data_transform = {
'train': T.Compose([
T.RandomResizedCrop(resize, scale=(0.5, 1.0)), #画像をランダムに切り抜き 224×224にリサイズ
T.RandomHorizontalFlip(), #画像をランダムに左右反転
T.ToTensor(), #Tensorに変換
T.Normalize(mean, std) #ImageNetの平均と標準偏差で正規化
]),
'val': T.Compose([
T.Resize(resize), #画像をリサイズ※このままだとtorch.Size([3, 224, 358])
T.CenterCrop(resize), #画像を中央で切りぬいて224x224にする
T.ToTensor(), #Tensorに変換
T.Normalize(mean, std) #ImageNetの平均と標準偏差で正規化
])
}
def __call__(self, img, phase='train'):
return self.data_transform[phase](img)
size = 224
mean, std = (0.485, 0.456, 0.406), (0.229, 0.224, 0.225) #ImageNetの平均と標準偏差
transform = ImageTransform(resize=size, mean=mean, std=std)
img_train = transform(img, phase='train') #train用の変換
img_val = transform(img, phase='val') #val用の変換
print(img_train.shape, img_train.min(), img_train.max(), img_val.shape, img_val.min(), img_val.max())
[OUT]
torch.Size([3, 224, 224]) tensor(-2.1179) tensor(2.6400) torch.Size([3, 224, 224]) tensor(-2.1179) tensor(2.6400)【画像確認用】
[IN]
img_train, img_val = torch.clip(img_train, 0, 1), torch.clip(img_val, 0, 1) #tensorの値を0~1に変更※Matplotlibで表示するため
print(img_train.shape, img_train.min(), img_train.max(), img_val.shape, img_val.min(), img_val.max())
fig, ax = plt.subplots(1, 2, figsize=(10, 5))
ax[0].imshow(img_train.permute(1,2,0)), ax[1].imshow(img_val.permute(1, 2, 0))
ax[0].set_title('Image_train'), ax[1].set_title('Image_val')
plt.show()
[OUT]
torch.Size([3, 224, 224]) tensor(-2.1179) tensor(2.6400) torch.Size([3, 224, 224]) tensor(-2.1179) tensor(2.6400)
torch.Size([3, 224, 224]) tensor(0.) tensor(1.) torch.Size([3, 224, 224]) tensor(0.) tensor(1.)
2-3.自作Datasetクラスの作成:Datasetの継承
自作データセットを作成していきますがポイントは下記の通りです。
1.torch.utils.data.Datasetモジュールを継承してDatasetを作成
2.DataLoaderでミニバッチ作成のため"len"と"getitem”を設定
->__len__():return len(iterable)でiterableの数をlen()で取得できる
->__getitem__():リストのように[idx]でデータを取得できる
3.基本的に”データ”と”ラベル”は別処理となるため状況に合わせてクラスを要調整
作成したDatasetには下記機能が確認できる。
【自作Datasetの機能】
1.出力はTupleであり(data, label)の形である
2.len()でデータ数が確認できる
3.list形式の形でデータが抽出できる
4.確認用としてTrueを与えるとファイル名を出力できるようにする
[IN]
from torch.utils.data import Dataset, DataLoader
class Dataset_DogCat(Dataset):
def __init__(self, file_list, transform=None, phase='train', return_path=False):
self.file_list = file_list #画像のパスを格納したリスト
self.transform = transform #前処理クラスのインスタンス
self.phase = phase #train or valの指定
self.return_path = return_path #画像のパスを返すかどうか
def __len__(self):
return len(self.file_list) #画像の枚数を返す
def __getitem__(self, index):
#画像の前処理
img_path = self.file_list[index] #index番目の画像のパスを取得
img = Image.open(img_path) #PIL形式で画像を読み込み
img_transformed = self.transform(img, self.phase) #画像の前処理を実施
#ラベルデータの取得
label = os.path.basename(img_path).split('_')[0] #画像名は「cat_0.jpg」のようになっているので、catかdogかを取得
json_labels = {'cat': 0, 'dog': 1} #ラベルをjson形式で定義
if self.return_path:
return img_transformed, json_labels[label], os.path.basename(img_path) #画像のtensor形式データ、ラベル、画像のパスを返す
else:
return img_transformed, json_labels[label] #画像のtensor形式データとラベルを返す
train_dataset = Dataset_DogCat(file_list=path_imgs_train,
transform=ImageTransform(size, mean, std),
phase='train')
val_dataset = Dataset_DogCat(file_list=path_imgs_val,
transform=ImageTransform(size, mean, std),
phase='val')
print(train_dataset, val_dataset) #インスタンスの確認
print(f'trainデータ数: {len(train_dataset)}, valデータ数: {len(val_dataset)}') #データ数の確認
print(type(train_dataset[0]), type(train_dataset[0][0]), type(train_dataset[0][1])) #データの確認
print(train_dataset[0][0].shape, train_dataset[0][1]) #データの確認
# plt.imshow(torch.clip(train_dataset[0][0].permute(1, 2, 0), 0, 1)) #猫であることを確
[OUT]
<__main__.Dataset_DogCat object at 0x000001ED21D66430> <__main__.Dataset_DogCat object at 0x000001ED21D66070>
trainデータ数: 24, valデータ数: 24
<class 'tuple'> <class 'torch.Tensor'> <class 'int'>
torch.Size([3, 224, 224]) 0参考として画像名とラベルを合わせて出力してみました。
[IN]
train_dataset_withpath = Dataset_DogCat(file_list=path_imgs_train,
transform=ImageTransform(size, mean, std),
phase='train',
return_path = True)
for i in range(20):
img, label, path = train_dataset_withpath[i]
print(f'img.shape:{img.shape}, Filename: {path}, Label: {label}')
[OUT]
Filename: cat_0.jpg, Label: 0
Filename: cat_1.jpg, Label: 0
Filename: cat_10.jpg, Label: 0
Filename: cat_11.jpg, Label: 0
Filename: cat_2.jpg, Label: 0
Filename: cat_3.jpg, Label: 0
Filename: cat_4.jpg, Label: 0
Filename: cat_5.jpg, Label: 0
Filename: cat_6.jpg, Label: 0
Filename: cat_7.jpg, Label: 0
Filename: cat_8.jpg, Label: 0
Filename: cat_9.jpg, Label: 0
Filename: dog_0.jpg, Label: 1
Filename: dog_1.jpg, Label: 1
Filename: dog_10.jpg, Label: 1
Filename: dog_11.jpg, Label: 1
Filename: dog_2.jpg, Label: 1
Filename: dog_3.jpg, Label: 1
Filename: dog_4.jpg, Label: 1
Filename: dog_5.jpg, Label: 13.ミニバッチの作成:DataLoader
ミニバッチを作成するには"torch.utils.data.DataLoader"を使用します。
[DataLoaderの引数]
DataLoader(dataset, batch_size=1, shuffle=False, sampler=None,
batch_sampler=None, num_workers=0, collate_fn=None,
pin_memory=False, drop_last=False, timeout=0,
worker_init_fn=None, *, prefetch_factor=2,
persistent_workers=False)【DataLoaderの引数】
●dataset:ロード元のデータセット
●batch_size{defalut:1}:バッチごとのサンプル数(ミニバッチ数)
●shuffle{defalut:False}:エポックごとにデータをシャッフルするかどうか
●sampler{defalut:-}:データセットからサンプルを抽出する方法を指定する
●batch_sampler{defalut:-}:samplerと同じ(バッチデータのindexを返す)
●num_workers{defalut:0}:データのロードに使用するサブプロセスの数
●collate_fn{defalut:-}:-
●pin_memory{defalut:False}:データローダーがテンソルを返す前にCUDA固定メモリにコピー
●drop_last{defalut:False}:データセットサイズがバッチサイズで割り切れない場合に、最後のバッチを破棄するかどうか
●timeout{defalut:0}:バッチ収集時のタイムアウトの値を設定
出力のポイントは下記の通りです。
【DataLoaderのポイント】
●出力はDatasetsに合わせて[<dataミニバッチ>, <labelミニバッチ>]で出力される。
●len(dataset)はミニバッチ数、len(dataset.dataset)はデータ数となる
●ミニバッチで出力されるため(ラベルはintでも)torch.tensor形式で出力
●割り切れない数は最後に余りの数だけ出力
●動作チェックしやすいようにshuffle=Falseにしたが、通常はTrueでよい
[IN]
train_dataloader = DataLoader(train_dataset, batch_size=8, shuffle=False)
val_dataloader = DataLoader(val_dataset, batch_size=7, shuffle=False)
print('train:', len(train_dataloader), 'val:', len(val_dataloader)) #minibatch数の確認
print('train:', len(train_dataloader.dataset), 'val:', len(val_dataloader.dataset)) #データ数の確認
#train/valの使い分け用に辞書型変数にまとめる
dataLoaders_dict = {'train': train_dataloader, 'val': val_dataloader}
for imgs, labels in dataLoaders_dict['train']:
print(type(imgs), imgs.shape ,type(labels), labels.shape, labels)
for imgs, labels in dataLoaders_dict['val']:
print(type(imgs), imgs.shape ,type(labels), labels.shape, labels)
[OUT]
train: 3 val: 4
train: 24 val: 24
<class 'torch.Tensor'> torch.Size([8, 3, 224, 224]) <class 'torch.Tensor'> torch.Size([8]) tensor([0, 0, 0, 0, 0, 0, 0, 0])
<class 'torch.Tensor'> torch.Size([8, 3, 224, 224]) <class 'torch.Tensor'> torch.Size([8]) tensor([0, 0, 0, 0, 1, 1, 1, 1])
<class 'torch.Tensor'> torch.Size([8, 3, 224, 224]) <class 'torch.Tensor'> torch.Size([8]) tensor([1, 1, 1, 1, 1, 1, 1, 1])
<class 'torch.Tensor'> torch.Size([7, 3, 224, 224]) <class 'torch.Tensor'> torch.Size([7]) tensor([0, 0, 0, 0, 0, 0, 0])
<class 'torch.Tensor'> torch.Size([7, 3, 224, 224]) <class 'torch.Tensor'> torch.Size([7]) tensor([0, 0, 0, 0, 0, 1, 1])
<class 'torch.Tensor'> torch.Size([7, 3, 224, 224]) <class 'torch.Tensor'> torch.Size([7]) tensor([1, 1, 1, 1, 1, 1, 1])
<class 'torch.Tensor'> torch.Size([3, 3, 224, 224]) <class 'torch.Tensor'> torch.Size([3]) tensor([1, 1, 1])4.番外編:2値問題の転移学習
せっかく2値問題を作成したので参考までに転移学習させてみました。(本当はtrain/valは別データがよいですが今回は参考用としてそのままいきます)
4-1.学習済みモデルのLoad/パラメータ調整
ILSVRCで使用されたresnet18を用いて下記流れでモデル実装しました。
ロギング用/表示用の関数を定義
torchvision.modelsで学習済みのresnet18をload
resnet18の最終層(fc)を1000分類->2値分類に変更
最終層のパラメータ以外はすべて"param.requires_grad = False"にする
最適化関数optim()に更新するパラメータ(List形式)を渡す
目的関数(損失関数)や学習率ηなど設定して学習用関数を作成/実行
def logging_epoch(logs, epoch, loss, accuracy): #学習結果を辞書に格納する関数
logs['epoch'].append(epoch) #学習回数を格納
logs['loss'].append(loss) #損失関数を格納
logs['accuracy'].append(accuracy) #正解率を格納
logs = {'train':{'epoch':[], 'loss':[], 'accuracy':[]},
'val':{'epoch':[], 'loss':[], 'accuracy':[]}} #学習結果を格納する辞書
def plot_logs(logs): #学習結果のグラフ化
fig, ax = plt.subplots(1, 2, figsize=(15, 5))
#損失関数のグラフ化
ax[0].plot(logs['train']['epoch'], logs['train']['loss'], label='train', ls='--') #train
ax[0].plot(logs['val']['epoch'], logs['val']['loss'], label='val') #val
ax[0].set_xlabel('epoch')
ax[0].set_ylabel('loss')
ax[0].set_title('Time series of Loss')
ax[0].legend(), ax[0].grid()
#正解率のグラフ化
ax[1].plot(logs['train']['epoch'], logs['train']['accuracy'], label='train', ls='--') #train
ax[1].plot(logs['val']['epoch'], logs['val']['accuracy'], label='val') #val
ax[1].set_xlabel('epoch')
ax[1].set_ylabel('accuracy')
ax[1].set_title('Time series of Accuracy')
ax[1].legend(), ax[1].grid()
plt.show()[IN]
from torchvision import models
import torch.nn as nn
import torch.optim as optim
from tqdm import tqdm
model_resnet18 = models.resnet18(pretrained=True)
model_resnet18.fc = nn.Linear(in_features=512, out_features=2) #出力層を2クラス分類用に変更
#訓練モード
model_resnet18.train()
criterion = nn.CrossEntropyLoss() #損失関数の定義
#転移学習:学習用パラメータの選択
# _paramnames = [n for n, p in model_resnet18.named_parameters()] #モデルのパラメータ名確認用
# print(_paramnames)
params_update = [] #学習させるパラメータを格納するリスト
names_param_updata = ["fc.weight", "fc.bias"]
for name, param in model_resnet18.named_parameters():
if name in names_param_updata:
param.requires_grad = True #学習させるパラメータ
params_update.append(param)
else:
param.requires_grad = False #学習させないパラメータ
print(f'学習用params: {params_update}')
epochs=30 #学習回数
lr = 0.001 #学習率
optimizer = optim.Adam(params_update, lr=lr) #model_resnet18.parameters()だと全パラメータが学習対象になる
#学習用関数の定義
def train_model(net,dataloaders, criterion, optimizer, epochs):
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
net = net.to(device)
for epoch in range(epochs):
print('Epoch {}/{}'.format(epoch+1, epochs))
print('-------------')
for phase in ['train', 'val']:
if phase == 'train':
net.train() #訓練モード
else:
net.eval() #評価モード
epoch_loss = 0.0 #epochの損失和
epoch_corrects = 0 #epochの正解数
#未学習時のval性能を確認するため、epoch=0の時は学習させない
if (epoch == 0) and (phase == 'train'):
continue
for inputs, labels in tqdm(dataloaders[phase]):
#CUDAが使えるならGPUにデータを送る
inputs = inputs.to(device)
labels = labels.to(device)
optimizer.zero_grad() #勾配の初期化
#順伝播(forward)の計算
with torch.set_grad_enabled(phase == 'train'): #学習時は勾配を計算するが、評価時は勾配を計算しない
outputs = net(inputs) #順伝播
loss = criterion(outputs, labels) #損失の計算※ミニバッチの平均値
_, preds = torch.max(outputs, 1) #ラベルの予測
if phase == 'train':
loss.backward() #逆伝播
optimizer.step() #重みの更新
epoch_loss += loss.item() * inputs.size(0) #lossの合計を更新※ミニバッチの合計値
epoch_corrects += torch.sum(preds == labels.data) #正解数の合計を更新
if epoch%1 == 0: #epochの表示間隔調整
epoch_loss = epoch_loss / len(dataloaders[phase].dataset) #epochの損失和をデータ数で割る
epoch_acc = epoch_corrects.double() / len(dataloaders[phase].dataset) #epochの正解率
logging_epoch(logs[phase], epoch, epoch_loss, epoch_acc.item()) #ログの保存
print(f'{phase}|epoch:{epoch}, Loss:{epoch_loss}, Accuracy:{epoch_acc}') #epochごとのlossと正解率の表示
train_model(model_resnet18, dataLoaders_dict, criterion, optimizer, epochs=epochs)[OUT]
学習用params: [Parameter containing:
tensor([[ 0.0273, -0.0290, 0.0345, ..., -0.0030, 0.0192, 0.0111],
[ 0.0318, 0.0052, 0.0325, ..., 0.0178, -0.0266, 0.0328]],
requires_grad=True), Parameter containing:
tensor([-0.0084, -0.0266], requires_grad=True)]
Epoch 1/10
-------------
100%|██████████| 4/4 [00:01<00:00, 2.55it/s]
val Loss: 1.0512 Acc: 0.2083
Epoch 2/10
-------------
100%|██████████| 3/3 [00:01<00:00, 2.05it/s]
train Loss: 2.5523 Acc: 0.4167
100%|██████████| 4/4 [00:01<00:00, 2.60it/s]
val Loss: 1.2649 Acc: 0.5000
Epoch 3/10
-------------
-------------
100%|██████████| 3/3 [00:01<00:00, 1.97it/s]
train Loss: 0.7384 Acc: 0.4583
100%|██████████| 4/4 [00:01<00:00, 2.83it/s]val Loss: 0.2227 Acc: 0.91674-2.学習の推移を確認
学習の推移を可視化するために事前に関数を作成しておりますので、後はそれを実行するだけです。
[IN]
plot_logs(logs)
[OUT]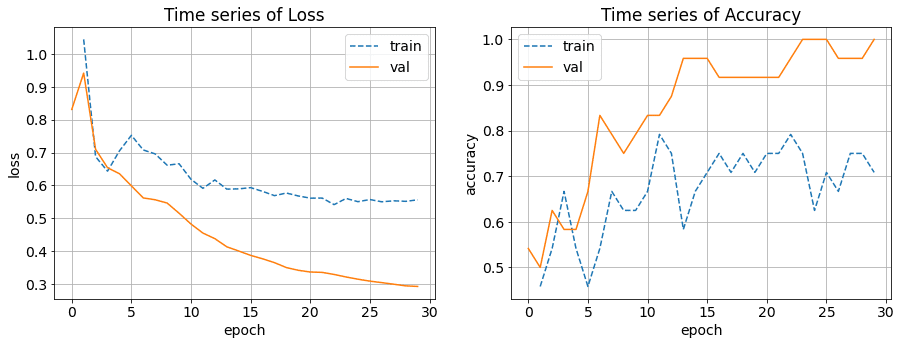
4-3.正解ラベル比較:混同行列(Confusion matrix)
下記を実行して結果を確認します。
検証用データ(本当はtest用があればそれが良い)を使用して、学習済みモデルで推論
”torch.max(_y_pred, 1)[1]”で正解値(index)を取得
上記ではGPUで計算したためoutputsなどはすべてcpu()に戻す
confusion matrix×Seabornで可視化
[IN]
from sklearn.metrics import confusion_matrix
model_resnet18.eval() #評価モード
#混同行列の計算
_ = DataLoader(val_dataset, batch_size=len(val_dataset), shuffle=False)
for x_val, labels in _: break
x_val = x_val.to(device) #GPUにデータを送る
_y_pred = model_resnet18(x_val) #予測
y_pred = torch.max(_y_pred, 1)[1] #ラベルの予測
accuracy = (y_pred.cpu() == labels).sum().item() / len(labels) #正解率
print(f'正解率: {accuracy:.3f}')
import seaborn as sns
#混同行列の計算
plt.rcParams['font.size'] = 14
matrix = confusion_matrix(labels, y_pred.cpu().detach().numpy())
fig, ax = plt.subplots(figsize=(8,6))
sns.heatmap(matrix, annot=True, fmt='d', cmap='Blues', cbar=False, #fmt='d'で整数
xticklabels=['cat', 'dog'], yticklabels=['cat', 'dog'])
ax.set(title='confusion matrix', ylabel='True label', xlabel='Predicted label')[OUT]
正解率: 0.917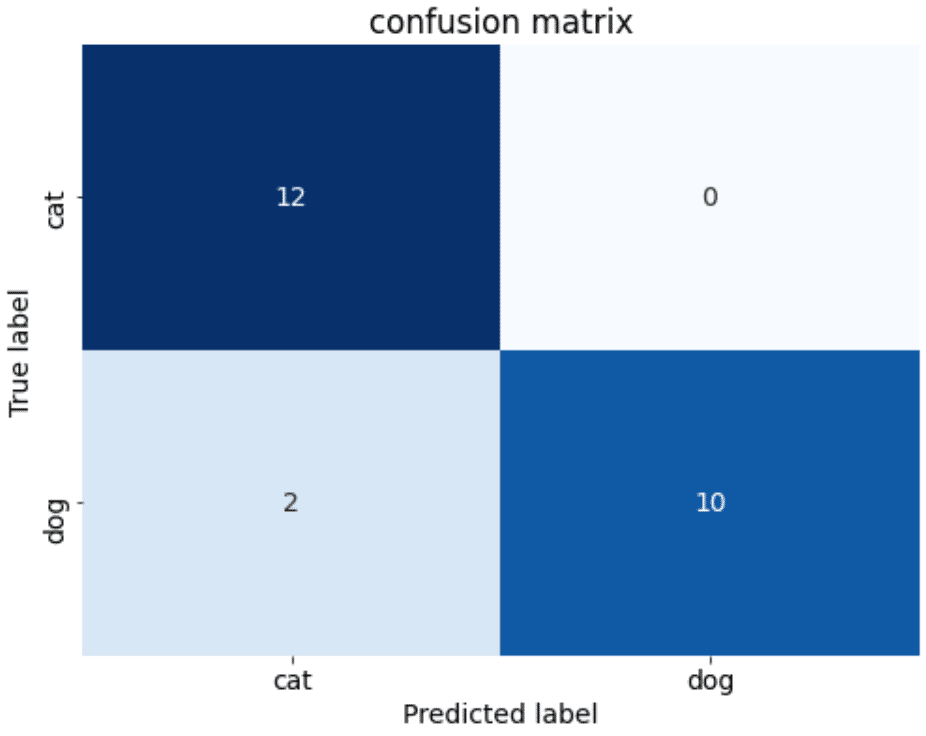
4-4.モデルの保存
学習済みモデルおよび(参考用に)ロギングデータを保存します。
[IN]
import joblib
torch.save(model_resnet18, 'model_resnet18.pth') #モデルの重み保存
torch.save(model_resnet18.state_dict(), 'params_resnet18.pth') #モデルの重み保存
joblib.dump(logs, 'logs_resnet18.pkl') #ログの保存参考資料
資料1:ライブラリ関係
資料2:本
あとがき
GitHub Copilot使用しながらコード書いてるけど、マジで参考資料みたいなコードが一瞬で出てきてヤバすぎる・・・
自分の実装力がしょぼくならないかが不安・・・・・・