
コンペ用メモ:Kaggle

Kaggleへ参戦する時の自分用メモ帳です。
1.ガイドライン/ルール関係
1-1.ガイドライン
1-2.エチケット/用語
2.作業環境
2-1.PCスペック(メモリ/Accelerator)
「code」->「New Notebook」から新しいNotebookを作成できます。
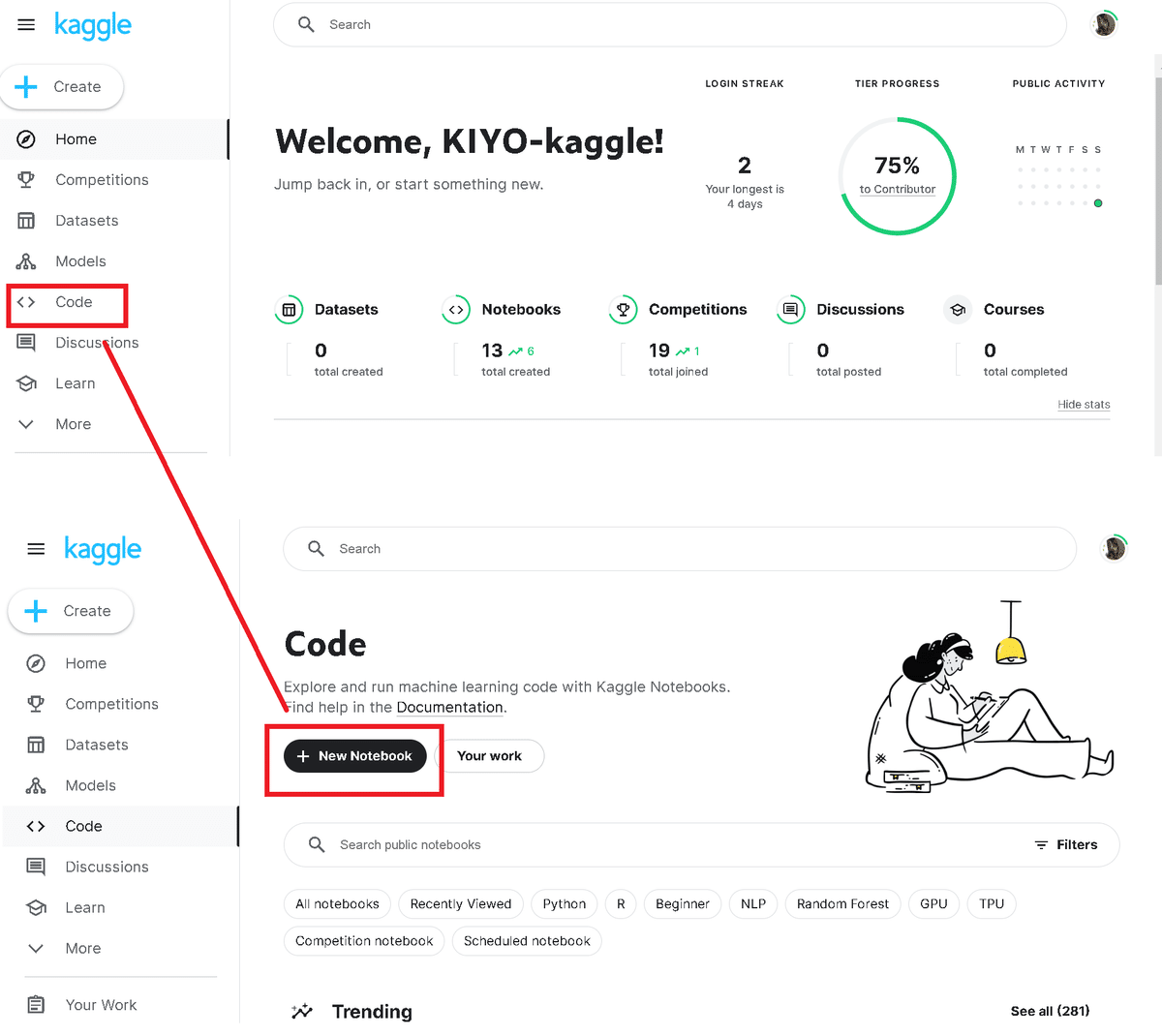
Codeブロックから作成したNoteBookのメモリは30GBあり、GPUなどの利用が可能です。
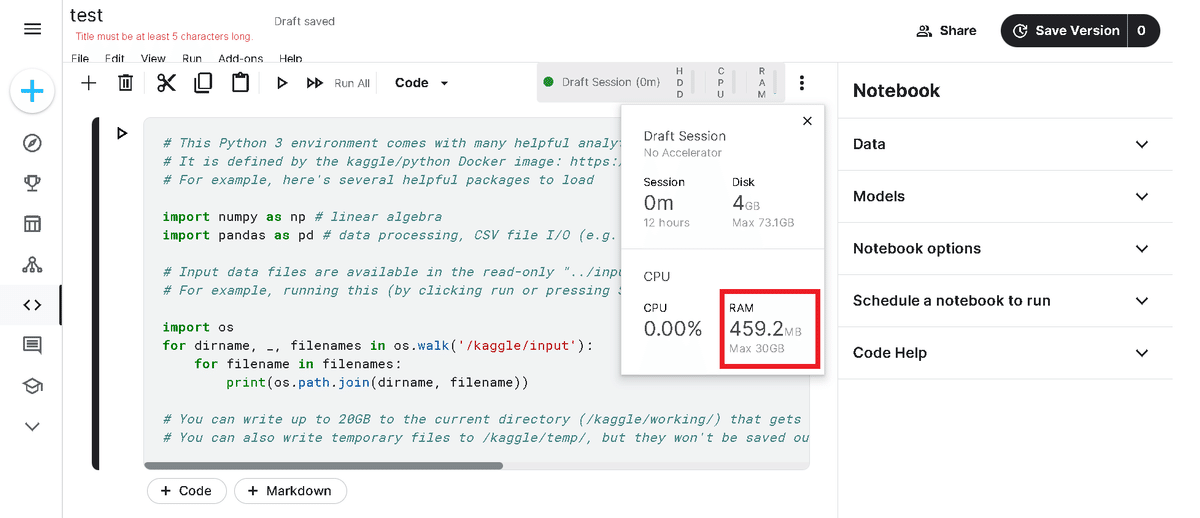
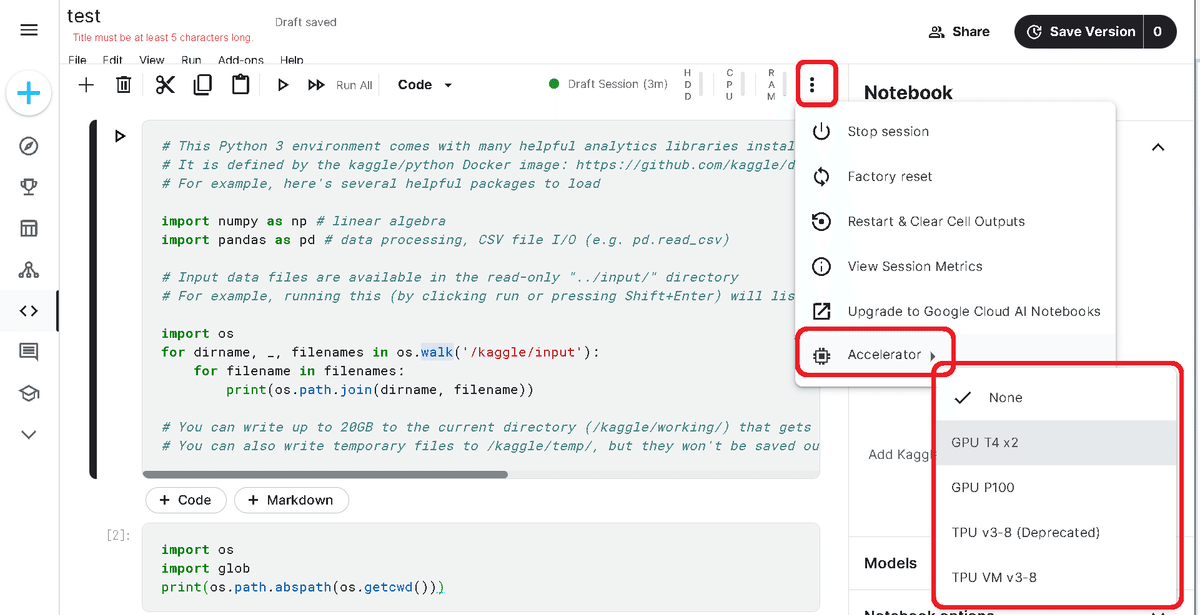
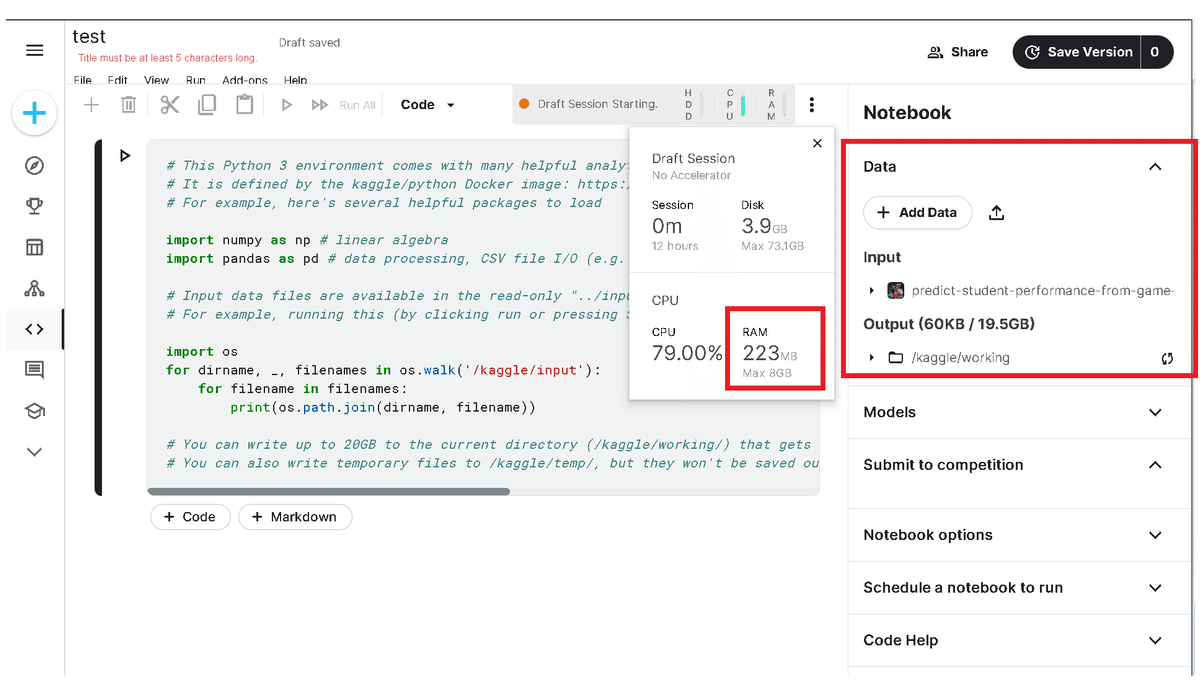
ただし制約付きコンペ(メモリ上限有、GPU/TPUなどの使用禁止)がある場合、コンペのページからNotebookを開くことはもちろんですが「Data->Add Data」からコンペのデータセットを追加した時点でメモリに制約がかかります。
なおコンペ外であればデータセットを削除して再起動することでメモリは元の30GBに復活します。
2-2.ディレクトリ構造:CodeブロックのNotebook
Codeブロックから作成したNotebookは{親フォルダ: 'kaggle'}でありその中の'working'フォルダが作業環境となります。
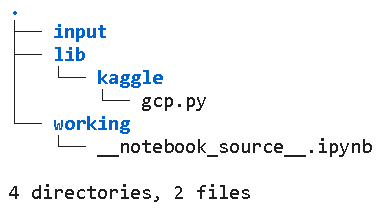
[IN]
import os
import glob
print(os.path.abspath(os.getcwd()))
print(glob.glob('*'))
!tree[OUT]
/kaggle/working
['__notebook_source__.ipynb']
.
└── __notebook_source__.ipynb
0 directories, 1 file2-3.ディレクトリ構造:コンペのNotebook
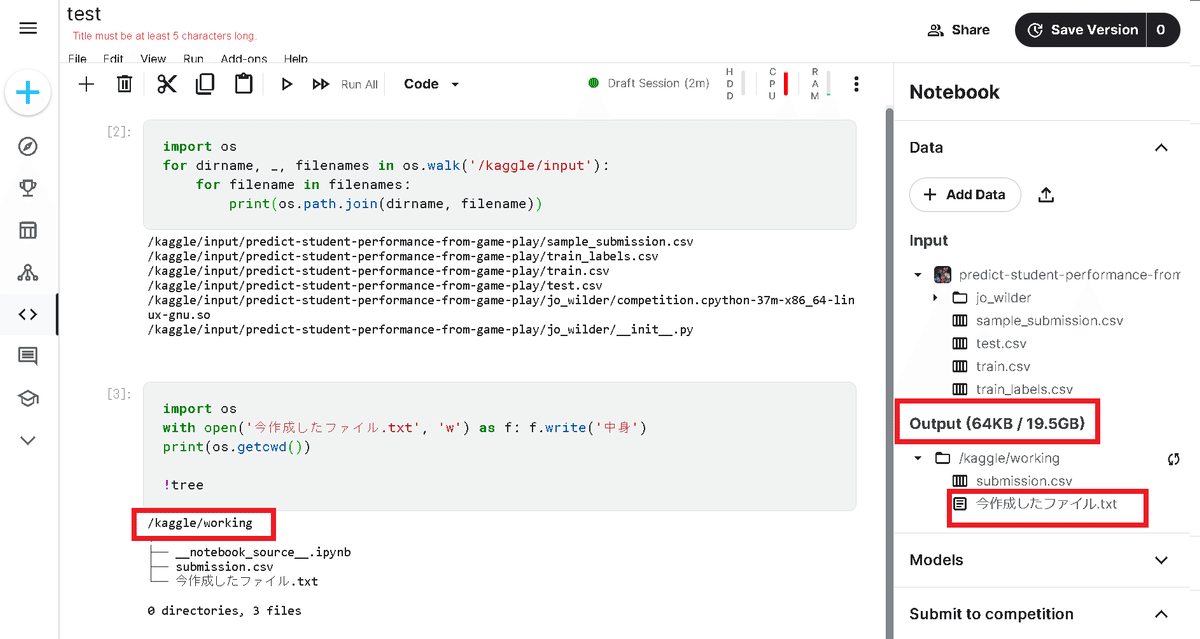
コンペ内のディレクトリ構造も確認します。コンペは「Predict Student Performance from Game Play」を使用しました。

作業ディレクトリは"kaggle/working"ですがinputフォルダにはコンペで使用するデータセットが既に入っております。
[IN]
import os
import glob
print(os.path.abspath(os.getcwd()))
print(glob.glob('*'))
!tree[OUT]
/kaggle/working
['submission.csv', '__notebook_source__.ipynb']
.
├── __notebook_source__.ipynb
└── submission.csv
0 directories, 2 files親フォルダに移動して全体を確認しました。
[IN]
os.chdir(os.path.dirname(os.getcwd()))
print(os.path.abspath(os.getcwd()))
print(glob.glob('*'))
!tree[OUT]
/kaggle
['lib', 'input', 'working']
.
├── input
│ └── predict-student-performance-from-game-play
│ ├── jo_wilder
│ │ ├── __init__.py
│ │ └── competition.cpython-37m-x86_64-linux-gnu.so
│ ├── sample_submission.csv
│ ├── test.csv
│ ├── train.csv
│ └── train_labels.csv
├── lib
│ └── kaggle
│ └── gcp.py
└── working
├── __notebook_source__.ipynb
└── submission.csv
6 directories, 9 filesなお右ブロックの"Output”はデフォルトの作業パス"kaggle/working"と連動しており、このディレクトリ内で作成・保存したファイルはOutput側に反映されます。
3.提出方法
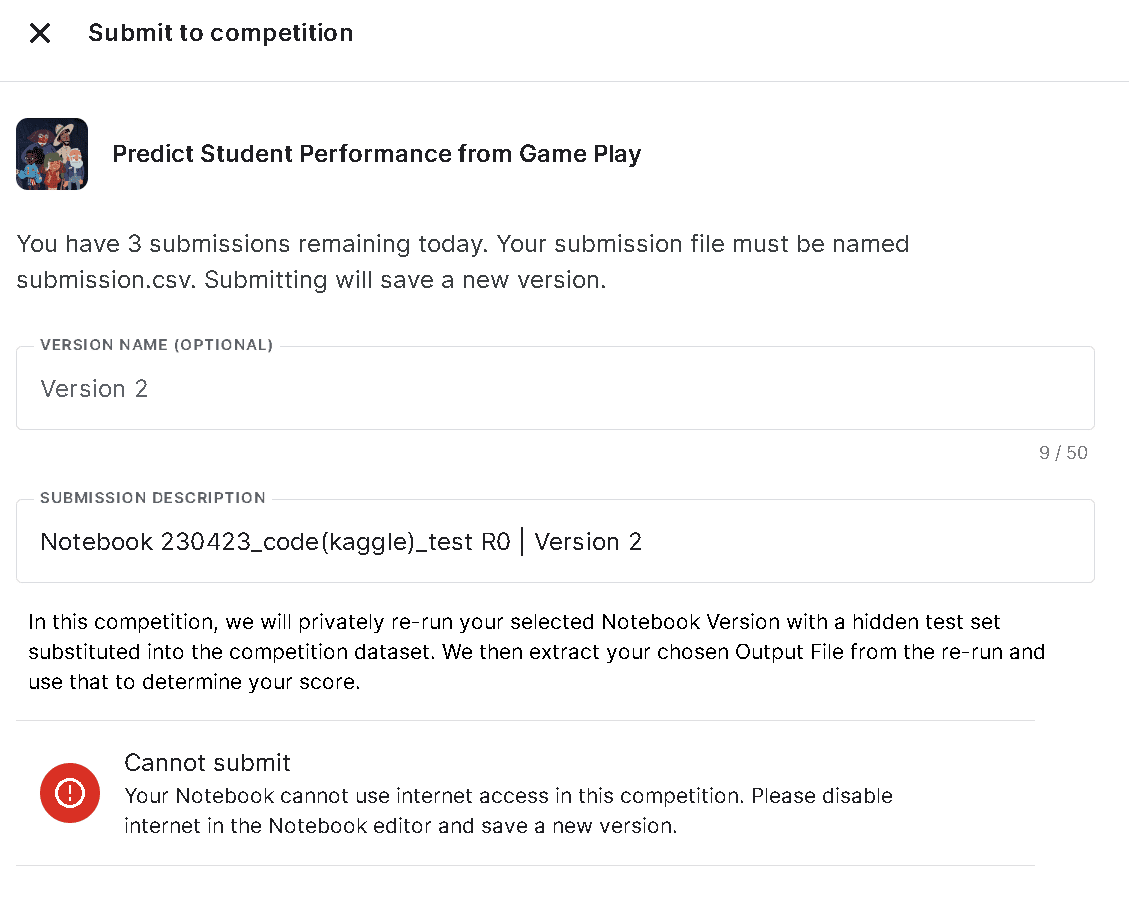
3-1.カーネルコンペのNotebook提出:submitできない
カーネルコンペ(提出物が予想値ではなくNotebookそのもの)においてファイルが提出できず下記エラーが発生しました。
Your Notebook cannot use internet access in this competition. Please disable internet in the Notebook editor and save a new version.
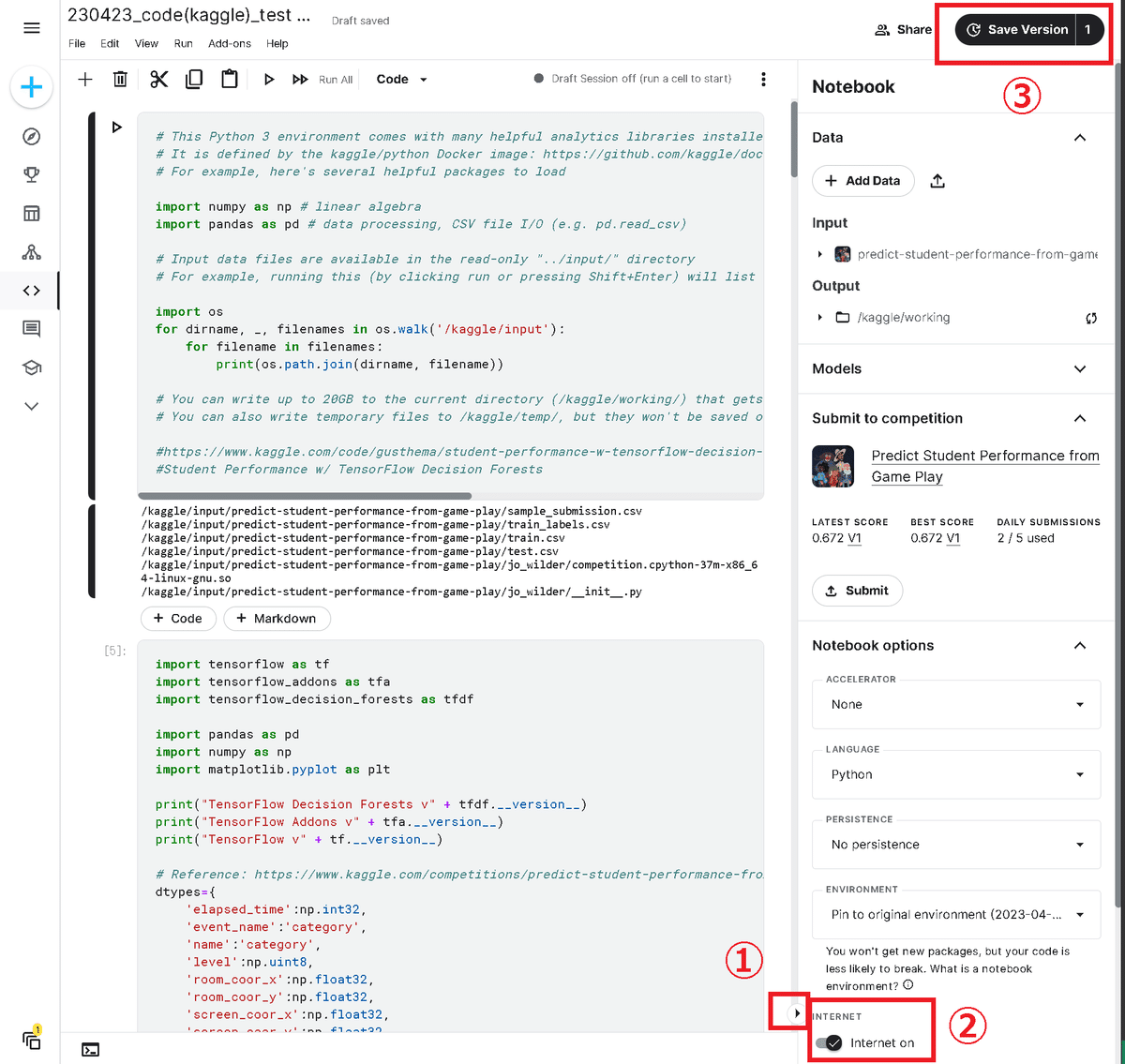
上記記事を参考にして下記手順で対応できました。
右下のマークをクリックしてサイドバーを開く
「Notebook Option」からInternetのトグルをOff
Notebookの動作確認後に新しいバージョンとして保存
4.予備章
5.役立ちコード:EDA編
5-1.DataFrameのサマリー情報確認
Pandasにはdf.info()やdf.describe()でDataFrameの情報を確認できますが自分が欲しい情報が不足しています。このsummary関数では各カラム(列情報)における下記情報を一括で取得できます。
データ型:データの種類や前処理の必要性確認
欠損値の数と割合:前処理の有無や方法(削除するか埋めるかなど)
統計情報(最大値、最小値):データの幅を確認
データの1~3番目の値:データの中身確認
オリジナルはdf.loc[<idx>]だったがindexがバラバラのデータだとエラーになるためilocに修正
[IN]
#EDA(Exploratory Data Analysis)
def summary(df):
print(f'data shape: {df.shape}')
summ = pd.DataFrame(df.dtypes, columns=['data type'])
summ['#missing'] = df.isnull().sum().values
summ['%missing'] = df.isnull().sum().values / len(df) * 100
summ['#unique'] = df.nunique().values
desc = pd.DataFrame(df.describe(include='all').transpose())
summ['min'] = desc['min'].values
summ['max'] = desc['max'].values
summ['first value'] = df.iloc[0, :].values
summ['second value'] = df.iloc[1, :].values
summ['third value'] = df.iloc[2, :].values
return summ[IN]
import pandas as pd
df_sample = pd.DataFrame({'A': [1, 2, 3], 'B': [4, 5, 6], 'C': [7, 8, 9]})
HorizontalDisplay(df_sample, summary(df_sample))
[OUT]
5-2.欠損値の可視化
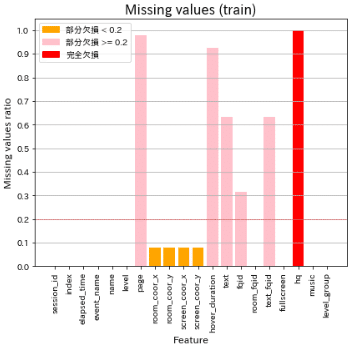
欠損値を可視化するコードです。オリジナルから少し自分用にアレンジ(色分けを3段階、複数の図を表示可、図のフォントサイズを調整)して関数化しました。
[IN]
import matplotlib.patches as mpatches
def plot_missing_values_ratio(df_list, titlenames, threshold=1, verbose=False):
if isinstance(df_list, pd.DataFrame):
df_list = [df_list]
fig, axes = plt.subplots(nrows=1, ncols=len(df_list), figsize=(8 * len(df_list), 8), facecolor='white')
plt.rcParams['font.size'] = 16
if len(df_list) == 1:
axes = [axes]
for i, (df, titlename) in enumerate(zip(df_list, titlenames)):
missing_ratios = df.isna().sum() / len(df)
colors = ['red' if ratio == 1 else
'pink' if ratio >= threshold else
'orange' for ratio in missing_ratios.values]
#欠損値を割合による色分けで棒グラフを描画
axes[i].bar(missing_ratios.index,
missing_ratios.values,
color=colors)
#閾値の線を描画
axes[i].axhline(y=threshold, color='red', linestyle='--', lw=0.5)
axes[i].set_xlabel('Feature', fontsize=12)
axes[i].set_ylabel('Missing values ratio', fontsize=12)
axes[i].set_yticks(np.arange(0, 1.1, 0.1))
axes[i].set_title(f'Missing values ({titlename})', fontsize=12)
axes[i].tick_params(axis='x', labelrotation=90)
axes[i].legend(handles=[mpatches.Patch(color='orange'),
mpatches.Patch(color='pink'),
mpatches.Patch(color='red')],
labels=[f'部分欠損 < {threshold}' ,
f'部分欠損 >= {threshold}',
'完全欠損'],
fontsize=12)
#グリッド線を描画
if verbose:
axes[i].grid(axis='y')
plt.tight_layout()
plt.show()[IN]
plot_missing_values_ratio([df_train, df_test], ['train', 'test'], threshold=0.5, verbose=True)
plot_missing_values_ratio([df_train], ['train'], threshold=0.2, verbose=True)
[OUT]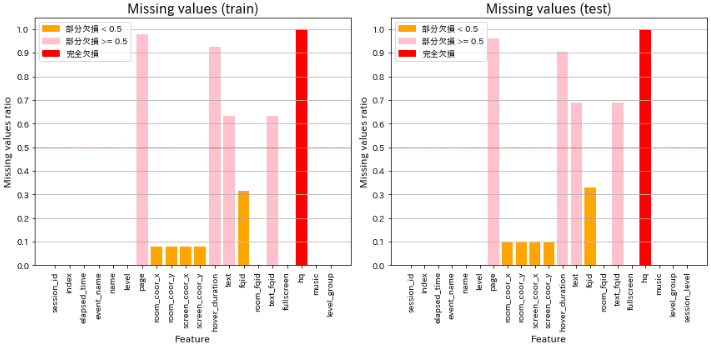
6.役立ちコード:高速化/メモリ節約編
6-1.DataFrameのメモリサイズ削減
データの型式を最適化することでDataFrameのメモリ削減が可能です。メモリ制限のあるコンペなどで役立ちます。
[IN]
# Reduce Memory Usage
# reference : https://www.kaggle.com/code/arjanso/reducing-dataframe-memory-size-by-65 @ARJANGROEN
def reduce_memory_usage(df):
start_mem = df.memory_usage().sum() / 1024**2
print('Memory usage of dataframe is {:.2f} MB'.format(start_mem))
for col in df.columns:
col_type = df[col].dtype.name
if ((col_type != 'datetime64[ns]') & (col_type != 'category')):
if (col_type != 'object'):
c_min = df[col].min()
c_max = df[col].max()
if str(col_type)[:3] == 'int':
if c_min > np.iinfo(np.int8).min and c_max < np.iinfo(np.int8).max:
df[col] = df[col].astype(np.int8)
elif c_min > np.iinfo(np.int16).min and c_max < np.iinfo(np.int16).max:
df[col] = df[col].astype(np.int16)
elif c_min > np.iinfo(np.int32).min and c_max < np.iinfo(np.int32).max:
df[col] = df[col].astype(np.int32)
elif c_min > np.iinfo(np.int64).min and c_max < np.iinfo(np.int64).max:
df[col] = df[col].astype(np.int64)
else:
if c_min > np.finfo(np.float16).min and c_max < np.finfo(np.float16).max:
df[col] = df[col].astype(np.float16)
elif c_min > np.finfo(np.float32).min and c_max < np.finfo(np.float32).max:
df[col] = df[col].astype(np.float32)
else:
pass
else:
df[col] = df[col].astype('category')
mem_usg = df.memory_usage().sum() / 1024**2
print("Memory usage became: ",mem_usg," MB")
return df[IN]
df_sample = pd.DataFrame({'A': [1, 2, 3], 'B': [4, 5, 6], 'C': [7, 8, 9]}, dtype='float64')
display(summary(df_sample))
df_sample_reducedmemory = reduce_memory_usage(df_sample)
display(summary(df_sample_reducedmemory))
[OUT]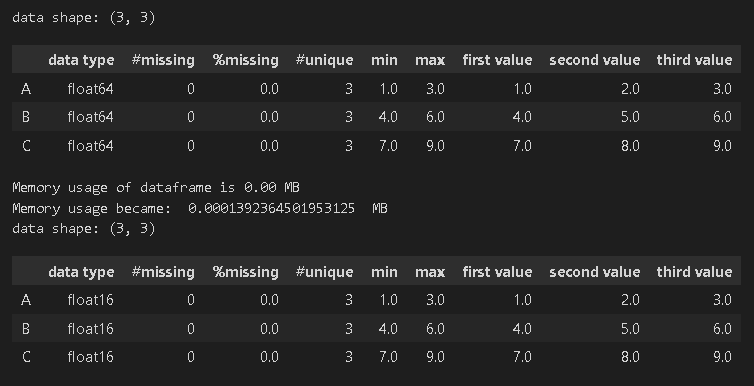
【参考:Parquetに変換】
Nishikaの「金融時系列予測」コンペのトピックより「データを事前加工し、ファイルサイズ、読み込み時間、メモリ使用量を8割以上削減する」が紹介されています。
こちらもデータ型を最適化してparquet形式で保存することでメモリ量削減、読み込み速度の上昇を図っています。

7.役立ちコード:再現性
コードの出力結果は(良い結果にせよ悪い結果にせよ)再現性が取れることが重要です。再現性を保証するためのコードを紹介します。
7-1.乱数値の固定
乱数値を固定する関数は下記の通りです。本コードではPyTorchにおけるGPU使用時の乱数も固定してくれるため非常に便利です。
[IN]
def seed_everything(seed=1234):
random.seed(seed)
os.environ['PYTHONHASHSEED'] = str(seed)
np.random.seed(seed)
torch.manual_seed(seed)
torch.cuda.manual_seed(seed)
torch.backends.cudnn.deterministic = True
seed_everything()参考資料
あとがき
2023年4月23日:初版記載
2023年8月18日:7章追加(再現性、乱数値)