
SIGNATEコンペの練習1:医療保険の費用帯予測

1.概要
最近学んだPyCaretの能力検証も含めてコンペに参加してみました。今回はSIGNATEの「【第22回_Tier限定コンペ】医療保険の費用帯予測」です。

結論としては「PyCaretはそこそこ使える。ただ、トップ狙うならまだまだ足りない」感じでした。
2.事前準備:SIGNATE側
2-1.データ概要の確認
データは一般的(専門知識が不要)な情報から医療保険の価格帯(charges)を3分類で予想する問題です。

評価指標は分類で適合率(Precision) · 再現率(Recall)のバランスをみるF1スコアで計算されます。

提出CSVの形はヘッダー無しでindexとラベルの2列とします。

2-2.学習・評価用データのダウンロード
学習・評価用データを下記からダウンロードします。CLIでもDL可能ですがカラムの有無やデータ項目の意味を確認するためHPにはいくため手動で実行する方が楽です。

2-3.SIGNATE APIトークンの準備
データ予想後のCSVを提出する時にCLIを使用したいため事前にAPI Token(signate.json)を準備します。
※なおホーム右上の「投稿」を押して下記画面からでも投稿できるため手動で実行するなら本節は不要です。

3.事前準備:Google Colab側
PyCaretを使用するためGoogle Colabを使用します。
3-1.SIGNATE APIトークンの配置/CLI準備
下記手順でAPIトークン(signate.json)を配置しました。※データDLも提出も手動でするなら不要。
【Google Colab内での処理手順】
1.(Googleドライブ内にトークンを入れてるため)ドライブのマウント
2.親フォルダに移動して、rootディレクトリ内に.signateを作成
3..signateディレクトリ内にAPIトークンをコピー
4.初期のディレクトリに戻る
5.CLIが使用できるようにsignateライブラリをインポート
[IN]
import os, shutil
from google.colab import drive
drive.mount('/content/drive') #Googleドライブをマウント
path_signate = '/content/drive/MyDrive/11. コンペ/signate.json' #ファイル保管場所
os.chdir('../')#ディレクトリを親ファイルに移動
#親ファイル内のrootフォルダにjsonファイルを移動
path_target = './root/.signate'
if os.path.exists(path_target) != True:
os.mkdir(path_target) #rootフォルダに.signateを作成
# shutil.copy(path_signate, os.path.join(path_target, 'signate.json'))
shutil.copy(path_signate, path_target)
print(f'{path_target}にjsonをコピーしました。')
os.chdir('./content') #起動時の作業ディレクトリに戻る
print(os.getcwd())
!pip install signate
3-2.必要なファイルの配置
contentフォルダ(作業dir)にDLしたファイルをアップロードします。

APIトークンを準備した場合は"signate download --competition-id=<id>"を実行すると作業dirにファイルをDLできます。
[IN]
# !signate list #① 投稿可能なコンペティション一覧の取得
!signate download --competition-id=725 #③ コンペティションが提供するファイルのダウンロード3-3.必要ライブラリのインポート
google colabは基本的な環境構築はされておりますが不足分は自分でインポートします。今回はPyCaretに必要な環境構築を実行します。
[IN]
#必要なライブラリのインストール
!pip install pandas-profiling==3.1.0
!pip install pycaret
!pip install shap
#Google Colabでのインタラクティブ化
from pycaret.utils import enable_colab
enable_colab()3-4.記事紹介用:Pandasのdf並列表示
記事紹介用+見やすさも考慮してDataFrameを並列で表示できる関数を作成しました。
[IN]
from IPython.display import display_html
def display_dfs(dfs, gap=50, justify='center'):
html = ""
for title, df in dfs.items():
df_html = df._repr_html_()
cur_html = f'<div> <h3>{title}</h3> {df_html}</div>'
html += cur_html
html= f"""
<div style="display:flex; gap:{gap}px; justify-content:{justify};">
{html}
</div>
"""
display_html(html, raw=True)4.データ解析
次章以降ではいろいろなパターンを検討しますが、本章ではどのモデルでも必要な処理を記載しました。
4-1.データ確認
データの中身に関しては最低でも下記を確認します。
【データ概要の確認事項】
①統計量
②欠損値の有無
③学習に使用しない(不要)なカラムの有無
④ラベルデータの偏り
[IN]
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
df_train = pd.read_csv('train.csv')
df_test = pd.read_csv('test.csv')
df_sample = pd.read_csv('sample_submit.csv', header=None) #カラム無しのためheader=None
print('df_train',df_train.shape, 'df_test', df_test.shape, 'df_sample', df_sample.shape)
display(df_train.head(5)) #提出データの形確認
#データの中身確認
display_dfs( {'df_train': df_train.describe(),
'df_test': df_test.describe()}
, justify='flex-start')
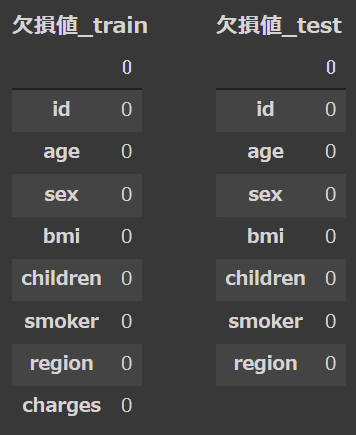
display_dfs( {'欠損値_train':pd.DataFrame(df_train.isnull().sum()),
'欠損値_test': pd.DataFrame(df_test.isnull().sum())}
, justify='flex-start')
df_train['charges'].value_counts() #ラベルデータの偏り確認
[OUT]
df_train (1200, 8) df_test (800, 7) df_sample (800, 2)
0 985
1 123
2 92
Name: charges, dtype: int64

【確認結果】
●学習データは1200程度であり少ない
●idカラムは学習に不要。それ以外は(モデル側で頑張ってくれると思うので)全部突っ込む
●数値データに関して統計量としては学習データとテストデータで大きな違い(MIN-MAXや標準偏差)はない。
●欠損値は学習・テストデータともになし:欠損地処理は不要
●ラベルデータは0(低)が多く1(中)、2(高)はそれぞれ10%、8%程度しかない:必要であれば学習時の教師データのバランスをとる
4-2.データの可視化:sns.pairplot()
データ同士の関係を確認するためにseabornのsns.pairplot()が便利です。
ー>特定の変数同士に高い相関(線形)がある場合は多重共線性による性能低下があるため前処理で不要なカラムを削除するか次元削減が必要です。
[IN]
sns.pairplot(df_train)
特に極端な傾向はなさそうなことを確認できました。(子供5人だとラベル=0くらいかな)
5.CASE1:シンプルなPyCaretで処理
まずはPyCaretをシンプルに使用してどの程度性能が出るか確認しました。結論として、このシンプルな処理でのLDA(Linear Discriminant Analysis)が本記事内での最高スコアでした。つまりいろいろハイパラや前処理をいじくりまわすより乱数値が運よくはまったものが良かった結果となりました。
5-1.前処理
まずは前処理を実施します。シンプルに①不要なカラム(id)を除去、②GPU使用 だけ追加して、後はPyCaret任せにします。
【確認事項】
●通常通り学習:検証=7:3で分割した
ー>今回はデータ数も少ないため、とりあえず学習・検証・テストの3分割ではなく2分割で実施してみる。
●前処理は(自動で)one-hot encoding
●カラムのidはignore_featuresで除去
●ラベルデータのバランスは学習・テスト時で大きくずれていないためfix_imbalance=Trueは実行しなかった
[IN]
from pycaret.classification import * #分類
exp = setup(df_train,
ignore_features=['id'],
use_gpu = True,
target = 'charges') #データの前処理
[OUT]
※session_idは実際処理した物とは別物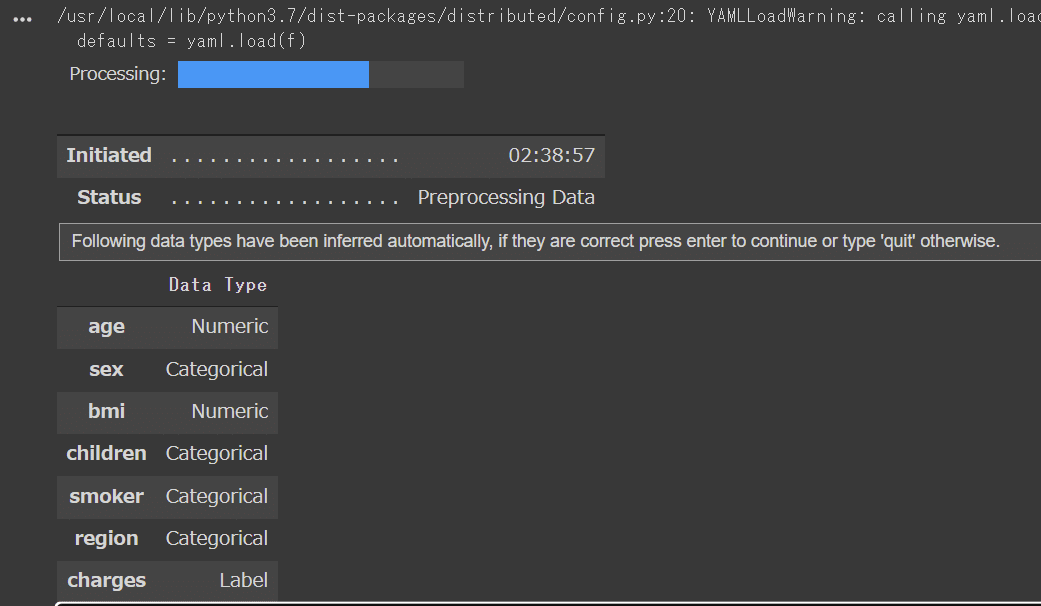

[IN ※追加で中身確認]
display(exp[37].head(5)) #前処理後データ(全データ=学習+検証)
exp[39].value_counts() #前処理後学習ラベル
[OUT]
0 693
1 88
2 58
5-2.学習・モデル比較
モデルの学習・比較を実施します。ランダム値(session_id)によって性能が変わるため毎回モデルの順位が前後します。
[IN]
best = compare_models() #モデルの比較
print(best)
print(type(best))
[OUT]
RidgeClassifier(alpha=1.0, class_weight=None, copy_X=True, fit_intercept=True,
max_iter=None, normalize=False, random_state=3940,
solver='auto', tol=0.001)
<class 'sklearn.linear_model._ridge.RidgeClassifier'>
学習時ではRidge回帰が最高性能となりましたが注意点は下記の通りです。
【学習時の注意点】
●後述しますがテストデータを使用するとモデルの順位は上下しますので学習時のベストモデル≠実際のベストモデルであることに注意
●ハイパーパラメータ調整していないため、調整しないとまともに性能が出ないモデル(例:SVM)は別途確認するかは判断すること
5-3.モデルの選択/ハイパーパラメーター調整
学習時のベストモデルはたまたま性能が良いだけかもしれませんので上位モデルを何個か試したいと思います。選択時は別種類のモデル(例:LightGBMを選択するならXGBoostは不要など)を選択しており、SIGNATEでは一日5回投稿できるため今回は5モデル選定しました。
[IN]
logistic = create_model('lr') #Logistic Regression
lda = create_model('lda') #Linear Discriminant Analysis
ramforest = create_model('rf') #Random Forest
lgbm = create_model('lightgbm') #Light GBM
#ハイパーパラメータ調整
tuned_ridge = tune_model(best) #Ridge Classifier
tuned_logistic = tune_model(logistic)
tuned_lda = tune_model(lda)
tuned_ramforest = tune_model(ramforest)
tuned_lgbm = tune_model(lgbm) 5-4.モデルの評価/結果の可視化
モデルの評価/結果の可視化を実施します。自分が詳しいモデルならハイパーパラメータの確認は重要ですが、よくわからない場合は最低でも①AUC:性能、②混同行列:精度、③学習カーブ:過学習は確認します。
[IN]
evaluate_model(tuned_ridge)
evaluate_model(logistic)
evaluate_model(lda)
evaluate_model(ramforest)
evaluate_model(lgbm) 
可視化はplot_modelで実施します(ridge回帰はAUCを作成できないためコメントアウト)
[IN]
# plot_model(tuned_ridge)
plot_model(logistic)
plot_model(lda)
plot_model(ramforest)
plot_model(lgbm) 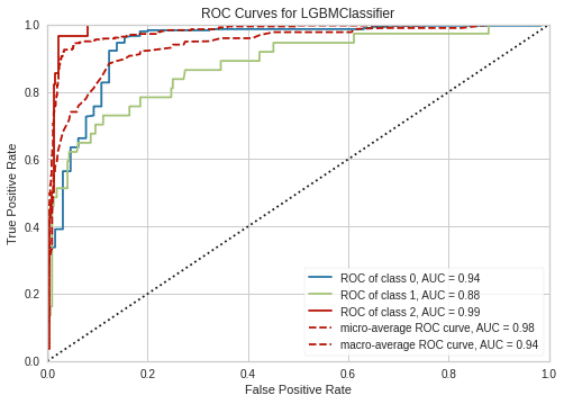
5-5.テストデータの推論
predict_modelにテストデータを渡してデータを推論します。また提出用CSVの形にするためid, labelだけ抽出してindex, headerは除去しました。
なお後々再現できなくなることを防止するためsave_model()でモデルを保存しておくことを推奨します。
[IN]
pred_ridge = predict_model(tuned_ridge, data=df_test)
df_output = pred_ridge[['id', 'Label']]
df_output.to_csv('220521_output_ridge.csv', header=False, index=False)
pred_logistic = predict_model(tuned_logistic, data=df_test) #Logistic Regression
df_output = pred_logistic[['id', 'Label']]
df_output.to_csv('220521_output_logistic.csv', header=False, index=False)
pred_lda = predict_model(tuned_lda, data=df_test) #Linear Discriminant Analysis
df_output = pred_lda[['id', 'Label']]
df_output.to_csv('220521_output_lda.csv', header=False, index=False)
pred_ramforest = predict_model(tuned_ramforest, data=df_test) #Ramdom Forest
df_output = pred_ramforest[['id', 'Label']]
df_output.to_csv('220521_output_ramforest.csv', header=False, index=False)
pred_lgbm = predict_model(tuned_lgbm, data=df_test) #Light GBM
df_output = pred_lgbm[['id', 'Label']]
df_output.to_csv('220521_output_lgbm.csv', header=False, index=False)
[OUT]
csv作成5-6.結果の提出
結果(CSVファイル)をCLIで投稿します。なおCLIを使用しなくてもコンペページから手動で投稿できます。
[IN]
!signate submit --competition-id=725 220521_output_ridge.csv --note PyCaretを使用したRidgeClassifierで投稿
!signate submit --competition-id=725 220521_output_logistic.csv --note PyCaretを使用したLogisticRegressionで投稿
!signate submit --competition-id=725 220521_output_lda.csv --note PyCaretを使用したLinearDiscriminantAnalysisで投稿
!signate submit --competition-id=725 220521_output_ramforest.csv --note PyCaretを使用したRamdoForestで投稿
!signate submit --competition-id=725 220521_output_lgbm.csv --note PyCaretを使用したLightGBMで投稿5-7.提出結果の確認
compere_models()では最高性能順に提出しましたが、実際のスコア(テストデータでの予想)は下記の通りです。参考までに今回の記事での最高スコアはLDAでの0.822でした。

6.CASE2:ハイパラ調整:評価指標を設定
前章ではPyCaretの簡易さも含めてシンプルに実行しましたが、さらなる性能向上を求めてハイパーパラメータの調整を検討しました。
※本当は5章モデルで実施すべきだったのですがsession_idを確認し忘れたため5章とは別の乱数値で計算(5章と比較できない)をしております。
6-1.前処理/学習・モデル比較
前処理および学習・モデル比較は前章と同じ内容で実行します。
[IN]
from pycaret.classification import * #分類
exp = setup(df_train,
ignore_features=['id'],
use_gpu = True,
# fix_imbalance = True, #偏りは小さいため不要
target = 'charges') #データの前処理
best = compare_models() #モデルの比較
print(best)
print(type(best))
[OUT]
LogisticRegression(C=1.0, class_weight=None, dual=False, fit_intercept=True,
intercept_scaling=1, l1_ratio=None, max_iter=1000,
multi_class='auto', n_jobs=None, penalty='l2',
random_state=4487, solver='lbfgs', tol=0.0001, verbose=0,
warm_start=False)
<class 'sklearn.linear_model._logistic.LogisticRegression'>
【備考】
●session_id = 4487 ※再現性確認用
●ランダム値が前回と変わったため最高性能モデルが変化
6-2.ハイパーパラメータ調整:指標追加
前回からの変更点は下記の通りです。
【変更点】
●ハイパラ調整時の評価資料をf1スコアに設定
●ハイパラ調整で調整前より性能が下がらないようにchoose_betterを設定
●参考用に調整時のアルゴリズムを確認できるようreturn_tuner=Trueを設定
[IN]
ridge = create_model('ridge') #Ridge Classifier
logistic = create_model('lr') #Logistic Regression
lda = create_model('lda') #Linear Discriminant Analysis
ramforest = create_model('rf') #Random Forest
lgbm = create_model('lightgbm') #Light GBM
#ハイパーパラメータ調整
#Ridge Classifier
tuned_ridge, tuner_ridge = tune_model(ridge,
optimize ='f1',
return_tuner=True,
choose_better = True)
#Logistic Regression
tuned_logistic, tuner_logistic = tune_model(logistic,
optimize ='f1',
return_tuner=True,
choose_better = True)
#Linear Discriminant Analysis
tuned_lda, tuner_lda = tune_model(lda,
optimize ='f1',
return_tuner=True,
choose_better = True)
#Random Forest
tuned_ramforest, tuner_ramforest = tune_model(ramforest,
optimize ='f1',
return_tuner=True,
choose_better = True)
#Light GBM
tuned_lgbm, tuner_lgbm = tune_model(lgbm,
optimize ='f1',
return_tuner=True,
choose_better = True)
[OUT]
各モデルの交差検証の結果が出力(下記は最後に処理したLightGBM)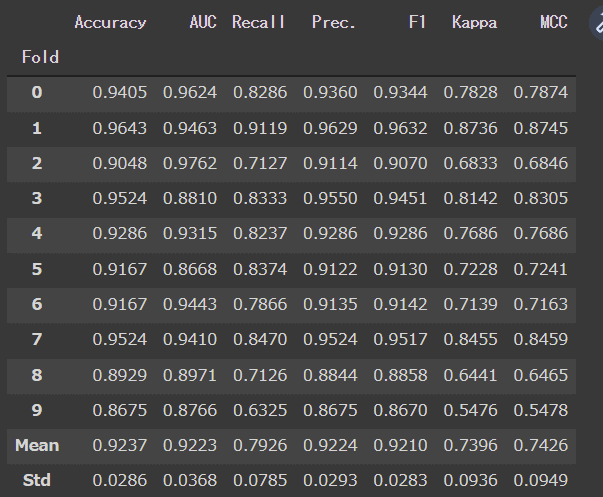
参考までに下記を実行することで各モデルでの最適化アルゴリズムを確認することができます。
[IN]
print('tuner_ridge',tuner_ridge)
print('tuner_logistic',tuner_logistic)
print('tuner_lda',tuner_lda)
print('tuner_ramforest',tuner_ramforest)
print('tuner_lgbm',tuner_lgbm)
[OUT]
長いので省略6-3.評価・可視化
評価および可視化します。
[IN1]
evaluate_model(tuned_ridge)
evaluate_model(tuned_logistic)
evaluate_model(tuned_lda)
evaluate_model(tuned_ramforest)
evaluate_model(tuned_lgbm)
[IN2]
# plot_model(tuned_ridge)
plot_model(tuned_logistic)
plot_model(tuned_lda)
plot_model(tuned_ramforest)
plot_model(tuned_lgbm)
[OUT]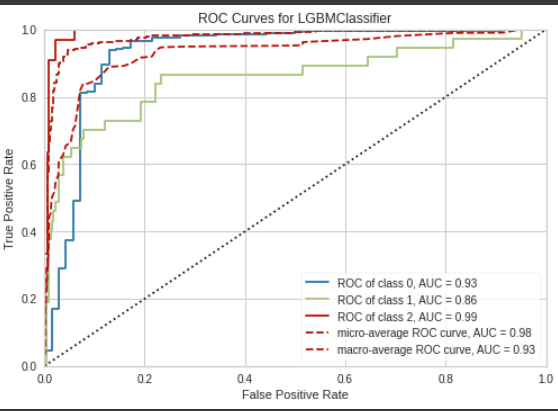
6-4.結果提出・評価の確認
結果を提出して評価を確認します。
[IN]
pred_ridge = predict_model(tuned_ridge, data=df_test)
df_output = pred_ridge[['id', 'Label']]
df_output.to_csv('220522_output_ridge_f1metric.csv', header=False, index=False)
pred_logistic = predict_model(tuned_logistic, data=df_test) #Logistic Regression
df_output = pred_logistic[['id', 'Label']]
df_output.to_csv('220522_output_logistic_f1metric.csv', header=False, index=False)
pred_lda = predict_model(tuned_lda, data=df_test) #Linear Discriminant Analysis
df_output = pred_lda[['id', 'Label']]
df_output.to_csv('220522_output_lda_f1metric.csv', header=False, index=False)
pred_ramforest = predict_model(tuned_ramforest, data=df_test) #Ramdom Forest
df_output = pred_ramforest[['id', 'Label']]
df_output.to_csv('220522_output_ramforest_f1metric.csv', header=False, index=False)
pred_lgbm = predict_model(tuned_lgbm, data=df_test) #Light GBM
df_output = pred_lgbm[['id', 'Label']]
df_output.to_csv('220522_output_lgbm_f1metric.csv', header=False, index=False)[IN ※提出したモデル評価中は提出できないため時間をおいて1個ずつ実施]
!signate submit --competition-id=725 220522_output_ridge_f1metric.csv --note PyCaretを使用したRidgeClassifierで投稿
# !signate submit --competition-id=725 220522_output_logistic_f1metric.csv --note PyCaretを使用したLogisticRegressionで投稿
# !signate submit --competition-id=725 220522_output_lda_f1metric.csv --note PyCaretを使用したLinearDiscriminantAnalysisで投稿
# !signate submit --competition-id=725 220522_output_ramforest_f1metric.csv --note PyCaretを使用したRamdoForestで投稿
# !signate submit --competition-id=725 220522_output_lgbm_f1metric.csv --note PyCaretを使用したLightGBMで投稿結果は下記の通りであり、性能更新とはいきませんでした。
【結果まとめ】
●Ridge、Logistic、LightGBMは性能が上昇したが、ldaとRandom Forestは性能が低下した。
●(前回のsession_idをメモってなかったため)、今回の結果がランダム値の影響が大きいか指標変化の影響が大きいか把握できなかった。
(正直指標評価のみで性能が上がると慢心してた)

6-5.モデルのPickle化+ファイル保存
後でハイパラを確認できるようにPickle化->ダウンロードしてファイルを保存します(Colab使用のため切断後にファイルが消えるため)。
[IN]
save_model(tuned_ridge, '220522_tuned_ridge_R1_f1metric')
save_model(tuned_logistic, '220522_tuned_logistic_R1_f1metric')
save_model(tuned_lda, '220522_tuned_lda_R1_f1metric')
save_model(tuned_ramforest, '220522_tuned_ramforest_R1_f1metric')
save_model(tuned_lgbm, '220522_tuned_lgbm_R1_f1metric')7.CASE3:アンサンブル
今度はアンサンブルを使用して調整しました。
7-1.前処理/学習・モデル比較
前処理および学習・モデル比較は前章と同じ内容で実行します。(同じ処理で確認不要のためsilent=True追加)
[IN]
from pycaret.classification import * #分類
exp = setup(df_train,
ignore_features=['id'],
use_gpu = True,
# fix_imbalance = True, #偏りは小さいため不要
silent=True,
target = 'charges') #データの前処理
best = compare_models() #モデルの比較
print(type(best))
print(best)
[OUT]
<class 'sklearn.linear_model._logistic.LogisticRegression'>
LogisticRegression(C=1.0, class_weight=None, dual=False, fit_intercept=True,
intercept_scaling=1, l1_ratio=None, max_iter=1000,
multi_class='auto', n_jobs=None, penalty='l2',
random_state=1220, solver='lbfgs', tol=0.0001, verbose=0,
warm_start=False)

7-2.アンサンブルモデルの作成
次にアンサンブルモデルを作成していきます。
[IN]
ridge = create_model('ridge') #Ridge Classifier
logistic = create_model('lr') #Logistic Regression
lda = create_model('lda') #Linear Discriminant Analysis
ramforest = create_model('rf') #Random Forest
lgbm = create_model('lightgbm') #Light GBM
blender1 = blend_models([logistic, ridge, lda, ramforest, lgbm])
blender1_weight = blend_models([logistic, ridge, lda, ramforest, lgbm],
weights=[0.2, 0.2, 0.2, 0.2, 0.2],
choose_better=True)
blender2 = blend_models([logistic, ridge, lda])
blender2_weight = blend_models([logistic, ridge, lda],
weights=[0.4, 0.3, 0.3],
choose_better=True)
tuned_blender1 = tune_model(blender1_weight)
tuned_blender2 = tune_model(blender2_weight)
print(blender1, tuned_blender1, blender2, tuned_blender2)
[OUT ※一部省略]
#tuned_blender1
VotingClassifier(estimators=[('lr',
LogisticRegression(C=1.0, class_weight=None,
dual=False, fit_intercept=True,
intercept_scaling=1,
l1_ratio=None, max_iter=1000,
multi_class='auto',
n_jobs=None, penalty='l2',
random_state=1220,
solver='lbfgs', tol=0.0001,
verbose=0, warm_start=False)),
('ridge',
RidgeClassifier(alpha=1.0, class_weight=None,
copy_X=True, fit_intercep...
learning_rate=0.1, max_depth=-1,
min_child_samples=20,
min_child_weight=0.001,
min_split_gain=0.0,
n_estimators=100, n_jobs=-1,
num_leaves=31, objective=None,
random_state=1220, reg_alpha=0.0,
reg_lambda=0.0, silent='warn',
subsample=1.0,
subsample_for_bin=200000,
subsample_freq=0))],
flatten_transform=True, n_jobs=1, verbose=False, voting='hard',
weights=[0.34, 0.6, 0.16, 0.099, 0.99])
#tuned_blender2
LogisticRegression(C=4.53, class_weight={}, dual=False, fit_intercept=True,
intercept_scaling=1, l1_ratio=None, max_iter=1000,
multi_class='auto', n_jobs=None, penalty='l2',
random_state=1220, solver='lbfgs', tol=0.0001, verbose=0,
warm_start=False)7-3.評価・可視化
評価および可視化します。
[IN]
省略7-4.結果提出・評価の確認
結果を提出して評価を確認します。こちらは前章と同じため省略します。
8.CaseX:その他対応事項
性能を上げるために下記を実施しましたが、結果として乱数値がたまたまベストだった5章の結果を超えることが出来ませんでした。
【結果まとめ】
1.シンプルな処理での精度確認
ー>ランダム値(データセットの分割、モデルの初期値など)は最終精度に大きな影響を与えた(※setup()は乱数を使用するため乱数を固定しないと毎回結果が異なる)
ー>検証時の各モデル精度と、実際のテストデータでの精度を比較すると順位がバラバラだった(1つのモデルに粘着するのもよくない)。
ー>fix_imbalance=True を使用した結果は、
2.評価指標をAccuracy->f1scoreに変更
ー>ランダム値の差を埋めることが出来るほどの影響はなかった
3.アンサンブルの効果確認
ー>アンサンブルする場合、各モデルは事前にハイパラ調整は必須
ー>アンサンブルの加重平均は思った以上の効果は得られなかった
4.スタッキングの効果確認
ー>アンサンブルとほぼ同じでありrestackの影響もほぼなし
【前処理編(参考記事)】
下記を個別実装しても今回のモデル(LDA, LightGBM)では性能向上がなかった
1.交互作用特徴量をsklearnで実装
2.標準化(normalize=True)
3.外れ値除去(remove_outliers=True)
4.Childrenをカテゴリカル->数値データ(numeric_features=['children'])
5.学習用データを75:25、80:25で試験※少し効果あり
6.データ分割時のラベルの割合を調整(fix_imbalance = True)
【ハイパーパラメータ調整】
1.学習をoptunaやscikit-optimizeを使用※性能向上なし
[IN ※前処理参考]
from pycaret.classification import * #分類
exp = setup(df_train,
ignore_features=['id'],
use_gpu = True,
session_id = 1220, #乱数値固定
fix_imbalance = True, #偏りは小さいため不要
silent=True,
train_size=0.75, #defalut=0.7
numeric_features=['children'],
remove_outliers=True, #外れ値除去
normalize=True, #標準化
log_experiment = True,
target = 'charges') #データの前処理
[OUT][IN ※交互作用特徴量の実装]
from sklearn.preprocessing import PolynomialFeatures
def get_poly(df, cols, degree=2):
poly = PolynomialFeatures(degree=degree, include_bias=False)
poly_df = poly.fit_transform(df[cols])
cols_poly = [cols[0], cols[1], cols[2], cols[0]+'^2', cols[0]+'*'+cols[1], cols[0]+'*'+cols[2], cols[1]+'^2', cols[1]+'*'+cols[2], cols[2]+'^2']
return pd.DataFrame(poly_df, columns=cols_poly)
_df_train = get_poly(df_train, ['age', 'bmi', 'children'])
_df_test = get_poly(df_test, ['age', 'bmi', 'children'])
df_train = pd.concat([_df_train, df_train.drop(columns=['age', 'bmi', 'children'])], axis=1)
df_test = pd.concat([_df_test, df_test.drop(columns=['age', 'bmi', 'children'])], axis=1)
#データの中身確認
display_dfs( {'df_train': df_train.describe(),
'df_test': df_test.describe()}
, justify='flex-start')
display_dfs( {'欠損値_train':pd.DataFrame(df_train.isnull().sum()),
'欠損値_test': pd.DataFrame(df_test.isnull().sum())}
, justify='flex-start')
df_train['charges'].value_counts() #ラベルデータの偏り確認
[OUT]
9.最終結果
下記の通り最高スコア=0.822でありLDAのハマり方が良かったです。アンサンブルでスコアが上がることを期待したのですがLDA単独の方が性能が良かったため結果はいまいちでした。

10.反省
今回のコンペでの反省点は「再現性をとれるよう取得データのログはとりましょう」です。(まさか適当にやったモデルの結果より性能が出なくなることを想定していなかったため)
参考資料
あとがき
とりあえずPyCaretの凄さはわかったけど、まだまだ惜しいところが多い。
【PyCaretの改善点 ※実際はできるかもしれないので探索中】
●まず公式DocumentのAPIが探しにくい
●setup後のexpがTupleのためほしいデータが取れない(普通は辞書)。
●複数モデルを処理したときに前のデータが残らない(tuned_modelの交差検証の結果など)ため、ほしいデータをまとめて確認しにくい。
●モデル事のプロット比較もできない。