
Pythonライブラリ(OCR):talula-py, pdfminer, donuts

0.概要
今回はOCR(PDFや画像データの文字認識)用ライブラリを紹介します。OCR用のサンプルデータは下記の通りです。
【OCRライブラリ】
●tabula-py:テーブルデータをPDFから取得->DataFrame型で出力
●pdfminer.six:PDFMinerとpdfminer.sixがあるが後者の方
●PyPDF2:日本語のテキスト抽出ができず開発も中断(参考)
【サンプル1:PDFelement(明細あり・ヨコ型の領収書) p1】

【サンプル2:機械学習品質マネジメントガイドライン 第2版 p207】
1.OCRライブラリ1:tabula-py
PDFのテーブルデータを読み取ることが出来ます。使用環境は「Java 8+、Python 3.7+、macOS」ですがWindows10でも動作可能です。
[Terminal]
pip install tabula-py【エラー発生時用の参考資料】
1-1.シンプル手法:tabula.read_pdf()
シンプルな読み込みはtabula.read_pdf(filepath, pages='all')とします。またfilepathにurlを指定すればweb経由で取得も可能です。
下記の通り戻り値はリスト形式で取得でき、リスト内のデータはDataFrame型となります。
[In]
import tabula
import pandas as pd
#URLでデータ取得->ファイル読み込み
# url = 'https://pdf.wondershare.jp/images/templates/pdf-templates/receipt-item-horizontal.pdf'
# dfs = tabula.read_pdf(url, pages='all') #PDFを読み込む
#ローカルファイルデータから読み込み
path = 'receipt-item-horizontal.pdf'
dfs = tabula.read_pdf(path, pages='all') #PDFを読み込む
print(len(dfs), type(dfs), type(dfs[0]))
dfs[Out]
4 <class 'list'> <class 'pandas.core.frame.DataFrame'>
[ 東京都千代田区●●町1-2-3 Unnamed: 0 領収書No 1234567890
0 秋葉原●●●ビル 領 収 書 発行日 2017/06/15,
Empty DataFrame
Columns: [品 名, 数量, 単位, 単価, 金 額, 摘 要, 備 考]
Index: [],
○○○○○○ 2 個 4,567 6,500 ○○○ Unnamed: 0
0 ○○○○○○ 2.0 セット 1,234 3,200 NaN NaN
1 NaN NaN NaN NaN NaN 小 計 9,700
2 NaN NaN NaN NaN NaN 税率 8%
3 NaN NaN NaN NaN NaN 消費税 776
4 NaN NaN NaN NaN NaN 合 計 10,476,
小 計 9,700
0 税率 8%
1 消費税 776
2 合 計 10,476]中身はリストのデータ抽出と同じためdfs[0]などで取得できます。
[In]
for df in dfs:
display(df)[Out]
東京都千代田区●●町1-2-3 Unnamed: 0 領収書No 1234567890
0 秋葉原●●●ビル 領 収 書 発行日 2017/06/15
品 名 数量 単位 単価 金 額 摘 要 備 考
○○○○○○ 2 個 4,567 6,500 ○○○ Unnamed: 0
0 ○○○○○○ 2.0 セット 1,234 3,200 NaN NaN
1 NaN NaN NaN NaN NaN 小 計 9,700
2 NaN NaN NaN NaN NaN 税率 8%
3 NaN NaN NaN NaN NaN 消費税 776
4 NaN NaN NaN NaN NaN 合 計 10,476
小 計 9,700
0 税率 8%
1 消費税 776
2 合 計 10,476
1-2.読み取り方法指定:stream/lattice
引数にPDFの読み取り方法を設定することが出来ます。読み取りが不十分だった場合にTrueに変更すると必要な値を抽出できることもあります。
下記ではlatticeでデータ抽出量が増えましたが余計なデータも増えてます。
●stream:格子がない表を自動補完
●lattice:格子がある表を自動補完
【streamで実施】
[In]
import tabula
path = 'receipt-item-horizontal.pdf'
dfs = tabula.read_pdf(path, pages='all', stream=True) #stream:格子がない表を自動補完, lattice:格子がある表を自動補完
print(len(dfs))
dfs
[Out]
4
stream=False(デフォルト値)と変化なし【latticeで実施】
[In]
import tabula
path = 'receipt-item-horizontal.pdf'
dfs = tabula.read_pdf(path, pages='all', lattice=True) #stream:格子がない表を自動補完, lattice:格子がある表を自動補完
print(len(dfs))
dfs[Out]
11

1-3.指定ページの抽出:pages
計207pageあるサンプル2からp205とp207のデータを抽出します。記法はリスト・文字列型で記載可能です。
[In]
import tabula
url = 'https://www.digiarc.aist.go.jp/publication/aiqm/AIQM-Guideline-2.1.0.pdf' #ファイルのリンク
dfs = tabula.read_pdf(url, pages=[205, 207]) #PDFを読み込む
print(len(dfs), type(dfs), type(dfs[0]))
for df in dfs:
display(df)
[Out]
2
※dfの中身は下図(参考までにPDFの中身も表示)

2.OCRライブラリ2:pdfminer.six
こちらは一般的なOCRで出力も文字列型となります。
[Terminal]
pip install pdfminer.six2-1.シンプル手法:extract_text(path)
シンプルな使用方法としては下記の通りfilepathを渡すだけで処理できます。それなりに精度高く文字認識できました。
ただし実用的に使う場合は文字列操作・正規表現などで指定箇所の値を抽出できるスキルは必要です。
[In]
from pdfminer.high_level import extract_text
path = 'receipt-item-horizontal.pdf'
text = extract_text(path)
print(type(text))
print(text.replace('\n\n', '\n')) #改行を消す[Out]
<class 'str'>
〒123-4567
東京都千代田区●●町1-2-3
株式会社○○○○○商会御中
秋葉原●●●ビル
領 収 書
領収書№
1234567890
発⾏⽇
2017/06/15
印
収
紙
入
下記、正に領収いたしました。
株式会社●●●●
合計⾦額
¥10,476
〒123-4567
東京都千代田区○○町1-2-3
秋葉原○○○ビル○○階
TEL : 09-8765-4321 FAX : 09-8765-4321
品 名
数量 単位
単価
⾦ 額
摘 要
備 考
○○○○○○
○○○○○○
2
個
2 セット
4,567
1,234
6,500
3,200
○○○
小 計
9,700
税率
消費税
8%
776
合 計
10,476
㊞
3.donut
2022年8月に公開されたtransformerを使用した最新モデルであり、請求書のOCRなどに利用できます。結論として「日本語のものに使用する場合はFine Tuningが必要だが、英語なら高精度」です。
公式が紹介しているモデル概要およびデモ風景は下図の通りです。

3-1.Webデモ
モデルのデモをWebで公開しているため公式サンプル画像を使用してデモを実施しました。

結果として十分な読み取り精度、かつJSON形式で出力を返してくれました。JSONを解析しないといけないですが、簡単に情報抽出ができます。
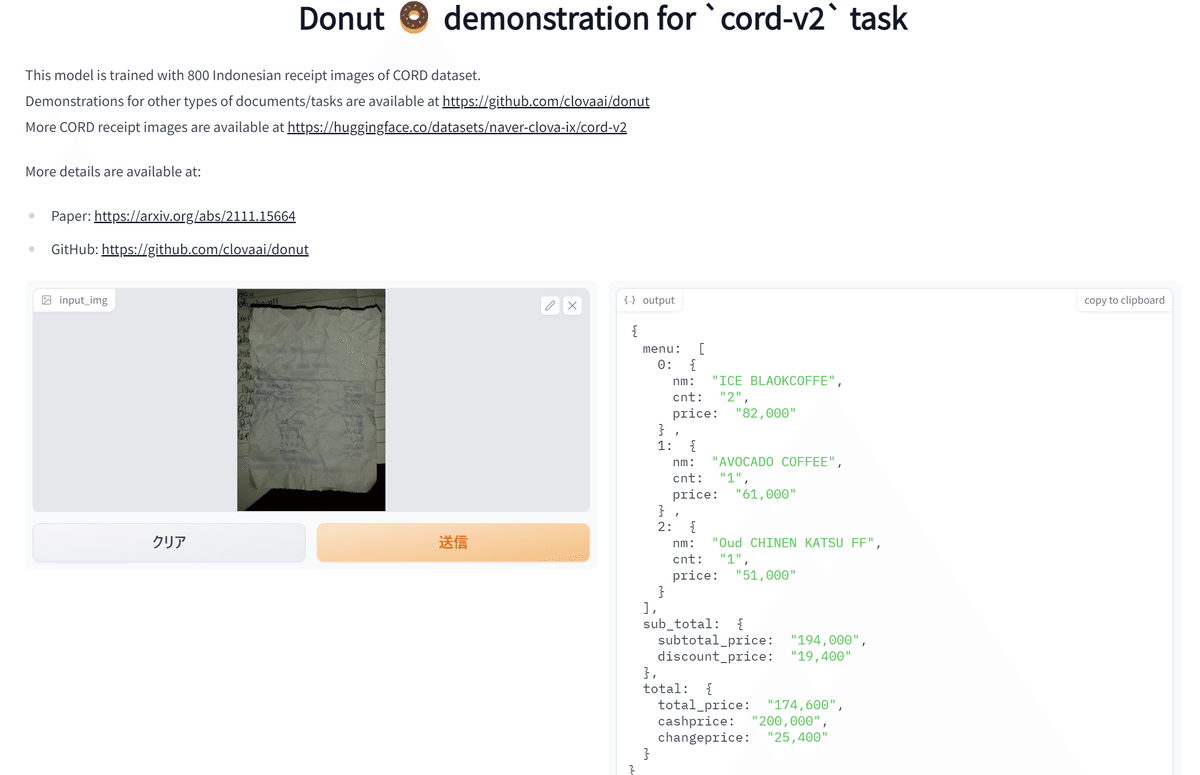
3-2.英語版サンプル
Webのデモをコードで実行します。公式Docsでは環境構築は仮想環境を使用しており煩雑なためGoogle Colabを使用しました。また、公式Docsだけだと理解できなかったためコードは下記記事を参照しました。
Webデモと同じ結果が出力されており、JSONの中身は下記の通りです。
【outputのJSON】
●nm(name):名称
●cnt(count):数量
●price:数値・価格
[IN]
!git clone https://github.com/clovaai/donut.git
%cd donut
!pwd
!pip install .
from donut import DonutModel
from PIL import Image
import torch
model = DonutModel.from_pretrained("naver-clova-ix/donut-base-finetuned-cord-v2")
if torch.cuda.is_available():
model.half()
device = torch.device("cuda")
model.to(device)
else:
model.encoder.to(torch.bfloat16)
model.eval()
image = Image.open("/content/1_sksoYvZkCpu4wuLKK81iMA.png").convert("RGB")
output = model.inference(image=image, prompt="<s_cord-v2>")
print(output)
[OUT]
{'predictions': [{'menu': [{'nm': 'ICE BLAOKCOFFE',
'cnt': '2',
'price': '82,000'},
{'nm': 'AVOCADO COFFEE', 'cnt': '1', 'price': '61,000'},
{'nm': 'Oud CHINEN KATSU FF', 'cnt': '1', 'price': '51,000'}],
'sub_total': {'subtotal_price': '194,000', 'discount_price': '19,400'},
'total': {'total_price': '174,600',
'cashprice': '200,000',
'changeprice': '25,400'}}]}[IN_outputをさらに解析]
for datas in output['predictions']:
for key, value in datas.items():
print(key, value)
[OUT]
menu [{'nm': 'ICE BLAOKCOFFE', 'cnt': '2', 'price': '82,000'}, {'nm': 'AVOCADO COFFEE', 'cnt': '1', 'price': '61,000'}, {'nm': 'Oud CHINEN KATSU FF', 'cnt': '1', 'price': '51,000'}]
sub_total {'subtotal_price': '194,000', 'discount_price': '19,400'}
total {'total_price': '174,600', 'cashprice': '200,000', 'changeprice': '25,400'}3-3.日本語版サンプル
それでは日本語版のサンプルで同じ動作を確認しました。サンプルは下記2サンプル(左:sample1, 右:sample2)を使用しました。

[IN]
from donut import DonutModel
from PIL import Image
import torch
model = DonutModel.from_pretrained("naver-clova-ix/donut-base-finetuned-cord-v2")
if torch.cuda.is_available():
model.half()
device = torch.device("cuda")
model.to(device)
else:
model.encoder.to(torch.bfloat16)
model.eval()
image1 = Image.open("/content/sample1.png").convert("RGB")
image2 = Image.open("/content/sample2.jpeg").convert("RGB")
output1 = model.inference(image=image1, prompt="<s_cord-v2>")
output2 = model.inference(image=image2, prompt="<s_cord-v2>")
print(output1)
print(output2)
[OUT]
{'predictions': [{'menu': [{'nm': '2013 12 05', 'unitprice': 'T000', 'cnt': '3', 'price': '12 05'}, {'cnt': '3', 'price': '1'}], 'sub_total': {'subtotal_price': '100,000', 'tax_price': '5,000'}, 'total': {'total_price': '105,000', 'total_etc': '5,000', 'changeprice': '( )', 'menuqty_cnt': '1'}}]}
{'predictions': [[{'nm': 'MRC M - M + CE ON C', 'unitprice': '10: 10: 10: 10: 10: 10: 10: 10 ingredientes', 'cnt': '7', 'price': '8', 'sub': {'nm': '(*) 12:34', 'num': '2011年11月118', 'unitprice': '123', 'cnt': '4', 'price': '4'}}, {'nm': '1100 大槻 *123', 'num': '1100', 'unitprice': '*321', 'cnt': '1', 'price': '1'}, {'unitprice': '345', 'cnt': '3', 'price': '200'}, {'unitprice': '-*50', 'cnt': '1', 'price': '1185', 'menuqty_cnt': '6.8.'}]]}結果の通り日本語のOCR機能が付いていないため読み違いが発生しております。また右図のレシートではJSONの構造が1層深くなっておりました。
[IN]
#sample1の結果(左図)
for datas in output1['predictions']:
for key, value in datas.items():
print(key, value)
#sample2の結果(右図)
for _datas in output2['predictions']:
for datas in _datas:
for key, value in datas.items():
print(key, value)
[OUT]
#output1
menu [{'nm': '2013 12 05', 'unitprice': 'T000', 'cnt': '3', 'price': '12 05'}, {'cnt': '3', 'price': '1'}]
sub_total {'subtotal_price': '100,000', 'tax_price': '5,000'}
total {'total_price': '105,000', 'total_etc': '5,000', 'changeprice': '( )', 'menuqty_cnt': '1'}
#output2
nm MRC M - M + CE ON C
unitprice 10: 10: 10: 10: 10: 10: 10: 10 ingredientes
cnt 7
price 8
sub {'nm': '(*) 12:34', 'num': '2011年11月118', 'unitprice': '123', 'cnt': '4', 'price': '4'}
nm 1100 大槻 *123
num 1100
unitprice *321
cnt 1
price 1
unitprice 345
cnt 3
price 200
unitprice -*50
cnt 1
price 1185
menuqty_cnt 6.8.あとがき
軽くOCR使いたい場面が出たのでとりあえず記載。ほしいタイミングで追記していきます。
AI-OCRとか最近流行ってるけどOCR単体の需要ってそんなにあるものなのかな?
Donutsのようなものが精度上がると事務作業の効率化がすごいことになるね。