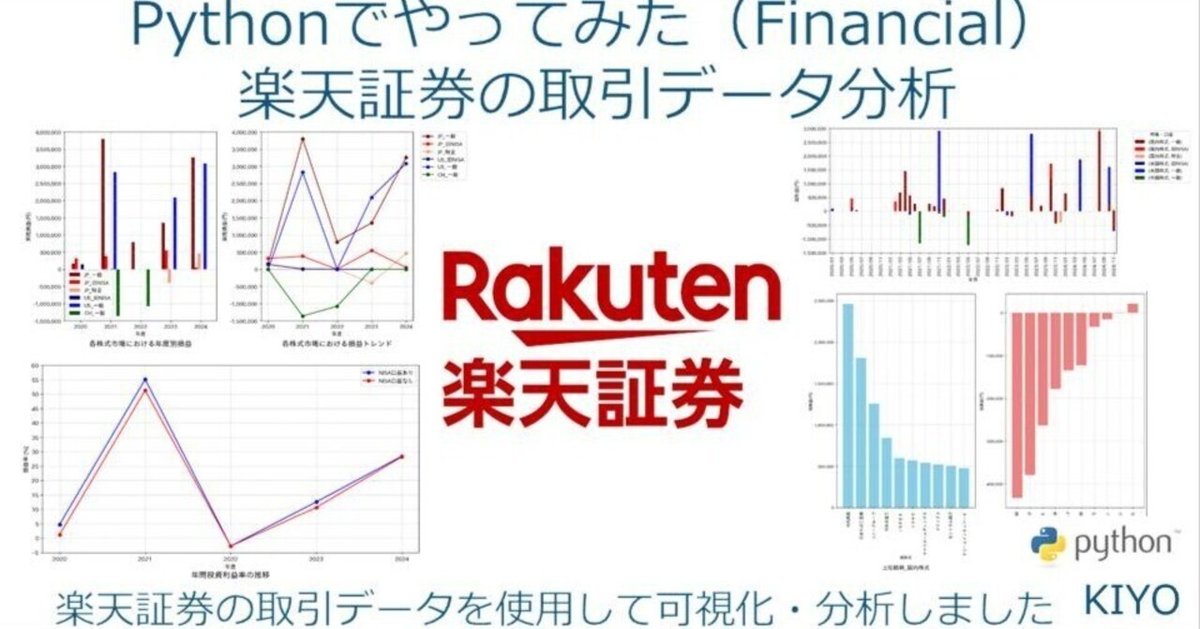
Pythonでやってみた(Finance)2:楽天証券の取引データ分析

1.概要
本記事では楽天証券の取引データを可視化し、投資分析に活かしていきたいと思います。
2.楽天証券の紹介
今まで株式投資では楽天証券を使い続けてきたため、簡単な紹介だけさせていただきます。なお、個人的な意見として他証券会社は下記理由で使ったことがあります。
2-1.資産管理が容易
入出金も含めた総資産(今持っているお金)の把握が容易です。
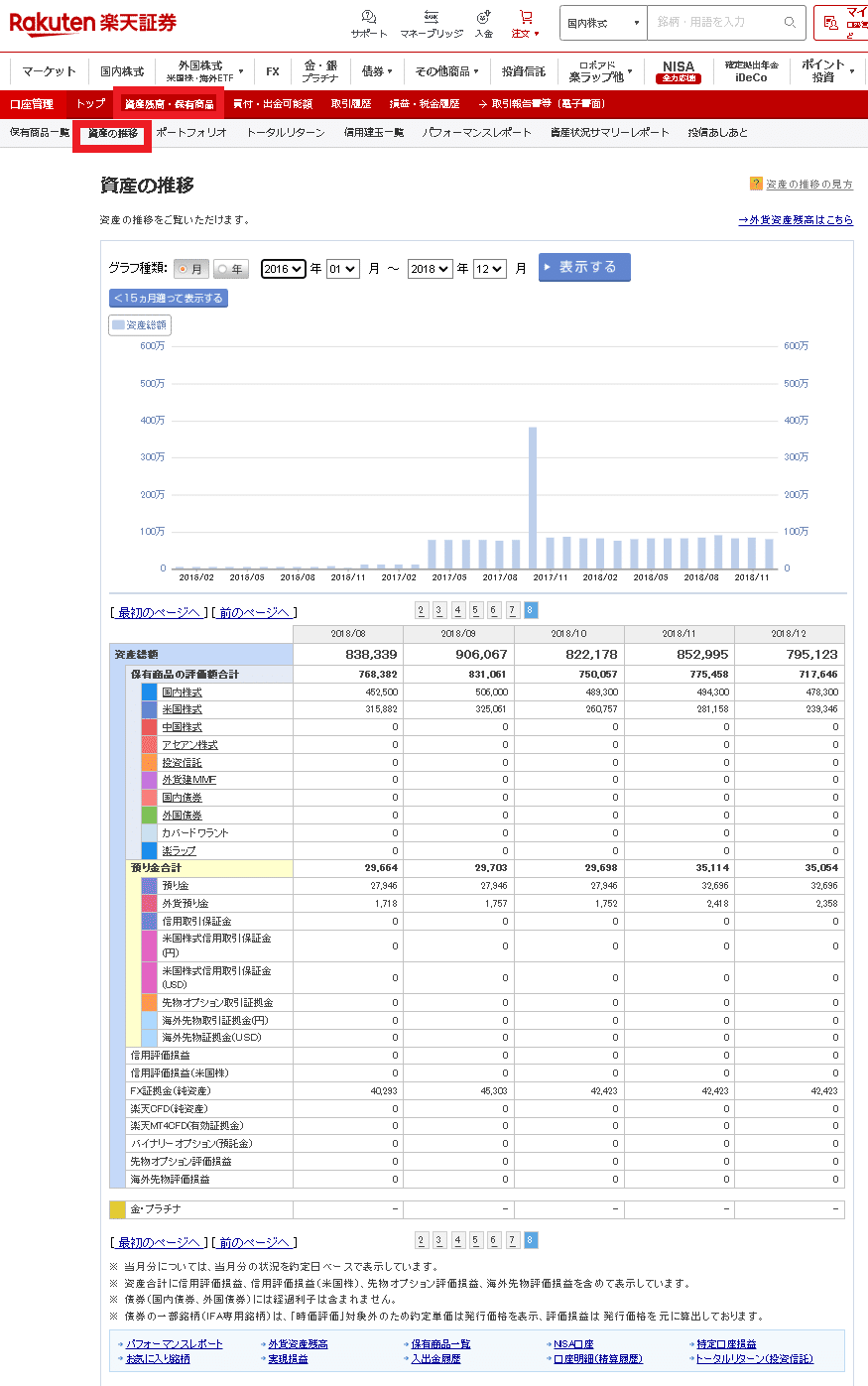
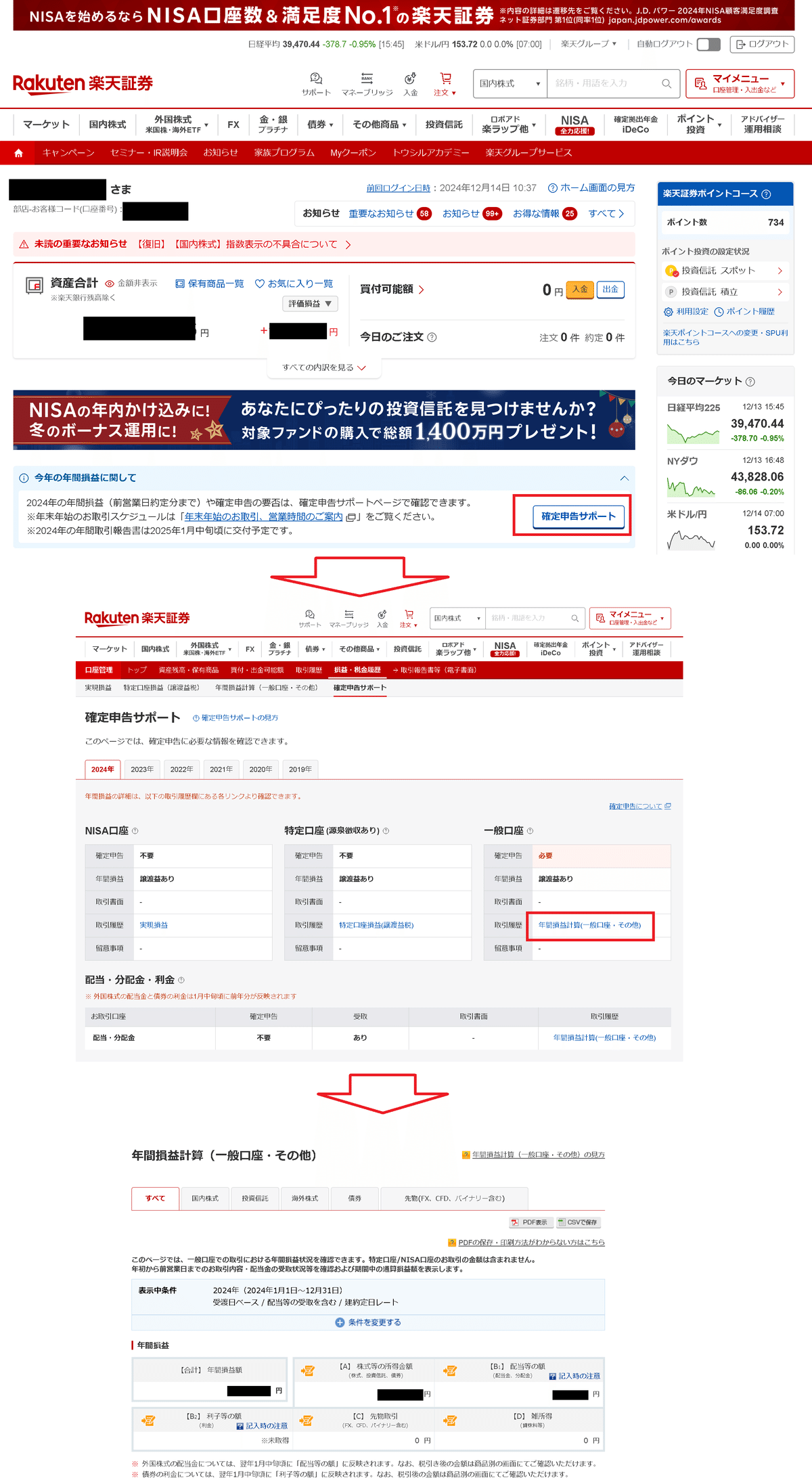
2-2.確定申告が楽
一般口座で投資をしている人は確定申告が必要となります(赤字でも譲渡損失による繰り越し可能)。
その場合、NISA口座や特定口座と分離された一般口座だけの損益が必要であり、楽天証券は非常に見やすい結果を出してくれます。
2-3.海外株式
海外株式は国内株式よりボラティリティ(株価の増減幅)が大きく、リスクとともに可能性のある株式市場です。
特に米国株式は日本人でも有名な企業が多く、かつそのような企業の株価が数倍にも上昇するため期待値の高い株式市場です。
逆にリスクもあり下げ幅も大きくなるため、(1年前くらいから購入検討していた会社の)株価が数分の1になる可能性もあります。
楽天証券では(会社がある程度スクリーニングしたうえで)米国や中国株の購入が可能です。
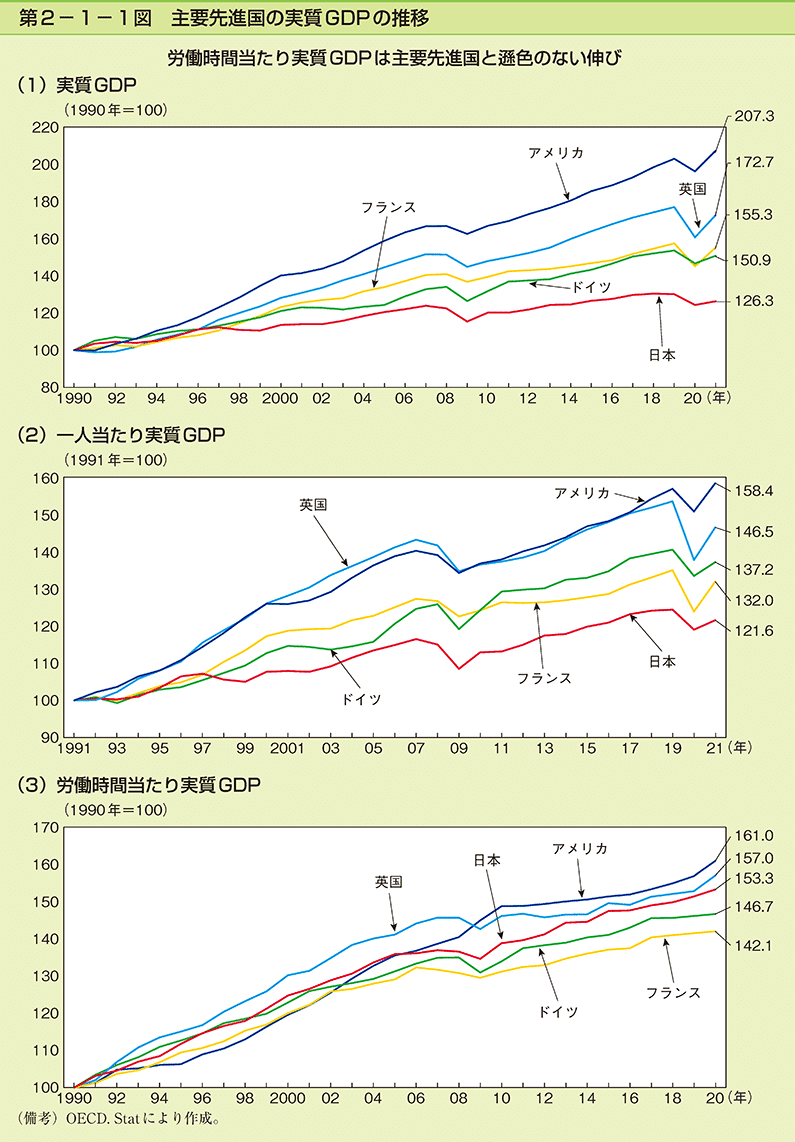
【参考:各国のGDPの推移】
日本と比較して各国のGPDは増加傾向です。つまり企業が儲けているので株価も上昇する傾向あるため、海外株式は一つの選択肢として持っておくのは重要と考えます。
3.設計思想
楽天証券内でも多くの情報が可視化されています。
年間損益計算(一般口座・その他)
国内株式と海外株式などの合計と個別ともに表示可
特定口座損益(譲渡益税)
資産の推移:楽天証券内の投資金額の時系列データ
よって、自分が見たい他にないデータを可視化していこうと思います。詳細としては下記の通りです。
NISA口座も含めた損益
年間損益計算は確定申告に必要な損益しかでないため
年度、月ごとの損益の推移
売買銘柄ごとの利益総額
どの銘柄に投資して儲けたかを確認
4.事前準備(データ取得)
それでは楽天証券から使用するデータを取得します。
4-1.実現損益のCSVデータ
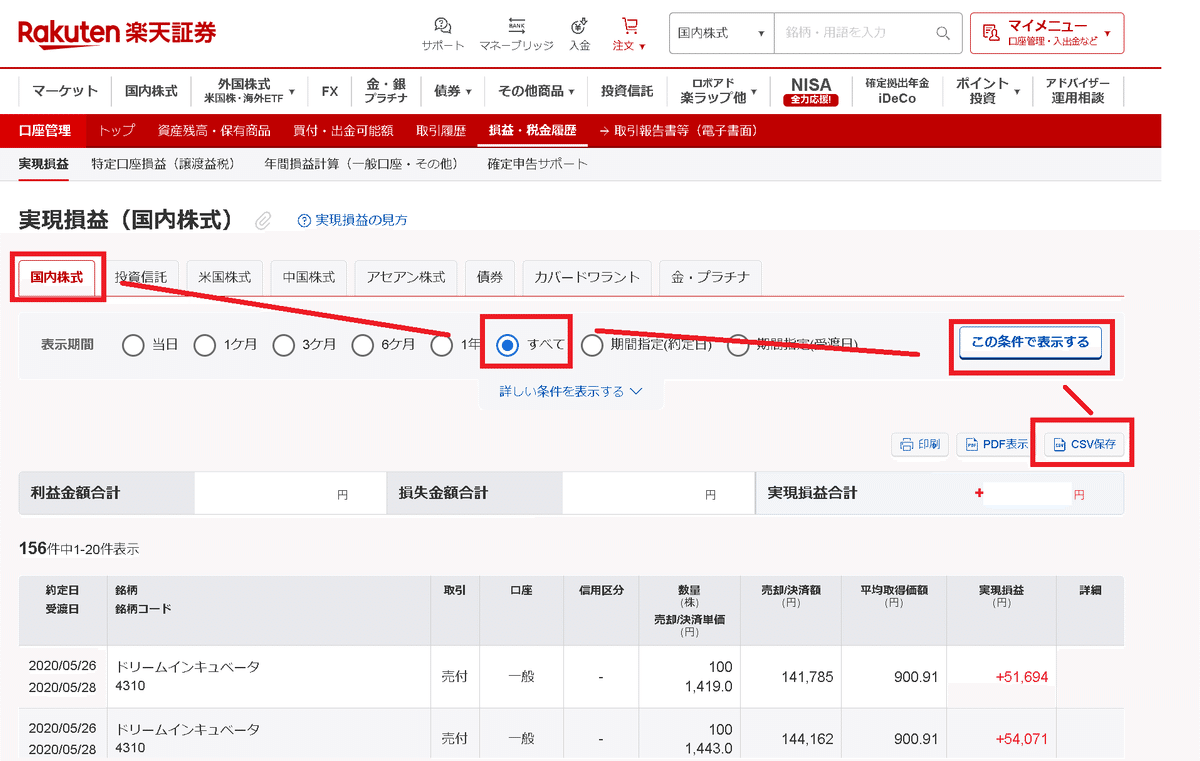
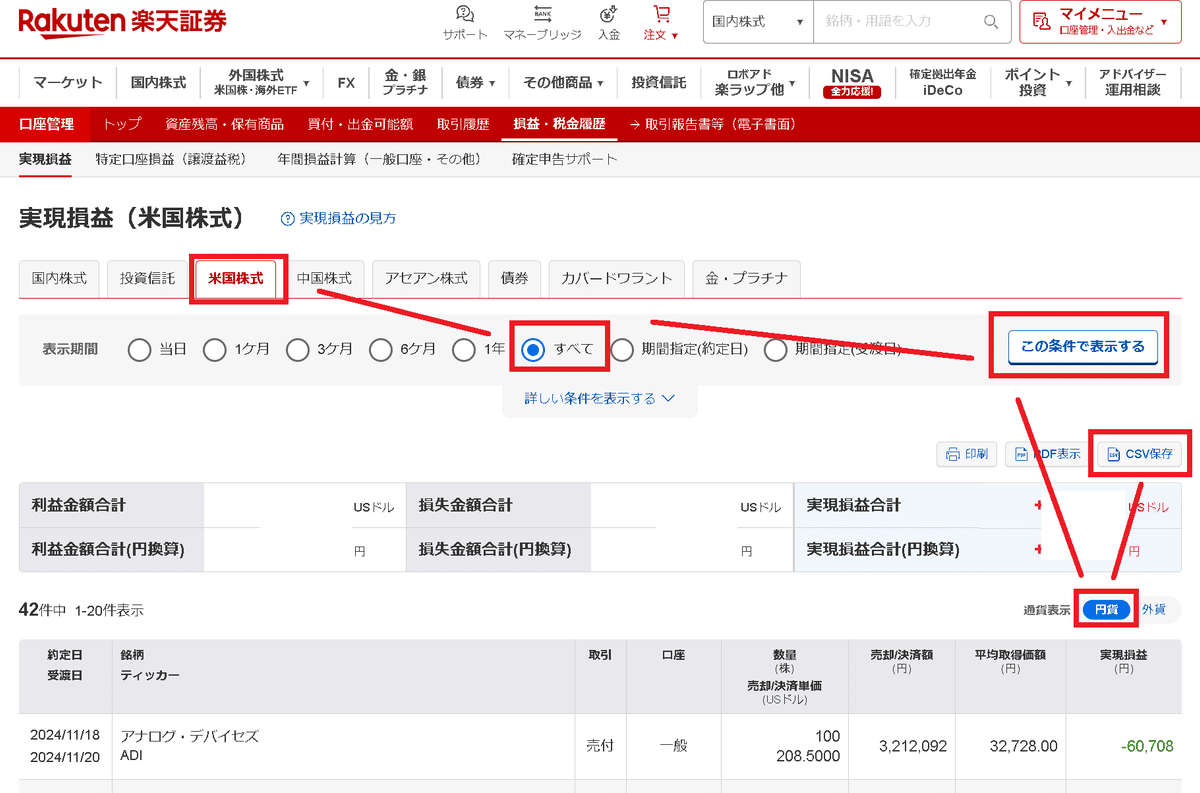
まずは「マイメニュー/実現損益」を選択します。
次に見たい市場(私は国内株式、米国株式、中国株式の3つ)を選択し、「すべて/この条件で表示する/CSV保存※」を選択します。
※米国株式はCSV保存の前に”通貨表示:円貨”を選択
取得したCSVをPythonファイルと同じディレクトリに保存します。これで準備は完了です。
4-2.資産データの作成
次に”損益率”計算のために資産の推移※を取得します。
(※入金データも含まれるためピュアな投資結果ではないことに注意)
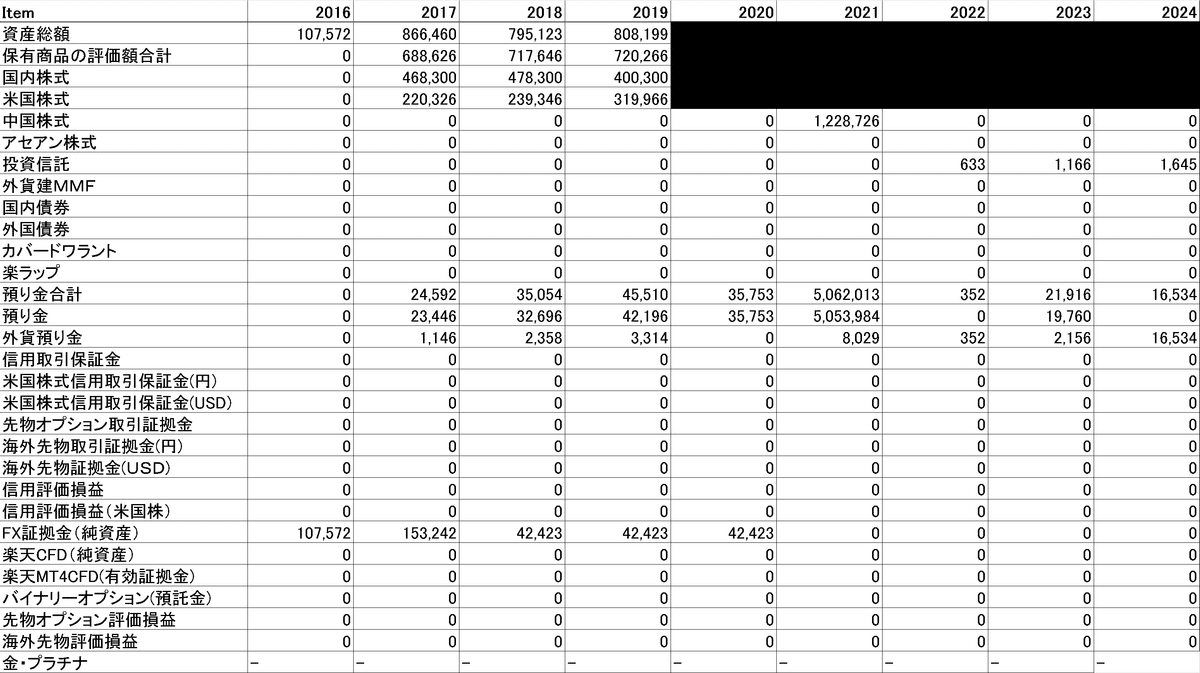
資産データはCSVでは取得できないため手打ちで作成しました。
まずは「マイメニュー/資産の推移」を選択します。
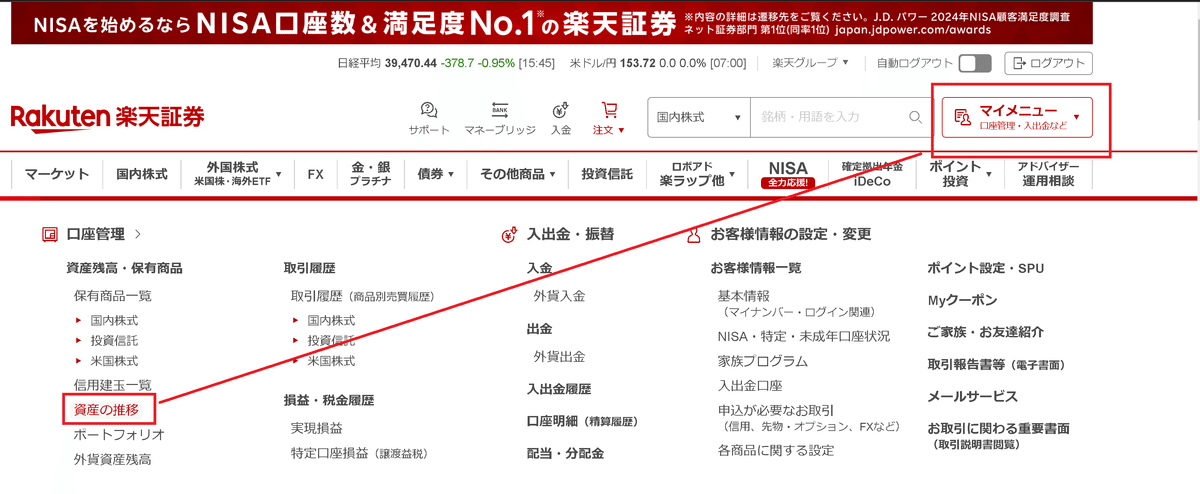
次にグラフの種類で”年”を選択し、投資開始年を選択して表示するボタンを押します。結果として資産表が表示されます。
PandasのDataFrameで取り扱えるようにExcelに下表の形で手入力しました。ファイル名は”assets_rakuten.xlsx”にしました。
5.Pythonスクリプト
5-1.前処理
スクリプトの内容は下記の通りです。
ライブラリインポート及び可視化用クラスの作成
作成したクラスは”Notebookに複数のDataFrameを(水平に)出力”参照
資産データをDataFrame型で読み込み
4章でDLしたCSVファイルをDataFrame型で読み込み
DataFrameを加工・計算できるように前処理
数値がStringのためカンマを削除し数値に変換
グループ化するために”年”と”年月”のカラムを追加
[IN]
import pandas as pd
import numpy as np
import os, glob, datetime, re, time, itertools, json, logging, gc
import matplotlib.pyplot as plt
import matplotlib.patches as mpatches
from matplotlib.ticker import StrMethodFormatter
import japanize_matplotlib
import seaborn as sns
class HorizontalDisplay:
def __init__(self, *args):
self.args = args
def _repr_html_(self):
template = '<div style="float: left; padding: 10px;">{}</div>'
return "\n".join(template.format(arg._repr_html_()) for arg in self.args)
#資産データ取得
path_assets = 'assets_rakuten.xlsx'
df_assets = pd.read_excel(path_assets, index_col=0)
display(df_assets)
#CSVファイルのパスを取得
paths_JP = glob.glob('*(JP)*.csv') #国内株式
paths_US = glob.glob('*(US)*.csv') #米国株式
paths_CH = glob.glob('*(CH)*.csv') #中国株式
path_JP, path_US, path_CH = paths_JP[0], paths_US[0], paths_CH[0] #最初のファイルを読み込む
#データフレームに読込※日本語の文字コードはshift-jis
_df_JP, _df_US, _df_CH = pd.read_csv(path_JP, encoding='shift-jis'), pd.read_csv(path_US, encoding='shift-jis'), pd.read_csv(path_CH, encoding='shift-jis')
#DataFrameを計算できるよう修正
def clean_df(df, columns_numeric:list):
#テキストデータを数値に変換
for c in columns_numeric:
if df[c].dtype == 'O':
df[c] = df[c].str.replace(',', '')
df[c] = pd.to_numeric(df[c], errors='coerce') #エラーがあればNaNに変換
#日付データをdatetimeに変換し、年度を追加
df['約定日'] = pd.to_datetime(df['約定日'], format='%Y/%m/%d')
df['年'] = df['約定日'].dt.year
df['年月'] = df['約定日'].dt.strftime('%Y/%m')
return df
#前処理+ピボットテーブル作成
columns_numeric_JP = ['数量[株]', '売却/決済単価[円]', '売却/決済額[円]', '平均取得価額[円]', '実現損益[円]'] #数値データのカラム(日本株)
columns_numeric_US = ['数量[株]', '売却/決済単価[USドル]', '売却/決済額[円]', '平均取得価額[円]', '実現損益[円]'] #数値データのカラム(米国株)
columns_numeric_CH = ['数量[株]', '売却単価[HKドル]', '売却額[円]', '平均取得価額[円]', '実現損益[円]'] #数値データのカラム(中国株)
df_JP = clean_df(_df_JP, columns_numeric_JP)
df_US = clean_df(_df_US, columns_numeric_US)
df_CH = clean_df(_df_CH, columns_numeric_CH)
df_JP.head()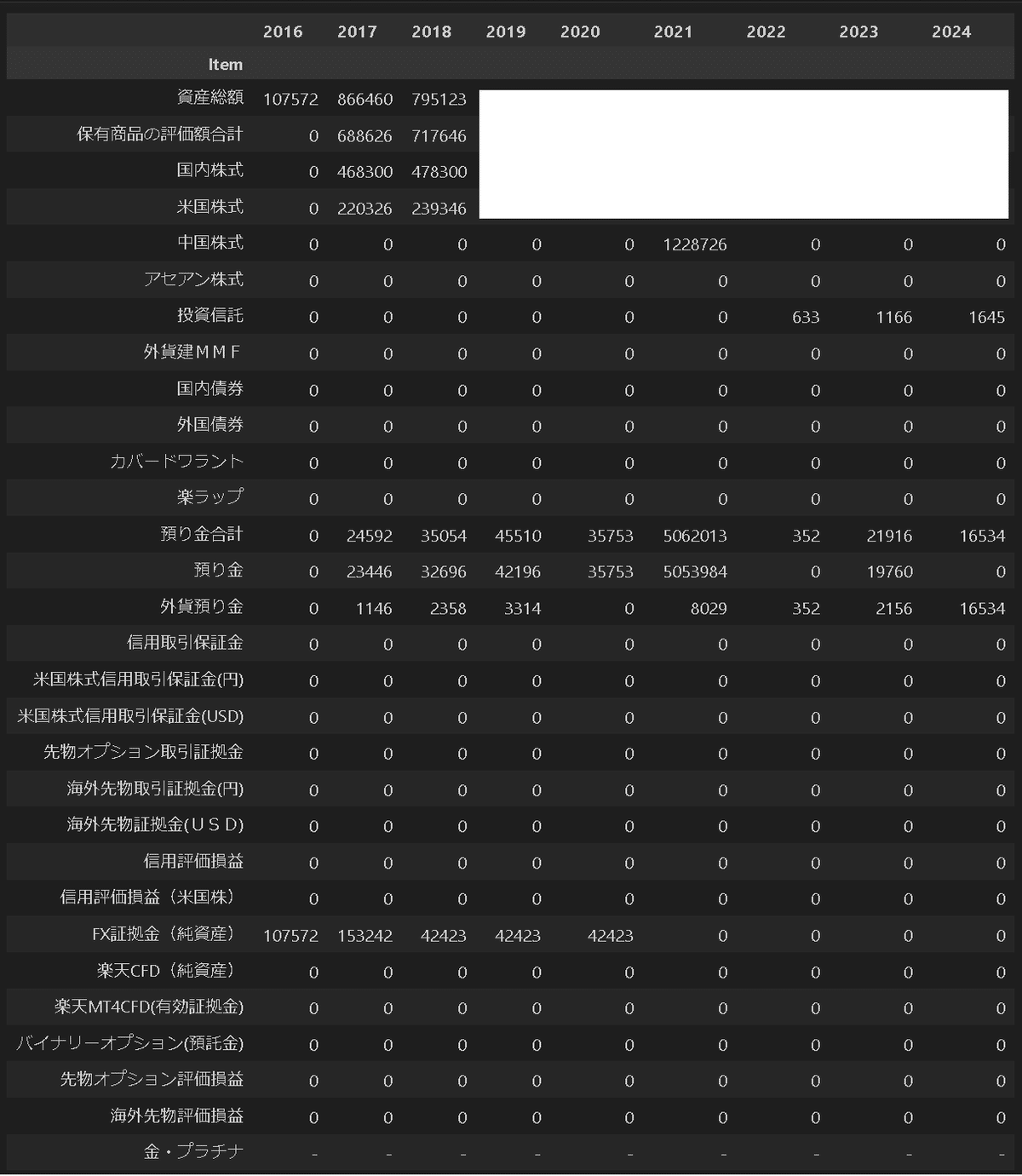
5-2.株式市場ごとの年間損益
各株式市場での年間損益を可視化します。大きく分けて前処理と可視化のスクリプトに分けました
5-2-1.前処理:年間データの作成
”年毎”と”口座(一般、特定、NISA)”別での実現損益のテーブルを作成し、各株式市場のテーブルと結合させてまとめます。
作成はPandasのpd.pivot()でピボットテーブルを使用しました。
[IN]
#ピボットテーブル作成:各口座の年度別実現損益を集計
dfPivot_JP = df_JP.groupby(['年', '口座'])['実現損益[円]'].sum().reset_index()
dfPivot_US = df_US.groupby(['年', '口座'])['実現損益[円]'].sum().reset_index()
dfPivot_CH = df_CH.groupby(['年', '口座'])['実現損益[円]'].sum().reset_index()
#可視化用に追加
dfPivot_JP['Market'], dfPivot_US['Market'], dfPivot_CH['Market'] = 'JP', 'US', 'CH'
display(HorizontalDisplay(dfPivot_JP, dfPivot_US, dfPivot_CH))
##可視化用にDataFrameを事前加工
df_all = pd.concat([dfPivot_JP, dfPivot_US, dfPivot_CH], axis=0, ignore_index=True) #全市場のデータを結合
df_plot = df_all.pivot(index='年', columns=['Market', '口座'], values='実現損益[円]').fillna(0) #各市場の口座別実現損益を年度別に集計
display(df_plot)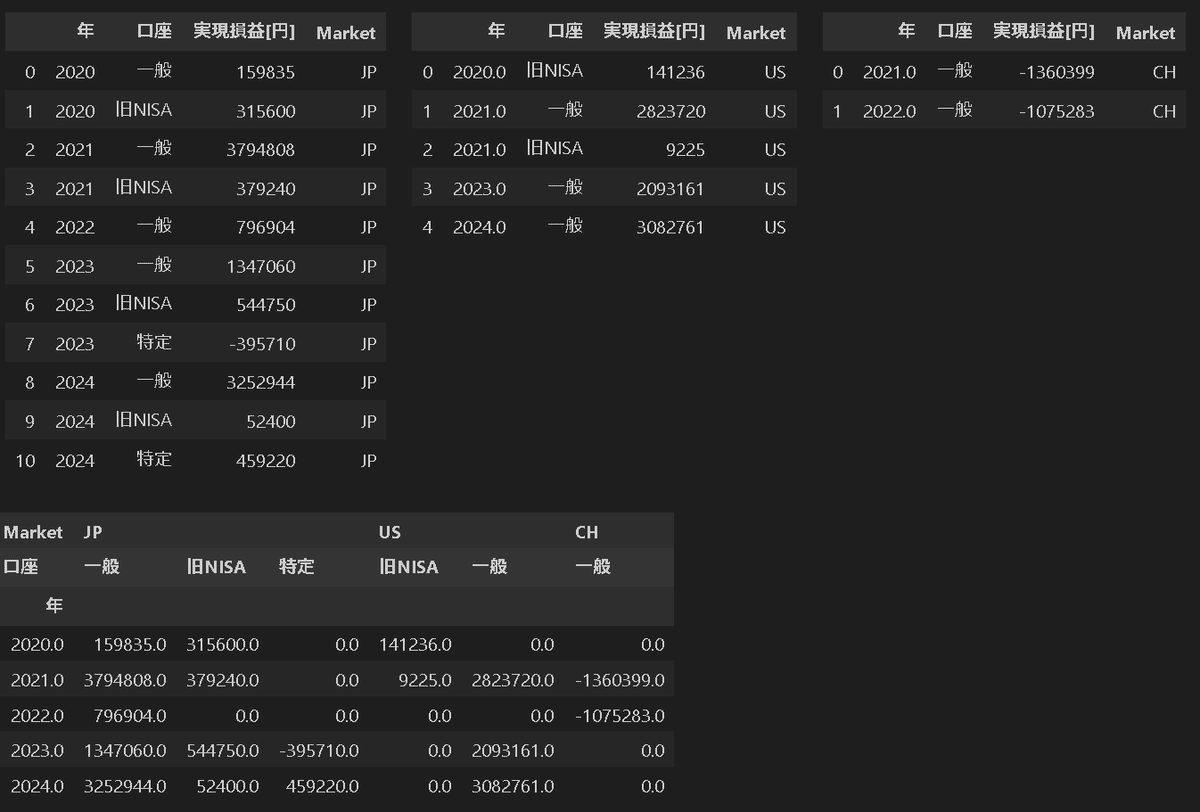
5-2-2.可視化
取得したピボットテーブルから下記思想でグラフを作成しました。
比較図は横軸:年度、縦軸:実現損益として棒グラフと折れ線グラフを作成(グラフの目的は下記記事参照)
棒グラフ:各年度においてどれが良いかの大小比較
折れ線グラフ:各株式市場での成果のトレンド
各株式市場で類似の色を出すようにcolormapリストを作成
指定した金額で目盛線を引けるように調整
calc_yticks()関数を作成
ylimは利益は少し余裕がある配置にし、下はギリギリに詰めた
今のところは50万円がちょうどよいのでデフォルト値に設定
[IN]
##グラフ作成
#y軸の目盛りを計算
def calc_yticks(df, y_scale=500000):
y_max = df.max().max()
y_min = df.min().min()
quotient_upper = y_max // y_scale #指定Scale(メモリ)単位で切り上げ
quotient_lower = y_min // y_scale #指定Scale(メモリ)単位で切り下げ
num_ylim_upper = (quotient_upper + 1) * y_scale #y軸の最大値
num_ylim_lower = quotient_lower * y_scale #y軸の最小値
num_yticks = np.arange(num_ylim_lower, num_ylim_upper+1, y_scale) #y軸の目盛り
return num_ylim_upper, num_ylim_lower, num_yticks
fig, axs = plt.subplots(1, 2, figsize=(12, 6))
ax1, ax2 = axs
x = df_plot.index #年度
num_upper, num_lower, num_yticks = calc_yticks(df_plot) #y軸の目盛りを計算
columns = df_plot.columns #(市場, 口座)のリスト(MultiIndex)
# マーケットごとのカラーテーマ定義
market_color_map = {
'JP': ['#8B0000', '#FF0000', '#FFA07A'], # 濃い赤~赤~ピンク系
'US': ['#00008B', '#0000FF', '#87CEFA'], # 濃い青~青~水色
'CH': ['#006400', '#008000', '#98FB98'] # 濃い緑~緑~明るい緑
}
# Marketごとに口座を抽出して、その順序に応じてカラーを割り当てる
market_accounts = {}
for (mkt, acc) in columns:
if mkt not in market_accounts:
market_accounts[mkt] = []
if acc not in market_accounts[mkt]:
market_accounts[mkt].append(acc)
print(f'market_accounts: {market_accounts}')
#設定値
bar_width = 0.1 # バーの幅
num_cols = len(columns) # カラム数
offsets = [(i - num_cols/2) * bar_width + bar_width/2 for i in range(num_cols)] # オフセット計算
# =============== 棒グラフ(ax1) ===============
for i, col in enumerate(columns):
market, account = col #株式市場(JP,US,CH)と口座(一般, 特定, NISA)
y = df_plot[col] #実現損益の抽出
label = f'{market}_{account}'
# market毎のパレットから口座の順に応じた色を選ぶ
acc_index = market_accounts[market].index(account) # market内のaccountリスト中でのインデックスを取得し、その順に対応する色を選択
color = market_color_map[market][acc_index % len(market_color_map[market])]
# オフセットを使ってバーを並べる
x_positions = x + offsets[i]
ax1.bar(x_positions, y, width=bar_width, label=label, color=color)
ax1.set_title('各株式市場における年度別損益', fontsize=14, y=-0.15)
ax1.set(xlabel='年度', ylabel='実現損益(円)', xticks=x, ylim=(num_lower, num_upper), yticks=num_yticks)
ax1.yaxis.set_major_formatter(StrMethodFormatter('{x:,.0f}'))
ax1.set_xticklabels([str(int(i)) for i in x])
ax1.legend()
ax1.grid(True, linestyle='--', alpha=0.7)
# =============== 折れ線グラフ(ax2) ===============
for col in columns:
market, account = col
y = df_plot[col]
label = f'{market}_{account}'
# 折れ線も同様にカラーを統一
acc_index = market_accounts[market].index(account)
color = market_color_map[market][acc_index % len(market_color_map[market])]
ax2.plot(x, y, marker='o', label=label, color=color)
ax2.set_title('各株式市場における損益トレンド', fontsize=14, y=-0.15)
ax2.set(xlabel='年度', ylabel='実現損益(円)', xticks=x, ylim=(num_lower, num_upper), yticks=num_yticks)
ax2.yaxis.set_major_formatter(StrMethodFormatter('{x:,.0f}'))
ax2.set_xticklabels([str(int(i)) for i in x])
ax2.legend(bbox_to_anchor=(1.05, 1), loc='upper left', borderaxespad=0) #凡例をグラフ外に表示
ax2.grid(True, linestyle='--', alpha=0.7)
plt.tight_layout()
plt.show()[OUT]
market_accounts: {'JP': ['一般', '旧NISA', '特定'], 'US': ['旧NISA', '一般'], 'CH': ['一般']}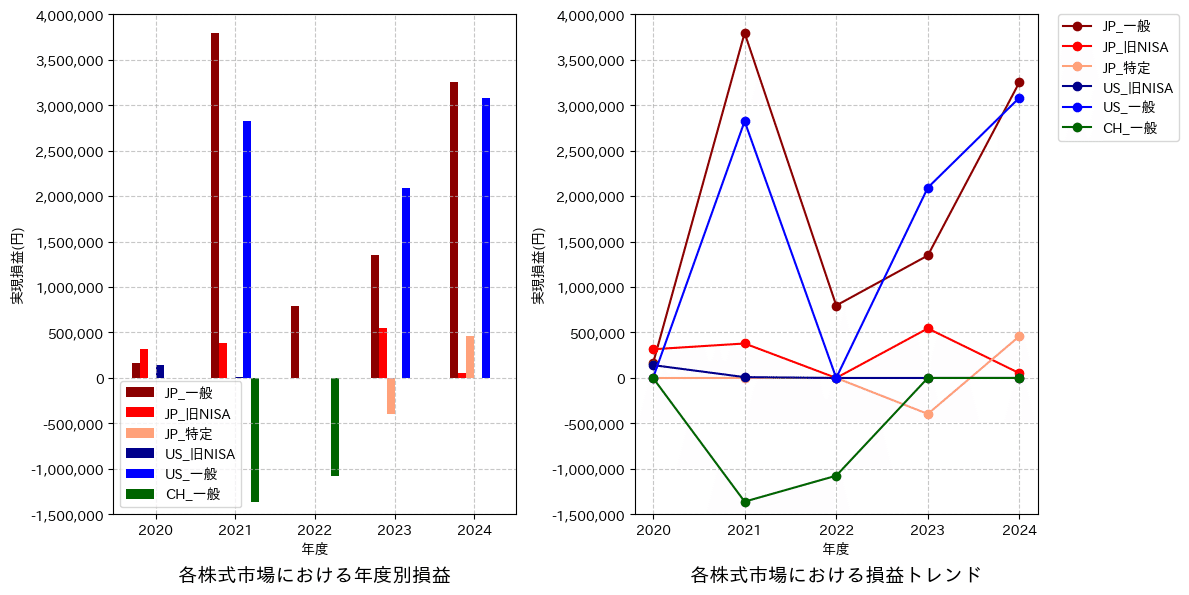
5-3.年間利益率
次に総資産から年間利益率[%]を計算します。
$$
年間利益率=\frac{年間損益}{総資産(投資原本)}\times100
$$
下記のような前提があるためあくまで参考値となります。
資産は100%が投資によるお金ではなく、自分の預貯金(安全資金)を入れたり、逆にがっつり使いたい時に出したりもしている。
理想の投資原本(分母)は前年度ですが、上記の理由もあり計算上は同じ年度で計算
5-3-1.前処理:年間損益率の計算
年間損益率は下記手順で計算しました。
資産情報を計算できるように加工
年度をスライスで抽出し、Indexの"資産総額"をlocで抽出
楽天の「年間損益計算(一般口座・その他)」で検算できるようにNISA口座あり・無しで計算
NISA口座の抽出は正規表現(re)を使用
合計はdf.sum(axis=1)で行方向にSUM計算
1・2を割り算して年間利益率を計算
[IN]
#資産情報を加工
df_assets_ext = df_assets[[2020, 2021, 2022, 2023, 2024]] #データがある年度のみ抽出
df_Totalassets_Year = df_assets_ext.loc['資産総額']
#NISA無しでのデータも作成(検算用)
_columns = []
for c in df_plot.columns:
if re.search(r'.*NISA.*', c[1]): #NISAという文字があるカラムがあるかどうか
continue
else:
_columns.append(c)
df_plot_NoNISA = df_plot[_columns] #NISA口座を除いたデータ
#年毎の実現損益を計算
df_PL_Year = df_plot.sum(axis=1) #年度別の実現損益
df_PL_Year_NoNISA = df_plot_NoNISA.sum(axis=1) #NISA口座を除いた実現損益
df_YearPL_Ratio = df_PL_Year / df_Totalassets_Year*100 #年間投資利益率[%]
df_YearPL_Ratio_NoNISA = df_PL_Year_NoNISA / df_Totalassets_Year*100 #NISA口座を除いた年間投資利益率[%]
#表示用
display(df_plot_NoNISA)
print(df_YearPL_Ratio)
print(df_YearPL_Ratio_NoNISA)
[OUT]
年
2020.0 4.771635
2021.0 55.061175
2022.0 -2.745491
2023.0 12.56399
2024.0 28.416469
dtype: object
年
2020.0 1.23676
2021.0 51.273168
2022.0 -2.745491
2023.0 10.657126
2024.0 28.199008
dtype: object
5-3-2.可視化
可視化は下図の通りです。コードの作り方は前節とほぼ同じです。
[IN]
#可視化
fig, axs = plt.subplots(1, 1, figsize=(12, 6))
ax1 = axs
#y軸の目盛り用
_y_max, _y_min = df_YearPL_Ratio.max(), df_YearPL_Ratio.min()
y_max, y_min = (_y_max//5+1) * 5, (_y_min//5) * 5
x = df_YearPL_Ratio.index
y1 = df_YearPL_Ratio.values
y2 = df_YearPL_Ratio_NoNISA.values
ax1.plot(x, y1, marker='o', label='NISA口座あり', color='blue')
ax1.plot(x, y2, marker='o', label='NISA口座なし', color='red')
ax1.set_title('年間投資利益率の推移', fontsize=14, y=-0.15)
ax1.set(xlabel='年度', ylabel='損益率 [%]',
xticks=x, ylim=(y_min, y_max),
yticks=np.arange(y_min, y_max+1, 5))
ax1.legend()
ax1.grid(True, linestyle='--', alpha=0.7)
plt.show()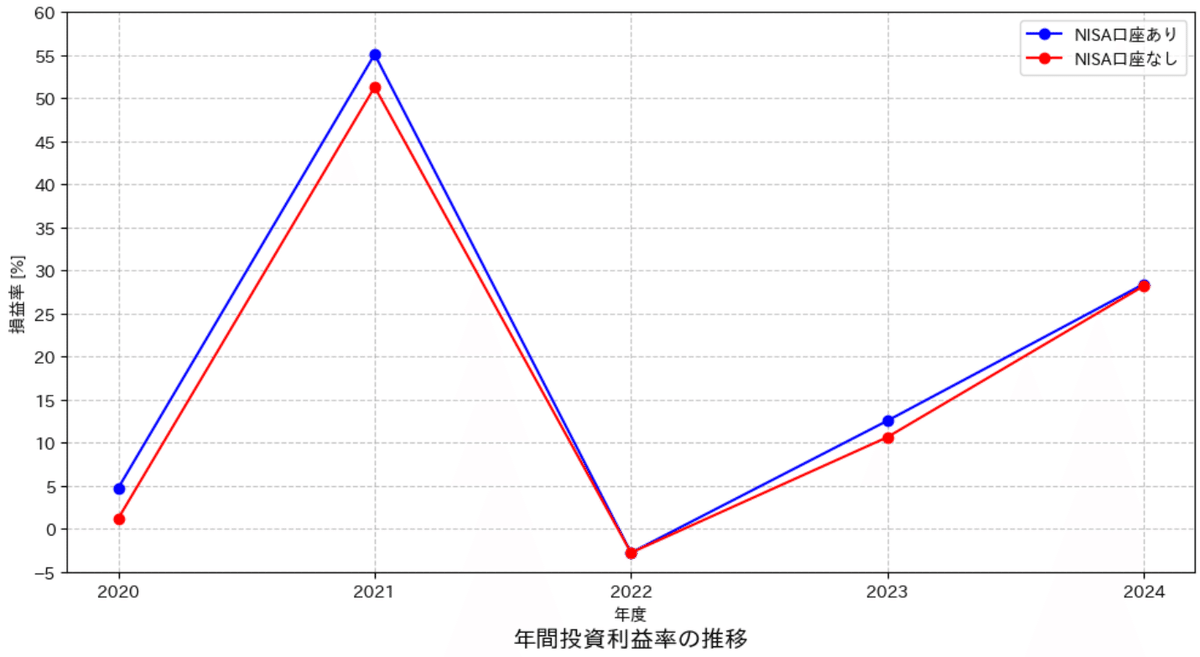
5-4.月ごとの損益
月ごとの損益データを可視化しました。
5-4-1.前処理:月次データ作成
月次データは前節同様にピボットテーブルを使用してグループ化しました。取引をしていない月も0円として認識できるように下記加工をしました。
元の年月をDataTimeに変換(※初期データの'約定日'から抽出してもOKですが、今回は年月だけでよいのであるデータから加工)
月次データの最古、最新をとり、その間を1か月区切りで範囲取得
ピボットテーブル後にNaNをfillna(0)で0埋め
最後にIndexをyyyy/mmの形に変更
[IN]
# 前処理: df_JP, df_US, df_CH から各月・口座の実現損益を集計
dfPivot_JP_month = df_JP.groupby(['年月', '口座'])['実現損益[円]'].sum().reset_index()
dfPivot_US_month = df_US.groupby(['年月', '口座'])['実現損益[円]'].sum().reset_index()
dfPivot_CH_month = df_CH.groupby(['年月', '口座'])['実現損益[円]'].sum().reset_index()
dfPivot_JP_month['Market'] = '国内株式'
dfPivot_US_month['Market'] = '米国株式'
dfPivot_CH_month['Market'] = '中国株式'
# display(HorizontalDisplay(dfPivot_JP_month, dfPivot_US_month, dfPivot_CH_month))
# 1. 全データ結合
df_all_month = pd.concat([dfPivot_JP_month, dfPivot_US_month, dfPivot_CH_month], ignore_index=True)
# 2. 年月をdatetime型に変換
df_all_month['年月'] = pd.to_datetime(df_all_month['年月'], format='%Y/%m')
# 3. NISA口座を除いたデータも作成
df_no_nisa_month = df_all_month[df_all_month['口座'] != 'NISA']
# 4. 全期間をカバーする月一覧を生成
min_date = min(df_all_month['年月'].min(), df_no_nisa_month['年月'].min())
max_date = max(df_all_month['年月'].max(), df_no_nisa_month['年月'].max())
# freq='MS'は毎月1日(Month Start)の日付を生成
full_range = pd.date_range(start=min_date, end=max_date, freq='MS')
print(full_range)
# 5. ピボット(Market, 口座)別に実現損益集計
df_all_accounts = df_all_month.pivot(index='年月', columns=['Market', '口座'], values='実現損益[円]')
df_no_nisa_accounts = df_no_nisa_month.pivot(index='年月', columns=['Market', '口座'], values='実現損益[円]')
# 6. full_rangeでreindexし、欠損は0で補完
df_all_accounts = df_all_accounts.reindex(full_range).fillna(0)
df_no_nisa_accounts = df_no_nisa_accounts.reindex(full_range).fillna(0)
# X軸をYYYY/MM形式で統一するためにインデックスを文字列に変換
df_all_accounts.index = df_all_accounts.index.strftime('%Y/%m')
df_no_nisa_accounts.index = df_no_nisa_accounts.index.strftime('%Y/%m')
display(HorizontalDisplay(df_all_accounts, df_no_nisa_accounts))[OUT]
DatetimeIndex(['2020-01-01', '2020-02-01', '2020-03-01', '2020-04-01',
'2020-05-01', '2020-06-01', '2020-07-01', '2020-08-01',
'2020-09-01', '2020-10-01', '2020-11-01', '2020-12-01',
'2021-01-01', '2021-02-01', '2021-03-01', '2021-04-01',
'2021-05-01', '2021-06-01', '2021-07-01', '2021-08-01',
'2021-09-01', '2021-10-01', '2021-11-01', '2021-12-01',
'2022-01-01', '2022-02-01', '2022-03-01', '2022-04-01',
'2022-05-01', '2022-06-01', '2022-07-01', '2022-08-01',
'2022-09-01', '2022-10-01', '2022-11-01', '2022-12-01',
'2023-01-01', '2023-02-01', '2023-03-01', '2023-04-01',
'2023-05-01', '2023-06-01', '2023-07-01', '2023-08-01',
'2023-09-01', '2023-10-01', '2023-11-01', '2023-12-01',
'2024-01-01', '2024-02-01', '2024-03-01', '2024-04-01',
'2024-05-01', '2024-06-01', '2024-07-01', '2024-08-01',
'2024-09-01', '2024-10-01', '2024-11-01'],
dtype='datetime64[ns]', freq='MS')
5-4-2.可視化
得られたデータを可視化します。しかし綺麗に見せるためには下記の問題が発生しますので、それぞれ関数を追加しました。
NISA有り無しの時の凡例の色がずれる
形が崩れない関数を追加
売買履歴が無い月が存在するとデータがずれる
前項で対応済み
データ数が増えるとx軸が見えにくい:2ヶ月ごとに表示
ちょうどよい軸設定がない:前節のcalc_yticks()を使用
最後にplt.plot(kind='bar', stacked=True)で重ね棒グラフを作成しました。
[IN]
#グラフ体裁の設定値
# 市場ごとのカラー定義
market_color_map = {
'国内株式': ['#8B0000', '#FF0000', '#FFA07A'],
'米国株式': ['#00008B', '#0000FF', '#87CEFA'],
'中国株式': ['#006400', '#008000', '#98FB98']
}
# カラー固定化のため全データからmarket_accounts抽出
all_columns = df_all_accounts.columns # (Market, 口座)のMultiIndex
market_accounts = {}
for (mkt, acc) in all_columns:
if mkt not in market_accounts:
market_accounts[mkt] = []
if acc not in market_accounts[mkt]:
market_accounts[mkt].append(acc)
def generate_color_list(df, market_color_map, market_accounts):
columns = df.columns
color_list = []
for (mkt, acc) in columns:
acc_index = market_accounts[mkt].index(acc)
color = market_color_map[mkt][acc_index % len(market_color_map[mkt])]
color_list.append(color)
return color_list
colors_all = generate_color_list(df_all_accounts, market_color_map, market_accounts)
colors_no_nisa = generate_color_list(df_no_nisa_accounts, market_color_map, market_accounts)
print(market_accounts)
print(colors_all)
print(colors_no_nisa)
#y軸の目盛り(tick)を計算
def calc_yticks(df, y_scale=500000):
y_max = df.max().max()
y_min = df.min().min()
quotient_upper = int(y_max // y_scale)
quotient_lower = int(y_min // y_scale)
num_ylim_upper = (quotient_upper + 1) * y_scale
num_ylim_lower = quotient_lower * y_scale
num_yticks = np.arange(num_ylim_lower, num_ylim_upper+1, y_scale)
return num_ylim_upper, num_ylim_lower, num_yticks
# 可視化
fig, (ax1, ax2) = plt.subplots(2, 1, figsize=(12, 10))
num_ylim_upper, num_ylim_lower, num_yticks = calc_yticks(df_all_accounts)
# 全口座グラフ(上段)
df_all_accounts.plot(kind='bar', stacked=True, ax=ax1, color=colors_all)
ax1.set(xlabel='年月', ylabel='総利益(円)', ylim=(num_ylim_lower, num_ylim_upper), yticks=num_yticks)
ax1.yaxis.set_major_formatter(StrMethodFormatter('{x:,.0f}'))
ax1.grid(True, linestyle='--', alpha=0.7)
ax1.legend(title='市場・口座', bbox_to_anchor=(1.05, 1), loc='upper left')
# NISA抜きグラフ(下段)
df_no_nisa_accounts.plot(kind='bar', stacked=True, ax=ax2, color=colors_no_nisa)
ax2.set(xlabel='年月', ylabel='総利益(円)', ylim=(num_ylim_lower, num_ylim_upper), yticks=num_yticks)
ax2.yaxis.set_major_formatter(StrMethodFormatter('{x:,.0f}'))
ax2.grid(True, linestyle='--', alpha=0.7)
ax2.legend(title='市場・口座', bbox_to_anchor=(1.05, 1), loc='upper left')
plt.suptitle('月次実現損益の推移(上:NISAあり、下:NISA無し)', fontsize=14, y=-0.01)
plt.tight_layout()
plt.show()[OUT]
{'国内株式': ['一般', '旧NISA', '特定'], '米国株式': ['旧NISA', '一般'], '中国株式': ['一般']}
['#8B0000', '#FF0000', '#FFA07A', '#00008B', '#0000FF', '#006400']
['#8B0000', '#FF0000', '#FFA07A', '#00008B', '#0000FF', '#006400']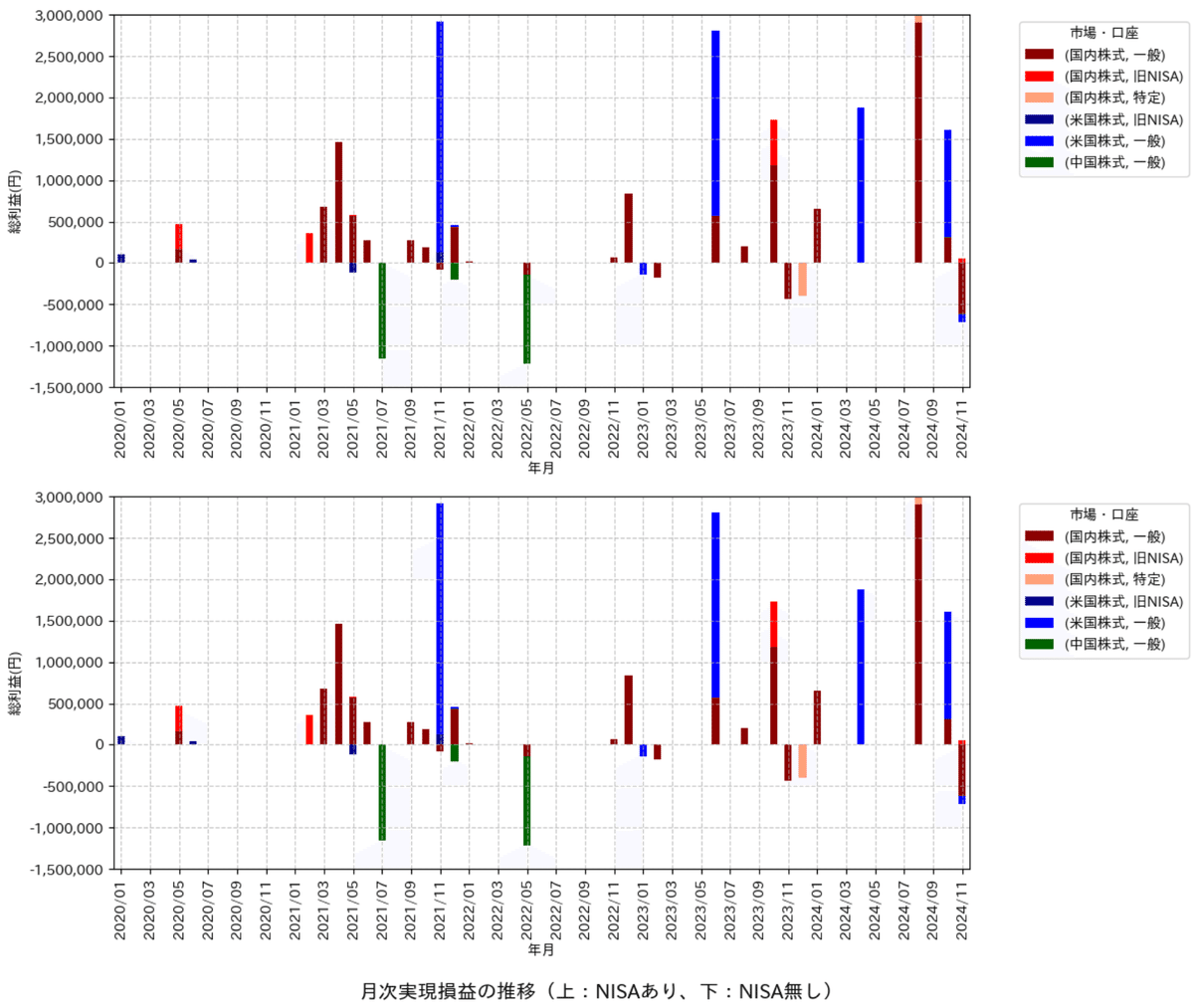
5-5.売買銘柄ごとの損益
どの銘柄で一番儲けたか/損したかを表示します。
5-5-1.前処理:銘柄データ作成
今回はトータル損益で計算するため元データの実現損益を銘柄名でグループ化するだけとなります。
[IN]
#ピボットテーブル作成:銘柄別の実現損益を集計
df_Brand_JP = df_JP.groupby('銘柄名')['実現損益[円]'].sum().reset_index()
df_Brand_US = df_US.groupby('銘柄名')['実現損益[円]'].sum().reset_index()
df_Brand_CH = df_CH.groupby('銘柄名')['実現損益[円]'].sum().reset_index()
def extract_top_bottom_n(df, n=5):
df_top = df.sort_values('実現損益[円]', ascending=False).head(n).reset_index(drop=True)
df_bottom = df.sort_values('実現損益[円]', ascending=True).head(n).reset_index(drop=True)
return df_top, df_bottom
#ソート
df_Brand_JP_top, df_Brand_JP_bottom = extract_top_bottom_n(df_Brand_JP, n=10)
df_Brand_US_top, df_Brand_US_bottom = extract_top_bottom_n(df_Brand_US, n=8)
df_Brand_CH_top, df_Brand_CH_bottom = extract_top_bottom_n(df_Brand_CH)
display(HorizontalDisplay(df_Brand_JP_top, df_Brand_JP_bottom))
display(HorizontalDisplay(df_Brand_US_top, df_Brand_US_bottom))
display(HorizontalDisplay(df_Brand_CH_top, df_Brand_CH_bottom))[OUT]
-
5-5-2.可視化
左に上位銘柄、右に下位銘柄を並べて、それを各株式市場で表示させたいと思うので可視化は関数にしました。
結果は下記の通りです。
[IN]
#可視化:左:上位銘柄、右:下位銘柄
def plot_PL_Ranking(df_top, df_bottom, titleword:str='国内株式'):
fig, axs = plt.subplots(1, 2, figsize=(12, 10))
ax1, ax2 = axs
ax1.bar(df_top['銘柄名'], df_top['実現損益[円]'], color='skyblue')
ax1.set_xticklabels(df_top['銘柄名'], rotation=90)
ax1.set_title(f'上位銘柄_{titleword}', fontsize=14, y=-0.3)
ax1.set(xlabel='銘柄名', ylabel='総損益(円)')
ax1.yaxis.set_major_formatter(StrMethodFormatter('{x:,.0f}'))
ax1.grid(True, linestyle='--', alpha=0.7)
ax2.bar(df_bottom['銘柄名'], df_bottom['実現損益[円]'], color='lightcoral')
ax2.set_title(f'下位銘柄_{titleword}', fontsize=14, y=-0.3)
ax2.set_xticklabels(df_bottom['銘柄名'], rotation=90)
ax2.set(xlabel='銘柄名', ylabel='総損益(円)')
ax2.yaxis.set_major_formatter(StrMethodFormatter('{x:,.0f}'))
ax2.grid(True, linestyle='--', alpha=0.7)
plt.tight_layout()
plt.show()
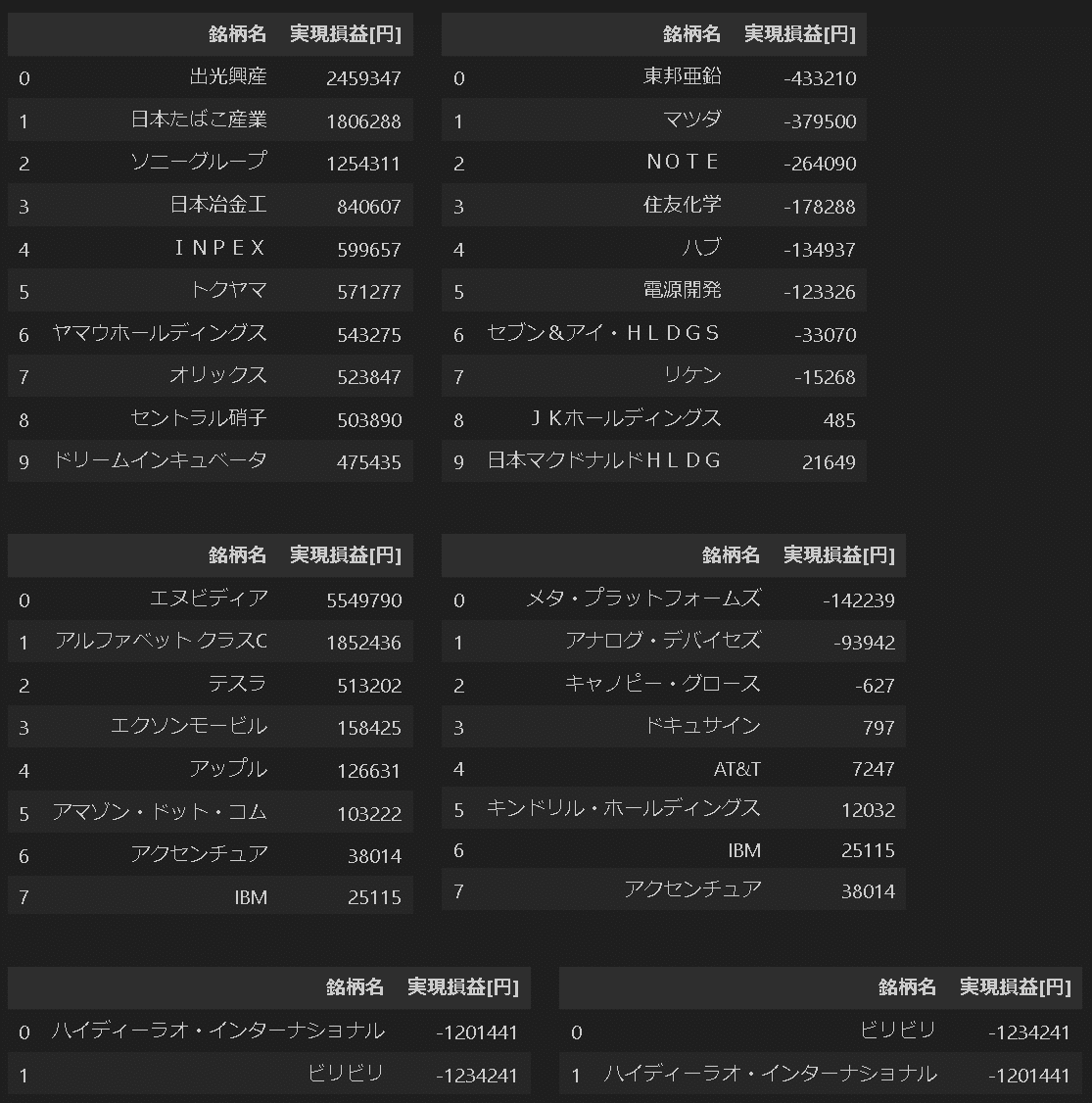
plot_PL_Ranking(df_Brand_JP_top, df_Brand_JP_bottom, titleword='国内株式')
plot_PL_Ranking(df_Brand_US_top, df_Brand_US_bottom, titleword='米国株式')
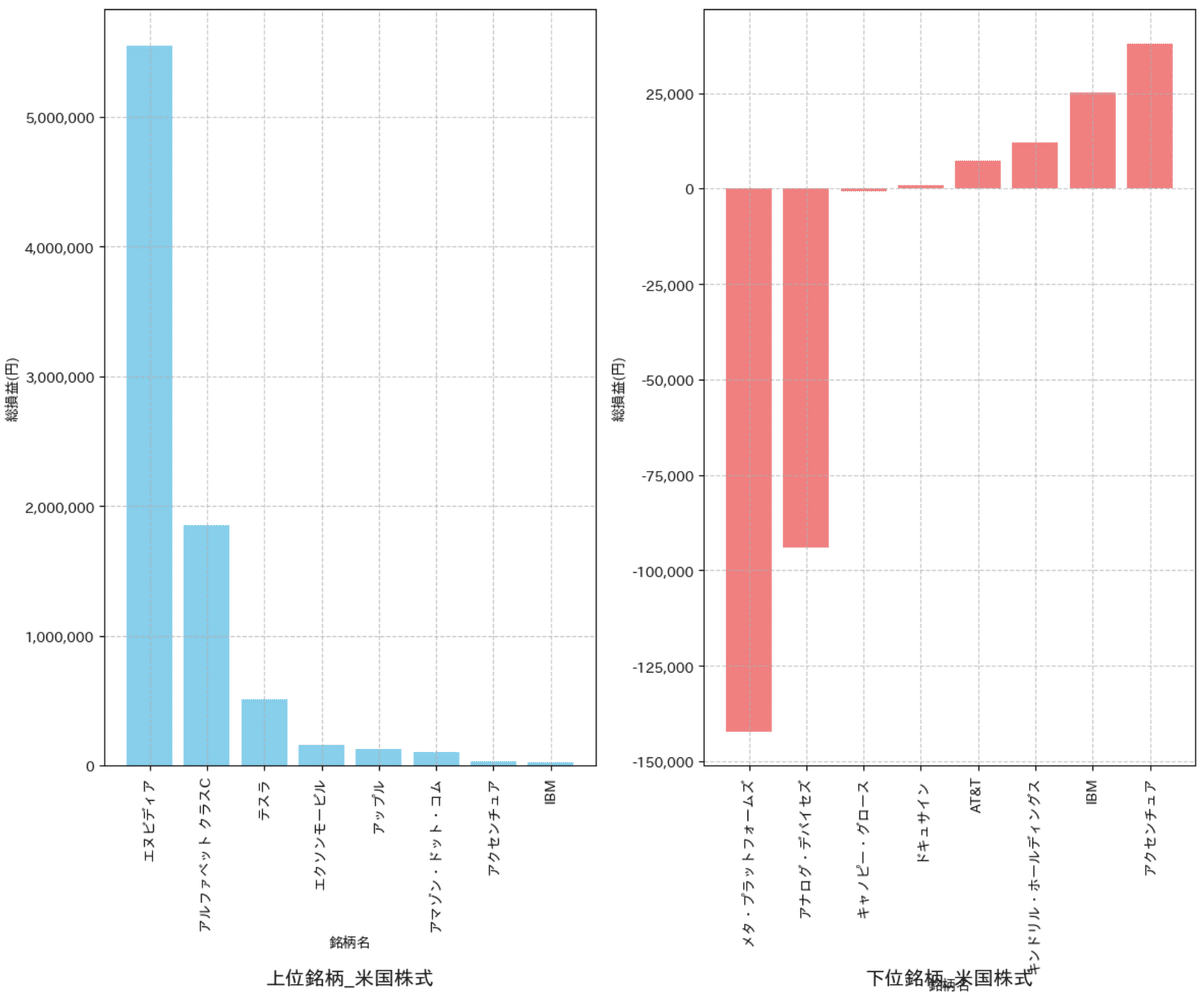
plot_PL_Ranking(df_Brand_CH_top, df_Brand_CH_bottom, titleword='中国株式')[OUT]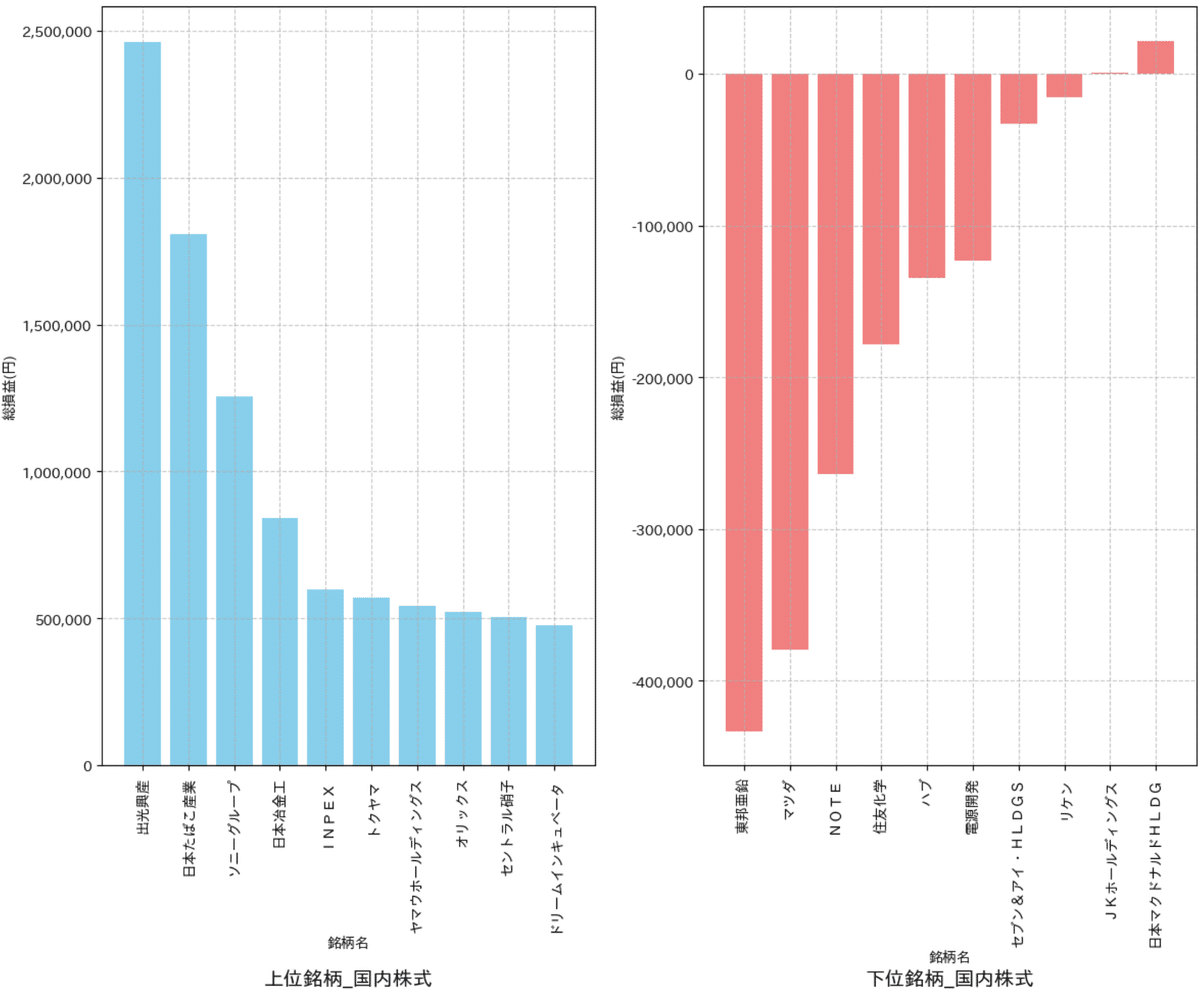
6.結果の分析(自分用)
下図の確認は下記の通り。
中国株式は銘柄選定が下手すぎるので手は出さない。
パフォーマンスは国内/米国株式市場の差よりは投資時期(運)要素が強い。良い銘柄が選べるならどちらでもOK
比較的連動(相関関係が強そう)なので、リスクヘッジの意味はなさそう
上手くNISAを使えてないので税金がもったいない
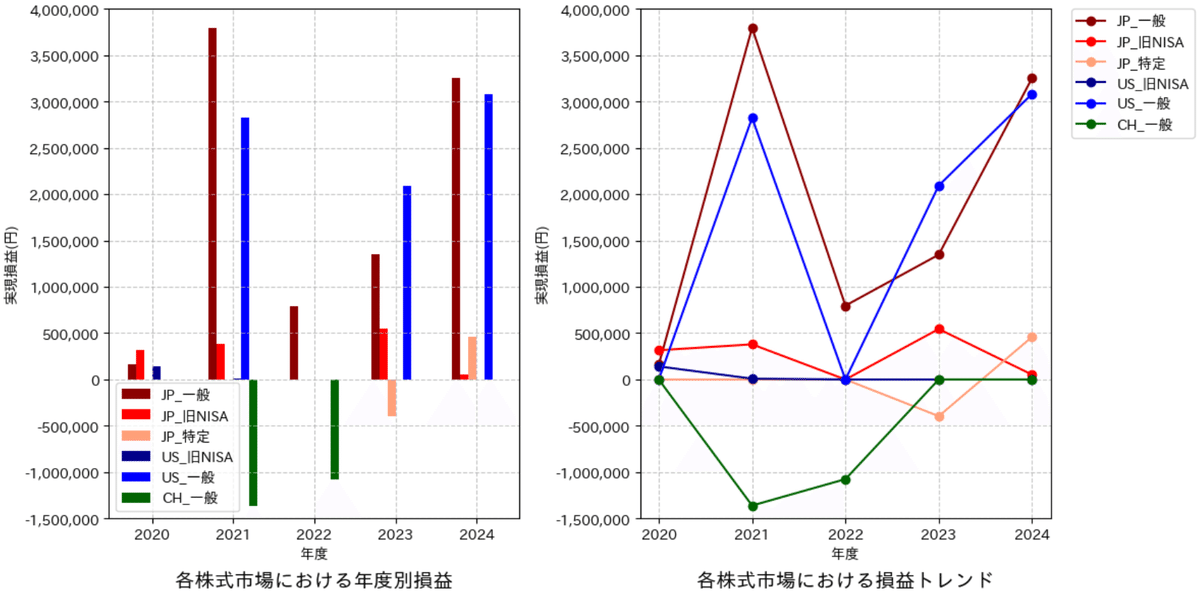
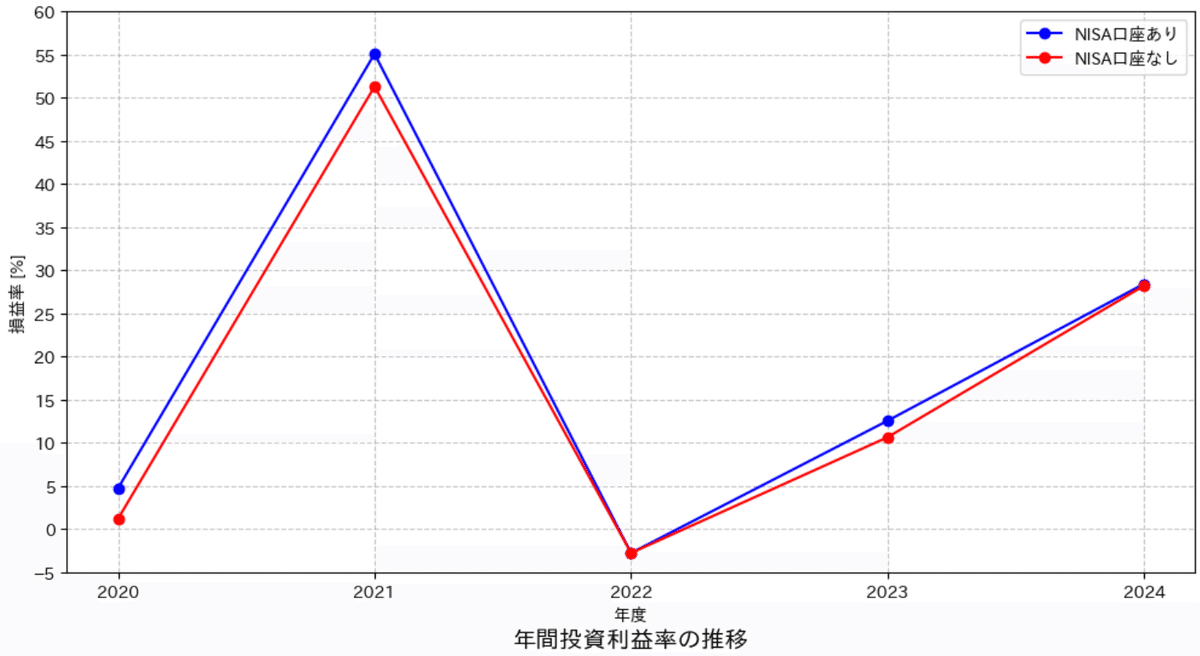
下図の確認は下記の通り。
投資スタイルも長期のため”コツコツドカン”みたいなのが多い。
結構早売りしてドカンが小さくなることは多々あり
ストップ安で直撃した銘柄もたくさんあるが、早めの損切りで数十万くらいに被害が収まってた
2022年はそもそもトレードをほとんどしてなかった
少しくらいは調整しても良かったかも
多分失恋と転職が重なって忙しかったのかも
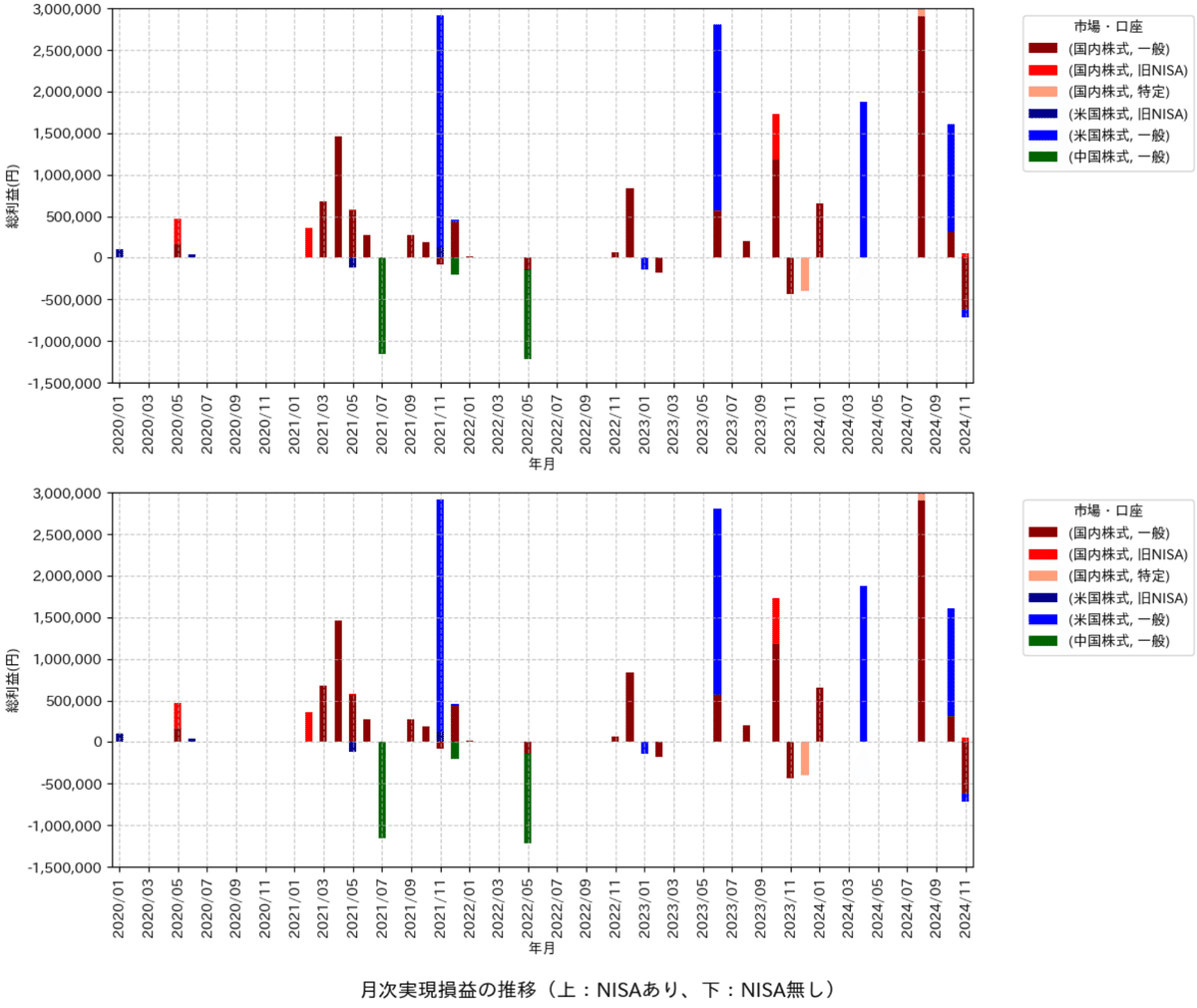
下図の確認は下記の通り。
国内は自分の記憶/イメージと全く銘柄がトップ/ワーストにきた
比較的最近の銘柄が多く、つまり資産が増えたため損益が増えていると想定される:損失率でみると全く変わると思う
米国株は14銘柄しか投資してなかったけどパフォーマンスが良いのは本当にたまたまだった
エヌビディアは本当に様様
参考資料
あとがき
エヌビディアやテスラに助けてもらったので、次の投資先を見つけないと