
Pythonライブラリ(画像処理):Pillow

1.概要
画像処理ライブラリのPillowを紹介します。OpenCV、YOLOのような高度な画像処理はできませんが、画像解析の前処理にも使用できます。
インストールは下記ですが使用時はPILとなりますのでご留意ください。
pip install Pillowサンプル画像は実家の猫を使用しました。
2.基礎処理
2-1.画像の取得:Image.open()
ファイル情報の取得はImage.open()を使用します。Jupyterであれば読みだした変数をそのまま処理で表示できます。
[In]
from PIL import Image
path_imgfile = 'konan.JPG'
#ファイルを開く
img_PIL = Image.open(path_imgfile) #PIL形式で開く
print(type(img_PIL), dir(img_PIL))
img_PIL
[OUT]
<class 'PIL.JpegImagePlugin.JpegImageFile'>
['_Image__transformer', '__array__', '__class__', '__copy__', '__delattr__', '__dict__', '__dir__', '__doc__', '__enter__', '__eq__', '__exit__', '__format__', '__ge__', '__getattr__', '__getattribute__', '__getstate__', '__gt__', '__hash__', '__init__', '__init_subclass__', '__le__', '__lt__', '__module__', '__ne__', '__new__', '__reduce__', '__reduce_ex__', '__repr__', '__setattr__', '__setstate__', '__sizeof__', '__str__', '__subclasshook__', '__weakref__', '_category', '_close_exclusive_fp_after_loading', '_copy', '_crop', '_dump', '_ensure_mutable', '_exclusive_fp', '_exif', '_expand', '_get_safe_box', '_getexif', '_getmp', '_getxmp', '_min_frame', '_new', '_open', '_repr_png_', '_seek_check', '_size', 'alpha_composite', 'app', 'applist', 'bits', 'close', 'convert', 'copy', 'crop', 'custom_mimetype', 'decoderconfig', 'decodermaxblock', 'draft', 'effect_spread', 'entropy', 'filename', 'filter', 'format', 'format_description', 'fp', 'frombytes', 'get_format_mimetype', 'getbands', 'getbbox', 'getchannel', 'getcolors', 'getdata', 'getexif', 'getextrema', 'getim', 'getpalette', 'getpixel', 'getprojection', 'getxmp', 'height', 'histogram', 'huffman_ac', 'huffman_dc', 'icclist', 'im', 'info', 'layer', 'layers', 'load', 'load_djpeg', 'load_end', 'load_prepare', 'load_read', 'mode', 'palette', 'paste', 'point', 'putalpha', 'putdata', 'putpalette', 'putpixel', 'pyaccess', 'quantization', 'quantize', 'readonly', 'reduce', 'remap_palette', 'resize', 'rotate', 'save', 'seek', 'show', 'size', 'split', 'tell', 'thumbnail', 'tile', 'tobitmap', 'tobytes', 'toqimage', 'toqpixmap', 'transform', 'transpose', 'verify', 'width']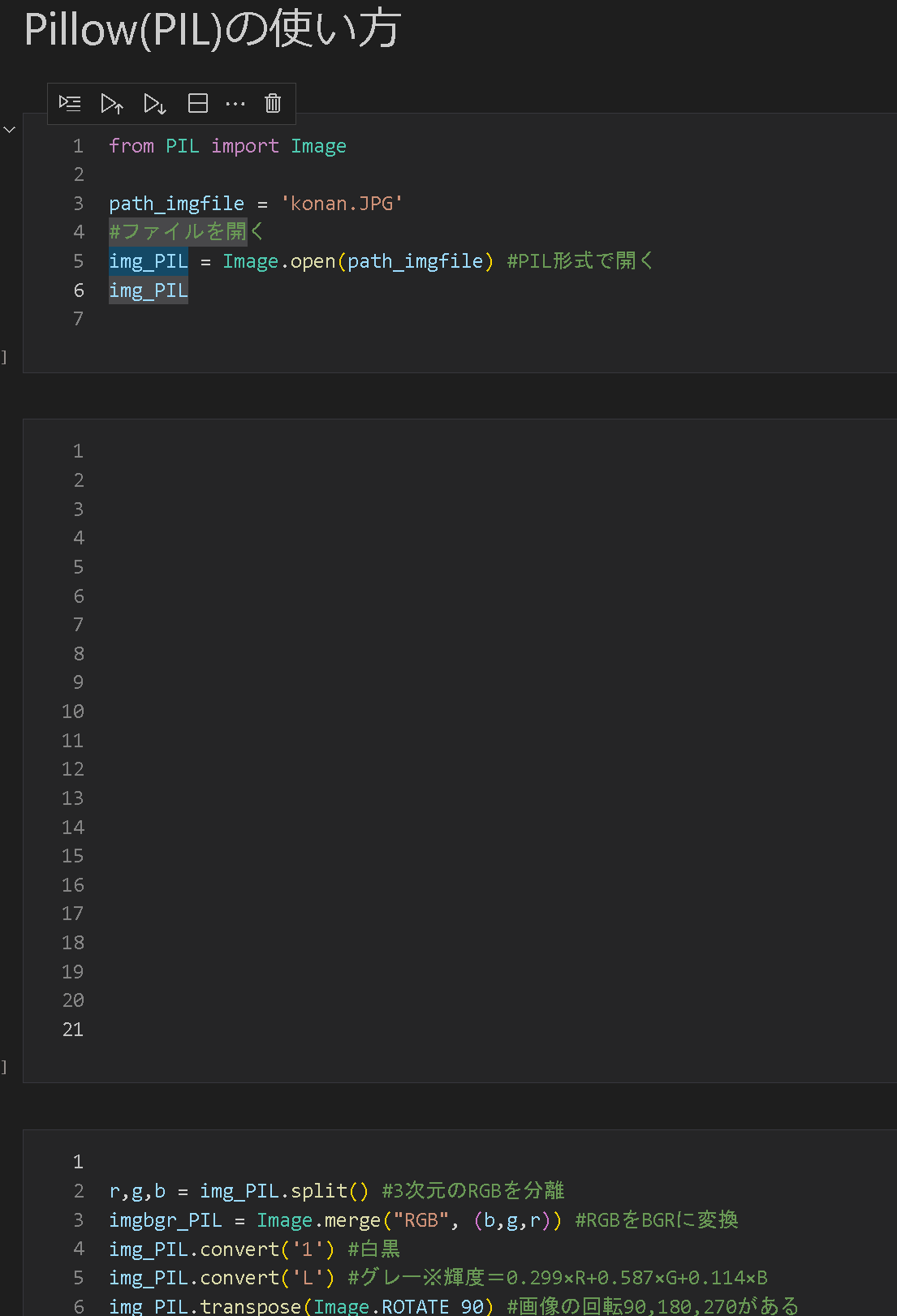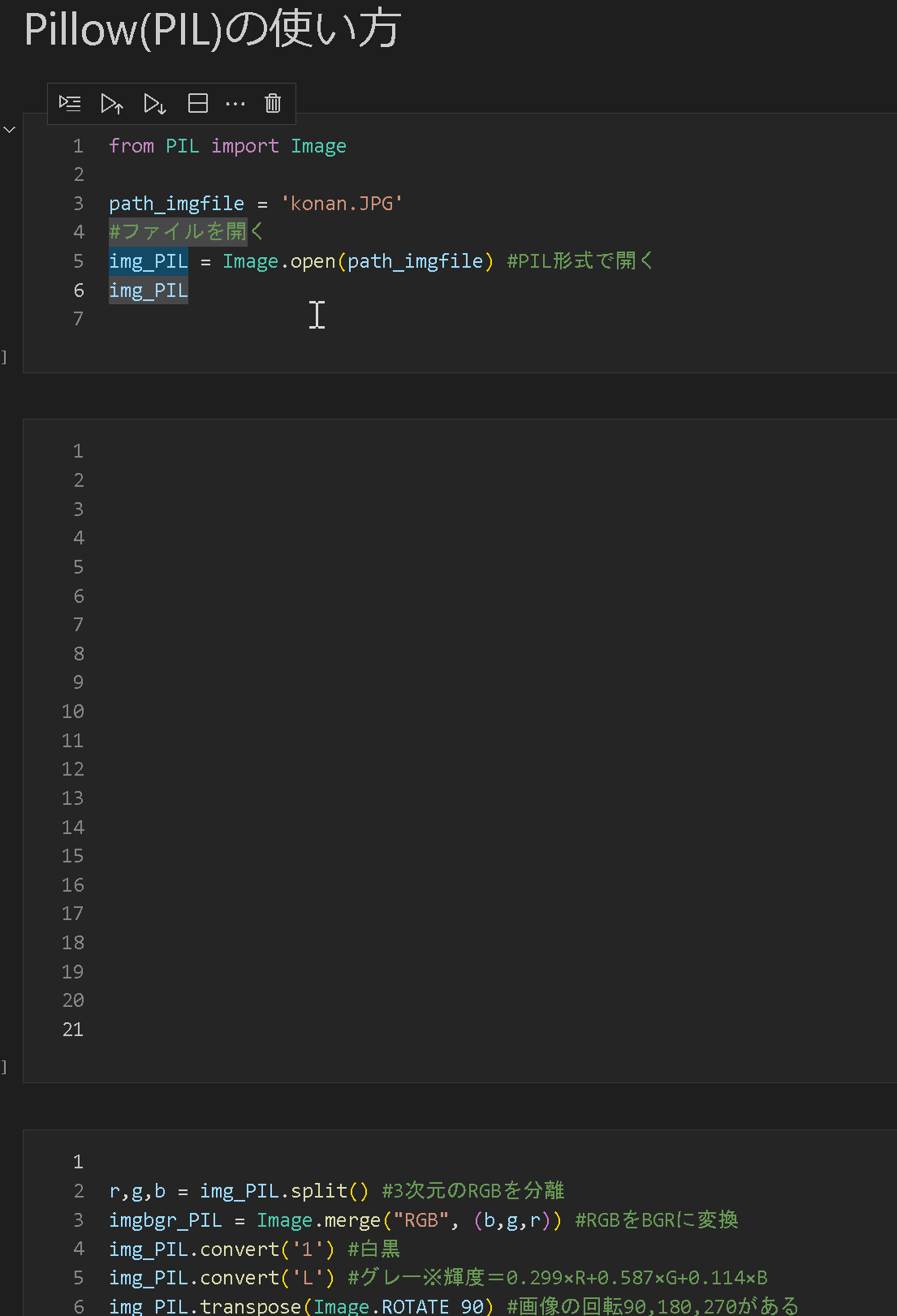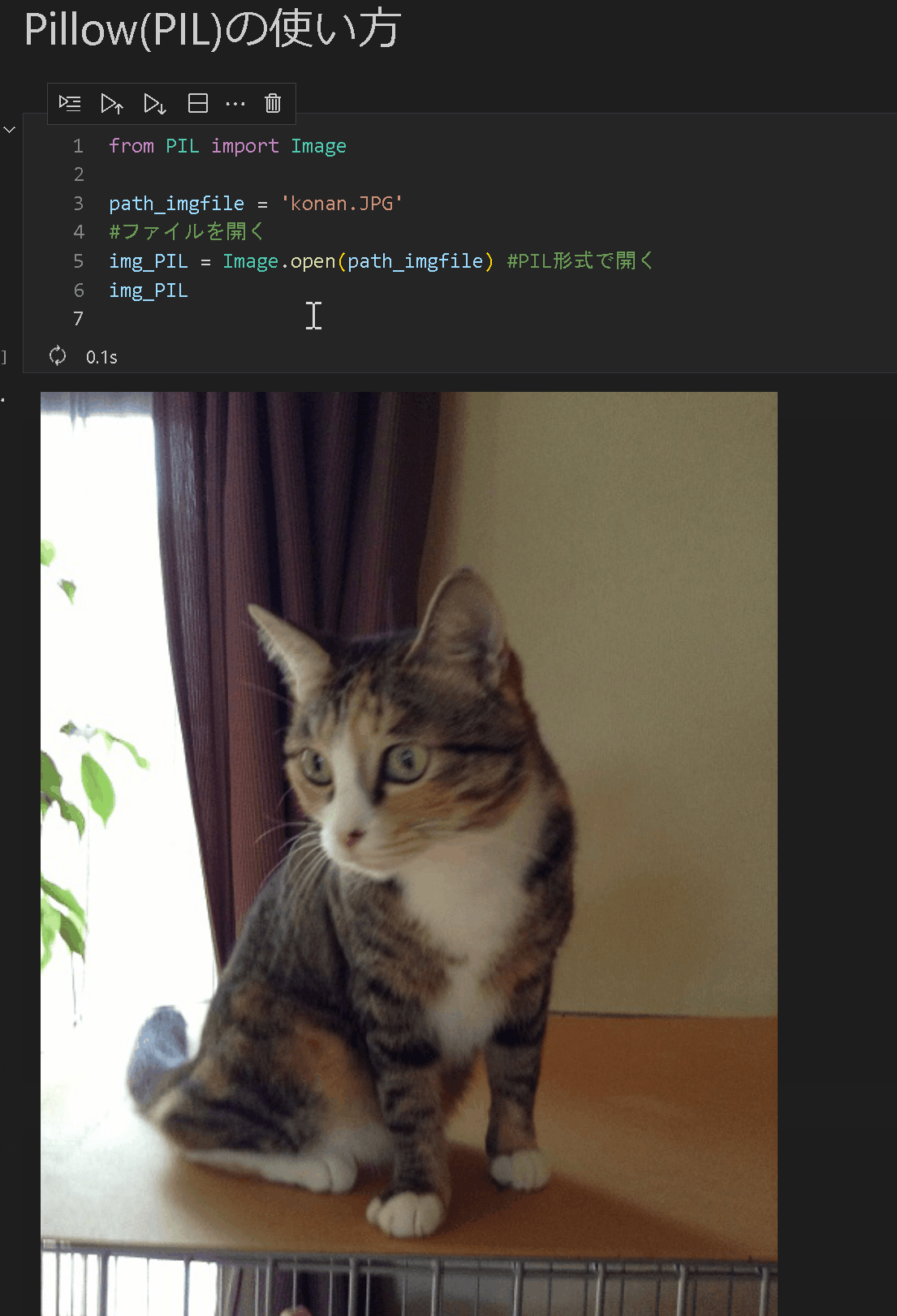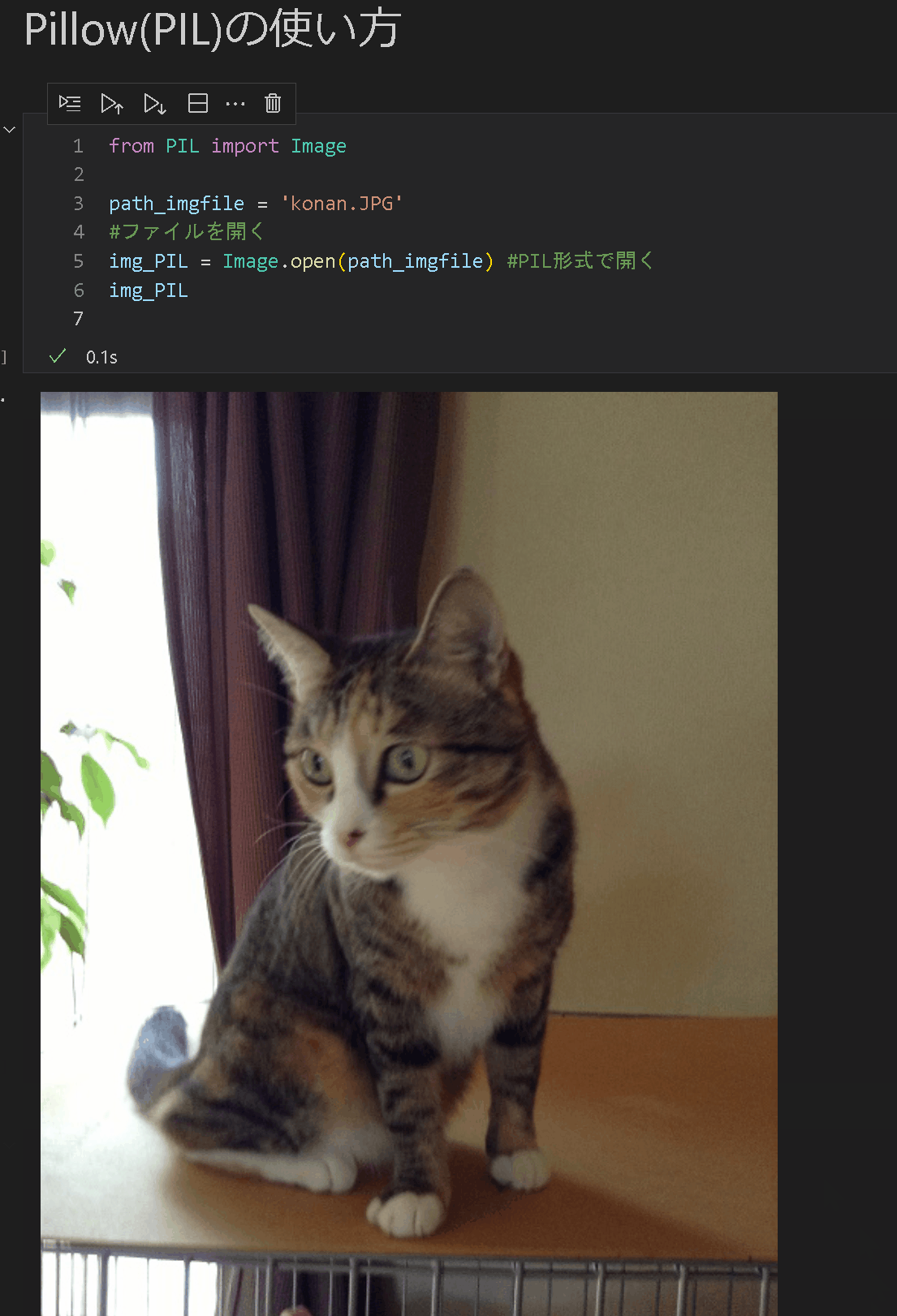
2ー2.画像情報の取得(サイズ、色)
画像データの幅・高さ、拡張子、3原色情報などは下記で取得できます。
[In]
print(img_PIL.mode)
print(img_PIL.size)
print(img_PIL.width, img_PIL.height)
print(img_PIL.format)
print(type(img_PIL))
[Out]
RGB
(484, 648)
484 648
JPEG
<class 'PIL.JpegImagePlugin.JpegImageFile'>2-3.空画像の作成:Image.new()
空の画像作成をする場合はImage.new('mode', (幅, 高さ), color)を使用します。本メソッドは次のImage.paste()と合わせて画像結合に使用できます。
【Image.new()の引数】
●mode:色の種類(Mode詳細は公式参照)
●size:画像の幅・高さ->形式はタプル
●color{default:0->黒色}:背景の色 (255,255,255)を渡すと白色になる
[IN]
from PIL import Image
path_imgfile = 'konan.JPG' # 元画像ファイル
img = Image.open(path_imgfile) #PIL形式で開く
dst = Image.new('RGB', (img.width , img.height)) # 画像サイズを指定
# dst = Image.new('RGB', (img.width , img.height), (255, 255, 255)) # 白色背景
print('width:height=',dst.size, dst.mode, dst.format)
dst
[OUT]
width:height= (484, 648) RGB None
(空画像のため)真っ黒な画像が生成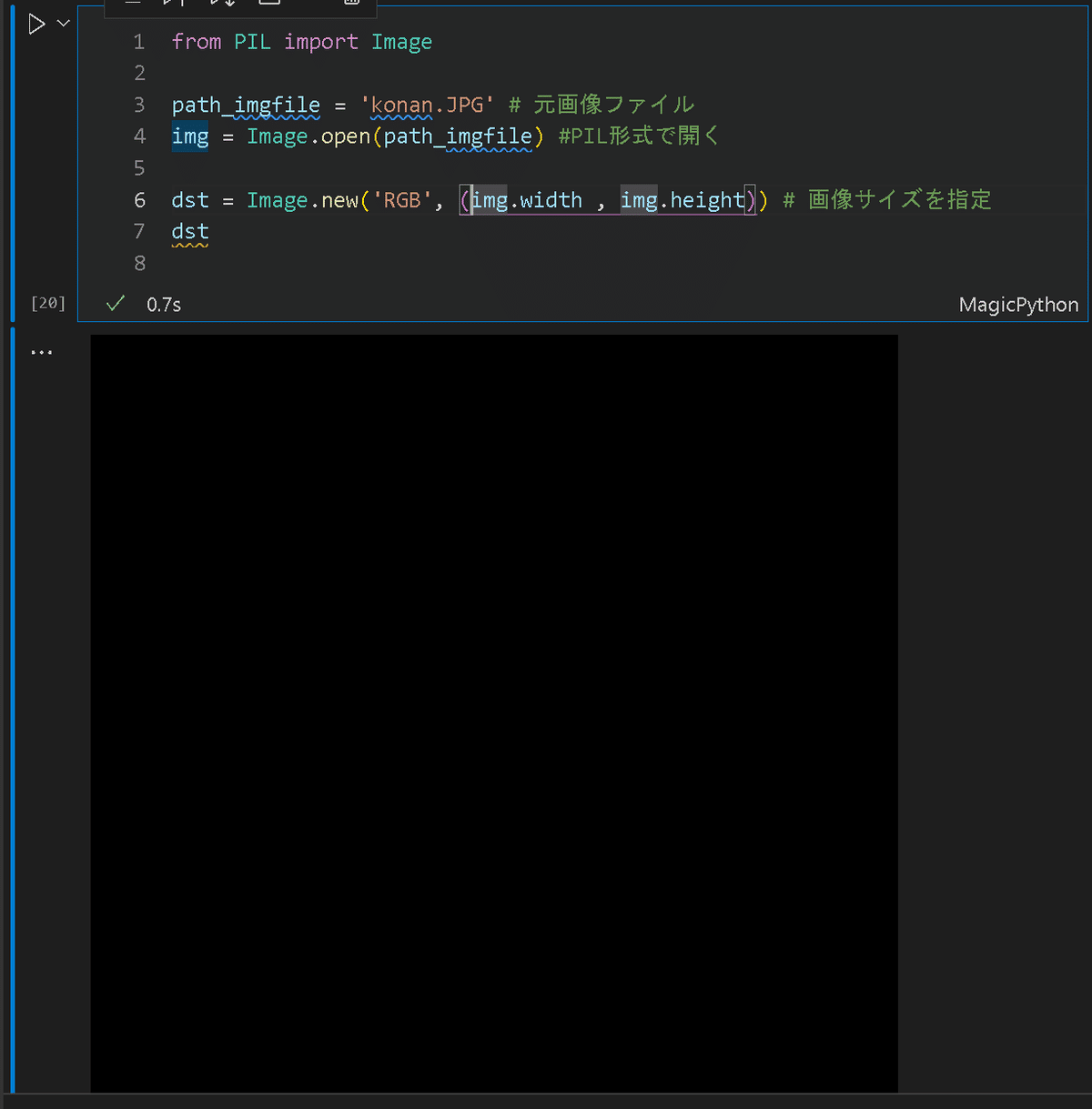
2-4.画像上に上書き:Image.paste()
画像の上に別の画像のペーストはImage.paste(img, 画像の位置)です。
【Image.paste()の引数】
●im:ペーストする画像
●box:タプル形式で渡すがデータ数が2個と4個で動作が異なる
->2-Tuple:(起点幅座標, 起点高さ座標)となり画像の起点は左角となる
->4-Tuple:(左の幅, 左の高さ, 右の幅, 右の高さ )
●mask:An optional mask image
サンプルコードの処理は①1/4サイズの画像と空画像を作成、②左上と右下に画像を張り付け(boxは2種類のやり方で処理)しました。

[IN]
from PIL import Image
path_imgfile = 'konan.JPG' # 元画像ファイル
img = Image.open(path_imgfile) #PIL形式で開く
img_quater=img.resize((int(img.width/2), int(img.height/2))) #オリジナルの1/4サイズ
dst = Image.new('RGB', (img.width , img.height)) # オリジナル画像と同じサイズ
dst.paste(img_quater, (0, 0)) #左角(0,0)を起点に画像を貼り付ける
dst.paste(img_quater, (int(img.width/2), int(img.height/2), int(img.width), int(img.height))) #右下側に張り付ける
dst
[OUT]
2-5.ファイルの保存(img.save())
ファイルの保存はimg.save('ファイルのパス')です。拡張子を変更することでJPG, PNG, PDFなどの形式で保存ができます。
[In]
img_BW = img_PIL.convert('1')
img_BW.save('konan_shirokuro.png') #ファイルと同じディレクトリに保存
3.画像の色情報(RGB)の処理
概要だけ説明すると「光の3原色」というルールがあり色はRed, Green, Blueから構成されており、写真の画像データもRGBの3次元データから構成されております。確認としてimageデータをnumpyの配列に変えてみると3次元であることがわかります。
[In]
import numpy as np
np.array(img_PIL).shape
[Out]
(648, 484, 3)3-1.RGB情報の分離:img.split()
PillowではこのRGBの各値を取得したり入れ替えたりすることができます。まず画像からRGB情報を分離するのはsplit()メソッドを使用します。
[IN]
r,g,b = img_PIL.split() #3次元のRGBを分離
print(r, r.size, r.mode, r.format)
print(g, g.size, g.mode, g.format)
print(b, b.size, b.mode, b.format)
[OUT]
<PIL.Image.Image image mode=L size=484x648 at 0x1A7E5820520> (484, 648) L None
<PIL.Image.Image image mode=L size=484x648 at 0x1A7E5928970> (484, 648) L None
<PIL.Image.Image image mode=L size=484x648 at 0x1A7E5928AC0> (484, 648) L None3-2.RGBの結合:img.merge()
画像情報の結合はmerge()メソッドを使用します。前述のsplit()で分離した情報をmergeで入れ替えることでRGB->BGRの変換が可能です。
[In]
r,g,b = img_PIL.split() #3次元のRGBを分離
imgbgr_PIL = Image.merge("RGB", (b,g,r)) #RGBをBGRに変換
imgbgr_PIL
こちらでは赤と青の色が反転しております。
4.画像加工1:形状加工
4-1.白黒・グレー変換:convert()
白黒・グレー変換はそれぞれconvertメソッドで変換可能です。なおJupyterに直接ではなくViewerで表示させるのであれば img.show()となります。
[In]
img_PIL.convert('1').show() #白黒
img_PIL.convert('L').show() #グレー※輝度=0.299×R+0.587×G+0.114×B
白黒は文字通り白と黒のドットだけで構成されます。

4-2.反転・回転:transpose()
画像加工はimg.transpose(メソッド設定)で実施可能です。条件は複数ありますので結果は出力でご確認ください。
[In]
import matplotlib.pyplot as plt
names =['Image.FLIP_LEFT_RIGHT','Image.FLIP_TOP_BOTTOM','Image.ROTATE_90','Image.ROTATE_180','Image.ROTATE_270']
methods = [Image.FLIP_LEFT_RIGHT,
Image.FLIP_TOP_BOTTOM,
Image.ROTATE_90,
Image.ROTATE_180,
Image.ROTATE_270]
fig = plt.figure(figsize=(18,12))
for idx, _ in enumerate(zip(methods,names)):
method, name = _ #zipから値を取り出す
img_edit = img_PIL.transpose(method)
ax = fig.add_subplot(1,5, idx+1)
ax.imshow(img_edit)
ax.set_title(name)
plt.axis('off') #軸を消す 
4-3.リサイズ:resize(Tuple)
画像のサイズ変更はimg.resize((Width, Height))となります。固定値を入れるとオリジナルから縦横比が分かりますので注意が必要です。
[In]
img_resize = img_PIL.resize((200, 200)) #リサイズ
print(img_resize.size)
img_resize
なおresize時の画像補完(処理)の引数としてresampleがありますが、詳細は下記記事が参考になります。
5.画像加工2
5-1.テキスト追加:ImageDraw()
画像に文字を追加する場合は”ImageDraw”を使用します。
[IN]
from PIL import Image, ImageDraw, ImageFont
#画像を開く
path_img = 'konan.JPG'
img = Image.open(path_img) #PIL形式で開く
#テキストの条件設定
draw = ImageDraw.Draw(img)
print(draw)
text = 'ここにテキストを入力'
font = ImageFont.truetype('C:\Windows\Fonts\meiryo.ttc', 30) #フォントの指定, font_size=30
textwidth, textheight = draw.textsize(text, font) #テキストのサイズを取得
#テキストの位置を設定
width_img, height_img = img.size #画像のサイズを取得
print(f'textwidth:{textwidth}, textheight:{textheight}, width_img:{width_img}, height_img:{height_img}')
x = width_img/2 - textwidth/2 #テキストのx座標
y = height_img - textheight -50 #テキストのy座標
draw.text((x,y), text, font=font) #テキストを描画
img
[OUT]
<PIL.ImageDraw.ImageDraw object at 0x0000023E78BE9A30>
textwidth:300, textheight:34, width_img:484, height_img:648
6.拡張子の変更
6-1.拡張子変換(png↔jpg):img.convert
"img.convert('RGB')"無しでも問題ないはずですが参考までに
[IN]
from PIL import Image
path_img = 'konan.JPG'
img = Image.open(path_img) #PIL形式で開く
img.save('konan.png') #png形式で保存
[OUT]
Day 125 : png to jpg using python https://t.co/Bf2toV6LeQ pic.twitter.com/WnlUY07IGG
— Python Coding (@clcoding) October 16, 2022
6-2.PDF作成(jpg/png->pdf):
画像保存:img.save()の拡張子をPDFに設定すれば対応可能です。
[IN]
from PIL import Image
path_img = 'konan.JPG'
img = Image.open(path_img) #PIL形式で開く
img.save('konan.pdf')
[OUT]
複数の画像をまとめてPDF化する場合は①ファイルパスをリスト化、②空リストの中に画像を追加、③リストをまとめてPDF化します。
[IN]
import glob
from PIL import Image
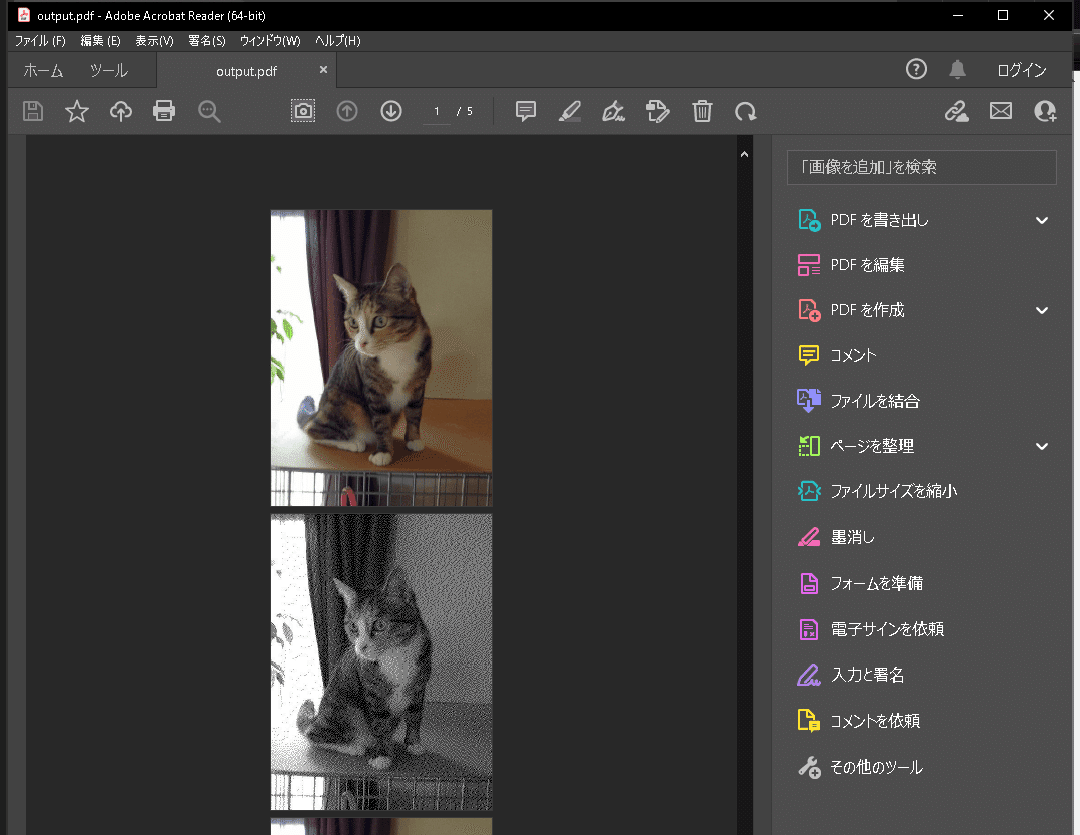
def Images_to_PDF(path_imgs, path_pdf='output.pdf'):
images = [] #画像を格納するリスト
for path_img in path_imgs:
img = Image.open(path_img)
img = img.convert('RGB') #カラーモードをRGBに変換
images.append(img)
images[0].save(path_pdf, save_all=True, append_images=images[1:])
filepaths = glob.glob('*.png')+glob.glob('*.jpg') #png+jpg形式のファイルを取得
print(filepaths)
Images_to_PDF(filepaths) #PDFに変換※ファイル名はoutput.pdf
[OUT]
['konan.png', 'konan_shirokuro.png', 'konan.JPG', 'konan_jpg.jpg', 'note見出し_ライブラリ.jpg']
7.予備章
8.その他処理
8-1.スクリーンショット:ImageGrab.grab()
画面のスクリーンショットはImageGrab.grab()で取得可能です。
[IN]
from PIL import ImageGrab
img_screen = ImageGrab.grab()# スクリーンショット取得
img_screen
[OUT]
画面が確認できます8-2.画像の圧縮:img.save()
画像の圧縮は画像の保存時にqualityなどの引数を指定します。元の画像サイズが小さいと圧縮時に画質が低下するため注意が必要です。
[IN]
from PIL import Image
path_imgfile = 'konan.JPG'
img = Image.open(path_imgfile) #PIL形式で開く
#画像を圧縮して保存
img.save("konan_comp.jpg",
format="JPEG", #フォーマット
optimize=True, #最適化
quality=5) #qualityは0~100の整数で指定
[OUT]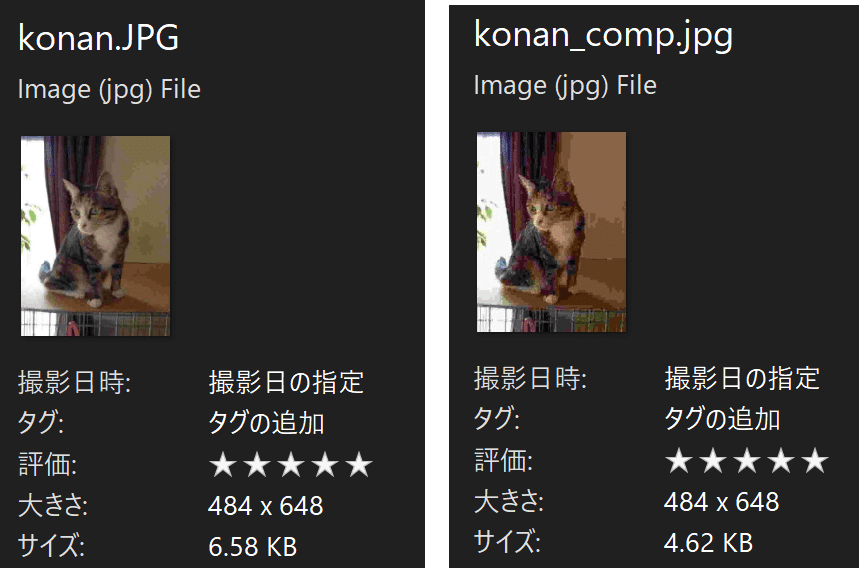
9.Pillowでやってみた1
9-1.ファイルをまとめて圧縮
職場あるあるで画像を圧縮して保存しようというのがありますが、Pillowで一括処理してみましょう。
※ここでは1つのファイルだけ処理しましたがfor文ですのでパス内に画像があれば複数処理します。
[In]
import glob, os #ファイル操作
#resizeフォルダがなければ作成
if not os.path.exists('resize'):
os.mkdir('resize')
#Pillowで等倍数でリサイズ
def imgresize(dividesize: int, imgfiles: list):
for imgfile in imgfiles:
img = Image.open(imgfile) #PIL形式で開く
img_resize = img.resize((int(img.width/dividesize), int(img.height /dividesize))) #リサイズ
_, extension = os.path.splitext(imgfiles[0]) #拡張子を取得
img_resize.save(f'resize/{os.path.basename(imgfile)[:-4]}_resize{extension}') # ファイル名を書き換える
imgfiles = glob.glob('./*.jpg') #output->['.\\konan.JPG']
imgresize(2, imgfiles) #1/2倍にリサイズ
念のためにサイズチェックもしました。
[In]
print('オリジナルファイルサイズ',Image.open('konan.JPG').size)
print('リサイズ(1/2)後サイズ', Image.open('resize/konan_resize.JPG').size)
[Out]
オリジナルファイルサイズ (484, 648)
リサイズ(1/2)後サイズ (242, 324)9-2.ぼかし・モザイク
Imageデータはそれぞれのドットの色を3次元の数値で構成されています。ファイルの圧縮はそれらの数値を平均化しており、それを拡大すると平均化された数値が使用されるため解像度が落ちます。論より証拠は下記の通り。
[In]
import matplotlib.pyplot as plt
import japanize_matplotlib
def imageblur(img, resolution: float):
width, height = img.size #imgのオリジナルサイズ(幅・寸法を記憶)
img_resize = img.resize((int(img.width/resolution), int(img.height /resolution))) #縮小
img_blur = img_resize.resize((width, height)) #オリジナルサイズの戻す
return img_blur
fig = plt.figure(figsize=(18,12))
for num in range(1,11):
img_edit = imageblur(img=img_PIL, resolution=num)
ax = fig.add_subplot(2,5, num)
ax.imshow(img_edit)
ax.set_title(f'{num}倍でぼかし変換', fontSize=16)
plt.axis('off') #軸を消す
plt.tight_layout()
全体ではなく部分的に抽出して大きく平均化したらモザイクも可能です。
(なぜかimg.sizeのwidthとheightが逆になった気がするが動いたからヨシ!)
[In]
import matplotlib.pyplot as plt
import japanize_matplotlib
from typing import List, Tuple
def getimagearea(img, size: int) -> Tuple:
height,width = img.size #imgのオリジナルサイズ(幅・寸法を記憶)
width_r, height_r = int(width/size), int(height/size)
x_start = int(width/size-width_r/2)
x_end = x_start + width_r
y_start = int(height/size-height_r/2)
y_end = y_start + height_r
return x_start, x_end, y_start, y_end
def imagemosaic(img, resol: float):
img_array = np.array(img_PIL)
x_start, x_end, y_start, y_end = getimagearea(img=img_PIL, size=2)
img_array_mosaic = img_array[x_start:x_end, y_start:y_end] #mosaicのエリアを抽出
width, height, _ = img_array_mosaic.shape
width_count, height_count = int(width/resol), int(height/resol)
for i in range(width_count):
for j in range(height_count):
mosaicarray = img_array_mosaic[resol*i:resol*i+resol, resol*j:resol*j+resol]
mean = mosaicarray.mean()
mosaicarray= np.where(mosaicarray==0, mean, mean)
img_array_mosaic[resol*i:resol*i+resol, resol*j:resol*j+resol] = mosaicarray
print(x_start, x_end, y_start, y_end)
img_array[x_start:x_end, y_start:y_end] = img_array_mosaic
return img_array
fig = plt.figure(figsize=(18,12))
for num in range(1,11):
img_edit = imagemosaic(img=img_PIL, resol=num)
ax = fig.add_subplot(2,5, num)
ax.imshow(img_edit)
ax.set_title(f'{num}倍でモザイク変換', fontSize=16)
plt.axis('off') #軸を消す
plt.tight_layout()
10.Pillowでやってみた2:画像の結合
複数のファイルをまとめて結合したいと思います。サンプル画像は下記サイトから適当に取得しました。
【処理プロセス】
●結合したいファイルを選択
●画像をリスト化して2次元構造に変換する:幅方向用と列方向処理用に分ける
●画像の最小高さを取得して幅方向に画像を結合する
●幅方向に結合した画像同士を列方向に結合する
10-1.画像データリストの2次元化
幅方向用と列方向用で処理を分けるためリストを2次元化します。処理として①globで処理ファイルを一括取得、②Image.open()でPILデータ取得、③関数を使用して2次元化 します。
③の関数の動作イメージは下記の通りです。
[IN ※参考用]
a = [1,2,3,4,5,6,7,8]
def make2dimlist(data, w, h):
return [data[i:i+w] for i in range(0, len(data), w)]
print('(2,4):', make2dimlist(a, 2,4))
print('(1,8):', make2dimlist(a, 1,8))
print('(8,1):', make2dimlist(a, 8,1))
[OUT]
(2,4): [[1, 2], [3, 4], [5, 6], [7, 8]]
(1,8): [[1], [2], [3], [4], [5], [6], [7], [8]]
(8,1): [[1, 2, 3, 4, 5, 6, 7, 8]]今回用の処理では下記の通りとなります。
[IN]
from PIL import Image
import matplotlib.pyplot as plt
import glob
def make2dimlist(data, w, h):
return [data[i:i+w] for i in range(0, len(data), w)]
imgfiles = glob.glob('sampleimages/*.jpg') #ファイルパス取得
imgs = [Image.open(i) for i in imgfiles] #PIL形式で開く
print([img.size for img in imgs]) #画像サイズを表示
img_2dim = make2dimlist(imgs, 2, 4) #2行4列の結合画像を作成予定
img_2dim
[OUT]
[(640, 427), (640, 427), (640, 427), (640, 427), (640, 427), (640, 427), (640, 427), (640, 427), (511, 340)]
[[<PIL.JpegImagePlugin.JpegImageFile image mode=RGB size=640x427 at 0x1A7E5957A00>,
<PIL.JpegImagePlugin.JpegImageFile image mode=RGB size=640x427 at 0x1A7E578AAF0>],
[<PIL.JpegImagePlugin.JpegImageFile image mode=RGB size=640x427 at 0x1A7E57FB940>,
<PIL.JpegImagePlugin.JpegImageFile image mode=RGB size=640x427 at 0x1A7E57B7160>],
[<PIL.JpegImagePlugin.JpegImageFile image mode=RGB size=640x427 at 0x1A7E57FBA00>,
<PIL.JpegImagePlugin.JpegImageFile image mode=RGB size=640x427 at 0x1A7E5858D90>],
[<PIL.JpegImagePlugin.JpegImageFile image mode=RGB size=640x427 at 0x1A7E5858C10>,
<PIL.JpegImagePlugin.JpegImageFile image mode=RGB size=640x427 at 0x1A7E5858E20>]]10-2.幅方向(Horizontal)への結合
次は画像を幅方向に結合する関数を作成します。処理としては①画像内の最小高さを取得、②最小高さに合わせて画像をresize、③幅方向の合計値を算出して(合計幅, 最小高さ)の空画像を作成、④各画像をpaste していきます。
[IN]
def mergeimg_h(imgs: List, resample=Image.BICUBIC) -> Image:
min_height = min(im.height for im in imgs) #画像リスト内での最小の高さ
imgs_resize = [im.resize((int(im.width * min_height / im.height), min_height),resample=resample) for im in imgs] #画像リスト内での最小の高さに合わせてリサイズ
total_width = sum(im.width for im in imgs_resize) #リサイズ後の画像の幅の合計
dst = Image.new('RGB', (total_width, min_height)) #画像リスト内での最小の高さに合わせて新しい画像を作成
pos_x = 0 #x座標
for im in imgs_resize:
dst.paste(im, (pos_x, 0))
pos_x += im.width
return dst
mergeimg_h(img_2dim[0])
[OUT]
10-3.列方向(Vertical)への結合
前節と同じ処理を縦方向にします。
[IN]
def mergeimg_v(imgs: List, resample=Image.BICUBIC) -> Image:
min_width = min(im.width for im in imgs) #画像リスト内での最小の幅
imgs_resize = [im.resize((min_width, int(im.height * min_width / im.width)),resample=resample) for im in imgs] #画像リスト内での最小の幅に合わせてリサイズ
total_height = sum(im.height for im in imgs_resize) #リサイズ後の画像の高さの合計
dst = Image.new('RGB', (min_width, total_height)) #画像リスト内での最小の幅に合わせて新しい画像を作成
pos_y = 0 #y座標
for im in imgs_resize:
dst.paste(im, (0, pos_y))
pos_y += im.height
return dst
img_w1 = mergeimg_h(img_2dim[0])
img_w2 = mergeimg_h(img_2dim[1])
mergeimg_v([img_w1, img_w2])
[OUT]
10-4.完成コード
最後に縦と横方向の結合をまとめてできる関数を追加したら完成です。
[IN]
from PIL import Image
import matplotlib.pyplot as plt
import glob
from typing import List
def make2dimlist(data, w, h):
return [data[i:i+w] for i in range(0, len(data), w)]
def mergeimg_h(imgs: List, resample=Image.BICUBIC) -> Image:
min_height = min(im.height for im in imgs) #画像リスト内での最小の高さ
imgs_resize = [im.resize((int(im.width * min_height / im.height), min_height),resample=resample) for im in imgs] #画像リスト内での最小の高さに合わせてリサイズ
total_width = sum(im.width for im in imgs_resize) #リサイズ後の画像の幅の合計
dst = Image.new('RGB', (total_width, min_height)) #画像リスト内での最小の高さに合わせて新しい画像を作成
pos_x = 0 #x座標
for im in imgs_resize:
dst.paste(im, (pos_x, 0))
pos_x += im.width
return dst
def mergeimg_v(imgs: List, resample=Image.BICUBIC) -> Image:
min_width = min(im.width for im in imgs) #画像リスト内での最小の幅
imgs_resize = [im.resize((min_width, int(im.height * min_width / im.width)),resample=resample) for im in imgs] #画像リスト内での最小の幅に合わせてリサイズ
total_height = sum(im.height for im in imgs_resize) #リサイズ後の画像の高さの合計
dst = Image.new('RGB', (min_width, total_height)) #画像リスト内での最小の幅に合わせて新しい画像を作成
pos_y = 0 #y座標
for im in imgs_resize:
dst.paste(im, (0, pos_y))
pos_y += im.height
return dst
def mergeimgs(imgs: List, resample=Image.BICUBIC) -> Image:
imgs_horizontal = [mergeimg_h(imgs_h, resample=resample) for imgs_h in imgs]
return mergeimg_v(imgs_horizontal, resample=resample)
imgfiles = glob.glob('sampleimages/*.jpg') #ファイルパス取得
imgs = [Image.open(i) for i in imgfiles] #PIL形式で開く
img_2dim = make2dimlist(imgs, 2, 4) #2行4列の結合画像を作成予定
mergeimgs(img_2dim, resample=Image.BICUBIC)
[OUT]

11.Pillowでやってみた3:画像の結合Ver.2
前章より美しいコードがあったため下記記事をそのまま参照しました。
手順はシンプルに①画像パス取得(List)、②PILで画像データ取得してリスト化(コードは内包表記で処理)、③image_grid関数を実行です。
[IN]
from PIL import Image
import glob
def image_grid(imgs, rows, cols):
assert len(imgs) == rows*cols #画像の枚数がrows*colsと一致するか確認
w, h = imgs[0].size #画像のサイズを取得
grid = Image.new('RGB', size=(cols*w, rows*h)) #新しい画像を作成
grid_w, grid_h = grid.size #新しい画像のサイズを取得
for i, img in enumerate(imgs):
grid.paste(img, box=(i%cols*w, i//cols*h)) #画像を貼り付ける
return grid
# ファイルパス取得
path_imgs = glob.glob('sampleimages/*.jpg')
print(len(path_imgs), path_imgs) #ファイルパス取得
path_imgs = path_imgs[:8] #8枚のみ
# 画像読み込み
images = [Image.open(path) for path in path_imgs] #PIL形式で開く
print(images)
#画像の表示
grid = image_grid(images, rows=4, cols=2) #2行4列の結合画像を作成
grid
あとがき
公式ドキュメントを見るとPillowも奥が深かった・・・とりあえず自分が使ってた分だけ書き出したけど、まだまだ書きたいこと多いw
=>PILはJPEGは簡単だけどPNGがなんかしんどかった気がする
=>写真イメージを縦横にくっつけるやつもすぐ忘れるから追加したい。