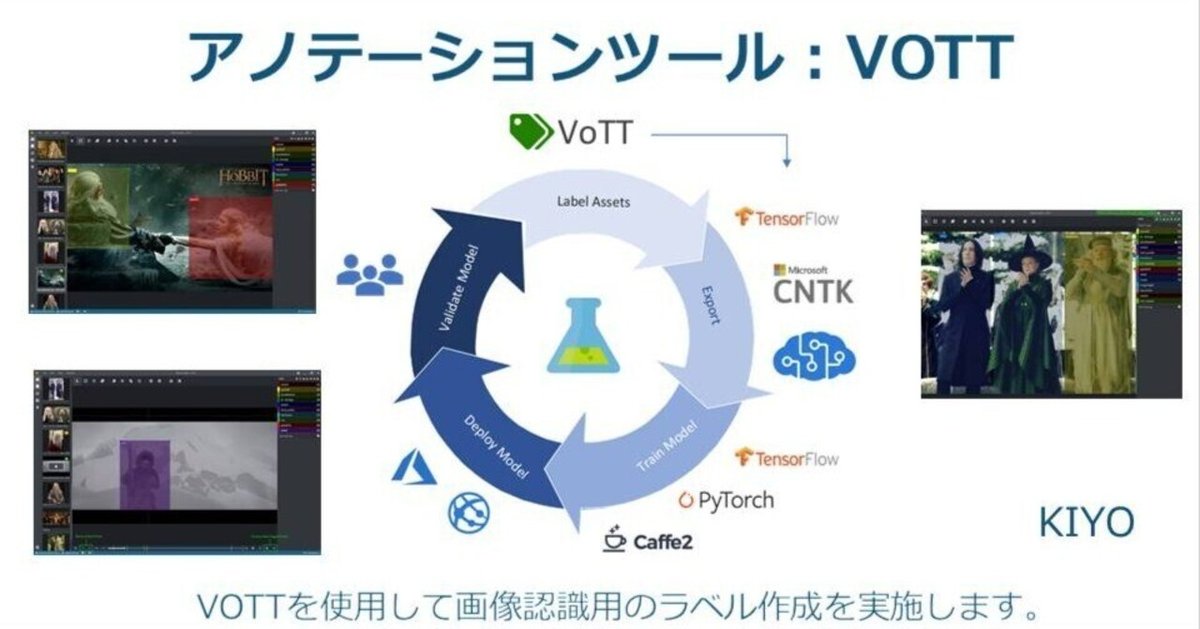
アノテーションツール:VOTT

1.概要
画像認識、物体検出は教師あり学習のため画像データと合わせてラベルデータ(正解データ)が必要であり、ラベルには座標情報が必要となります。
今回は下記のYOLOv5用にアノテーションを実施してラベルデータを作成しました。
1-1.アノテーションツールの紹介
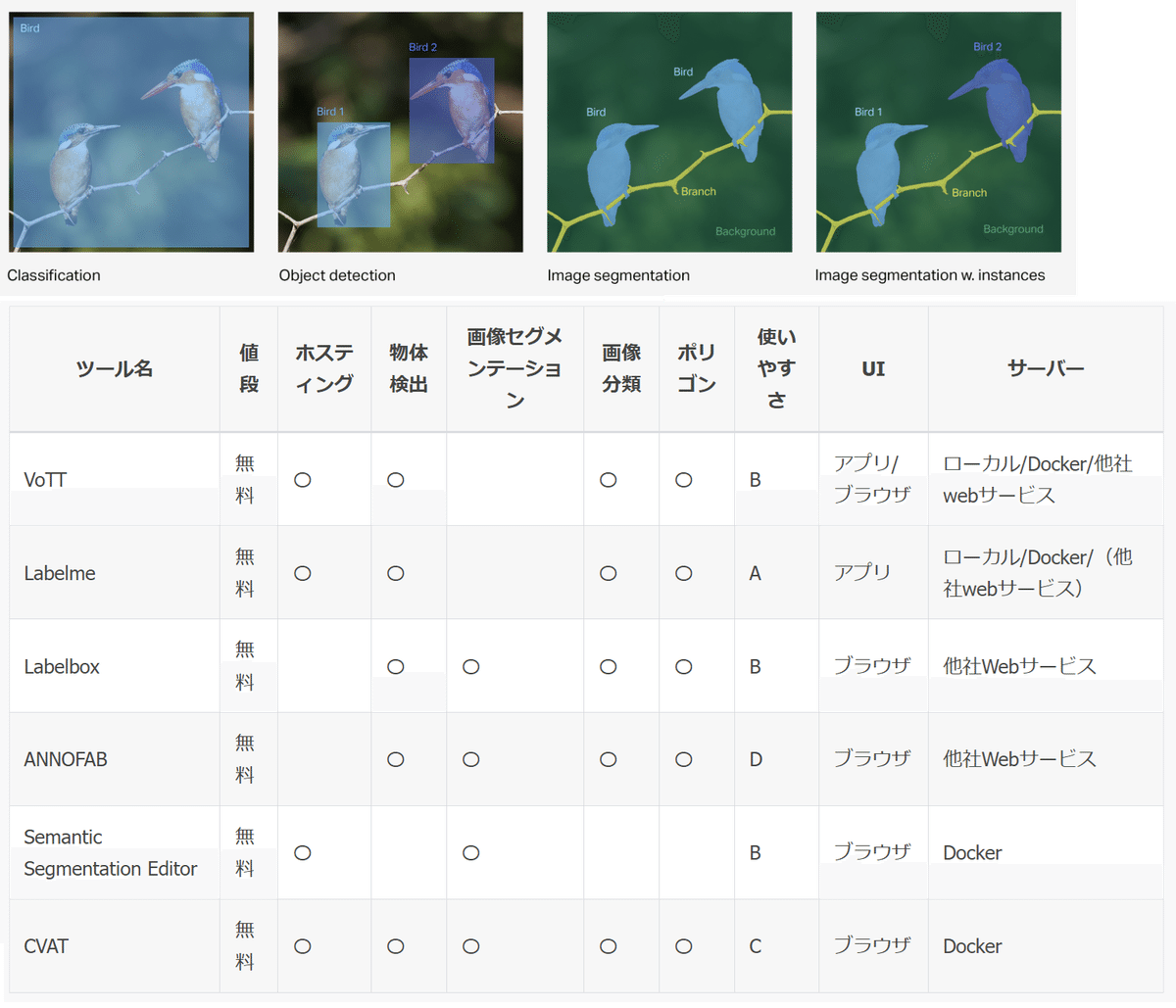
アノテーションツールは複数あり用途、価格、使いやすさで選定します。VoTTは、画像セグメンテーションはできませんが、無料であり物体検出は可能なため今回はこちらを利用しました。
2.YOLOv5のアノテーション情報
下記を参照しておりますので詳細は記事でご確認ください。
アノテーションのポイントは画像サイズに対する相対比として作成する必要があり"分類クラス x座標 y座標 幅 高さ"の順で記載します。
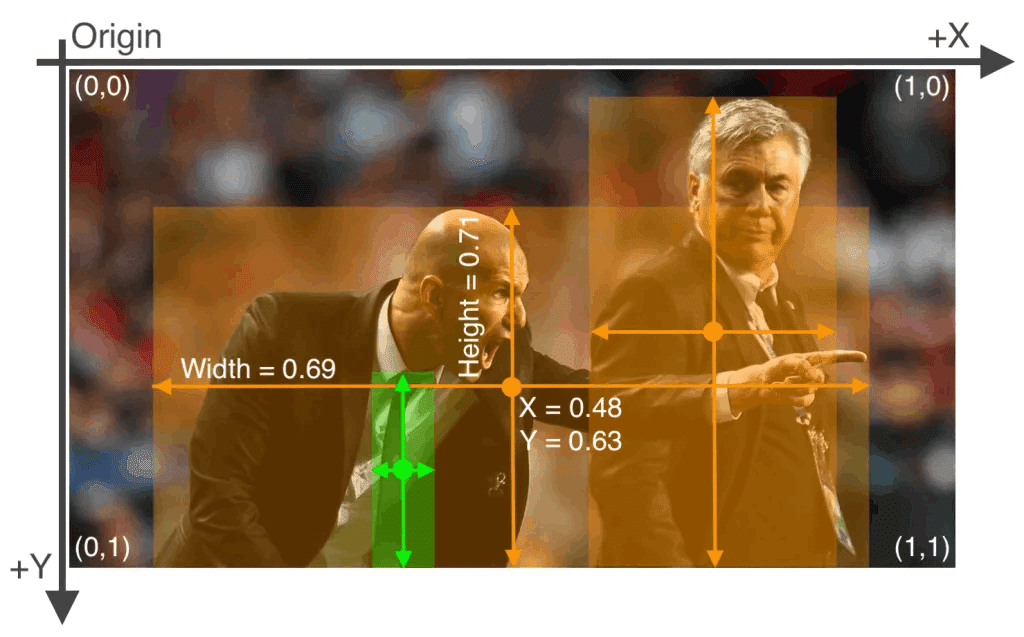
[ラベルのサンプル ※[oject-class] [x_center] [y_center] [width] [height]]
0 0.480000 0.630000 0.690000 0.710000
0 0.740000 0.520000 0.310000 0.930000
27 0.360000 0.790000 0.070000 0.400000【ラベルの意味】
●oject-class:クラスの番号。yamlファイルの内容と合わせる
●x_center:bounding box 中心のx座標
●y_center:bounding box 中心のy座標
●width:bounding box x方向長さ
●height:bounding box y方向長さ
3.VOTTの環境構築・セットアップ
アノテーションをGUIで実施できるツールのVOTTを使用して自作ラベルを作成します。下記記事をベースに躓いた点だけサクッと記載します。
3-1.VOTTアプリをインストール
まず初めに「GitHub:microsoft/VoTT」から(Windowsユーザーなので)exeファイルをダウンロードして実行します。
3-2.フォルダ・画像の準備
作業フォルダと画像を用意します。画像データはVOTTが自動認識するため先にフォルダに配置しておきます。

3-3.VOTTのセットアップ
VOTTのセットアップの流れは下記の通りです。
【VOTTセットアップの流れ】
●接続設定
●プロジェクト設定
●アクティブラーニング:学習済みモデルを使った予測設定
●エクスポート設定:出力情報の設定
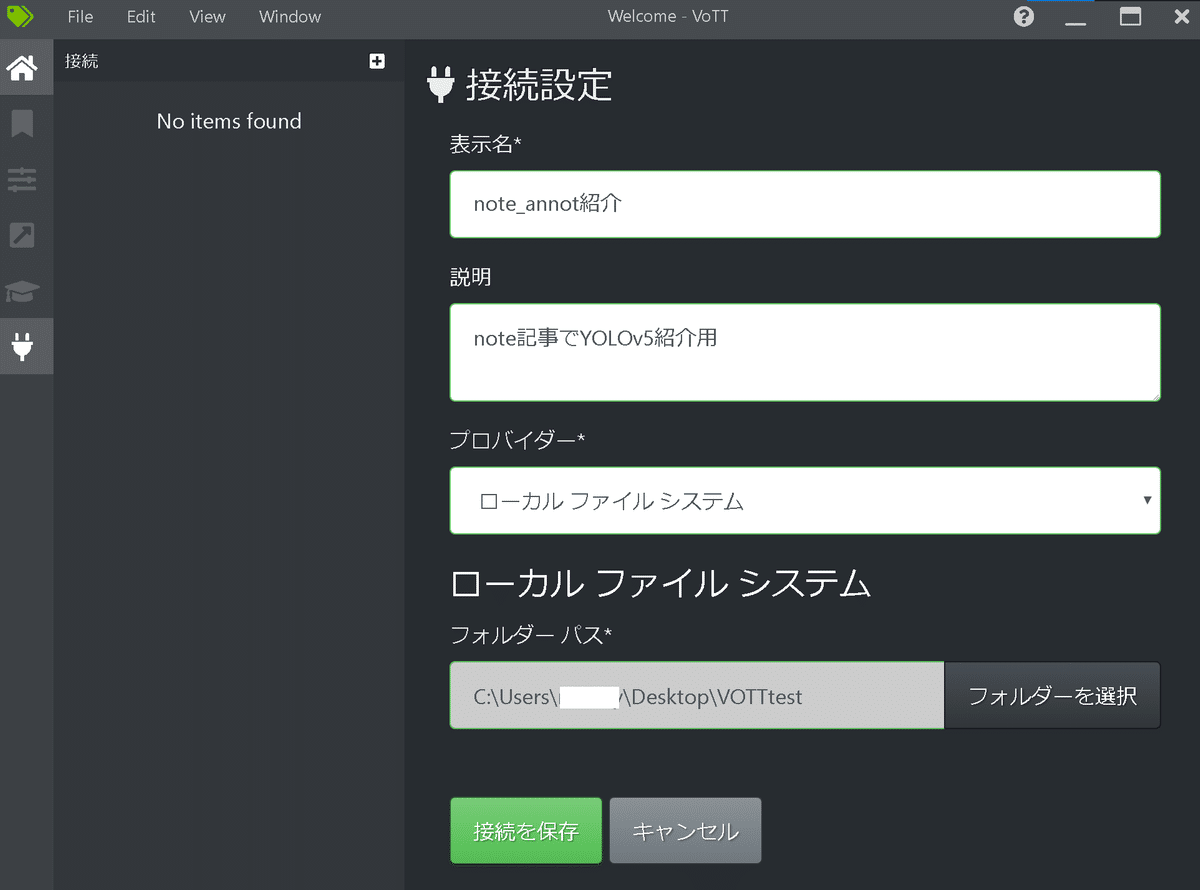
【接続設定】
下記赤枠を押して接続設定に移動して、必要な情報を埋めます。
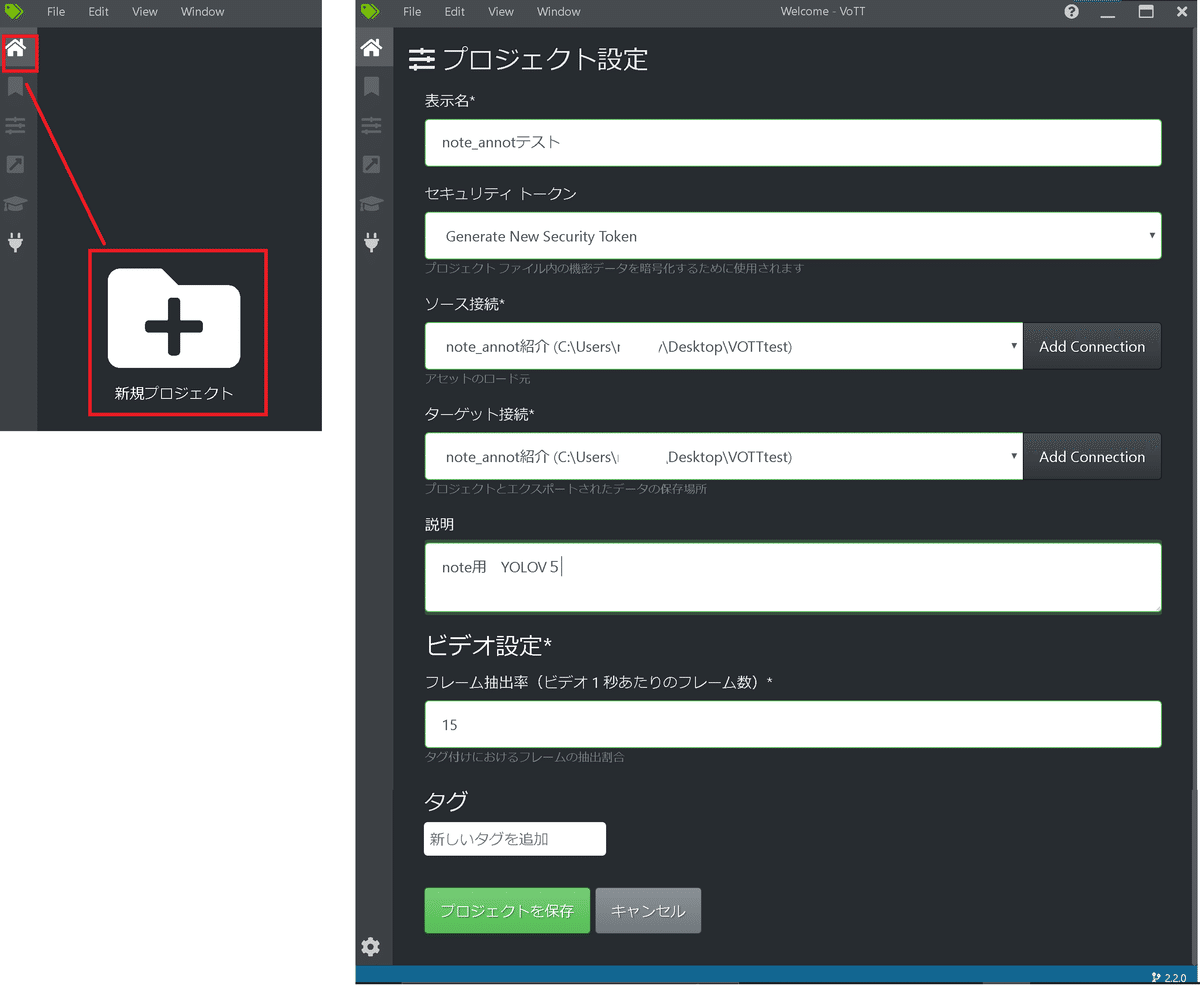
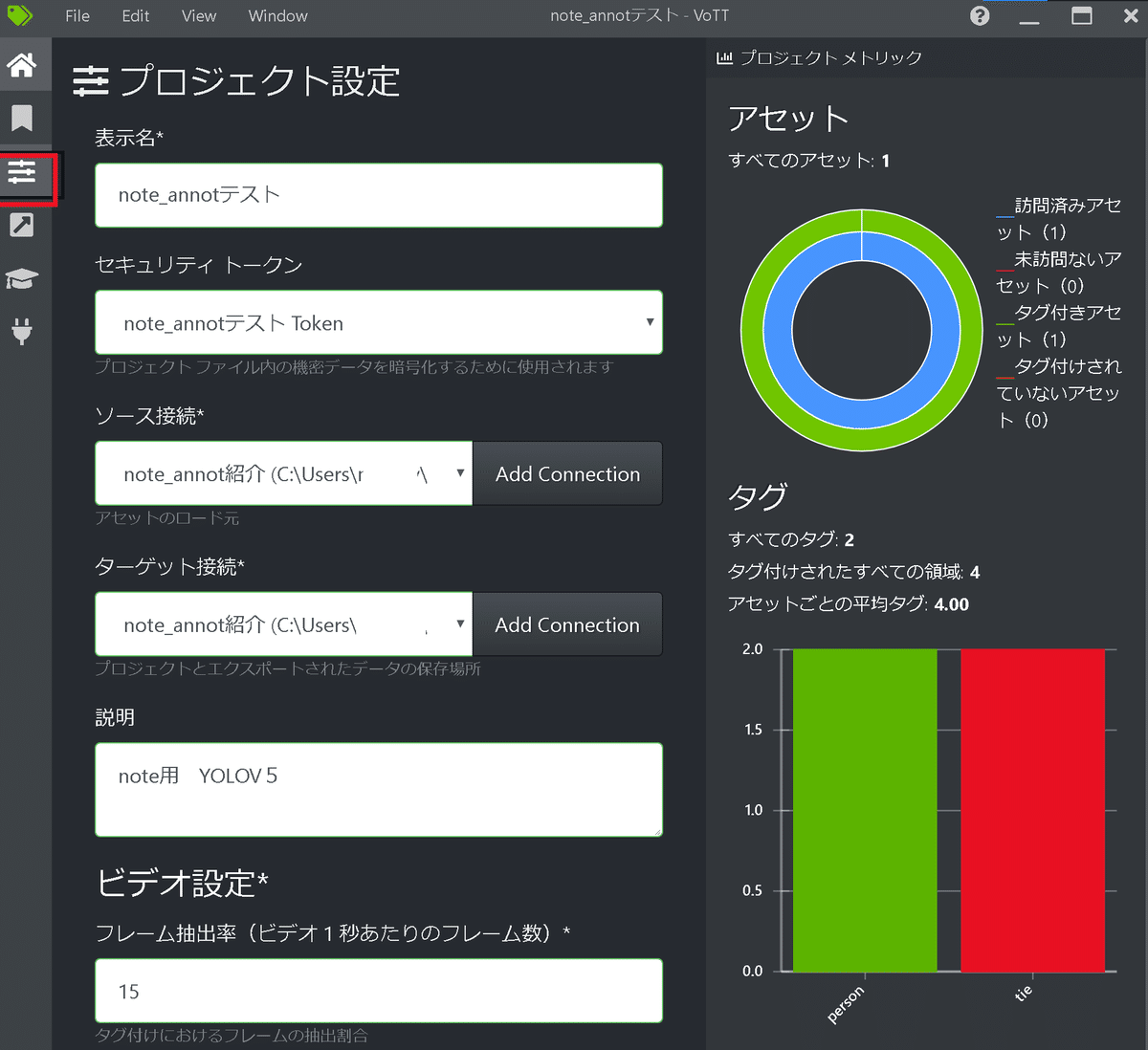
【プロジェクト設定】
「ホーム」->「新規プロジェクト」からプロジェクト設定情報を入力
※"ソース接続(画像データ)"と"ターゲット接続(出力先)"は前の接続設定から選択可能
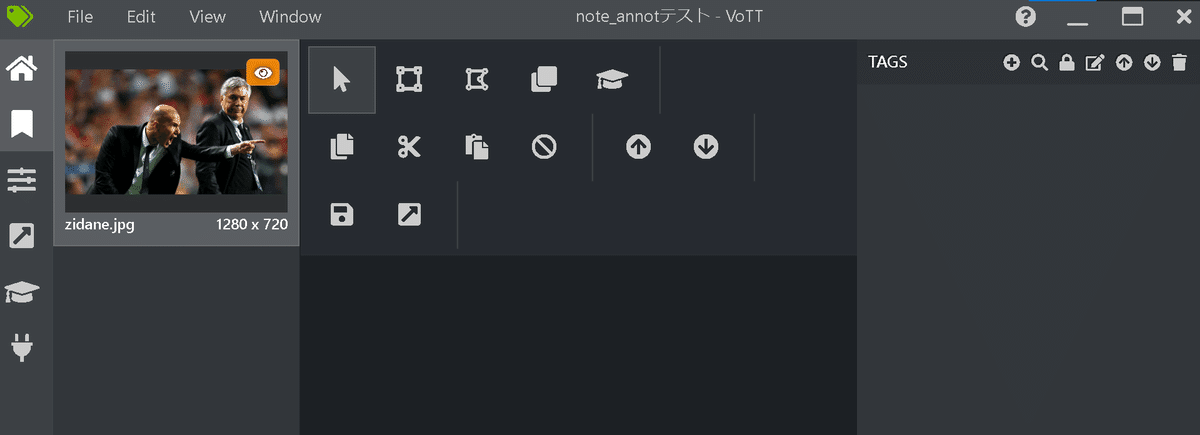
プロジェクト保存を押すと下記のような画面に移動しました。ソース接続先に保存している画像が左のプレビューに表示されていれば成功です。
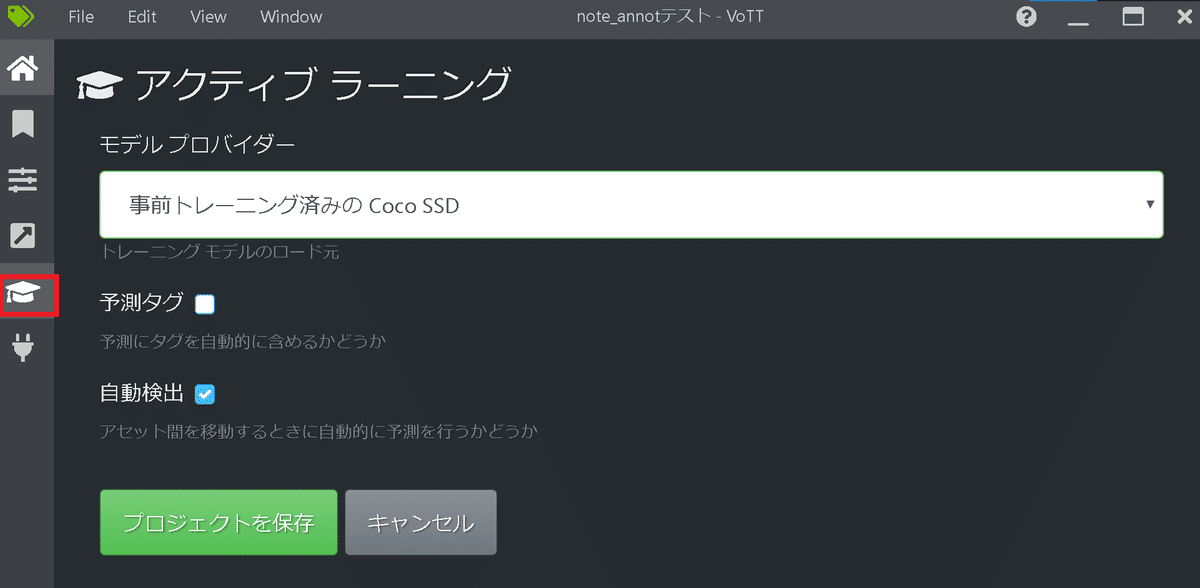
【アクティブラーニング:学習済みモデルを使った予測設定】
下記アイコンを選択しておきます。
【エクスポート設定】
出力ラベルデータの形式を選択します。YOLOの形式は"Pascal VOC"が良いらしいです。
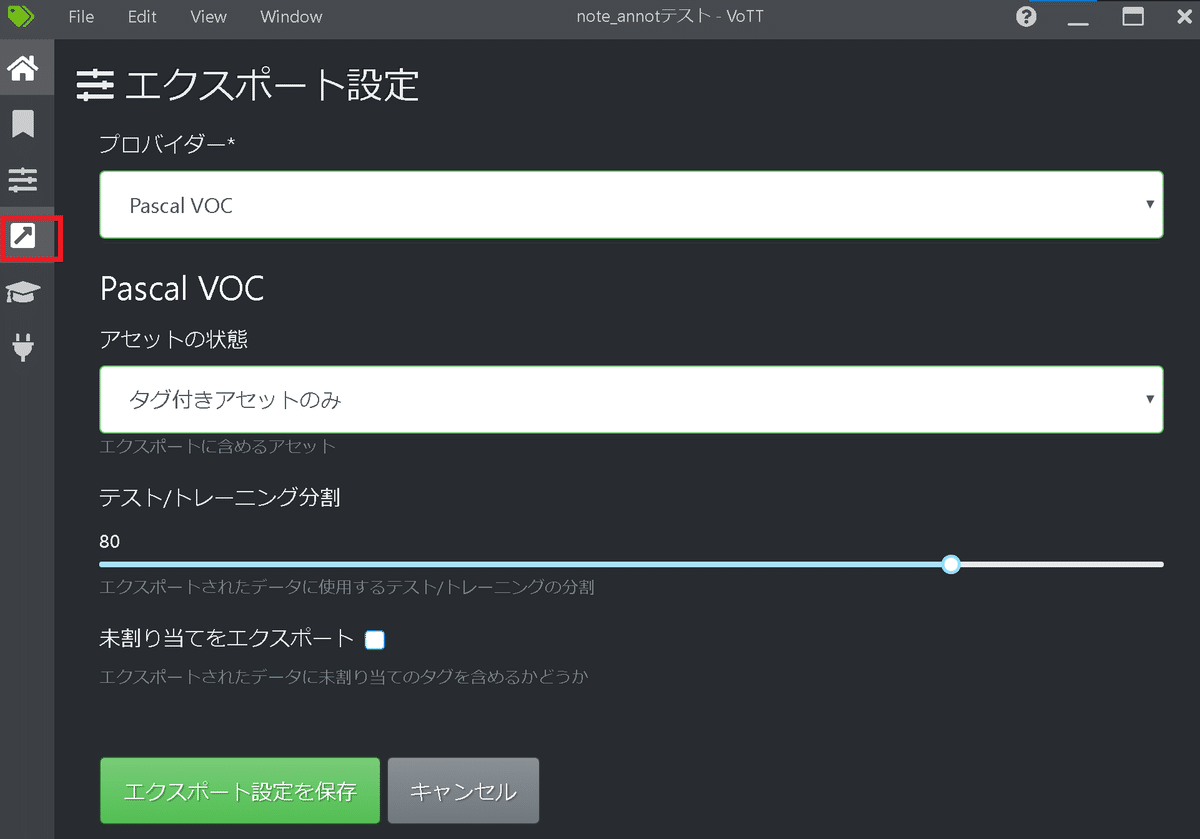
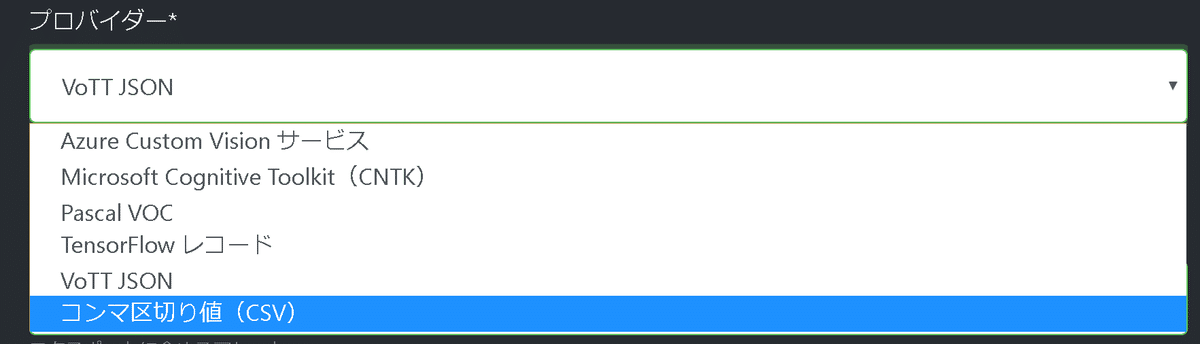
なお他の出力形式は下記の通りです。
4.アノテーションの実施
4-1.ラベル付け
設定が完了したら実際にアノテーションを実施します。処理の流れおよび操作は下記の通りです。
【アノテーションの流れ】
●タグ名の設定:右に数値が出てきますが出力結果には出ないため注意
●座標の設定:アイコンで長方形とポリゴン(多角形)を選択可能
●タグ付け:座標設定後にタグをクリックすると選択可能

なおタグ付け後は”プロジェクト設定”に移動するとアノテーションの結果を確認することが出来ます。
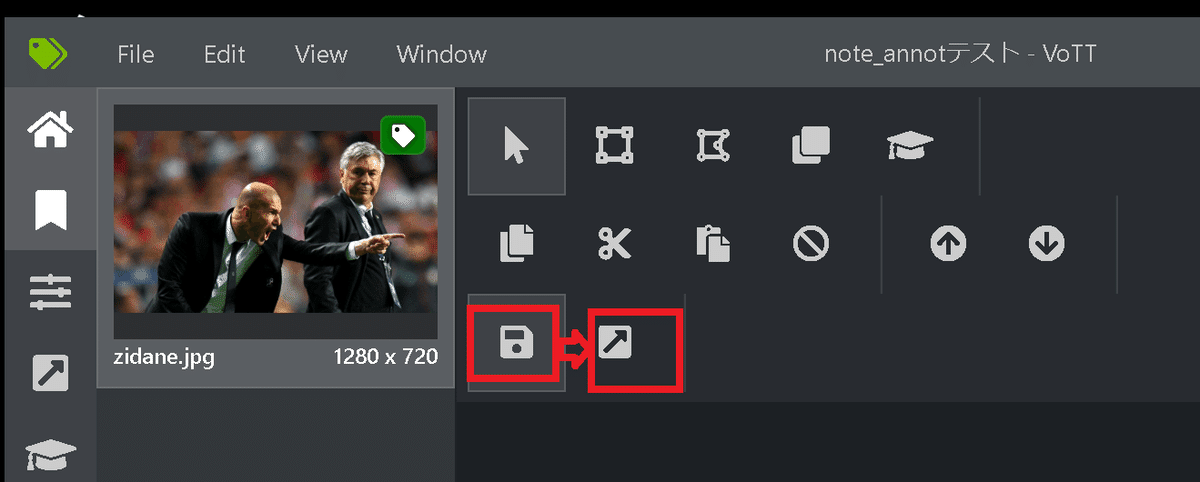
今回の最終出力は下記のようにしました。

4-2.結果の出力
結果の出力は左枠の「プロジェクトの保存」を押した後に「プロジェクトをエクスポート」を押します。
しばらくするとexportフォルダとjsonファイルが出力されました。(JSONファイルの出力が安定しないですが・・・)
JSONファイルの中身を確認すると下記の通り座標情報が入っておりますが、下記の注意点があり、YOLOv5のラベルにはそのまま使用できません。
【出力情報の注意点】
●タグ名はあるがラベル値がない
●位置情報が絶対値で入力されている。

5.PythonでYOLOv5用のラベルに変更
下記のような出力を目指してラベルを作成していきます。
[ラベルのサンプル ※[oject-class] [x_center] [y_center] [width] [height]]
0 0.480000 0.630000 0.690000 0.710000
0 0.740000 0.520000 0.310000 0.930000
27 0.360000 0.790000 0.070000 0.4000005-1.JSON解析
JSONは文字列型のため辞書型に変換したうえでデータを解析します。とりあえずJSONの中身を確認しました。
【出力形式】
●asset:画像データ情報
●regions:アノテーションの結果
●version:VOTTのVersion
[IN]
import glob
import json
files_json = glob.glob('*.json') #出力したラベル
file_json = files_json[0]
with open(file_json, 'r') as f:
text = f.read()
data_json = json.loads(text) #jsonを辞書に変換
print(type(text), type(data_json))
print(data_json.keys()) #データのキーを確認
data_json
[OUT]
<class 'str'> <class 'dict'>
dict_keys(['asset', 'regions', 'version'])
{'asset': {'format': 'jpg',
'id': 'bde31842d2b09ac2069d248101d3b22b',
'name': 'zidane.jpg',
'path': 'file:C:/Users/KIYO/Desktop/VOTTtest/zidane.jpg',
'size': {'width': 1280, 'height': 720},
'state': 2,
'type': 1,
'predicted': True},
'regions': [{'id': '1V2eVsX42',
'type': 'RECTANGLE',
'tags': ['person'],
'boundingBox': {'height': 504.70588235294116,
'width': 1036.6942148760331,
'left': 112.8374655647383,
'top': 204.70588235294116},
'points': [{'x': 112.8374655647383, 'y': 204.70588235294116},
{'x': 1149.5316804407714, 'y': 204.70588235294116},
{'x': 1149.5316804407714, 'y': 709.4117647058823},
{'x': 112.8374655647383, 'y': 709.4117647058823}]},
{'id': '_LlIXDVhB',
'type': 'RECTANGLE',
'tags': ['person'],
'boundingBox': {'height': 672.9902020622702,
'width': 394.93112947658403,
'left': 765.1790633608815,
'top': 47.00979793772978},
'points': [{'x': 765.1790633608815, 'y': 47.00979793772978},
{'x': 1160.1101928374655, 'y': 47.00979793772978},
{'x': 1160.1101928374655, 'y': 720},
{'x': 765.1790633608815, 'y': 720}]},
{'id': '5LHpGuH4F',
'type': 'RECTANGLE',
'tags': ['tie'],
'boundingBox': {'height': 288.57836555032173,
'width': 116.36363636363626,
'left': 416.08815426997245,
'top': 423.5294117647058},
'points': [{'x': 416.08815426997245, 'y': 423.5294117647058},
{'x': 532.4517906336088, 'y': 423.5294117647058},
{'x': 532.4517906336088, 'y': 712.1077773150275},
{'x': 416.08815426997245, 'y': 712.1077773150275}]}],
'version': '2.2.0'}regionsの結果を解析すると下記の通りです。よってtagsとboundingBoxを使えばラベルを作成できそうです。
【regionsのポイント】
●"tags"にはリスト形式でタグ情報が格納
●"boundingBox"は左上のx(left), y座標(top)とそこからの幅・高さが格納
●"points"は左上、右上、右下、左下の順(時計回り)でxy座標が格納
[IN]
regions = data_json['regions']
print(type(regions), len(regions), type(regions[0]['tags'])) #データ形式確認
print(regions[0].keys())
regions[0]
[OUT]
<class 'list'> 3 <class 'list'>
dict_keys(['id', 'type', 'tags', 'boundingBox', 'points'])
{'id': '1V2eVsX42',
'type': 'RECTANGLE',
'tags': ['person'],
'boundingBox': {'height': 504.70588235294116,
'width': 1036.6942148760331,
'left': 112.8374655647383,
'top': 204.70588235294116},
'points': [{'x': 112.8374655647383, 'y': 204.70588235294116},
{'x': 1149.5316804407714, 'y': 204.70588235294116},
{'x': 1149.5316804407714, 'y': 709.4117647058823},
{'x': 112.8374655647383, 'y': 709.4117647058823}]}5-2.タグ情報の作成
まずはタグにつけるIDを作成します。辞書型には下記の通り"if Key in 辞書"とするとKEYの有無を判別できます。
[IN]
testdic = {'a':1, 'b':2, 'c':3} #テスト用の辞書
if 'a' in testdic:print('a') #出力される
if 1 in testdic:print(1) #出力されない
[OUT]
a上記を参考にしてタグを作成しました。
[IN]
def make_tag2id(retions:dict):
output = {} #出力用の辞書
labelid = 0 #ラベルID
for region in regions:
tag = region['tags'][0]
#出力用の辞書作成
if not tag in output: #
output[tag] = labelid #IDの割り当て
labelid += 1 #次に割り当てるIDを1つ増やす
return output
tags = make_tag2id(regions)
print(tags)
[OUT]
{'person': 0, 'tie': 1}5-3.絶対座標を相対座標に変換
YOLOv5用の位置座標取得の手順は下記の通りです。
【位置情報取得】
1.左上の座標から幅と高さの半分の値を足す:長方形の中心位置の絶対座標を取得
2.取得した中心位置座標を画像の幅・高さ方向で割る:相対値取得
3.ラベルIDに合わせてデータを出力する
[IN ※次節で少しコード追加します]
from PIL import Image
def get_label(img, height, width, left, top):
width_img, height_img = img.size #画像のサイズを取得
#座標の絶対値を計算
x_move, y_move = width/2, height/2 #画像の中心を取得
x_abs = left + x_move #x座標:絶対値
y_abs = top + y_move #y座標:絶対値
#座標を相対比に変換
x_center = x_abs/width_img #x座標:相対値
y_center = y_abs/height_img #y座標:相対値
height_rel = height/height_img #高さ:相対値
width_rel = width/width_img #幅:相対値
return [x_center, y_center, height_rel, width_rel]
imgpath = 'zidane.jpg' #画像のパス
img = Image.open(imgpath) #画像を開く
for region in regions:
tagname = region['tags'][0] #タグ情報を取得
tag = tags[tagname] #タグIDを取得
keys_coord = ['height', 'width', 'left', 'top'] #座標情報のキー
height, width, left, top = [region['boundingBox'][key] for key in keys_coord] #座標を取得
data_coord = get_label(img, height, width, left, top)
labelinfo = [tag] + data_coord #タグIDと座標を結合
print(labelinfo)
[OUT]
[0, 0.49311294765840225, 0.6348039215686274, 0.7009803921568627, 0.8099173553719009]
[0, 0.7520661157024794, 0.5326456930123123, 0.9347086139753753, 0.3085399449035813]
[1, 0.3705234159779614, 0.788636936860926, 0.40080328548655797, 0.09090909090909083]ラベルサンプルが下記の通りですので問題ないと判断できます(元サンプルのtieのラベルは27)。
[ラベルのサンプル ※[oject-class] [x_center] [y_center] [width] [height]]
0 0.480000 0.630000 0.690000 0.710000
0 0.740000 0.520000 0.310000 0.930000
27 0.360000 0.790000 0.070000 0.4000005-4.テキストデータとして出力:完成コード
最後にYOLOv5の転移学習で使用できるようにテキストデータとして保存します。前のコードに下記を追加しました。
【追加内容】
●リストをテキストデータに変換する関数
●ラベルのテキスト名=画像名にするためにosライブラリで設定
●出力はすべて"labels"フォルダに保管されるように設定
[IN]
def make_tag2id(retions:dict):
output = {} #出力用の辞書
labelid = 0 #ラベルID
for region in regions:
tag = region['tags'][0]
#出力用の辞書作成
if not tag in output: #
output[tag] = labelid #IDの割り当て
labelid += 1 #次に割り当てるIDを1つ増やす
return output
tags = make_tag2id(regions)
from PIL import Image
import os
def get_label(img, height, width, left, top):
width_img, height_img = img.size #画像のサイズを取得
#座標の絶対値を計算
x_move, y_move = width/2, height/2 #画像の中心を取得
x_abs = left + x_move #x座標:絶対値
y_abs = top + y_move #y座標:絶対値
#座標を相対比に変換
x_center = x_abs/width_img #x座標:相対値
y_center = y_abs/height_img #y座標:相対値
height_rel = height/height_img #高さ:相対値
width_rel = width/width_img #幅:相対値
return [x_center, y_center, height_rel, width_rel]
#画像を読み込む
imgpath = 'zidane.jpg' #画像のパス
img = Image.open(imgpath) #画像を開く
#出力用テキスト
def list2text(data):
data = str(data)
data = data.replace('[', '')
data = data.replace(']', '')
data = data.replace(',', '')
return data
text = '' #出力用の文字列
for idx, region in enumerate(regions):
tagname = region['tags'][0] #タグ情報を取得
tag = tags[tagname] #タグIDを取得
keys_coord = ['height', 'width', 'left', 'top'] #座標情報のキー
height, width, left, top = [region['boundingBox'][key] for key in keys_coord] #座標を取得
data_coord = get_label(img, height, width, left, top)
labelinfo = [tag] + data_coord #タグIDと座標を結合
textdata = list2text(labelinfo) #タグIDと座標を文字列に変換
if not idx == len(regions) - 1:
text += textdata + '\n' #タグIDと座標を改行で結合
else:
text += textdata #最後の行は改行しない
filename_img = os.path.basename(imgpath).split('.')[0] #画像のファイル名を取得
if not os.path.exists('labels'):
os.mkdir('labels') #labelsフォルダがない場合は作成
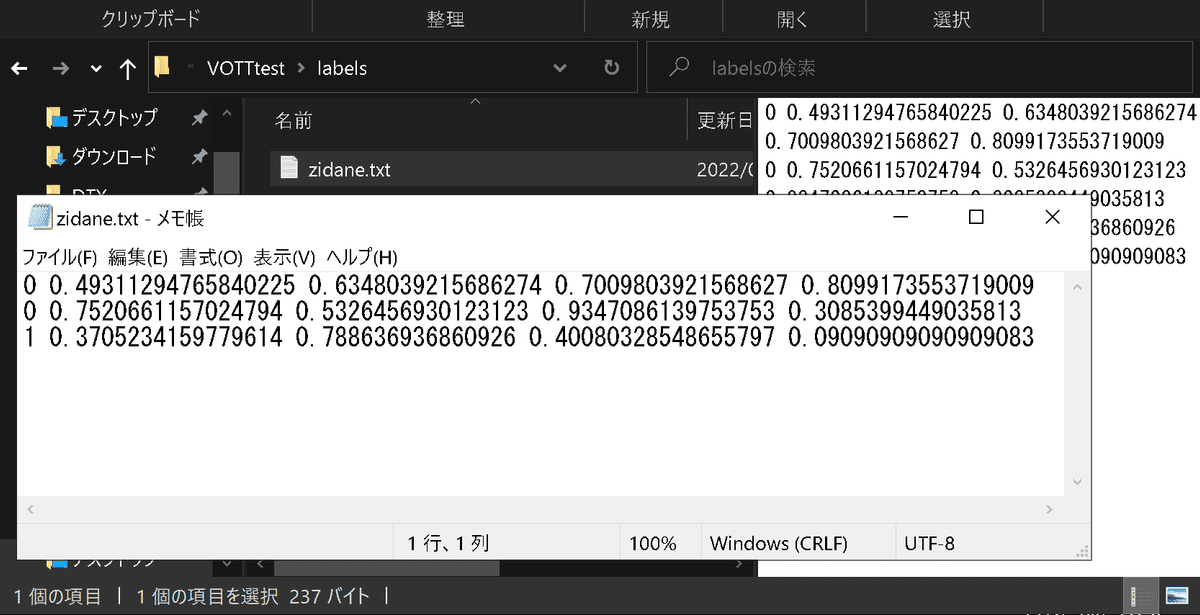
with open(f'labels/{filename_img}.txt', 'w') as f:
f.write(text) #出力用のテキストをファイルに書き込む
[OUT]これで"labels"フォルダに希望する形のアノテーションデータを作成できました。
6.参考:その他アノテーションツール
VOTTのサポートが終了しているため参考用に他のツールも紹介します。
参考資料
【別のアノテーションツール: VGG Image Annotator (VIA)】
あとがき
取り急ぎ出力。お金のある大企業ならアノテーション作業はアルバイトとか派遣に任せることができるけど個人は自分でせっせとやらんといけんのか・・・