
Pythonライブラリ(画像データ拡張):Albumentations

1.概要
データ画像の水増し(data augment)ライブラリであるAlbumentationsを紹介します。
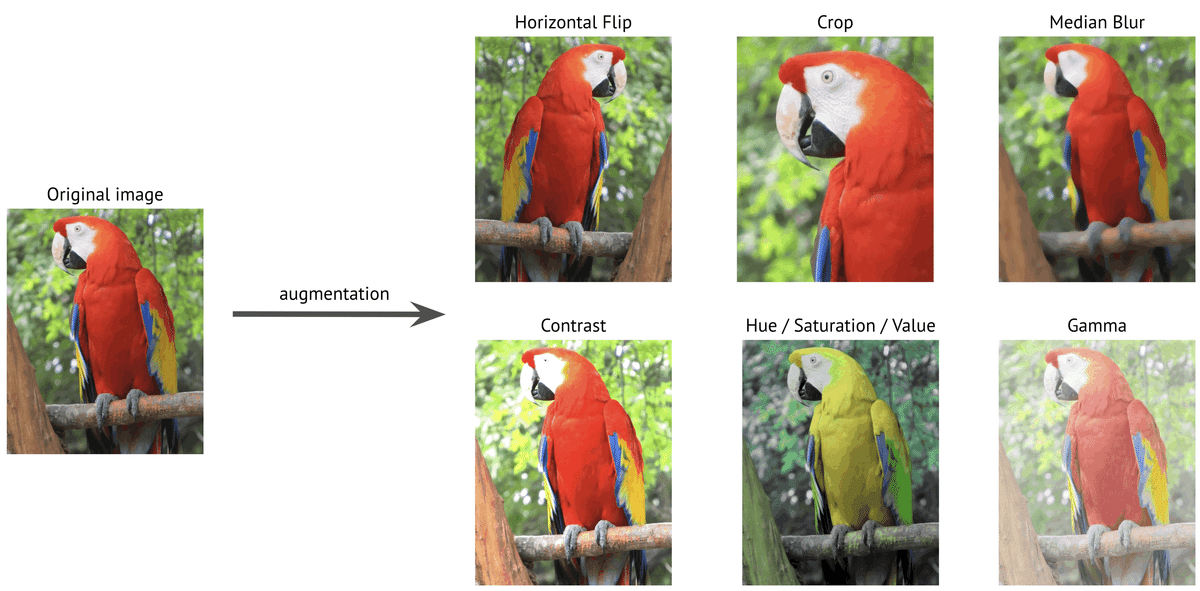
画像モデル学習のためのデータが足りないためデータ数を増やす時などに利用できます(データ加工のイメージは下図参照)。
2.環境構築
現在のPC環境ではANACONDAを使用しておりますが、下記のみで使用可能でした。
[Terminal]
pip install -U albumentations3.基礎操作
3-1.簡易処理:Alb.method()
Albumentationsの簡易の使用法は”Alb.method(params)(image=データ)"
で処理して["image"]でデータを抽出できます。
[IN]
import albumentations as Alb
import matplotlib.pyplot as plt
import cv2
import japanize_matplotlib
# データ読み込み
imgfile = 'konan.JPG' #画像ファイルパス
img = cv2.imread(imgfile) #画像読み込み->numpy配列
img = cv2.cvtColor(img, cv2.COLOR_BGR2RGB) #BGR→RGB変換
#画像処理
img_alb = Alb.RandomCrop(width=256, height=256)(image=img)["image"] #切り取り
#データ表示
fig, ax = plt.subplots(1, 2, figsize=(12, 6))
ax[0].axis("off") #axisを消す
ax[0].set_title("オリジナル画像")
ax[0].imshow(img) #axisを消す
ax[1].axis("off") #axisを消す
ax[1].set_title("データ変換処理後")
ax[1].imshow(img_alb)
[OUT]
3-2.パイプライン化:Alb.Compose()
複数の画像処理を一つのオブジェクトで実施する場合はパイプライン化します。コードの作成フローは下記の通りです。
【パイプラインの作成フロー】
1.画像データ読み込み(Numpy型)
2.画像処理のパイプライン作成(一連の画像処理のオブジェクト)
3.パイプラインのオブジェクトでデータ処理
サンプルは①画像切り取り(RandomCrop)、②水平反転(HorizontalFlip)、③輝度(RandomBrightnessContrast)でデータ処理しました。
[IN]
import numpy as np
import albumentations as Alb
import matplotlib.pyplot as plt
import cv2
import japanize_matplotlib
# データ読み込み+前処理
imgfile = 'konan.JPG' #画像ファイルパス
img = cv2.imread(imgfile) #画像読み込み->numpy配列
img = cv2.cvtColor(img, cv2.COLOR_BGR2RGB) #BGR→RGB変換
# Declare an augmentation pipeline
transform = Alb.Compose([
Alb.RandomCrop(width=256, height=256),
Alb.HorizontalFlip(p=1.0), #p:確率 0.0:なし 1.0:すべて
Alb.RandomBrightnessContrast(p=0.2),
])
# イメージ変換(augmentation)
transformed = transform(image=img)
transformed_img = transformed["image"]
#データ表示
fig, ax = plt.subplots(1, 2, figsize=(12, 6))
ax[0].axis("off") #axisを消す
ax[0].set_title("オリジナル画像")
ax[0].imshow(img) #axisを消す
ax[1].axis("off") #axisを消す
ax[1].set_title("データ変換処理後")
ax[1].imshow(transformed_img)
[OUT]
データ処理はパイプライン(Alb.Compose)に入っており、画像処理後のデータは{"image":Numpy配列型画像データ}のDict型で出力されるため["image"]でデータを抽出します。
[IN]
print(transform)
print(transformed) #出力はdict型
print(type(transformed_img), transformed_img.shape) #出力はnumpy配列型、shapeは(256, 256, 3)
[OUT]
Compose([
RandomCrop(always_apply=False, p=1.0, height=256, width=256),
HorizontalFlip(always_apply=False, p=1.0),
RandomBrightnessContrast(always_apply=False, p=0.2, brightness_limit=(-0.2, 0.2), contrast_limit=(-0.2, 0.2), brightness_by_max=True),
], p=1.0, bbox_params=None, keypoint_params=None, additional_targets={})
{'image': array([[[52, 44, 21],
[46, 39, 15],
[52, 44, 21],
...,
[ 0, 0, 0],
[ 0, 0, 0],
[ 0, 0, 0]],
~以下省略~
<class 'numpy.ndarray'> (256, 256, 3)4.Pixel-level transforms
ピクセル単位の画像処理の一覧は下記の通りです。

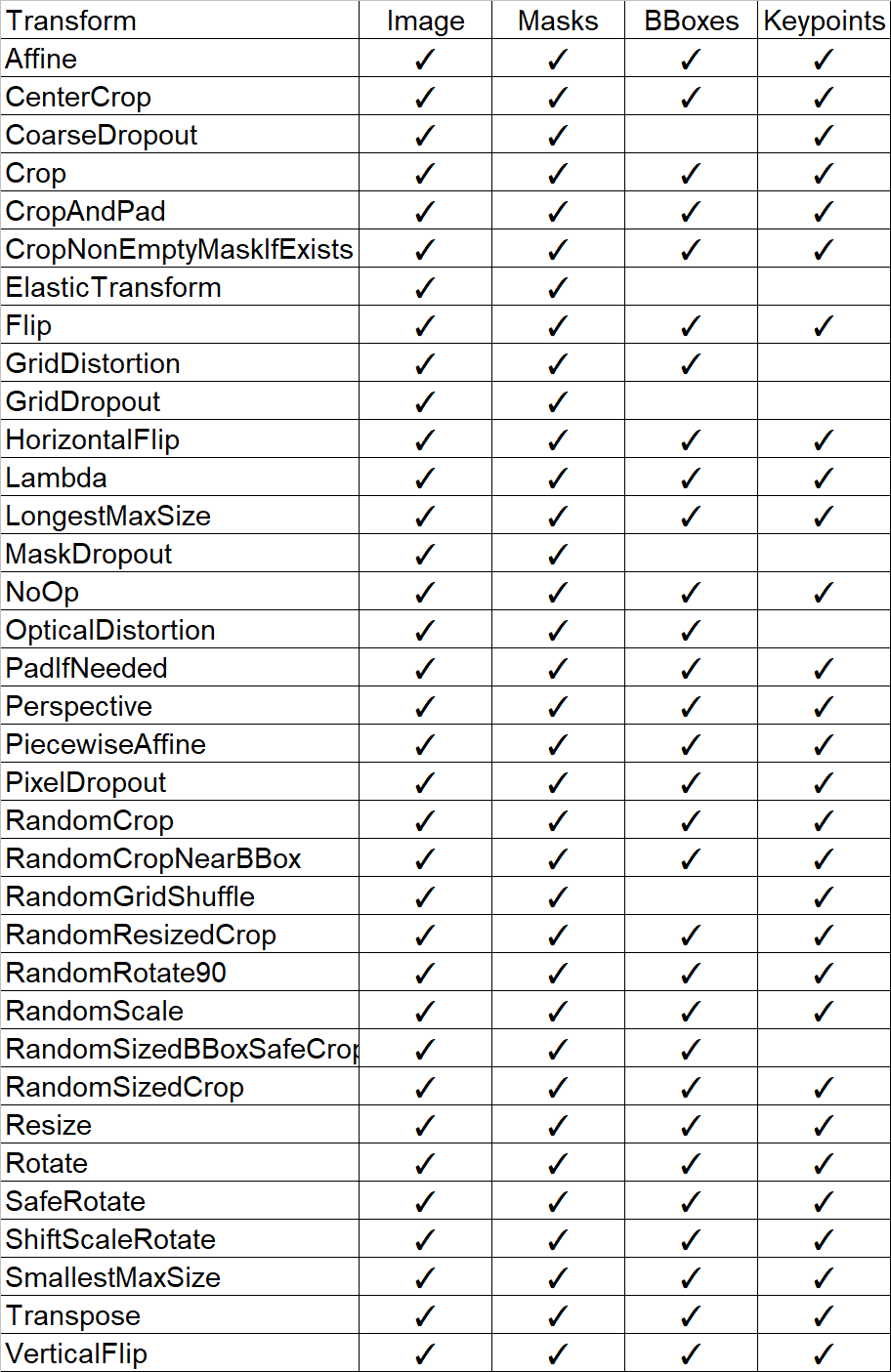
5.Spatial-level transforms
空間系処理:追って
参考資料
あとがき
とりあえず先出:PillowやOpenCV、torchvisionがある中で学習した方がよさそうかは別途検討