
2024年度の振り返りと2025年の抱負

1.概要
「2024年度の振り返り」と「2025年の抱負」を記載しました。
2.2024年度の振り返り-note
2-1.創作記録/前年との比較
今年の結果は下図の通りです。


まとめ結果を手動で抽出して結果を可視化しました。発行記事数が増えた分だけ閲覧数は増えてますが、記事の作成数が減っています。
原因はシンプルに仕事で時間が取れないのと、いろいろとモチベーションが下がっているためと思います。
[IN]
#note記事まとめの結果:1. 作成記事数, 2. Like数, 3. 閲覧数, 4. 増えたフォロワー
datas_note = {2021: [54, 145, 4462, 22],
2022: [107, 282, 72000, 61],
2023: [82, 445, 224000, 126],
2024: [34, 357, 261000, 113]}
columns = ['作成記事数', 'Like数', '閲覧数', '増えたフォロワー']
_df_note = pd.DataFrame(datas_note, index=columns)
df_note = _df_note.T
#可視化
fig, axs = plt.subplots(2,2,figsize=(10, 10))
ax1, ax2, ax3, ax4 = axs.flatten()
colors = ['blue', 'red', 'green', 'orange']
for ax, column, color in zip(axs.flatten(), columns, colors):
df_note[column].plot(kind='bar', ax=ax, color=color, alpha=0.5)
ax.set(title=column, ylabel=column)
plt.suptitle('図 note創作の記録', fontsize=20, y=-0.01)
plt.tight_layout()
plt.show()
[OUT]
2-2.結果分析(閲覧数vsいいね数)
せっかくなので、下記手順で閲覧数といいね数の関係を可視化しました。
noteの「マイページ/ダッシュボード/アクセス状況」から記事情報(記事、ビュー、コメント、スキ)を取得し、Excelに貼り付け
Excelのカラム名を変更(Item, View, Comment, Like)
Pythonスクリプトで可視化
閲覧数といいね数
閲覧数といいね率
Pythonスクリプトおよび結果は下記の通りです。
閲覧数がとびぬけているのは多分他の方がX(Twitter)で紹介していただいたためと想定
2023年も一番人気->最新情報より、使えそうな情報がよさそう
いいね率は基本的にどの記事でもほとんど変化なし(0.05~0.3%)
人の紹介が無くても閲覧数が伸びるような工夫が必要かな・・・
一番高いのは「note-API(非公式)で記事情報の取得」です。多分需要があるのに公式Docsがないからなのかな?
VBAをVSCodeで書くための方法をとてつもなく丁寧に解説してくれている記事。GitHub Copilotもちゃんと効いて震えた…😱
— たわら ¦¦ HackGenのひと (@tawara_san) June 17, 2023
VBA基礎5:VS CODEでVBAを編集(ariawase)|KIYO https://t.co/XUqEkcM6ls pic.twitter.com/G8rj4dnuv6
[IN]
import time
import requests
import json
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import matplotlib.ticker as ticker
import japanize_matplotlib
import datetime
path_excel = 'note2024.xlsx' #MyPageから手動で作成
df = pd.read_excel(path_excel)
#データの抽出
def roundup_tick(x, num_tick:int):
output = (x//num_tick + 1) * num_tick
return output
views = df['View'].values
likes = df['Like'].values
df['LikeRate'] = df['Like'] / df['View'] * 100 #いいね率[%]
rate_like = df['LikeRate'].values
max_view = roundup_tick(max(views), 5000)
max_like = roundup_tick(max(likes), 5)
print(f'Max View:{max(views)}, xtick:{max_view}, Max Like:{max(likes)}, ytick:{max_like}')
#可視化
fig, axs = plt.subplots(2,1,figsize=(10, 14))
ax1, ax2 = axs
#閲覧数vsいいね数
ax1.scatter(views, likes, color='blue', alpha=0.5)
ax1.set(xlabel='閲覧数', ylabel='いいね数', xticks=np.arange(0, max_view, 2000), yticks=np.arange(0, max_like, 2))
ax1.xaxis.set_major_formatter(ticker.StrMethodFormatter('{x:,.0f}'))
ax1.yaxis.set_major_formatter(ticker.StrMethodFormatter('{x:,.0f}'))
ax1.grid()
#ラベルを付与
for idx in range(5):
ax1.text(views[idx], likes[idx], df['Item'][idx], fontsize=8)
#閲覧数vsいいね率
ax2.scatter(views, rate_like, color='red', alpha=0.5)
ax2.set(xlabel='閲覧数', ylabel='いいね率[%]', xticks=np.arange(0, max_view, 2000), yticks=np.arange(0, 1, 0.05))
ax2.xaxis.set_major_formatter(ticker.StrMethodFormatter('{x:,.0f}'))
ax2.yaxis.set_major_formatter(ticker.StrMethodFormatter('{x:,.2f}'))
ax2.grid()
#ラベルを付与
for idx in range(5):
ax2.text(views[idx], rate_like[idx], df['Item'][idx], fontsize=8)
plt.suptitle('図 2024年度-note記事のデータ解析', fontsize=20, y=-0.01)
plt.tight_layout()
plt.show()[OUT]
Max View:23637, xtick:25000, Max Like:15, ytick:20
【参考:記事全体のLike数確認】
全期間における記事のLike数も簡単に振り返りました。コードは下記記事をベースに作成しました。
定性的に、VBAの記事以外はいいねと閲覧数に相関はなさそうでした。
[IN]
import time
import requests
import json
import pandas as pd
import matplotlib.pyplot as plt
import matplotlib.ticker as ticker
import japanize_matplotlib
import datetime
def getAllnotes(username:str, maxpage:int, waittime:float=1.0):
output = None
for numpage in range(1, maxpage+1):
time.sleep(waittime) #サーバー負荷軽減のため
res = requests.get(f'https://note.com/api/v2/creators/{username}/contents?kind=note&page={numpage}')
data_json = json.loads(res.text) #JSON->Dict
content = data_json['data']['contents'] #データ抽出
if content: #データが空でない場合
df = pd.DataFrame(content) #Dict->DataFrame
if numpage == 1:
output = df
else:
output = pd.concat([output, df], axis=0) #axis=0:行方向に結合
else:
print(f'page {numpage} は空のため処理完了!')
output = output.reset_index(drop=True, inplace=False) #indexを振り直す
return output
output = output.reset_index(drop=True, inplace=False) #indexを振り直す
return output
#データ抽出
df = getAllnotes(username='kiyo_ai_note',
maxpage=100,
waittime=1.0)
columns = ['id', 'name', 'likeCount', 'commentCount', 'publishAt']
df_extract = df[columns]
df_extract.set_index('id', inplace=True)
#PublishAtを年月日に変換
df_extract['publishAt'] = pd.to_datetime(df_extract['publishAt']).dt.date
df_extract.sort_values('likeCount', ascending=False, inplace=True)
df_extract.head(15)
#Like数の多い記事を抽出
def plot_barh_likes(df: pd.DataFrame, num_xticks: int = 5):
fig, ax = plt.subplots(figsize=(14, 7), facecolor="white")
ax.barh(df["name"], df["likeCount"], color='blue')
ax.set(xlabel="likeCount", ylabel="記事名")
ax.xaxis.set_major_locator(ticker.MultipleLocator(num_xticks)) # 目盛りを設定
ax.xaxis.set_major_formatter(ticker.FuncFormatter(lambda x, pos: f'{int(x):,}'))
ax.grid(axis='x', linestyle='--', alpha=0.7) # 縦軸に補助線を追加
plt.tight_layout()
plt.show()
# 関数を実行してグラフを表示
df_sorted = df.sort_values('likeCount', ascending=False) # 降順にソート
df_sorted = df_sorted.iloc[:12, :]
df_sorted.sort_values('likeCount', ascending=True, inplace=True) # 昇順にソート
plot_barh_likes(df_sorted, num_xticks=5)
[OUT]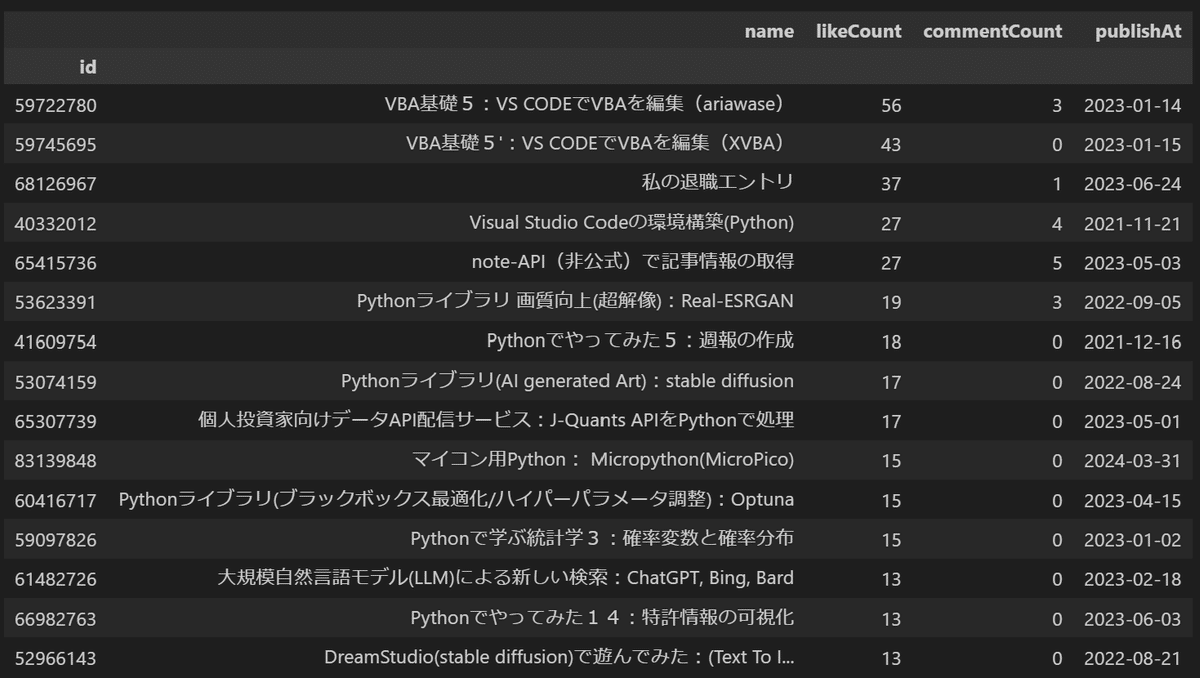

3.2024年度の振り返り-仕事
2023年に転職(私の退職エントリ、転職半年後の振り返り)した後、2024年は何とか頑張って過ごしました。
2024年の仕事において、技術面で大きな変化はありませんが社内のドタバタ(チーム内編成が崩れる)によりプロジェクトを一人でまわし、グループ内雑務も全部ひとりでする状態になりました。頑張ってアウトプット出したため高い評価はもらえ、年収は元より上がりました。
今まで知らなかった技術の方向性(PLCやSCADA)は得られましたが、グループ内に専門家がいないため完全に独学の状態です。技術も重要ですが、年収も重要なので自分の将来をどうしたいかは常に考えていきたいと思います。
将来の目標は(目的は人生を楽しむ)?
人生を楽しむためには何が必要か/何がしたいか?
どのくらいお金・時間が必要か/そのための手段は?
4.2025年の抱負
4-1.note記事/学習
記事化・学習は将来につながる(仕事に使える->年収UP狙える)ものがよいです。基本的にモノづくりが好きなので、メーカーに勤める/関わること前提で最近は下記のような求人に興味があります。
製造業系のコンサル
モノづくりではないため注意
ITコンサルとかの方が年収は高い(ような気がする)->SAPとか
量子化学計算/機械学習/マテリアルインフォマティクス(MI)
大体プログラミング+機械学習+評価分析技術(NMR, IR, XRD, XRFなど)の知識・実務経験も求められる。(+組織マネジメント)
純粋なITエンジニアなら高級(1,500~2,000万円以上)だが、メーカー系は国内だと(学ぶこと多いわりに)年収上限あり
データサイエンティストもあるが、モノを触る機会が減る
DXの推進
プラントの自動運転(AI技術×化学プロセス)
製造現場のスマートファクトリー化(※キーワードはインダストリー4.0/ソサエティ 5.0)
新規事業/事業企画
企画創出(0->1)
事業化・事業拡大(1->10)
上記を考えながらも「やりたいこととすべきことが重なる」部分をを選んで記事作っていきたいです。直近では「PLC、SCADA、通信、計器」関係を学習予定です。
4-2.仕事編
2024年の抱負は「やりきること」であり、これは達成できました。ただ自分を削った年(特に2024年6月以降)$${^{※}}$$と感じ、「自分の幸せとは何か」を考える年でもありました。
※一番しんどい時期は前の会社でしたが若かった/社畜だったため、乗り越えることができました。
今年色々経験した中で、おそらく今後もDXやエネルギー(カーボンニュートラル)関係のプロジェクト携わることになると思っています。2025年の抱負は、やりきることは当たり前として下記を実行していきます。
【2025年の抱負】
技術だけでなくプロジェクトマネジメント、英語、契約関係などを高いレベル(ちゃんと本・論文などで知識も入れつつ実践)で経験を積む
「仕事=価値づくり」を認識しながら働く
企業文化として大量の説明資料/申請書は必須のため、あくまで頭の中で分類すること
7つの習慣でいう第2領域/エッセンシャル思考も大事
5.参考
5-1.note記事記録
5-2.振り返り/抱負記事
6.あとがき
一応恋愛も頑張らないと・・・・・