
Pythonライブラリ(Webスクレイピング):Beautiful Soup4

1.概要
WebスクレイピングライブラリのBeautiful Soup4を紹介します。WebスクレイピングはWebページから情報を抽出する技術のことです。
スクレイピングのライブラリは複数ありますが個人の意見としては下記の通りです。

2.Beautiful Soup4について
2-1.Beautiful Soup4の基礎知識
Beautiful Soup4は公式に記載の通りHTMLを解析して簡単に情報を抽出できるライブラリです。
[ターミナル]
pip install BeautifulSoup4Beautiful Soup4を使うためには最低限のHTML構造の理解が必須+CSSセレクタの理解がある方が便利ですが、本記事はライブラリ説明用のため説明は割愛します。
2-2.WebブラウザでHTML確認:デベロッパーツール
HTMLからデータを抽出するためにWebページのHTMLを確認する必要があります。HTMLの確認は「デベロッパーツール」を使用して行いますが、ツールはブラウザ上で「F12」ボタンを押したら下記の通り確認できます。

Beautiful Soup4は解析結果から直接HTML構造が読めるためデベロッパーツールは使わなくても処理できますが覚えておく方が便利です。
2-3.Webスクレイピング実施時の注意事項
高速でアクセスできるため連続処理をするとサーバーへ負荷がかかる(例:人気チケットやワクチン予約)ためスクレイピングを禁止しているサイトもあります。
また禁止されていなくても連続処理する場合はサーバーへの負荷を考慮して待機時間を設けるのが一般的です。
[In] ※for文の処理をループごとに1秒待機
import time
for i in range(5):
print(i)
time.sleep(1)
3.Beautiful Soup4の基礎
3-1.HTML構造の解析:BeautifulSoup(parser)
初めにrequestsライブラリで解析したいURLのHTML情報を取得します。そしてBeaufilSoup(HTMLデータ(String), parser)で処理ができます。
parserはHTML構造を解析モデルみたいなものですか"html5lib"で十分です。

[In]
import requests
from bs4 import BeautifulSoup
import time
url_note = 'https://note.com/kiyo_ai_note/magazines'
res = requests.get(url_note) # 指定URLからレスポンスを取得
soup = BeautifulSoup(res.text, 'html5lib') #最近のWebブラウザと似たような解析
# soup = BeautifulSoup(res.text, 'html.parser') #html5libで見にくければこちら
print(soup)
print(soup.prettify())解析したHTMLをきれいに表示するためにprettify()メソッドを使用します。

3-2.タグ情報1つ取得:soup.find, soup_select_one
解析したHTML(soup)からタグ情報を抽出します。HTMLデータ内の最初のタグを取得する場合は下記の通りです。
【HTML構造の要素を一つ取得】
●soup.tag:指定したタグ情報を取得
●soup.find('tag'):soup.tagと同じ
●soup.select_one('cssselector'):引数にCSSセレクタを使用して情報を取得
[In]
print(soup.title) # <title>タグを取得
print(soup.p) #最初のpタグを取得
print(soup.find('p')) #最初のpタグを取得
print(soup.select_one('p')) #最初のpタグを取得[Out]
#soup.title
<title>KIYOのマガジン一覧|note</title>
#soup.pおよびsoup.find('p')
<p class="o-contentMagazine__description" data-v-1a3a27f4="" data-v-4116c80d="">
Pythonの基礎を押さえながらPythonでできることを記載していきます。
Web系というより製造業(自分が使っている)で使えるネタをコードとともに記載していきます。
</p>3-3.タグ情報の一括取得:soup.find_all, soup.select
指定したすべての要素をリスト形式で取得する場合は下記の通りです。
【HTML構造の要素をまとめて取得】※戻り値->List
●soup.find_all('tag'):引数であるタグ要素をリストで取得
●soup.select('cssselector'):引数にCSSセレクタを使用して情報を取得
[In]
tags_p = soup.find_all('p')
print(type(tags_p), len(tags_p)) #取得したpタグリストの型式と要素数
print(tags_p[:3]) #最初の3つのpタグを取得
soup.find_all('p') == soup.select('p') #出力の確認[Out]
#type(tags_p), len(tags_p)
<class 'bs4.element.ResultSet'> 26
#tags_p[:3]
[<p class="o-contentMagazine__description" data-v-1a3a27f4="" data-v-4116c80d="">
Pythonの基礎を押さえながらPythonでできることを記載していきます。
Web系というより製造業(自分が使っている)で使えるネタをコードとともに記載していきます。
</p>, <p class="o-magazineItemWithNotes__avatarName" data-v-3d268250="">
KIYO
</p>, <p class="m-noteBody__description m-noteBody__description--TextNote" data-v-232de199="">1.概要 Pythonを使用して物体検出をしてみます。物体検出モデルとしてYOLOを使用しました。
※2022年1月15日現在:リアルタイム検出がエラーのため未実装ですが静止画はできているためとりあえず投稿
2.参考資料 You only look once (YOLO) とはリアルタイムで高精度に物体を検出してくれるAIモデルです。詳細・実演はYOLO開発者:Joseph Redmon氏のTED公演をご確認ください。
YOLO実装は基本的にサイトをそのまま実行していき</p>]
#soup.find_all('p') == soup.select('p')
Truesoup.find_allの場合、指定した属性のタグ情報を取得したい場合は引数にattr={'属性':'値'}を入力します。
[In]
soup.find_all('p', attrs={'class': 'o-magazineItemWithNotes__avatarName'}) #指定したclass属性のpタグを取得
soup.select('p.o-magazineItemWithNotes__avatarName') #指定したclass属性のpタグを取得[Out] ※出力は同じ
[<p class="o-magazineItemWithNotes__avatarName" data-v-3d268250="">
KIYO </p>,
<p class="o-magazineItemWithNotes__avatarName" data-v-3d268250="">
KIYO </p>,
<p class="o-magazineItemWithNotes__avatarName" data-v-3d268250="">
KIYO </p>,
<p class="o-magazineItemWithNotes__avatarName" data-v-3d268250="">
KIYO </p>,
<p class="o-magazineItemWithNotes__avatarName" data-v-3d268250="">
KIYO </p>]3-4.属性・テキストの取得
要素にはタグがついているためここからほしい情報だけ取得します。
●tag.text:子や孫要素含めたテキスト情報を取得
●tag.string:要素のテキスト情報を取得
●tag.strings:子や孫要素含めたテキスト情報をジェネレータで取得
●tag.attrs:要素の属性一覧を取得
●tag['属性名'] またはtag.get('属性名'):要素の属性情報を取得
[In]
soup.p.text #要素のテキスト情報
soup.p.string #要素のテキスト情報
next(iter(soup.p.strings)) #要素のテキスト情報の一つ目を取得
soup.p.attrs #要素の属性情報取得
soup.p['class'] #属性の値を取得[Out]
#soup.p.text、soup.p.string、next(iter(soup.p.strings))と同じ出力
'\n Pythonの基礎を押さえながらPythonでできることを記載していきます。\nWeb系というより製造業(自分が使っている)で使えるネタをコードとともに記載していきます。\n '
#soup.p.attrs
{'class': ['o-contentMagazine__description'], 'data-v-1a3a27f4': '', 'data-v-4116c80d': ''}
#soup.p['class']
['o-contentMagazine__description']3-5.DOM(親要素・子要素)へのアクセス
HTMLは木構造となっており特低タグからみて親要素や子要素があります。それらにアクセスする方法は下記の通りです。(普段使わないので参考用)
[In]
print(soup.p.parent)
print(soup.p.children)
print(soup.p.previous_sibling)
print(soup.p.previous_siblings)
print(soup.p.next_sibling)
print(soup.p.next_siblings)[Out]
#soup.p.parent
<div class="m-horizontalScrollingList__description" data-v-1a3a27f4=""><p class="o-contentMagazine__description" data-v-1a3a27f4="" data-v-4116c80d="">
Pythonの基礎を押さえながらPythonでできることを記載していきます。
Web系というより製造業(自分が使っている)で使えるネタをコードとともに記載していきます。
</p></div>
<list_iterator object at 0x00000212201FAA90> #soup.p.children
None #soup.p.previous_sibling
<generator object PageElement.previous_siblings at 0x000002122022E740> #soup.p.previous_siblings
None #soup.p.next_sibling
<generator object PageElement.next_siblings at 0x000002122022E6D0> #soup.p.next_siblings4.Webスクレイピングの応用
4-1.画像情報の取得
簡単に画像取得を実施しています。詳細は飛ばしますがHTML構造で画像は<img>タグが使用され一般的には'src'属性にURL記載があります。よって"img"タグを一括取得して"src"属性内にあるURLを処理することで画像データが取得できます。
[In]
import requests
from bs4 import BeautifulSoup
import time
import urllib
url_note = 'https://note.com/kiyo_ai_note/magazines'
res = requests.get(url_note)
soup = BeautifulSoup(res.text, 'html5lib')
for idx, tag_img in enumerate(soup.find_all('img')[:5]): #最初の5つのimgタグを取得
url = tag_img['data-src'] #今回のページはsrcではなく、data-src属性の値を取得
res = requests.get(url)
with open(f'./imagefile{idx}.jpg', 'wb') as f:
f.write(res.content)
time.sleep(1) #1秒待つ※重要!!
4-2.データの一覧表作成
私のnoteマガジンページに表示されている記事のタイトル、概要、スキの数の一覧表を作成しました。なお取得したい値の要素・属性・要素数の順番はデベロッパーツールとsoup.prettify()で事前に調べました。
[In]
import pandas as pd
import requests
from bs4 import BeautifulSoup
url_note = 'https://note.com/kiyo_ai_note/magazines'
res = requests.get(url_note)
soup = BeautifulSoup(res.text, 'html5lib')
#要素を取得
titles = soup.find_all('a', attrs={'class':'a-link m-largeNoteWrapper__link fn'}) #指定したclass属性のaタグを取得
descrs = soup.find_all('p', attrs={'class':'m-noteBody__description m-noteBody__description--TextNote'})
_likenum = soup.find_all('div', attrs={'class':'m-noteBody__status'})
#要素から属性を取得して体裁をきれいに調整
titles = [title['aria-label'] for title in titles] #aria-label属性を取得:タイトル取得
descrs = [descr.text.replace('\n','').replace('\u3000',' ') for descr in descrs] #改行と全角スペースを削除
_likenum = [num.text.split('\n') for num in _likenum] #スキの数を取得
linenum = [num[3].strip() if len(num) > 3 else 0 for num in _likenum ] #lenで判定:好きの数が0の物は別処理で戻り値0とする。
#まとめ
df = pd.DataFrame([titles, descrs, linenum]).T
df.columns = ['タイトル', '概要', 'スキの数']
df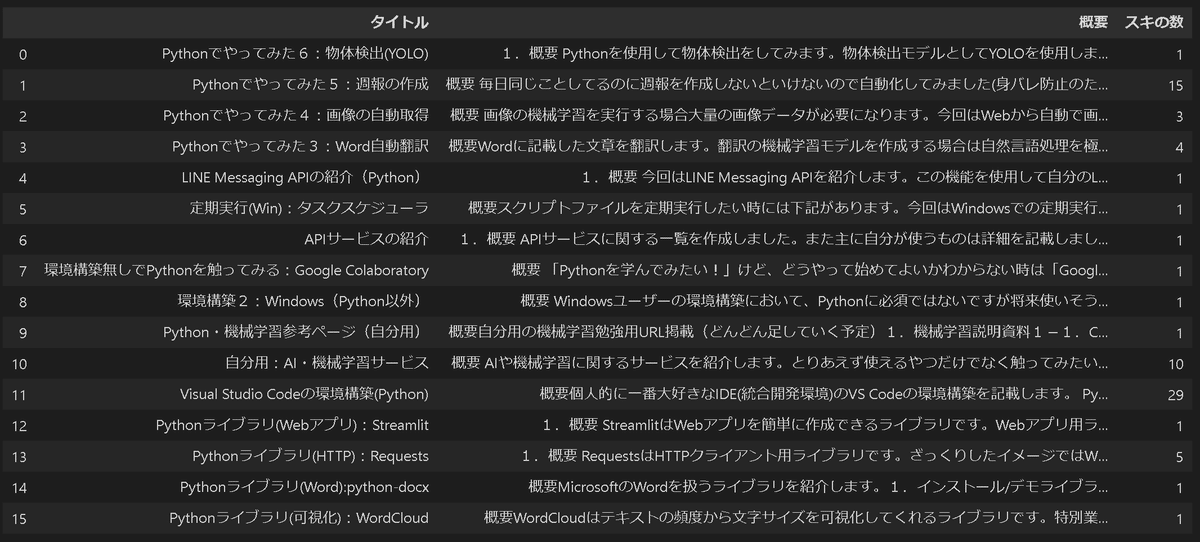
5.エラー事例
Beautiful Soup4でよく生じたエラー事例は下記の通りです。
●要素が取れなくなった:Webページの構造や属性名は比較的コロコロ変わるためいつの間にかエラーがでる。
●ブラウザには見えるページが取得できない:最近のWebページはJavascriptで動的に動くためブラウザで接続しないと取得できない(このようなケースではSeleniumで対応可能)
● 文字化け:requestsで取得したデータrをr.textではなくt.contentを使用
参考記事
あとがき
情報取得手法として個人的にはAPIが一番好きだけど使えないとしょうがないので最低限のスクレイピングスキルは取得しておきたいですね。