
Pythonライブラリ(SAPデータ抽出):pyodbc

1.概要
まず初めに今回の記事は特定の人向け(ほぼ自分用備忘録)となり、使わない人は多いと思いますのでご留意ください。
大企業で使用されるEPRとしてSAPがあります。SAPではデータベース内にデータを保管していくためデータ活用が可能です。
しかし一般的にSAPはGUIで操作でする※ため自分が欲しいデータ抽出が手間であり自動化もできません。データベースからCLIでデータ抽出するためのライブラリとしてpyodbcを使用しました。
(※多くの作業者が使用できるようにGUIにしていると思います。)
2.環境構築
自分のPCに環境構築していきますが、基本的には社内の情報システム部が管理(使用できる操作やアクセスできるテーブルなど)されていると思いますので詳細は該当部門に問い合わせてください。
2-1.ODBCドライバ
(今の会社でのルールより)SAPのデータベースに接続するためにODBCドライバーをインストールします。ODBCとは「Open Database Connectivity」であり、ODBCを使用することで安定した接続が可能です。
【環境構築 ※詳細は情シスの方に要確認】
1.SAP HANA Clientの導入
2.SAP HANA Clientの設定
【参考 ※SAP HANA Clientの設定】
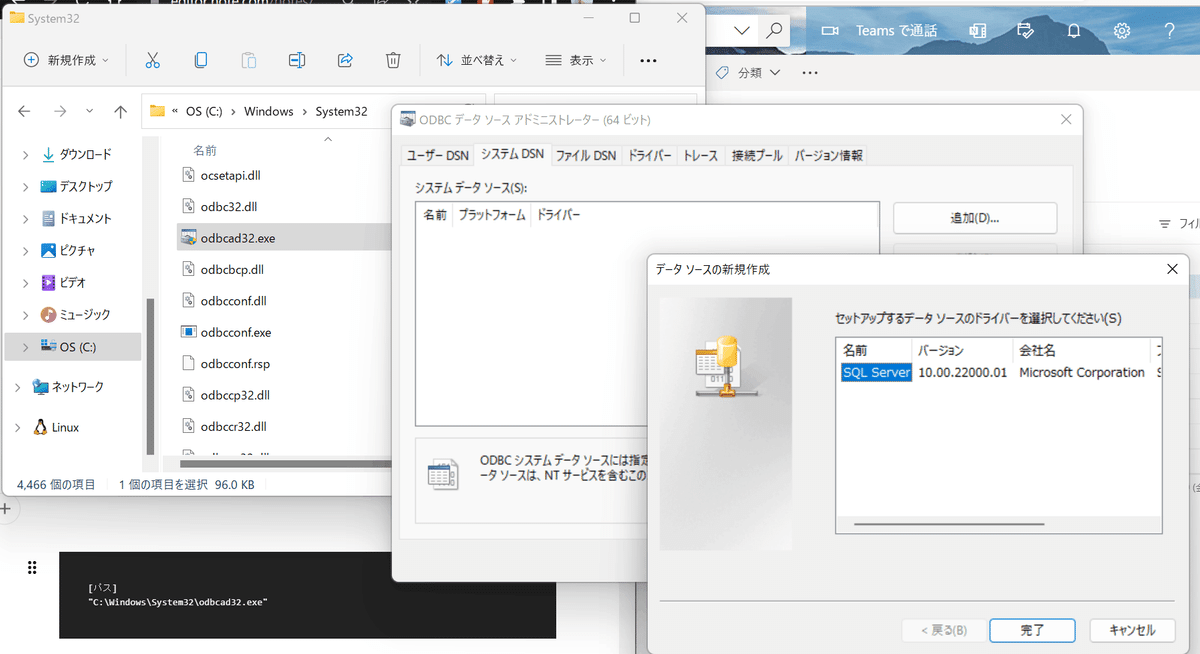
1.を実行後に「"C:\Windows\System32\odbcad32.exe"」のシステムDSNから追加を押すと該当のODBCドライバが選択できるようになります(下図は実行していないため無し)。
その後必要な情報(Data Source, Description, Server Host, Server Instance number, Database, Database Tenant databaseなど)を登録します。
2-2.pyodbcライブラリ
ODBCドライバを扱うためpyodbcライブラリをインストールします。
[Terminal]
pip install pyodbcpyodbcで使用できるドライバはdrivers()メソッドで確認できます。
[IN]
import pyodbc
print(pyodbc.drivers()) #使用できるdriver確認
[OUT]
['SQL Server', 'PostgreSQL ANSI(x64)', 'PostgreSQL Unicode(x64)', 'ODBC Driver 17 for SQL Server', 'SnowflakeDSIIDriver', 'HDBODBC']3.データベースへ接続
3-1.事前知識
pyodbcの接続はシステムが32bit版と64bit版で異なります。今の会社のSAPデータベースは32bitですがPythonは64bitでも接続できたためbitは合わせずそのまま使用しております。
現在のPythonのbit数を確認するには下記コードを実行します。
[IN]
import platform
platform.architecture()[0]
[OUT]
'64bit'3-2.DataBaseへ接続:pyodbc.connect()
DataBaseへ接続するにはpyodbc.connect()を使用します。ポイントは下記の通りです。実行することでcursorオブジェクトを取得します。
【ポイント】
●Pythonが32bit版、64bit版どちらでも使えるように条件分岐
●SAPのデータベース用ドライバとして”HDBODBC”を選択
[IN] ※dsn, username, passwordは環境構築で設定した値に変更すること
import pyodbc
import platform
bit_python = platform.architecture()[0]
(dsn, username, password) = '設定したDSN','設定したusename', "設定したpass" #SAPHANAのDSN,ユーザー名,パスワード
if bit_python == '64bit':
cnxn = pyodbc.connect(f'driver=HDBODBC;DSN={dsn};UID={username};PWD={password};SERVERNODE=vhhtzhdpdb.sap.hitachizosen.co.jp:30215') #64bit
else:
cnxn = pyodbc.connect(f'driver=HDBODBC32;DSN={dsn};UID={username};PWD={password};SERVERNODE=vhhtzhdpdb.sap.hitachizosen.co.jp:30215') #32bit
cursor = cnxn.cursor()
[OUT]
-3-3.データ抽出:cursor.execute(SQL)
取得したcursorオブジェクトはsqlite3のようにexecuteメソッドを使用することで直接SQL文を記載することができます。
SQL文記載時の注意点は下記の通りです。
【pyodbcでのSQL文の注意点】
●テーブル名(FROMの後ろ)の記法が特殊のため要注意
●カラム名は情シスで管理していると思うので問い合わせてください
サンプルコードも合わせて記載しました。イメージとしては「①SAPデータベースから②条件"PSPID" = '384XSD2321' かつ "AUART" = 'XRD1のテーブルを取得して、③"PJ_NAME","PJ_PRICE"カラムの情報を抽出」です。
カラム名(SELECT後ろ)と条件の値(WHERE)の後ろは適当ですのでほしいデータに合わせて自分で設定してください。
[IN]
cursor.execute('''SELECT "PJ_NAME","PJ_PRICE"
FROM "_SYS_BIC"."s4.sd/CA_SD_RECEIVED_ORDER"
WHERE "PSPID" = '384XSD2321' and "AUART" = 'XRD1';
''')
for row in cursor: # Looping over returned rows and printing them
print(row)
[OUT ※出力はイメージです]
('noteプロジェクト', '1,000,000')指定のテーブル(またはビュー)からDataFrame型でデータ取得したい場合は下記の通りです。おそらく会社ごとに出力されるデータの形が違う可能性があるため、適宜コードを編集すればほしい形に変更可能です。
[IN]
import pandas as pd
def checkview(viewname: str):
cursor = cnxn.cursor()
cursor.execute(f'''SELECT *
FROM "_SYS_BIC"."s4.zz/{viewname}";
''')
output = [row for row in cursor]
cursor.close()
return output
_datas = checkview(viewname='CA_ZZ_Z4314fad') #特定グループ情報
datas = [list(i) for i in _datas]
pd.DataFrame(datas)
[OUT]
参考記事
あとがき
需要は少ないだろうけど、自分と同じように大きな需要がある人もいるだろう