
#xhack勉強会レポ 「短期集中!90分で正規表現の苦手意識をなくす勉強会 」(2021年4月3日)

こんばんは。4/3(土)にxhack勉強会主催の『短期集中!90分で正規表現の苦手意識をなくす勉強会』に参加したので、勉強会で教えていただいたPHPでの正規表現の書き方をまとめます!
勉強会の内容+新たに自分で調べた内容を追加しました。
まずは本題に入る前に一言。。。
最高の勉強会でした!!!まじで!
主催者のたなべこうせいさんは「正規表現に対する恐怖心をなくそう」をテーマとして掲げておられましたが、勉強会が終わった頃には恐怖心がなくなったどころか電話番号やメアドの正規表現もなんとなく読めるレベルになっていました。たった90分で。
ここでまとめておかないと絶対忘れてしまう(逆にまとめておけば一生見返して使える)と思ったので、記事にします。
メタ文字
正規表現で出てくる
. ^ $ [ ] * + ? | ( )といった特殊文字のことをメタ文字といいます!
早速実際に見ていきます!
正規表現チェッカー
正規表現チェッカーというブラウザ上で正規表現をチェックできるサイトを使って確認します!
.(ドット)
なんでもいい一文字を意味する。
正規表現 私は.です
修飾子 u //パターンと検索対象の文字コードをutf-8として処理をするというオプション検証対象の文字列
私は猫です
私はいぬです
私はうさぎです
// 「私は猫です」が赤色になる(= 正規表現にマッチ)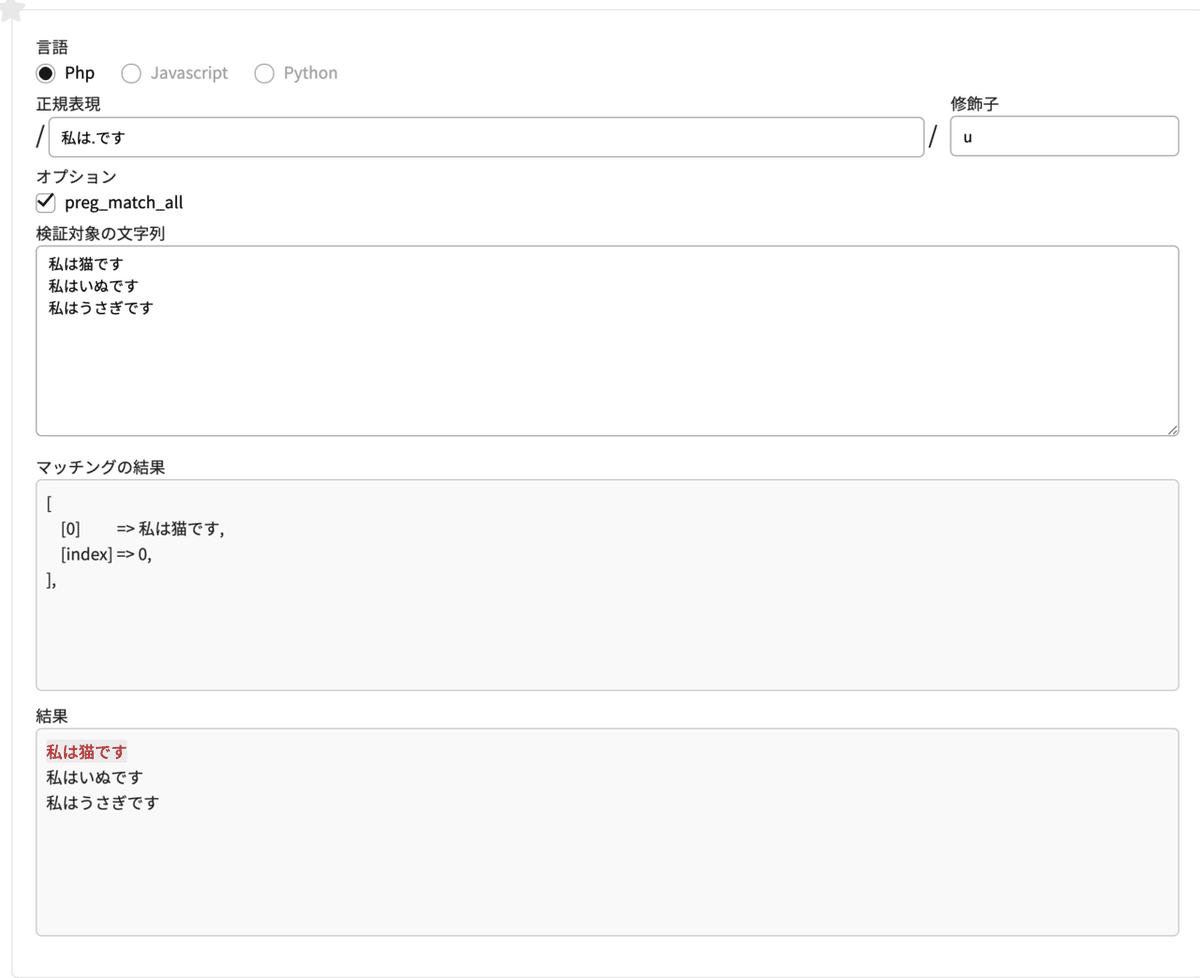
正規表現
私は.ですに対し、検証対象の文字列
私は猫です
私はいぬです
私はうさぎですをチェックすると、私は猫ですの文字色が赤くなります。赤くなった部分が正規表現にマッチしたということになります。
「『私は』と『です』の間になんでもいいから1文字入ってる」というルールなので、私は猫ですがマッチするんですね。
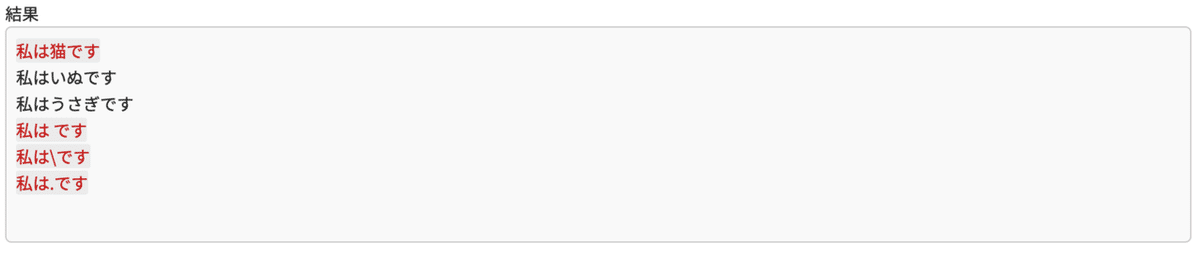
たとえば、
私は です
私は\です
私は.ですなども全てマッチします。
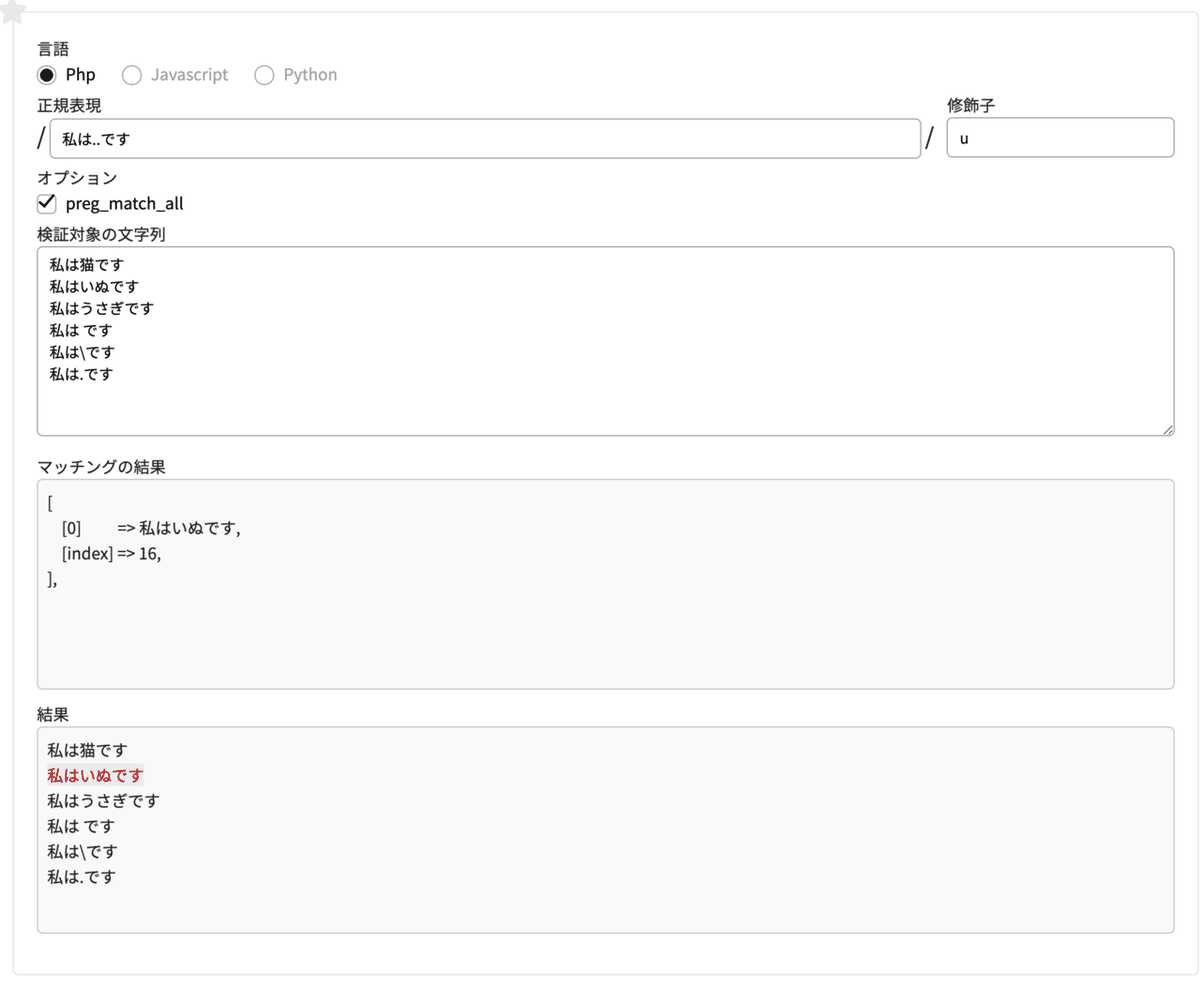
正規表現ルールを
正規表現 私は..です // ..を2つ続けるとすると、私はいぬですだけがマッチします。
直前の文字・パターンを繰り返す
直前の文字・パターンが何回繰り返されているかを表現する特殊文字を、量指定子と呼びます。
* (アスタリスク)
直前の文字が0個以上あるかをチェックする
正規表現 おー*い
修飾子 u検証対象の文字列
おいお茶
おーいお茶
おーーいお茶
おーーーいお茶
おおいお茶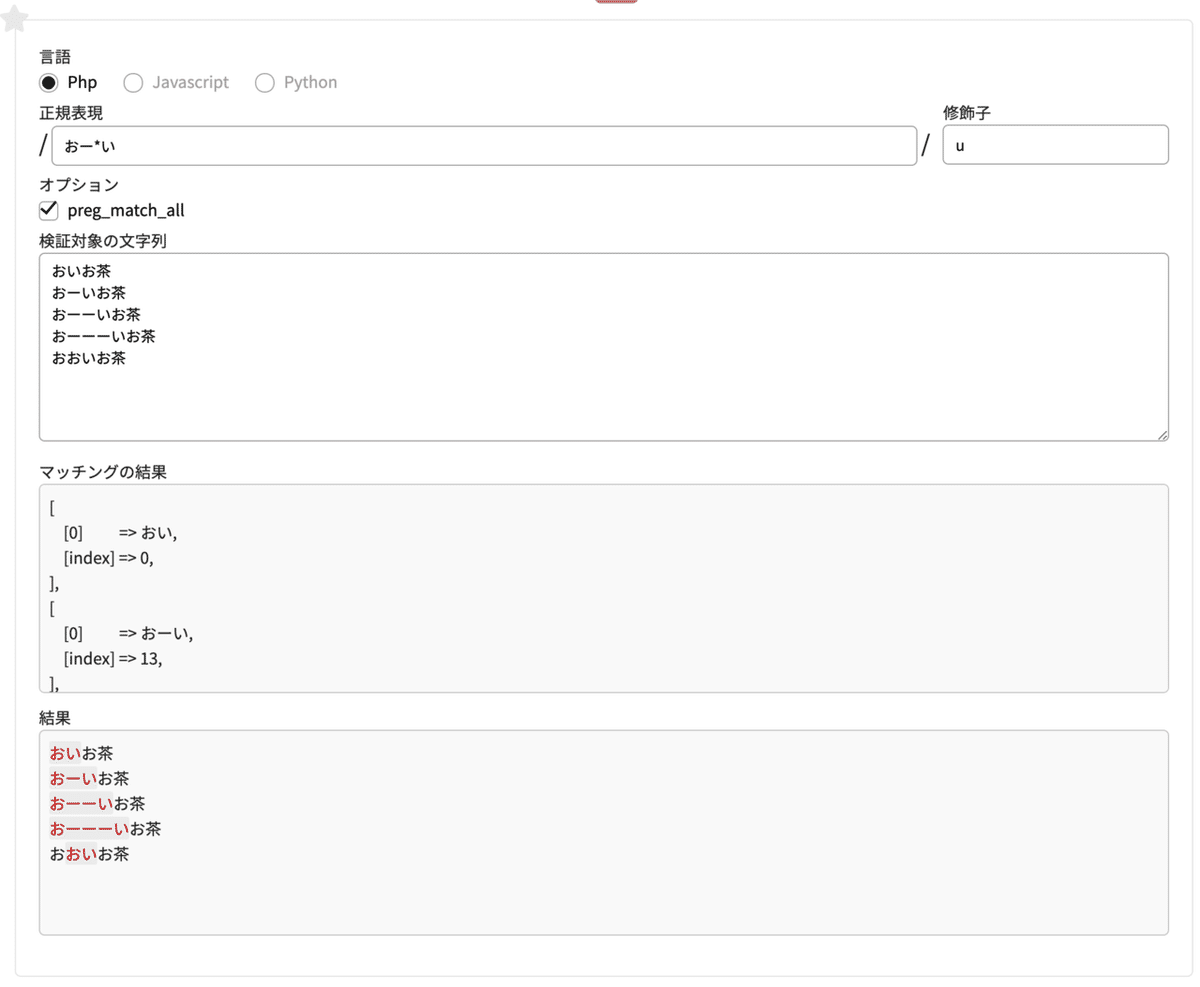
「直前の文字が0個以上あるか」という判定基準なので、なくてもマッチします。
+ (プラス)
直前の文字が1個以上あるかをチェックする
正規表現 おー+い
修飾子 u検証対象の文字列
おいお茶
おーいお茶
おーーいお茶
おーーーいお茶
おおいお茶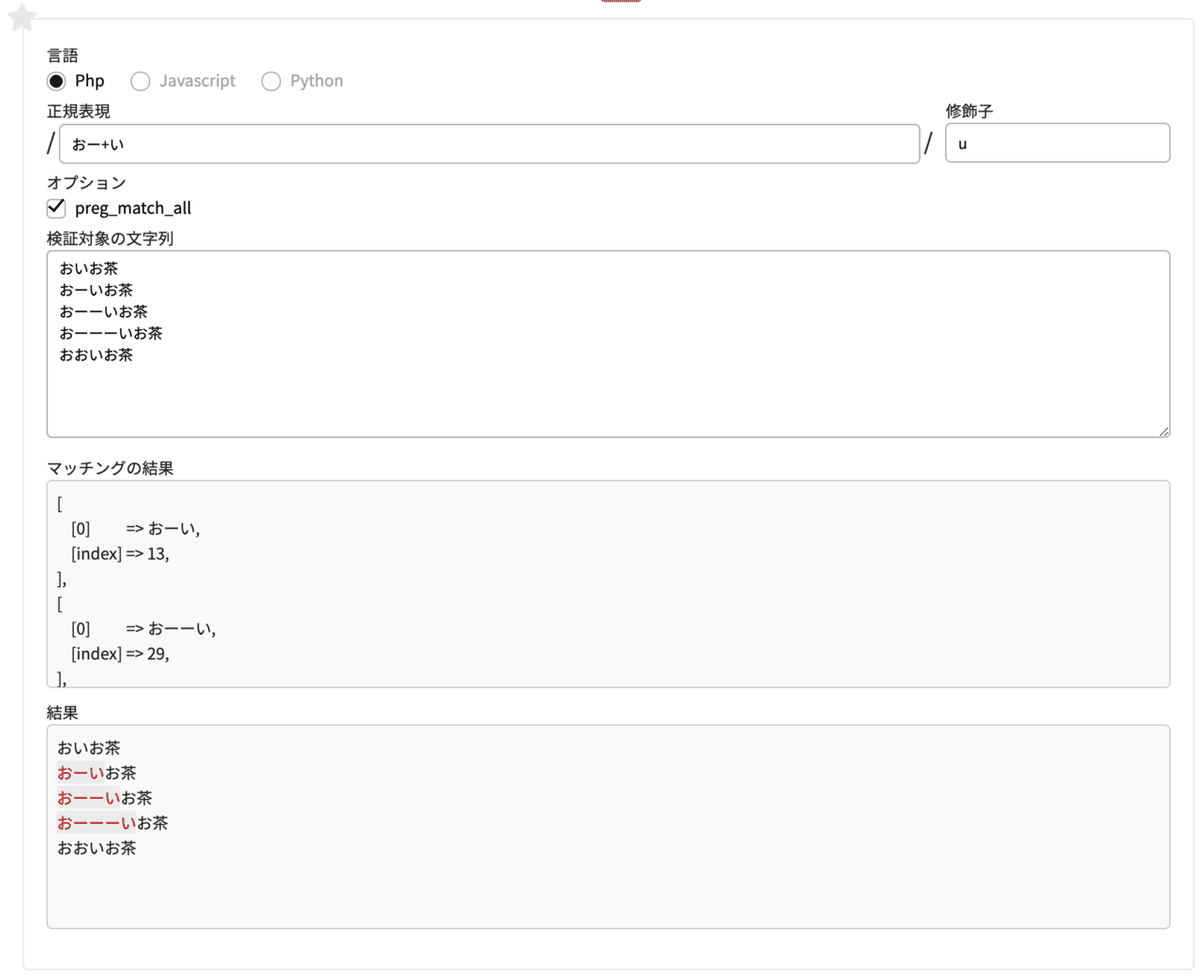
さきほどの「*」は「直前の文字が0個以上」でしたが、「+」は「直前の文字が1個以上」なので、
おいお茶
おおいお茶はマッチしません。
? (クエスチョンマーク)
直前の文字が0個もしくは1個あるかをチェックする
正規表現 おー?い
修飾子 u検証対象の文字列
おいお茶
おーいお茶
おーーいお茶
おーーーいお茶
おおいお茶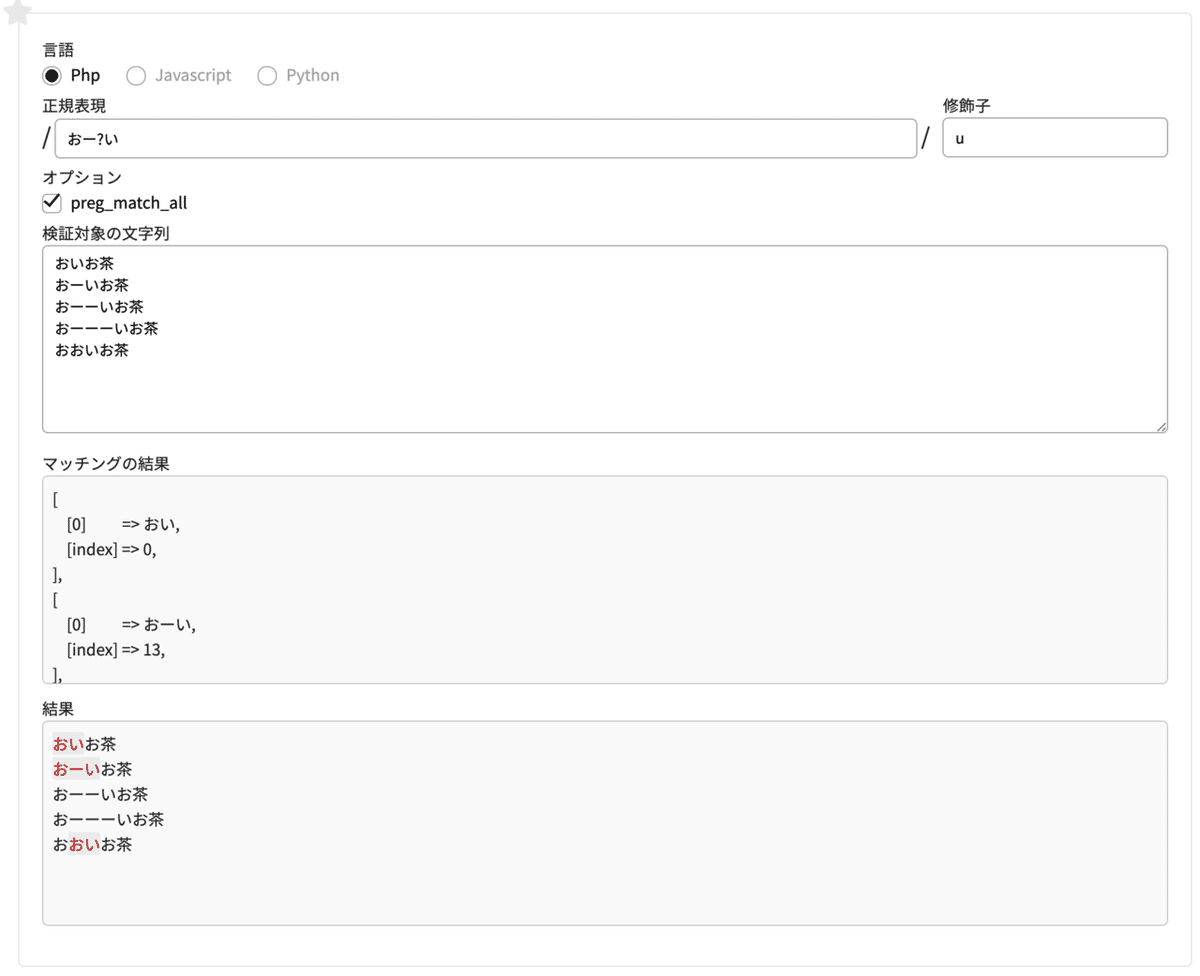
「?」は、「直前の文字が0個か1個」あるかをチェックします。なので、
おいお茶 の おい
おーいお茶 の おーい
おおいお茶 の おい
がマッチします。
{ n, m } (繰り返しの回数を指定する)
直前の文字の繰り返し回数の最小値、最大値を指定します。nは最小値、mは最大値です。
正規表現 おー{1,3} # ーが一回以上3回以下あるかをチェック
修飾子 u検索対象の文字列
おいお茶
おーいお茶
おーーいお茶
おーーーいお茶
おーーーーいお茶
おーーーーーいお茶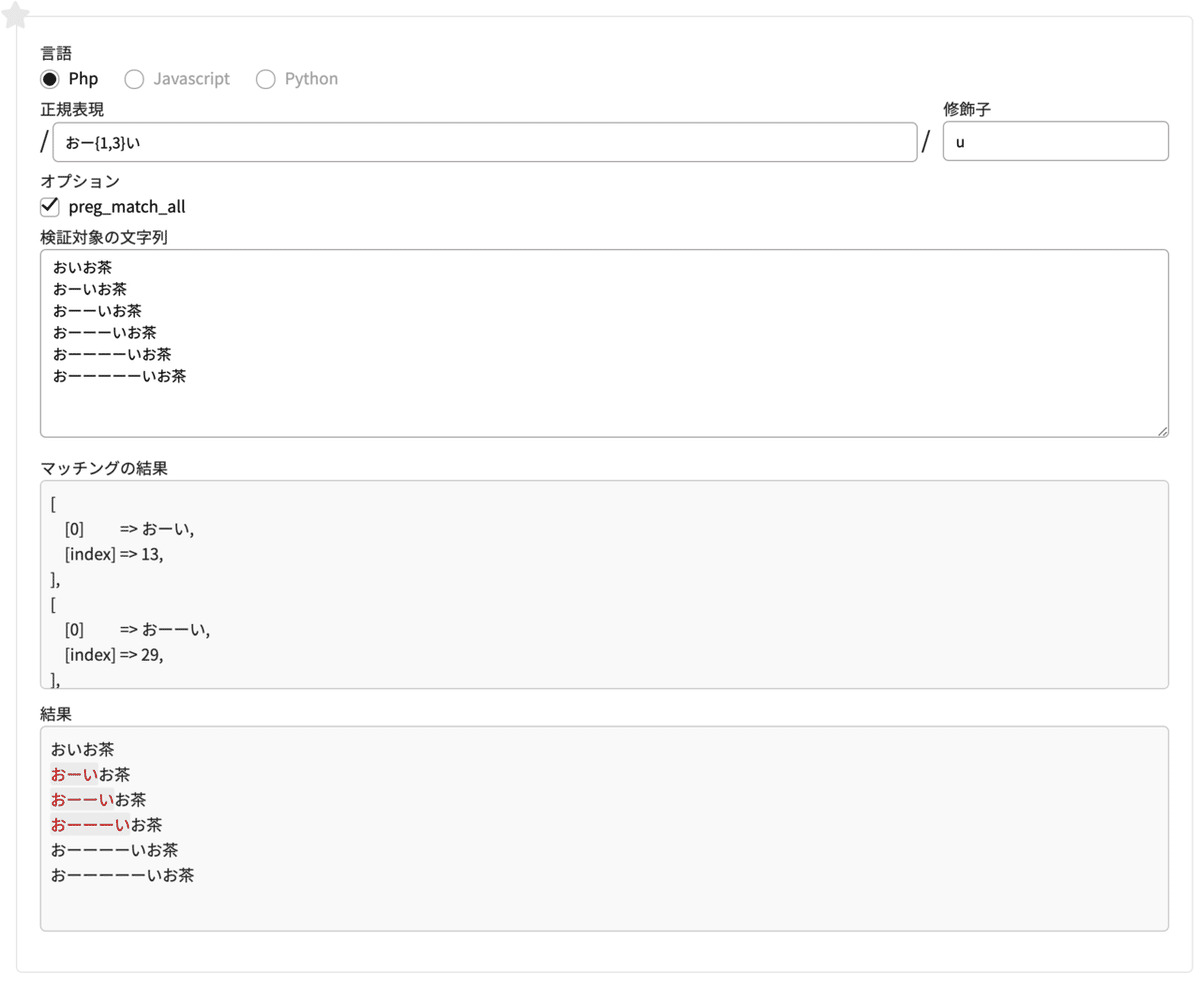
「お」 のあとに 「ー」 が1〜3個あるものがマッチします!
またこの変形として、最小値または最大値のみを指定する事も出来ます。
正規表現 おー{1,} # ーが最低一個以上あるかをチェック
正規表現 おー{,3} # ーが3個以下あるかをチェック
↑↑ PHPとJavaScriptでは使えない・・・!
正規表現 おー{3} # ーが三個ついているもののみチェックただ注意点としては、最大値のみ指定する方法はPHPとJavaScriptでは使えないようです・・・!
正規表現 おー{,3}は、
正規表現 おー{0,3} # ーが3個以下あるかをチェックと同じなので、最大値を指定したい場合は最小値に0を入れてあげましょう!
最長マッチ
量指定子のひとつ。(このあと、逆の最短マッチというのが出てきます)
最長マッチは、可能な限り長くマッチしようとします。そして、量指定子はデフォルトでは最長マッチとなります。
ちょっと何言ってるか分からないですね!実際に見てみましょう!
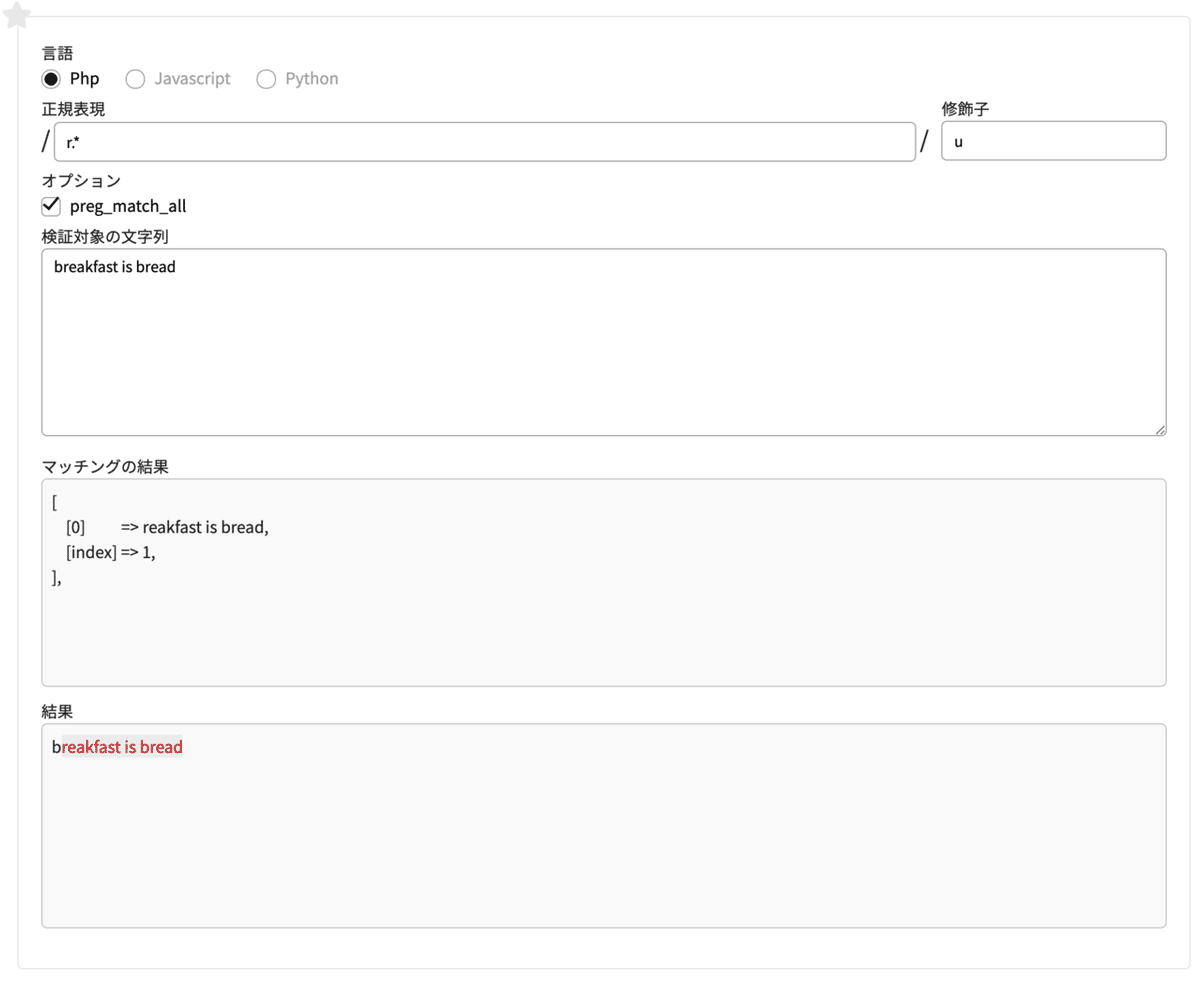
正規表現 r.+
#rの次に、何かしらの文字が一文字以上あるというパターン検索対象の文字列
breakfast is bread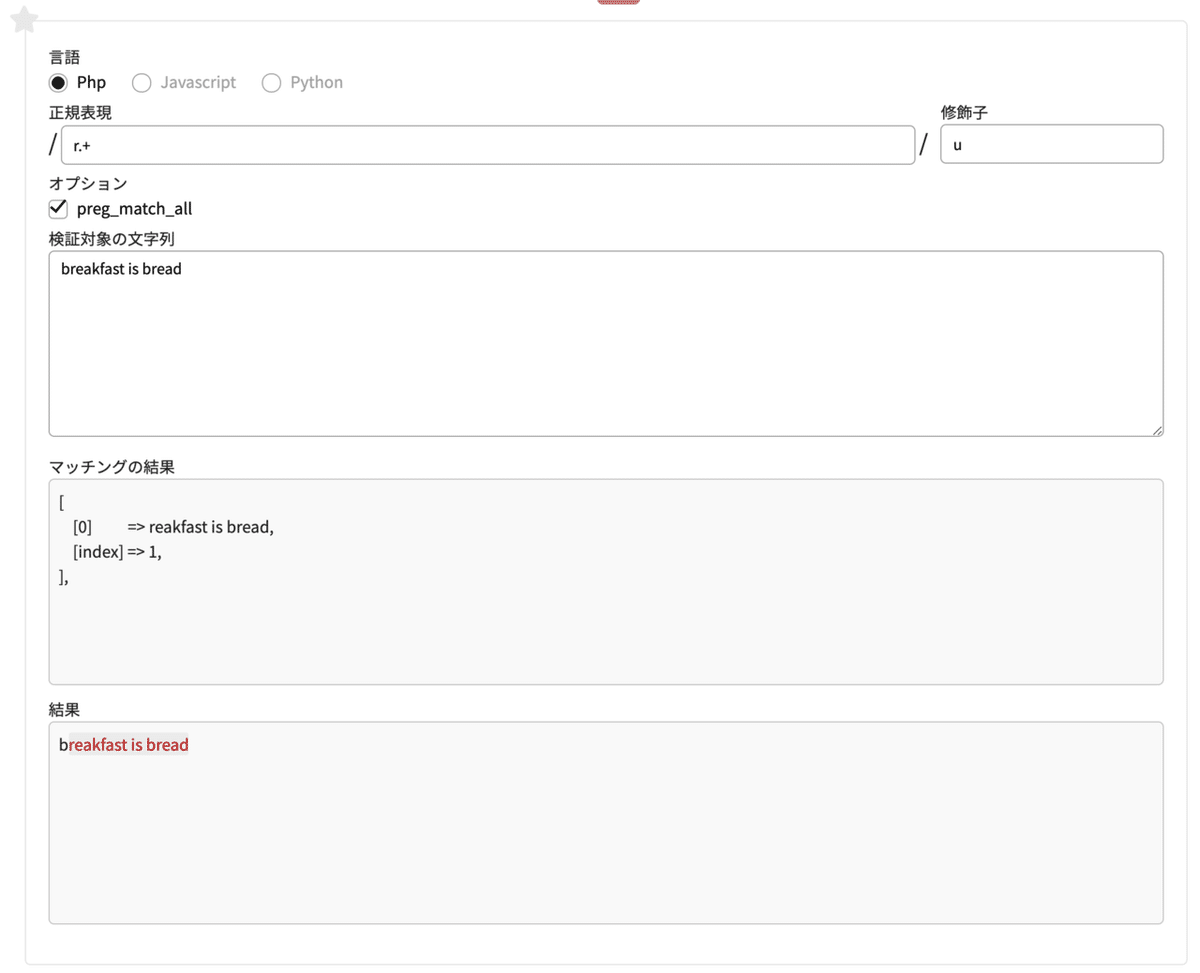
先ほど出てきた「+(直前の文字が1個以上あるかどうか)」を使っています。可能な限り長くマッチするので、「reakfast is bread」がマッチします。
「*(直前の文字が0個以上あるかどうか)」を使っても、結果は同じになります。(そろそろ難しくなってきましたね・・?)
最短マッチ
最長マッチの逆で、可能な限り短くマッチしようとします。
最短マッチで検索したい場合は、以下のように量指定子の後ろに?をつけます。
*?
+?
??
{n,m}?では実際に見てみましょう!
正規表現 r.+?
#rの次に、何かしらの文字が一文字以上ある。
#パターンに当てはまるものがあった時点でマッチを止める検索対象の文字列
breakfast is bread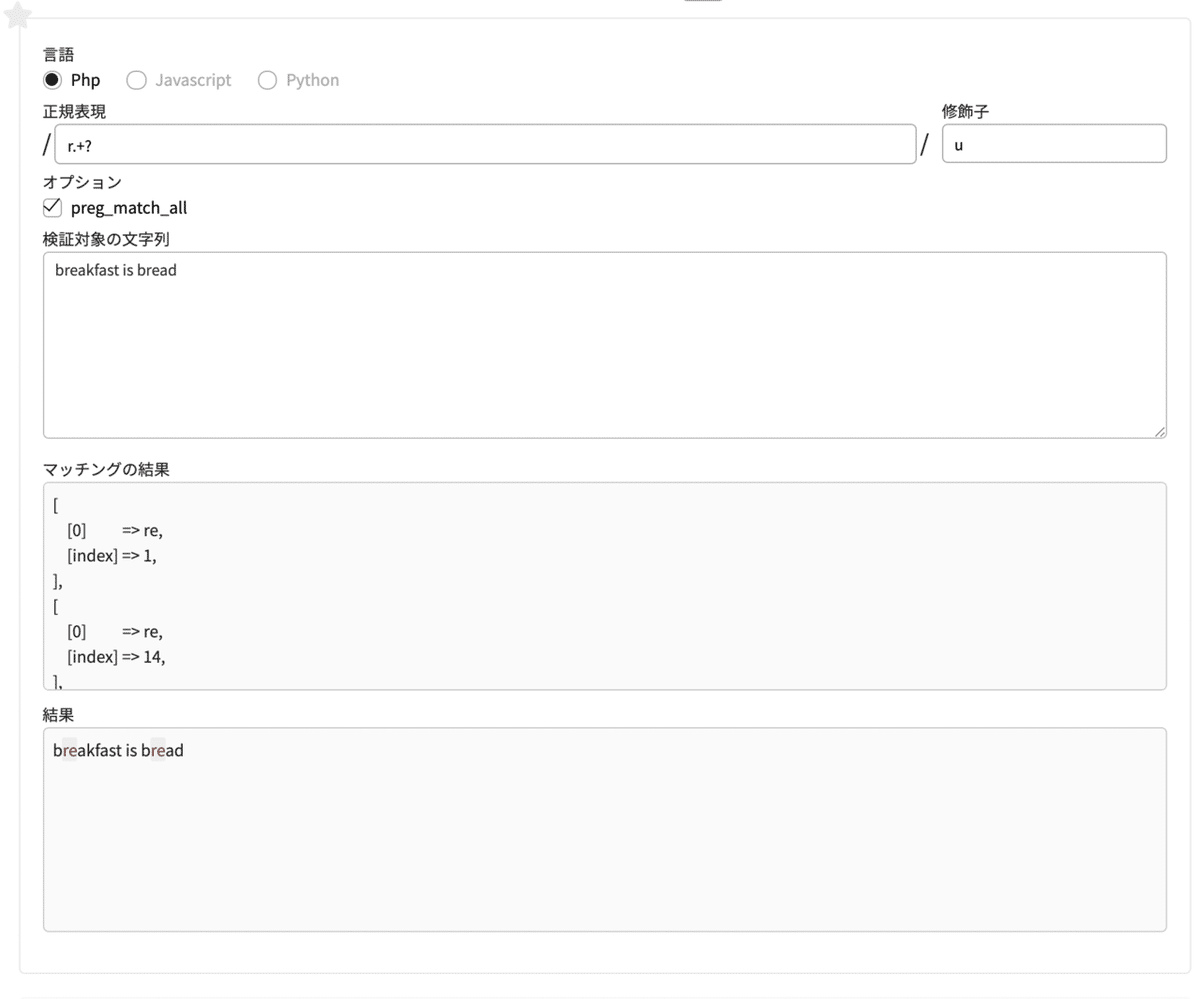
正規表現「r.+?」は、rのあとに何でも良い一文字(.)が1個以上(+)あり、かつ最短マッチ(?)となります。
今回だと、reがマッチします。
あと今更ですが、「preg_match_all」のオプションにチェックを入れると、検索対象の文字列に対して正規表現にマッチしたものは全て抽出し、逆にチェックを入れないと最初にマッチしたものを抽出します。
なので、今回はpreg_match_allにチェックが入っているのでreが2箇所ともマッチしています。
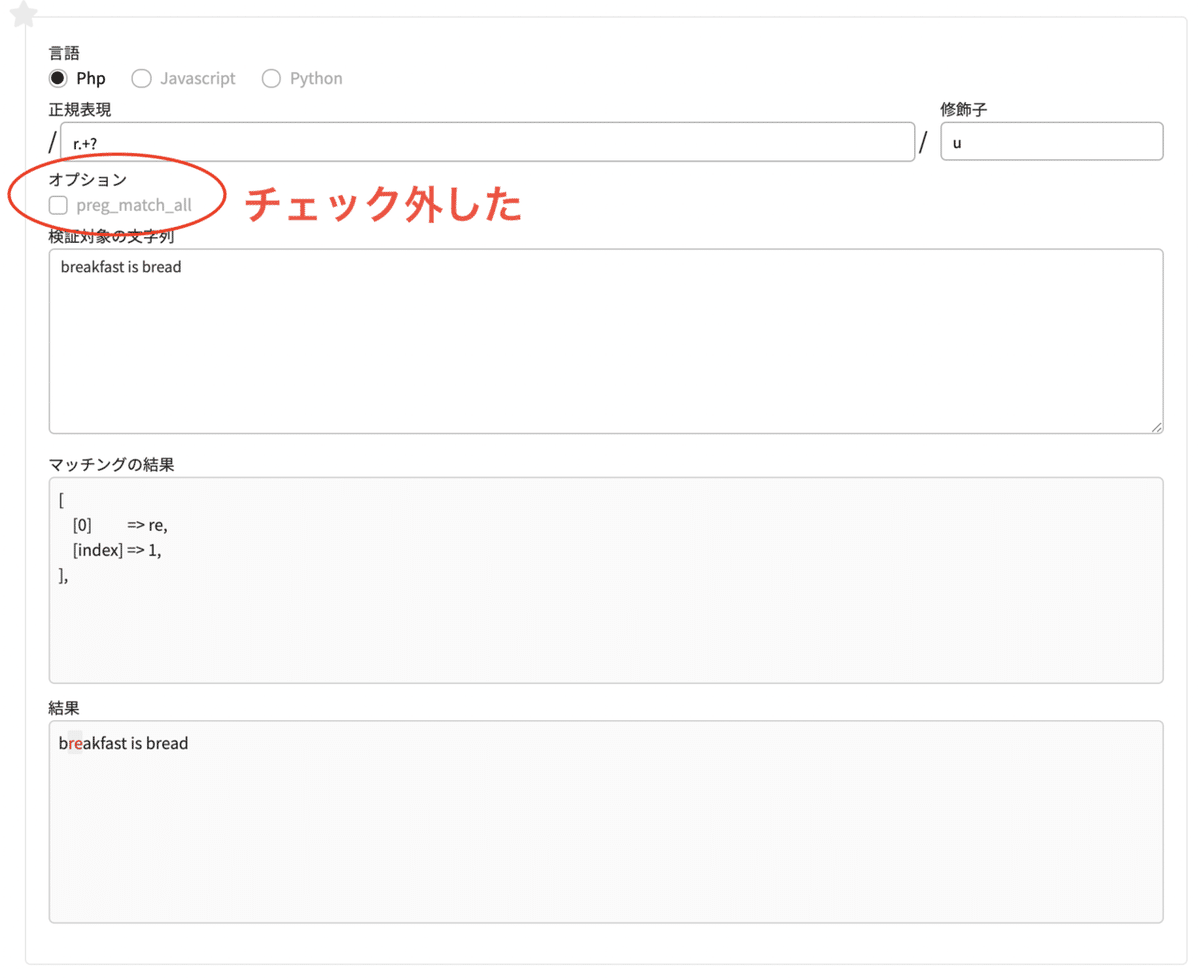
チェックを外すと、最初のreだけマッチします。
では、正規表現を「r.*?」に変えてみたらどうなるでしょうか?
正規表現 r.+?
#rの次に、何かしらの文字が0個以上ある。
#パターンに当てはまるものがあった時点でマッチを止める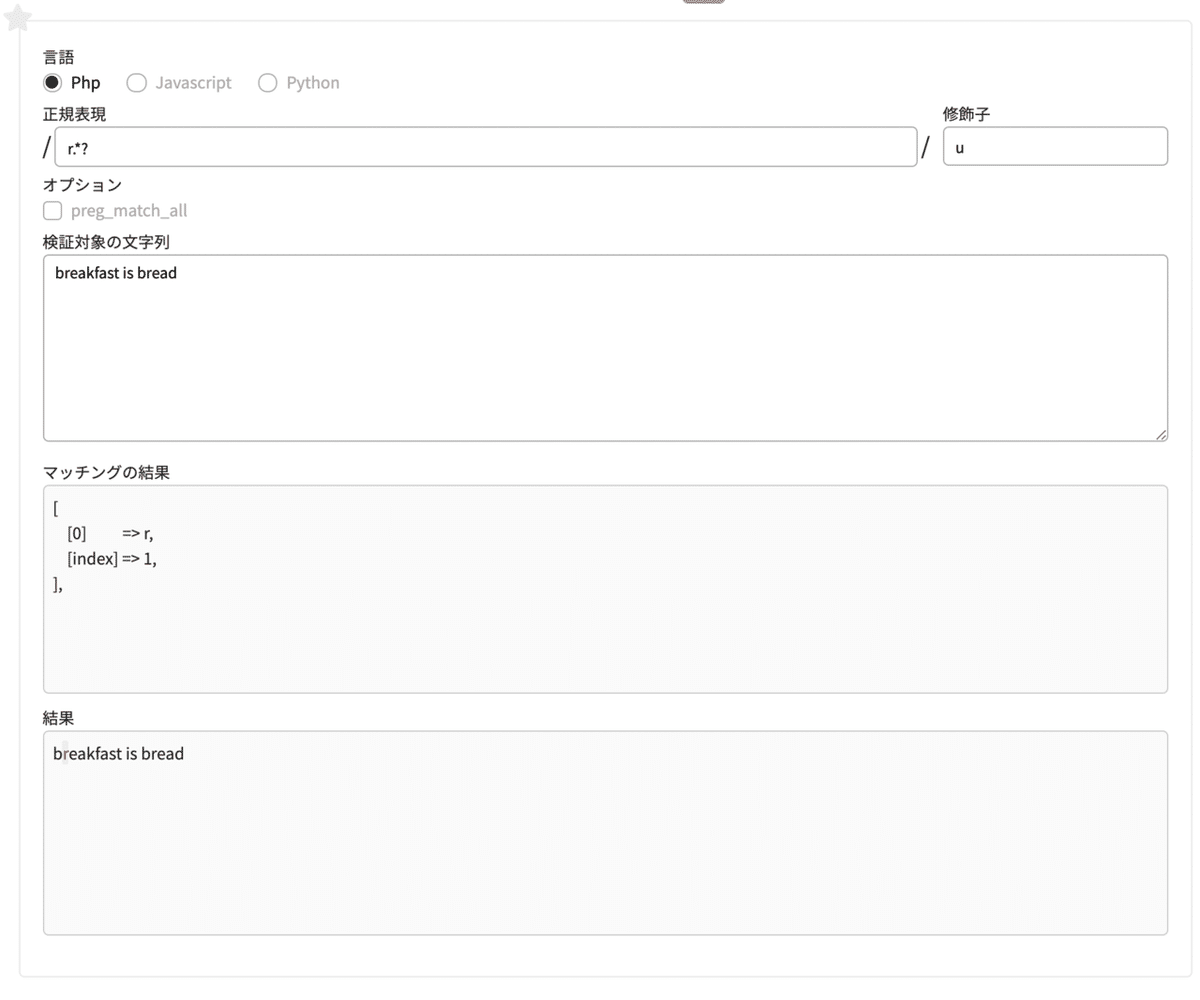
正規表現「r.*?」は、rのあとに何でも良い一文字(.)が0個以上(*)あり、かつ最短マッチ(?)となります。
先ほどはreがマッチしましたが、今回は「rのあとに何でも良い一文字が0個以上かつ最短マッチ」ということで、最初のrのみがマッチします。
以上、最長マッチ・最短マッチでした。
|(パイプ・パイプライン) いずれかの文字列を検索 (〇〇または△△)
いずれかの文字列・条件に合うものを探します。
正規表現 サバ|さわら|マグロ
修飾子 u検索対象の文字列
とんかつカレー
サバカレー
さわらカレー
マグロカレー
カレーうどん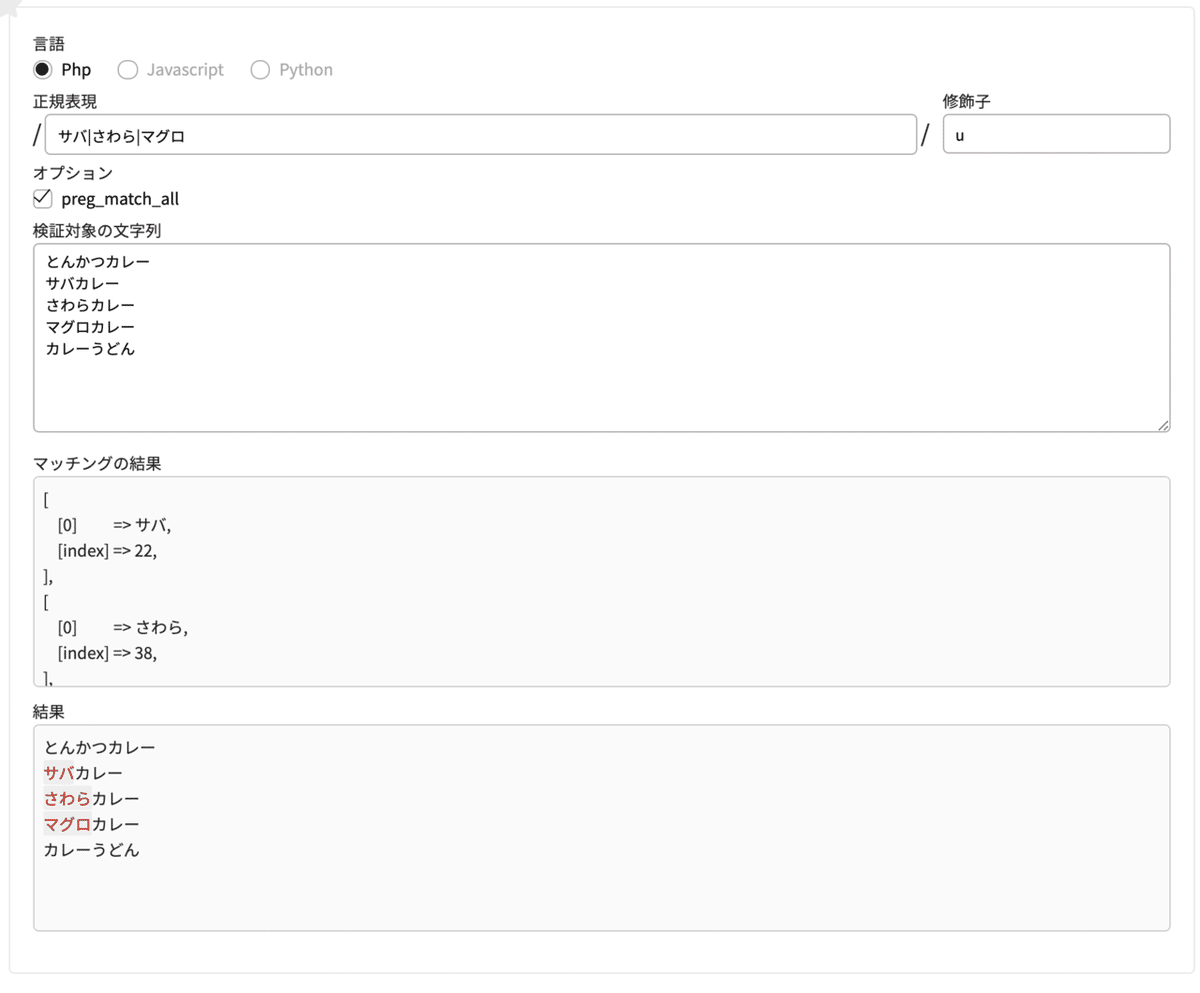
正規表現「サバ|さわら|マグロ」は、「サバ もしくは さわら もしくは マグロ」を含むものを探します。
^(キャレット) 行の頭が〇〇で始まるもの
「^」 は、行の頭にマッチする( = 前方一致)ものを探します。
このあと出てくる行の最後尾にマッチする「$」と合わせて、位置に対してマッチするものを位置指定子(アンカー)と呼びます。
正規表現 ^カレー #行の頭の後ろにカレーがつくものを探す
修飾子 um #m修飾子は、^や$を各行ごとにマッチさせる「行ごと」にマッチさせるため、修飾子に「m」を追加します。
検索対象の文字列
とんかつカレー
サバカレー
さわらカレー
マグロカレー
カレーうどん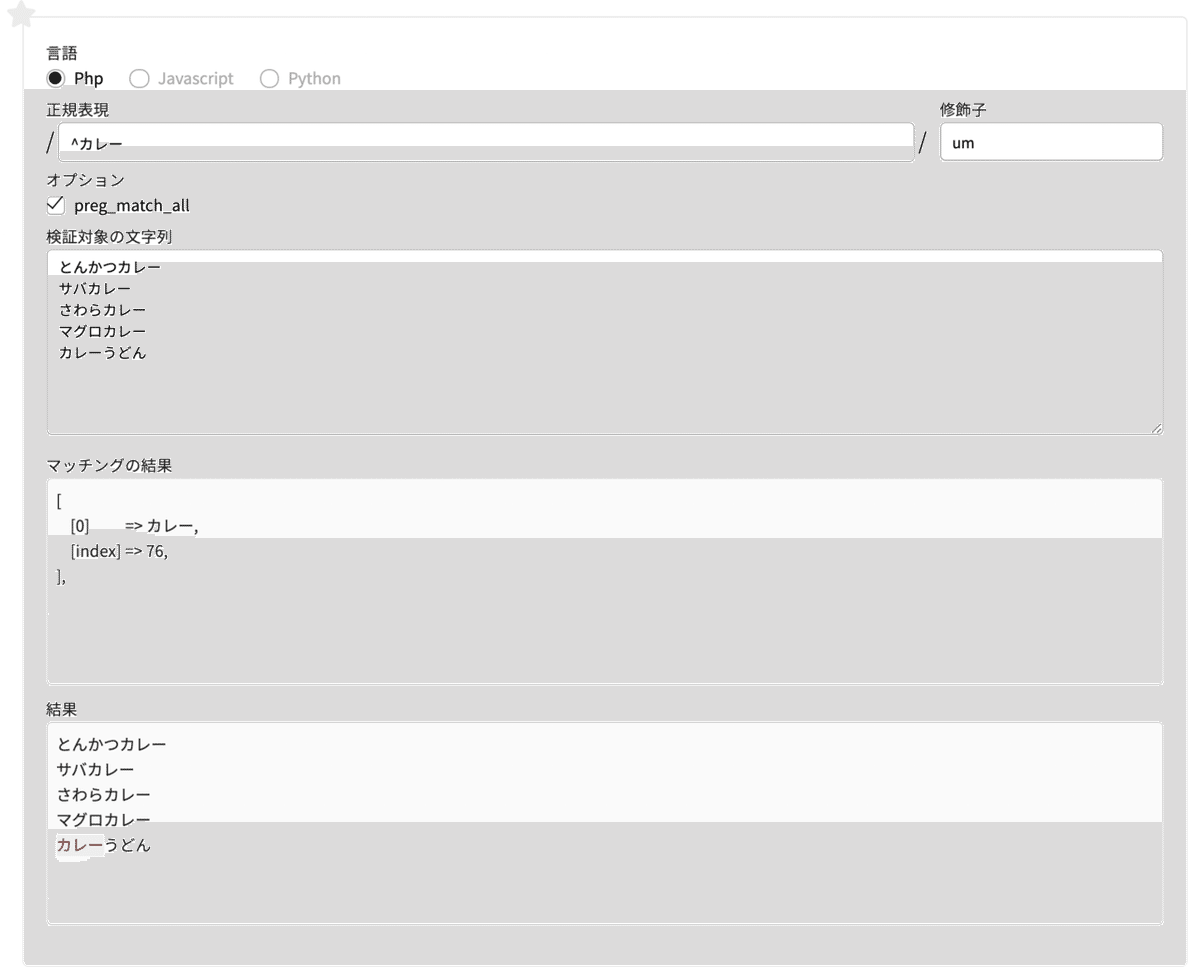
行の始めが「カレー」になっているカレーうどんの、カレーの部分がマッチします。
$(ドルマーク) 行の最後尾が〇〇で終わるもの
「$」 は、行の最後尾にマッチする( = 後方一致)ものを探します。
正規表現 カレー$ #カレーの後ろに行の最後尾がある物を探す
修飾子 um #m修飾子は、^や$を各行ごとにマッチさせる
検索対象の文字列
とんかつカレー
サバカレー
さわらカレー
マグロカレー
カレーうどん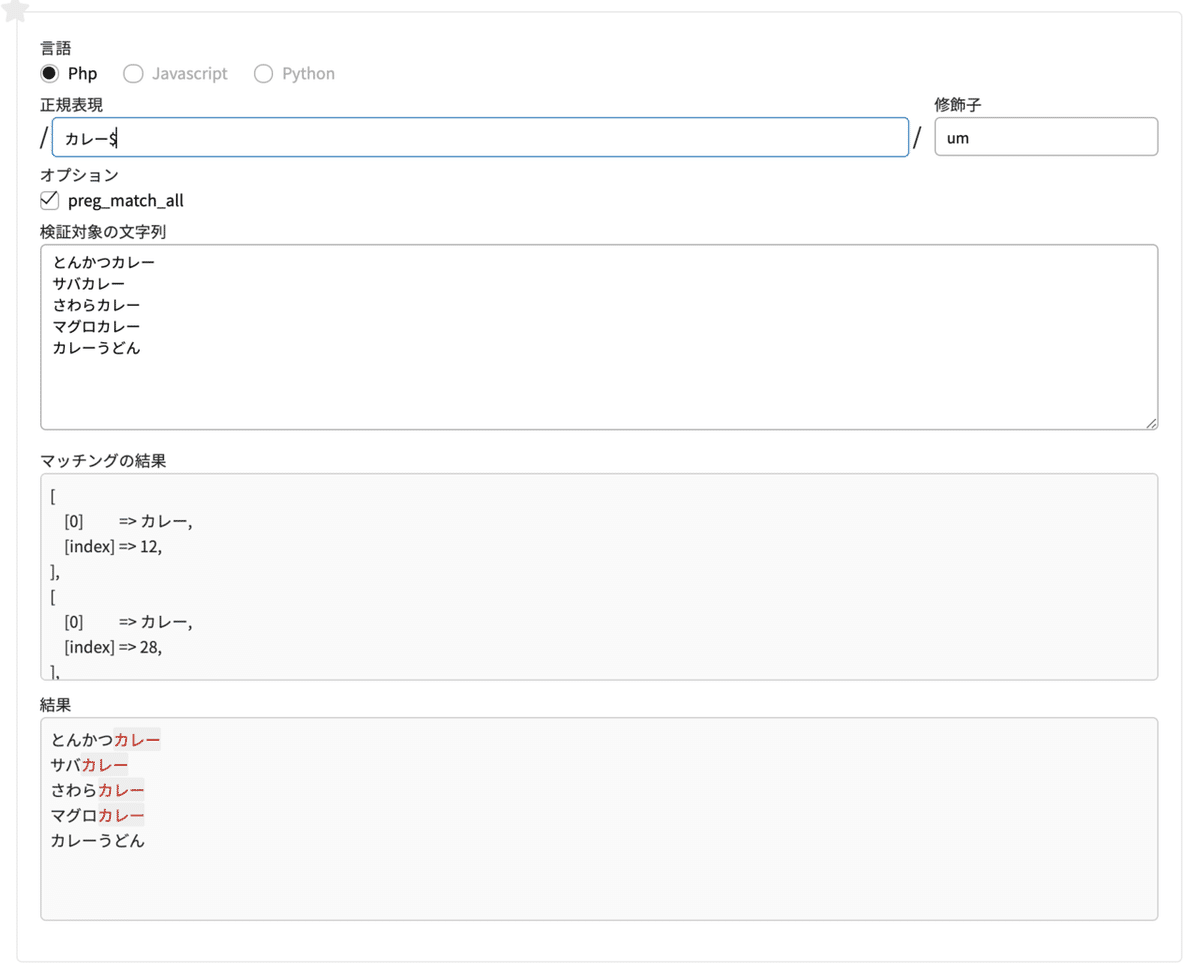
「カレー」で終わる、とんかつカレー・サバカレー・さわらカレー・マグロカレー の、「カレー」の部分がマッチします。
^と$を同時に使うとどうなるか
では、前方一致の「^」と後方一致の「$」を同時に使うとどうなるのでしょうか?
正規表現 ^カレー$検索対象の文字列
とんかつカレー
サバカレー
さわらカレー
マグロカレー
カレーうどん
カレー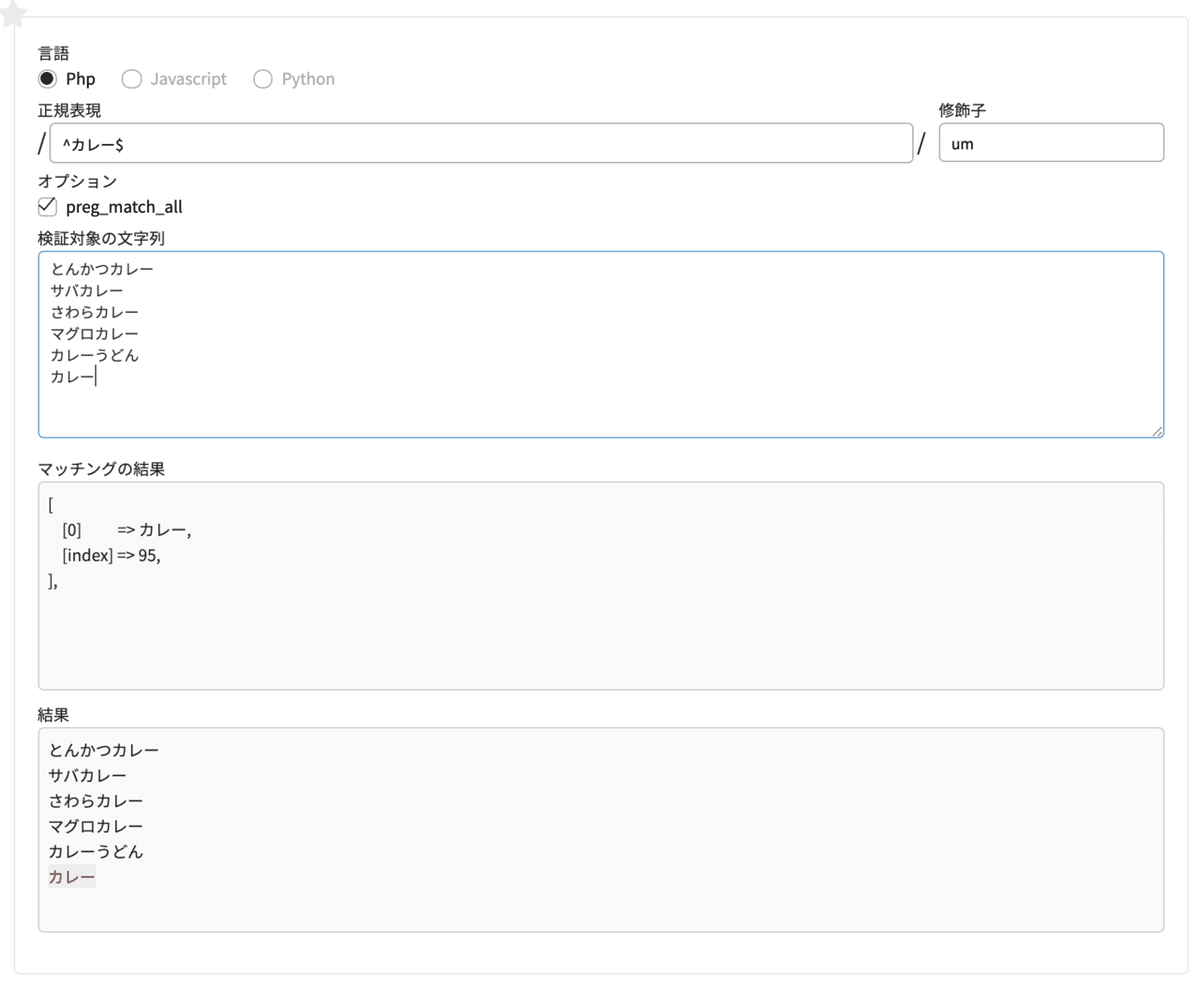
前方一致の「^」と後方一致の「$」を同時に使うということはつまり、完全一致です。カレーだけがマッチします。
[](角カッコ) 指定した文字のうちのどれか
文字クラスと呼びます。
カッコの中に任意の文字を指定する事で、カッコ内の文字のいずれか一文字といったパターンを書く事が出来ます。
[ABCDEFGHIJKLMNOPQRSTUVWXYZ]
# A~Zのうちどれか
# [A-Z]とも書けますそれでは、この文字クラスを応用して確認してみます!
正規表現 A[A-Z]+?検索対象の文字列
AB
ABC
ABC111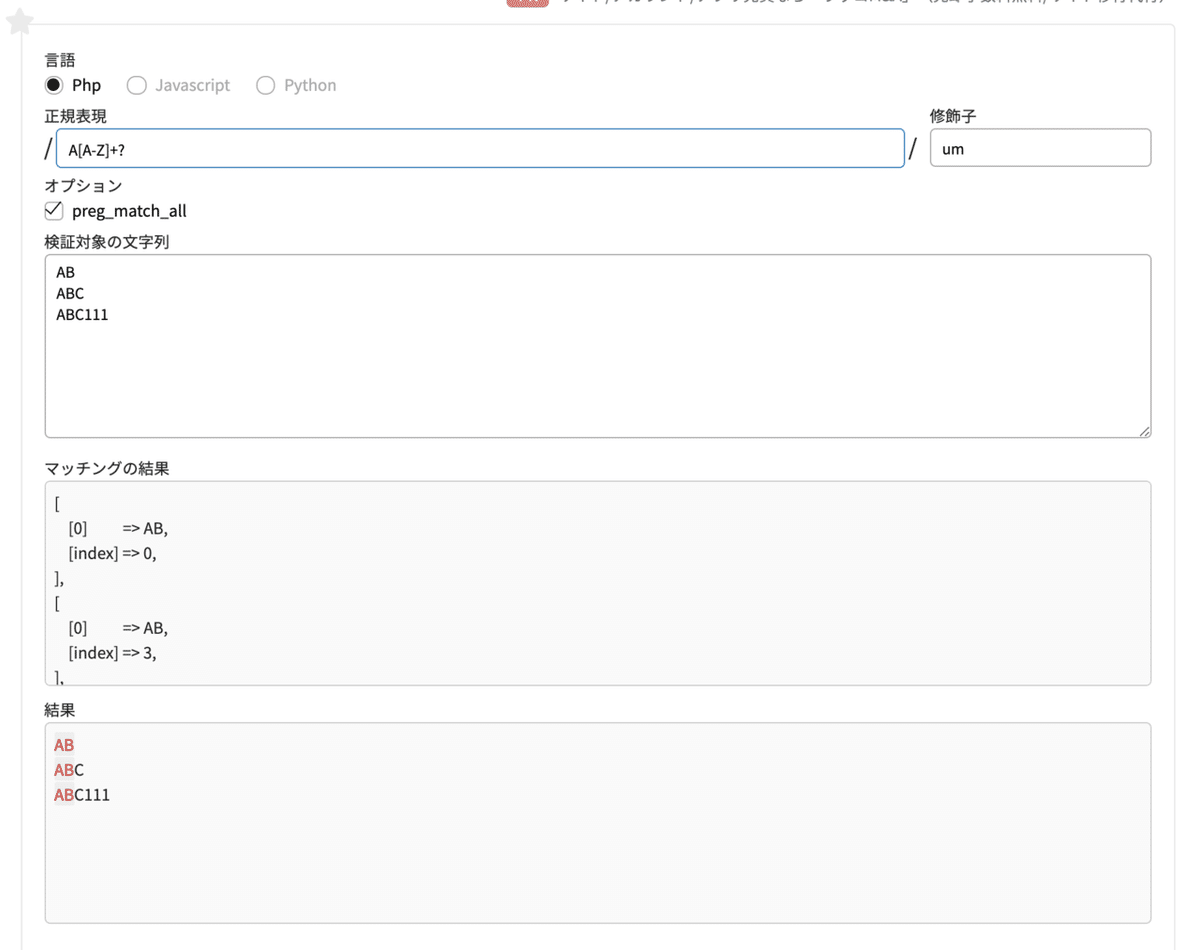
正規表現「A[A-Z]+?」は、「Aのあとに、大文字アルファベット(A~Z)のうちどれかが1文字以上繰り返され、かつ最短マッチ」ということになります。
結果は、
AB は全てマッチ
ABC はABがマッチ
ABC111 はABがマッチ
となります。ちょっと難しくなってきましたねぇ〜
() (丸カッコ)文字のグループ化
正規表現 (サバ|マグロ)カレー
修飾子 u検索対象の文字列
サバカレー
サバサバカレー
マグロカレー
カレー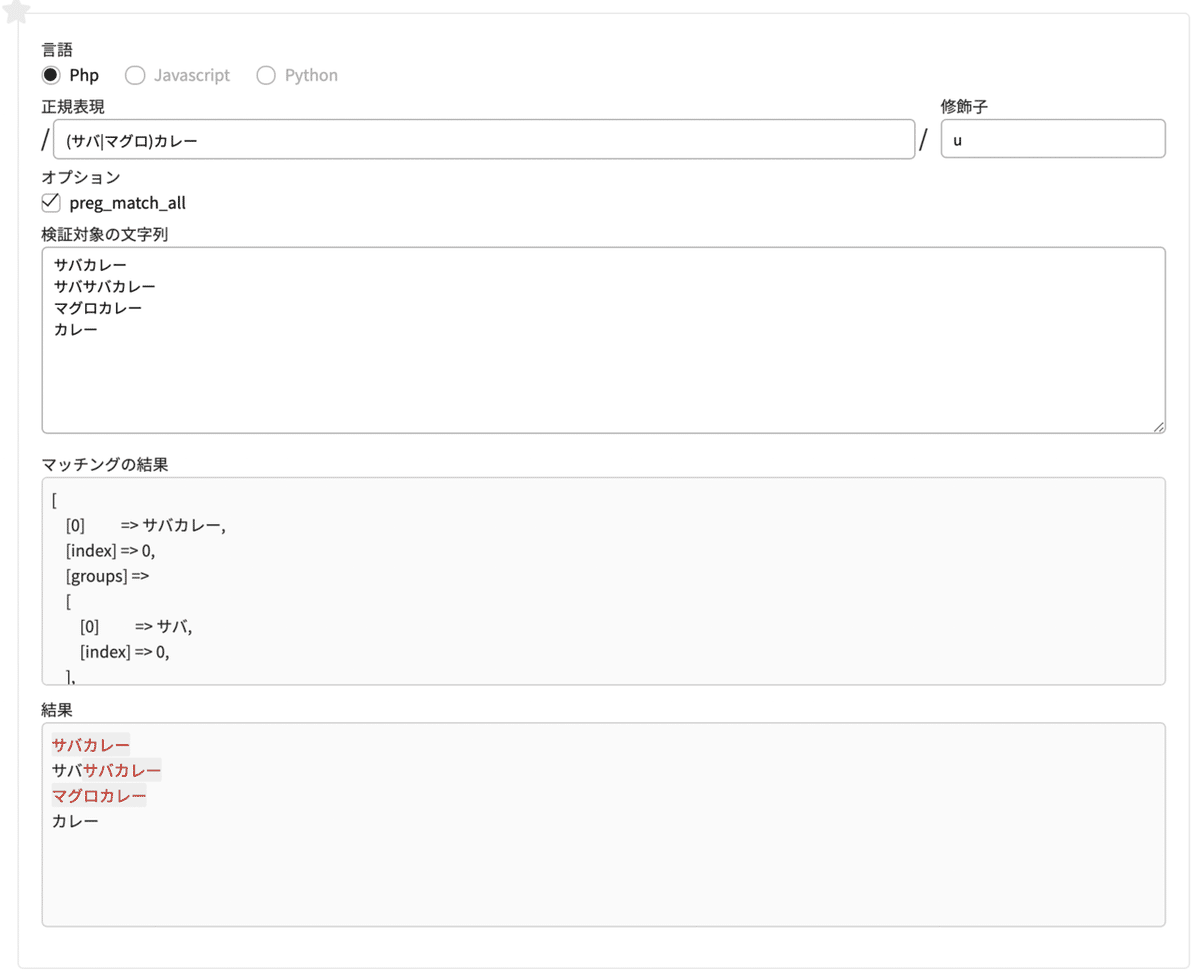
サバカレー もしくは マグロカレー がマッチします。
以上で勉強会で扱ったPHPの基本的な正規表現は終了です!
せっかくなので、勉強会で触れられなかった他のメタ文字をいくつか紹介します!
\d 1つの半角数字
結論から言うと、[0-9]と同じです!半角数字を表します。
正規表現 \d\d\d-
修飾子 u検索する文字列
01-
012-
0123-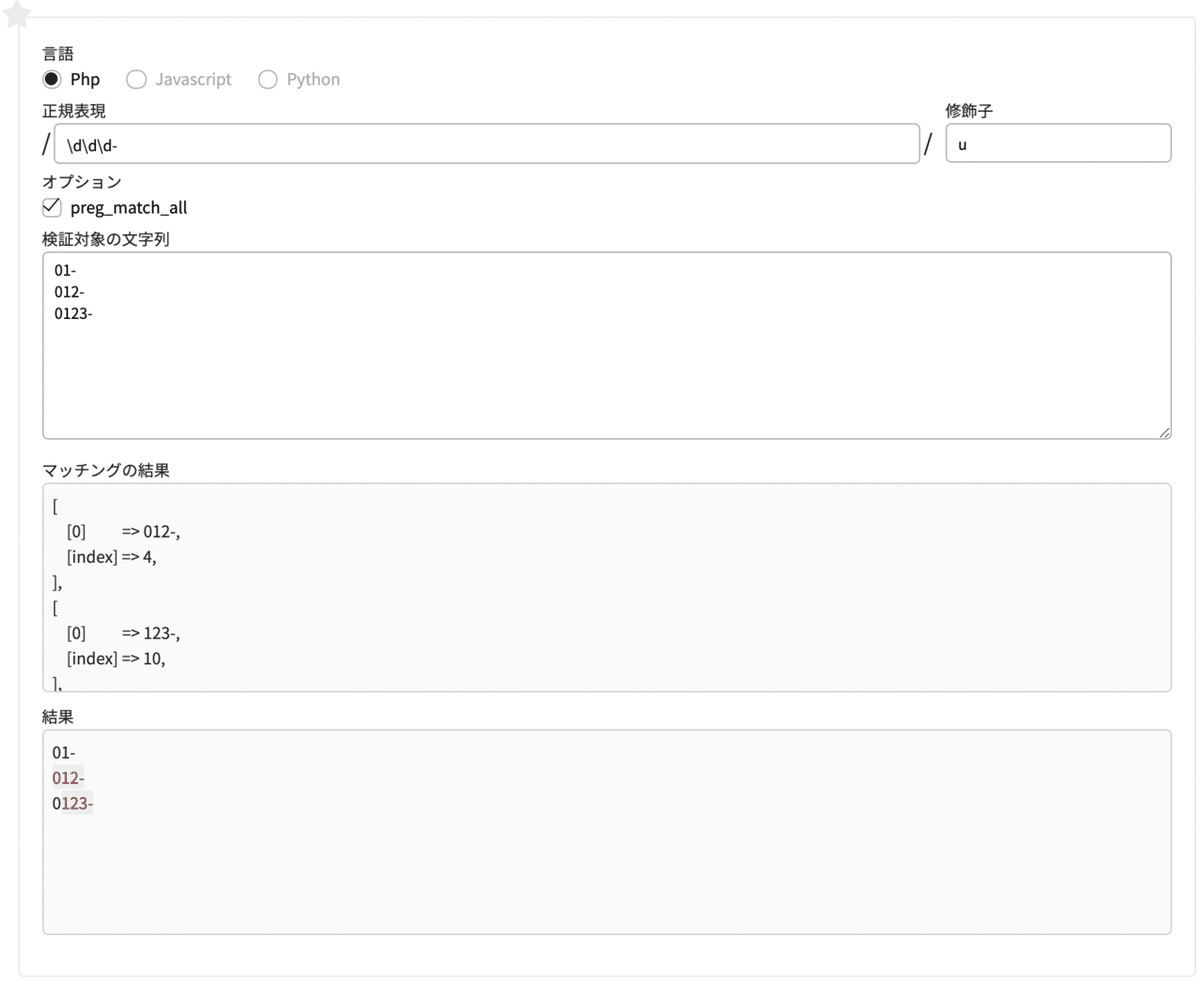
\t タブ文字
ブラウザで通常のテキスト入力をしている時はあまり起きないですが、エンジニアならお馴染みのtabキーによるスペースです。エディタで入力したものをコピペしたりすると、ブラウザ上でもtabスペースが入力されてしまうことはありますね。
正規表現 [a-z][\t][0-9]
修飾子 uけ検索する文字列
a0
aa-0
aaa 00 //わかりづらいけど a と 0 の間にタブスペースが入っている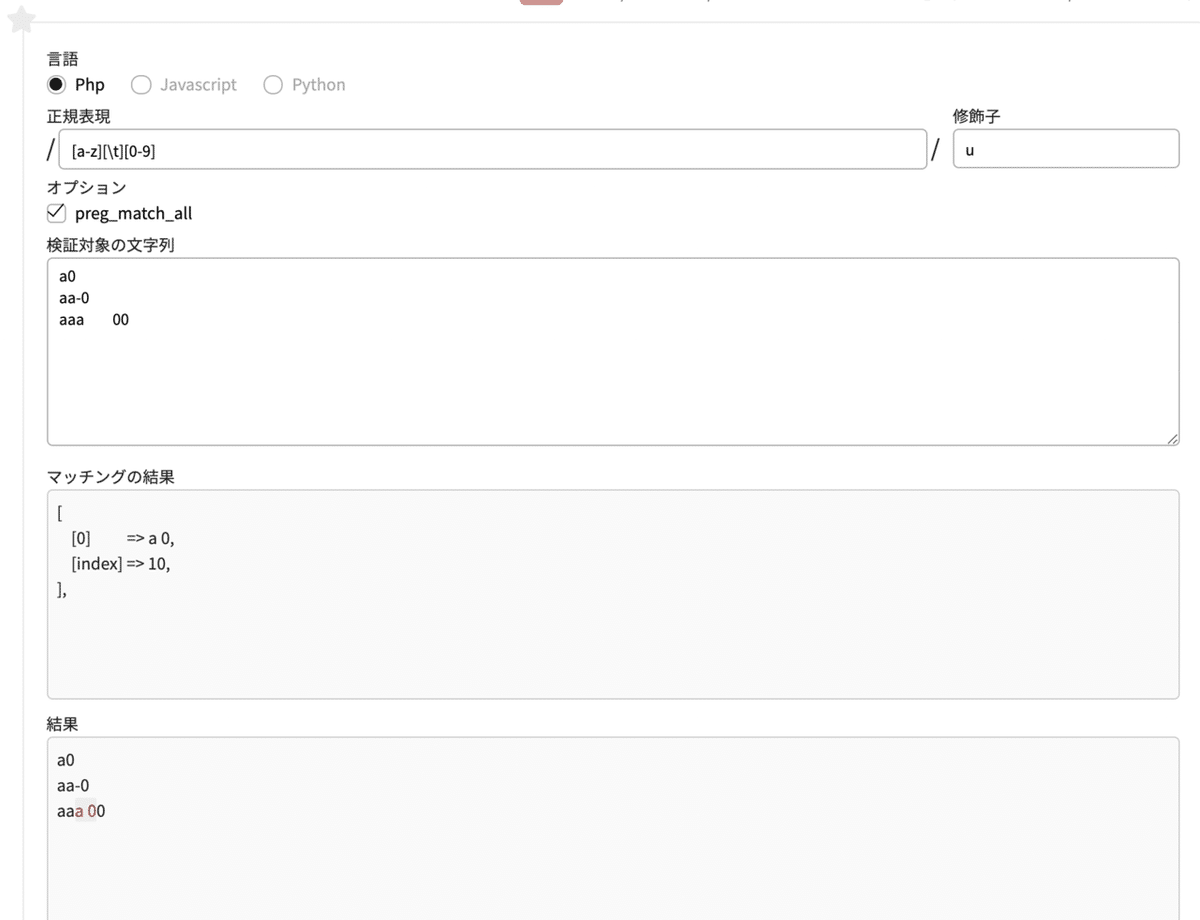
小文字アルファベット([a-z])と半角数字([0-9])の間にタブスペースのある a 0 がマッチします。
\s 空白文字全般
\s は、\t によるタブスペースを含む半角スペース・全角スペース・改行文字などの空白文字全般です。
正規表現 [a-z][\s][0-9]
修飾子 u検索する文字列
a0
aa-0
aaa 00 //タブスペース入り
aaa 0 //半角スペース入り
aaa 0 //全角スペース入り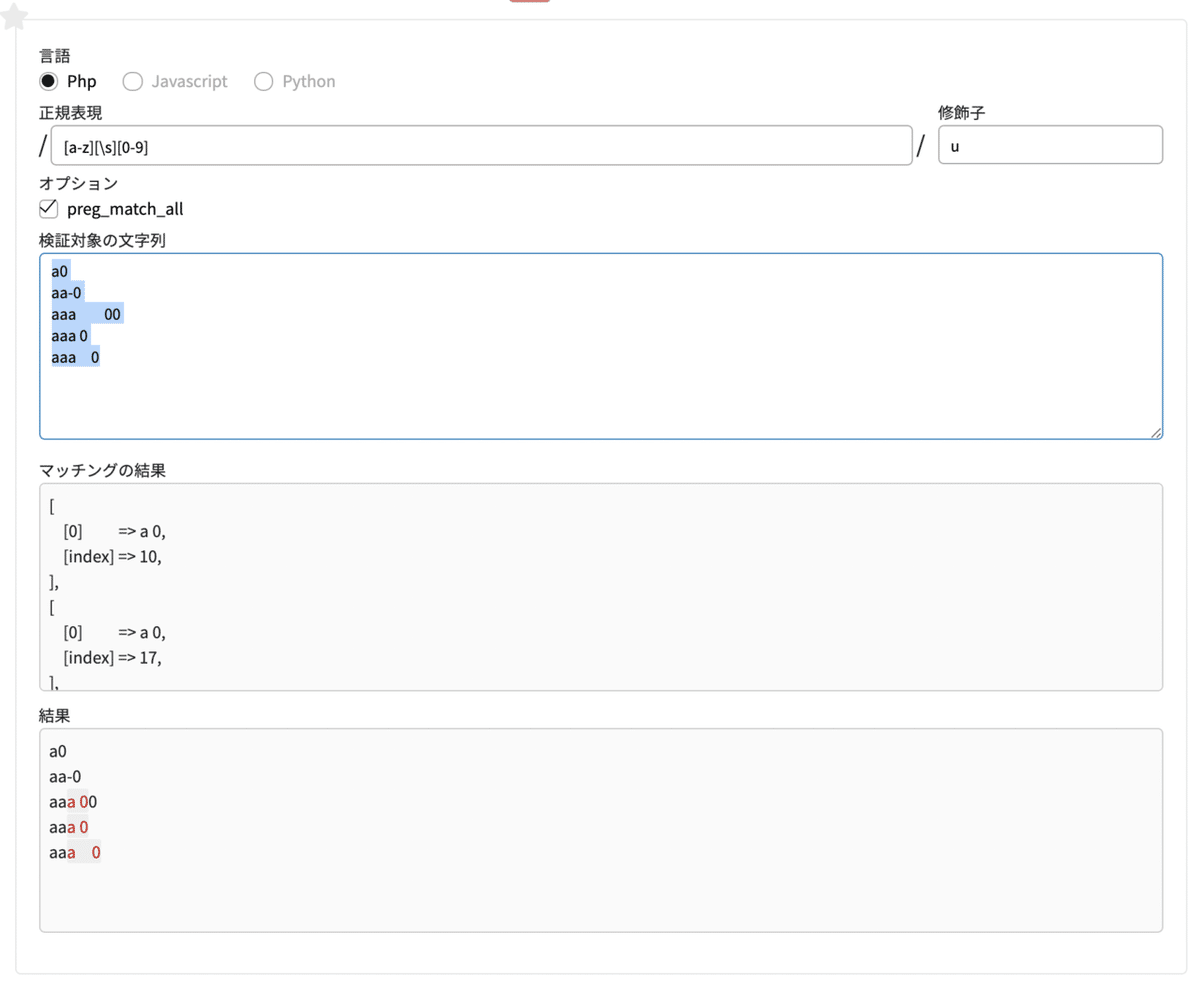
^ (キャレット)[]の中で先頭につけると否定条件
先ほど前方一致で登場した ^(キャレット) ですが、[]の中で先頭につけると否定条件という全く違う挙動をします。
正規表現 [^abc]
修飾子 u検索する文字列
aaa
bbb
ccc
ddd
abcd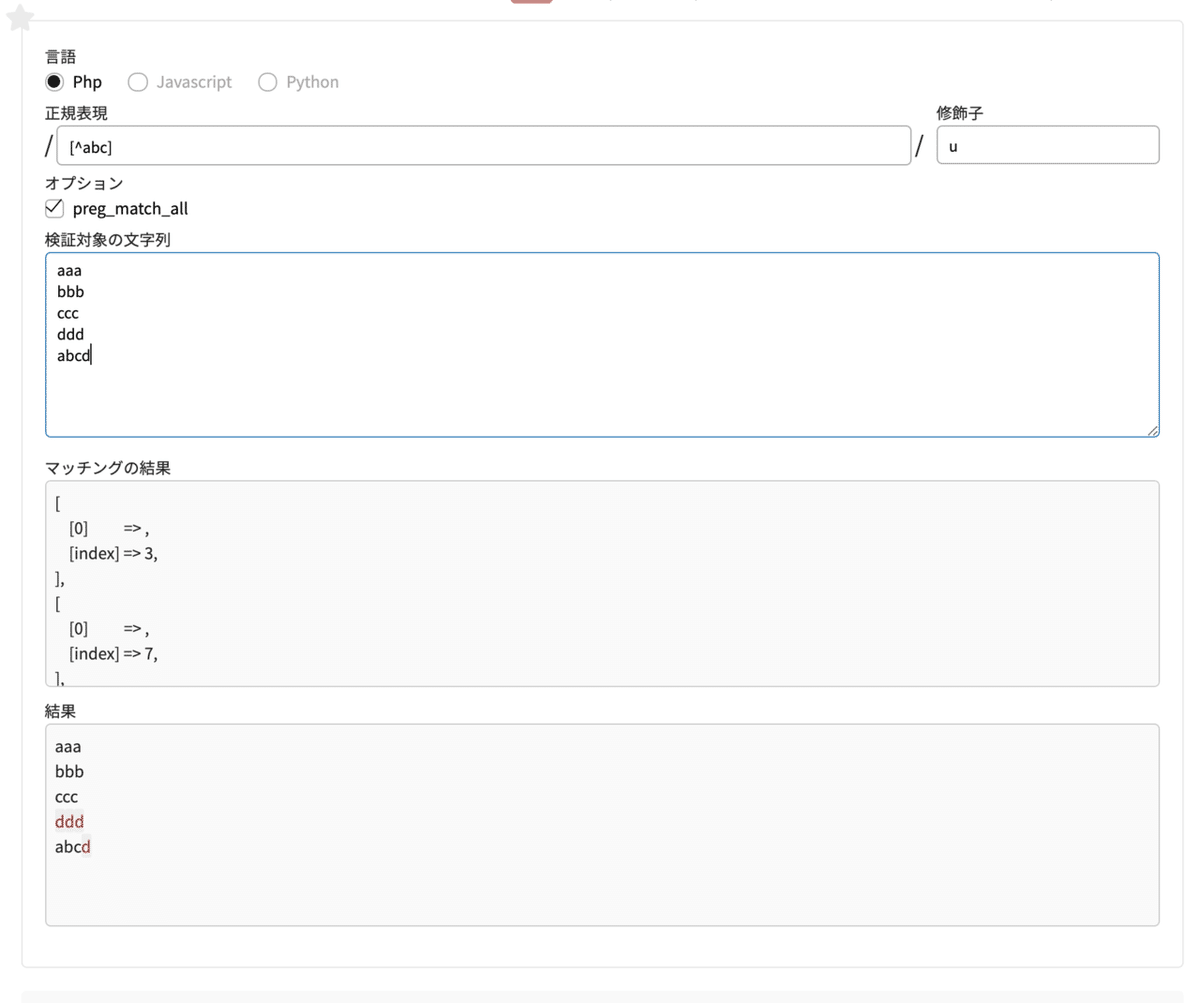
[^abc]は、a,b,c以外のアルファベットにマッチします。
電話番号の正規表現を読み解いてみる
最後に、この記事で紹介されていた電話番号の正規表現「 \d{2,5}[-(]\d{1,4}[-)]\d{4} 」を読み解いてみます!
まずは大きくいくつかのブロックに分解して考えてみます。
\d{2,5}[-(]\d{1,4}[-)]\d{4} は、以下5つに分けて考えることができそうです!
\d{2,5}
[-(]
\d{1,4}
[-)]
\d{4}
一つずつみていきます!
\d{2,5} ・・・ 半角数字が、2〜5文字
[-(] ・・・ '-' もしくは '('
\d{1,4} ・・・ 半角数字が、1~4文字
[-)] ・・・ '-' もしくは ')'
\d{4} ・・・ 半角数字4桁
つまり、以下たぶんマッチするやつ
090-0000-0000
090(0000)0000
03-1234-5678ありえないけどマッチしちゃうやつ
090-0000)0000
090(0000-0000
99999-1234-5678 //桁数多いそそして、マッチしないやつ
09000000000 // 区切りのハイフン・かっこなし
090 0000 0000 //スペースで区切り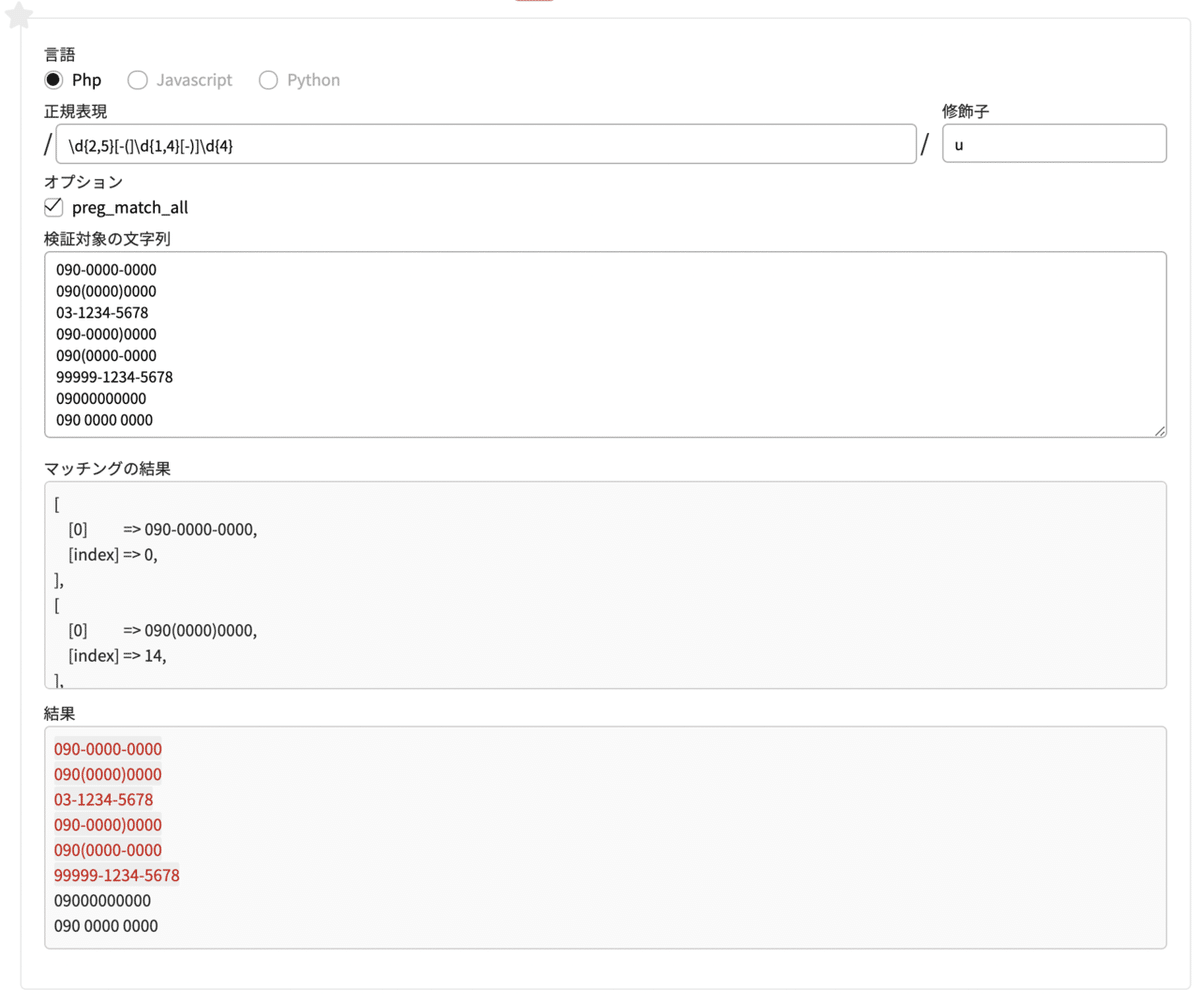
読、、、め、、、、た、、、、、!?ってことでいいかな!?!?!
まとめ
いろいろ調べていると、まだまだ複雑な条件式もあります。
初心者歓迎!手と目で覚える正規表現入門・その1「さまざまな形式の電話番号を検索しよう」にもありますが、たとえばメールアドレスの「99.99%正確な正規表現」はこんな感じになるそうです。

初心者歓迎!手と目で覚える正規表現入門・その1「さまざまな形式の電話番号を検索しよう」で、以下のようにまとめられています。
毎回こんな複雑な正規表現を考えている時間はないでしょうし、もしうまく動かなかったときに正規表現を読み解いてデバッグするのもほぼ不可能です。
というわけで、現実的には「100%完璧ではなく、そこそこ正しいレベルの正規表現」で妥協することがよくあります。
そして、「そこそこ正しい」の度合いは要件によって変わってきます。
たとえば、大量のテキストから「電話番号っぽい文字列」を抽出して、人間が目視で判断するのであれば、今回作った \d{2,5}[-(]\d{1,4}[-)]\d{4} でも十分でしょう。
そう、完璧など現実にはありえないのです!!!
ただ今回習得したレベルで簡単なgrepやバリデーションが行えるようになったことは確かですし、今後さらに難しい正規表現を理解していく最初の一歩を踏み出せました!
この記事をまとめる過程で改めて勉強会の内容を1から振り返り、非常に有意義でした。今回はPHPが題材でしたが、他の言語でもオプションや細かい仕様の違いはあれどベースは同じなので、応用は利きます。
この記事に一番助けられるのは、今後の自分であることは間違いないでしょう!
ではまた!
参考