
【データの集め方講座】当日の株式情報を最速で集める [Pandas datareader]

はじめに
ごあいさつ
ご高覧いただきありがとうございます.
ソフトウェアエンジニアのKitaharaです.
本日は株価データの収集方法を解説します!
もしかしたら「Kitaharaさん前にも株データの記事かいていませんか?」という方もいるかもしれません. おそらく下記の記事のことだと思います.
今回は上記の記事とは別の方法で株データを集める方法を見つけたのでやってみることにします.
Pandas DataReaderを使ってみた
Pandas DataReaderを使ってみる
Pandas DataReaderとは
The Pandas datareader is a sub package that allows one to create a dataframe from various internet datasources, currently including:
Yahoo! Finance
Google Finance
St.Louis FED (FRED)
Kenneth French’s data library
World Bank
Google Analytics
翻訳すると
Pandas datareaderとは様々なインターネットの情報資源からデータフレームを作成することを可能にするサブパッケージである
といったところでしょうか.
何にせよ株情報を収集できるのは大きそうですね.
他のデータも面白そうなデータの取得先が多いので次回以降の記事にしてみようと思います.
補足: pandas-datareaderの公式サイト
以下の記事を参考にしながらGoogle Colabでデータ取得を行ってみました.
(ローカルだとPandasインストールするの結構時間かかります)
# ライブラリのimport (pip install 不要)
import pandas_datareader.data as web
# 株価情報の取得
df = web.DataReader("9020.T", data_source='yahoo', start='2010-01-01')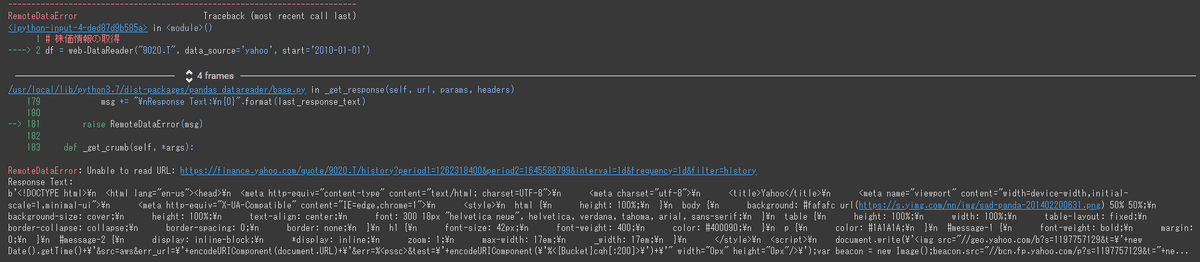
エラーが出没しました.
???って感じですよね
エラーの回避
少し調べものをしてみました.
調べているとこんな記事が…
Yahoo Finance の規約に引っかかっているから対策されて使えないという話でした. 前の記事にも書きましたが, そもそもYahoo Financeはスクレイピング禁止だから使えなくなったというのです.
まあ, それはそうなのですが, PandasというPythonの超有名ライブラリなら何かしらの対応をしているのではないかと思い, 公式をもう一度探してみました. すると以下の記事を発見しました.
そこにはexampleとして以下のコードを発見.
先程のコードと違ったので動くかもしれないと思い実行してみました.
INPUT
import pandas_datareader.data as web
from pandas_datareader.yahoo.headers import DEFAULT_HEADERS
import datetime
import requests_cache
expire_after = datetime.timedelta(days=3)
session = requests_cache.CachedSession(cache_name='cache', backend='sqlite', expire_after=expire_after)
session.headers = DEFAULT_HEADERS
start = datetime.datetime(2010, 1, 1)
end = datetime.datetime(2013, 1, 27)
f = web.DataReader("F", 'yahoo', start, end, session=session)
f.loc['2010-01-04']OUTPUT
High 1.028000e+01
Low 1.005000e+01
Open 1.017000e+01
Close 1.028000e+01
Volume 6.085580e+07
Adj Close 6.898167e+00
Name: 2010-01-04 00:00:00, dtype: float64動きました.
次に日本株を検索してみましょう.
INPUT
import pandas_datareader.data as web
from pandas_datareader.yahoo.headers import DEFAULT_HEADERS
import datetime
import requests_cache
expire_after = datetime.timedelta(days=3)
session = requests_cache.CachedSession(cache_name='cache', backend='sqlite', expire_after=expire_after)
session.headers = DEFAULT_HEADERS
start = datetime.datetime(2010, 1, 1)
end = datetime.datetime(2013, 1, 27)
f = web.DataReader("9020.T", 'yahoo', start, end, session=session)
f.loc['2010-01-04']OUTPUT
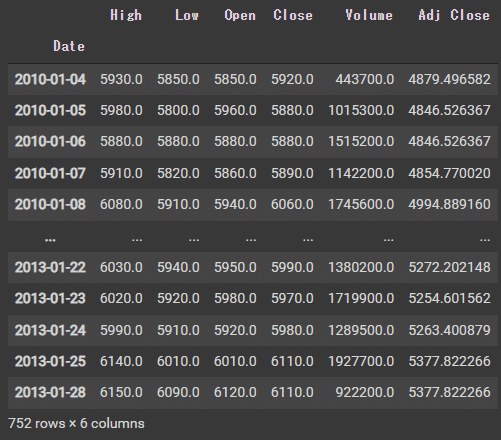
日本株も問題なく動いているようです.
最後にどれだけの期間が掲載されているのかを見てみましょう.
明日の予測をしたいのに今日のデータが無ければ意味がないですからね…
INPUT
import pandas_datareader.data as web
from pandas_datareader.yahoo.headers import DEFAULT_HEADERS
import datetime
import requests_cache
expire_after = datetime.timedelta(days=3)
session = requests_cache.CachedSession(cache_name='cache', backend='sqlite', expire_after=expire_after)
session.headers = DEFAULT_HEADERS
start = datetime.datetime(2022, 1, 1)
end = datetime.datetime(2022, 2, 22)
f = web.DataReader("9020.T", 'yahoo', start, end, session=session)f.tail()OUTPUT
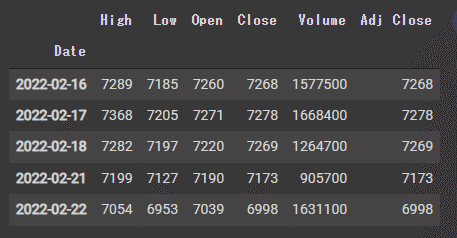
今日のデータまでしっかり取得できていますね.
これは便利だ…!
他の回避方法
下記の記事に別の方法が記載されていました
yfinanceというライブラリをpip install して使うことができます.
INPUT
from pandas_datareader import data as pdr
import datetime
import yfinance as yf
start = "2020-1-1"
end = datetime.date.today()
ticker = "9020.T"
yf.pdr_override()
df = pdr.get_data_yahoo(ticker, start, end)
dfOUTPUT

コチラでも無事に出力することができています.
APIを叩くときのお約束
APIを叩くときにはデータの提供元のサーバに負荷をかけないようにしなければいけません. 先程の公式サイトにも以下の様な警告がなされています.
Making the same request repeatedly can use a lot of bandwidth, slow down your code and may result in your IP being banned.
pandas-datareader allows you to cache queries using requests_cache by passing a requests_cache.Session to DataReader or Options using the session parameter.
Below is an example with Yahoo! Finance. The session parameter is implemented for all datareaders.
翻訳すると
同じリクエストを連続して送ることは帯域幅を大量に使用し, コードの実行を遅くするほか, IPがBANされる可能性があります.
pandas-datareaderでは, DataReaderやOptionsにsessionパラメータを使ってrequests_cache.Sessionを渡すことで, requests_cacheを使ってクエリをキャッシュすることができます.
下記はYahoo! Financeの例です. セッションパラメータはすべてのデータリーダーに埋め込まれています.
といったところでしょうか.
活用方法の考案
上記の通り, 連続してクエリを送れない以上, すべてのデータを集めるということはまず不可能です.
なのですぐに欲しい株式データのみを10数件検索してモデルに組み込む等の方法が現実的なのかなと思います. (あとで無尽蔵からdownloadすればいいだけです)
おわりに
今回はPythonを使って株式情報を収集する方法を解説しました!
参考になったという方はぜひハートボタンを押していってください!
モチベーションが上がります!
記事内で不明な点等ございましたら気軽にご連絡ください.
Twitter: @kitahara_dev
email: kitahara.main1@gmail.com
この記事が気に入ったらサポートをしてみませんか?