
【データの集め方講座】株式投資インフルエンサーのTweetを収集する-イナゴ投資-

はじめに
ごあいさつ
ご高覧いただきありがとうございます.
ソフトウェアエンジニアのKitahraです.
本日は株式投資インフルエンサーのTweetを収集してみたいと思います.
==================================================
イナゴ投資
株式投資にはイナゴ投資というものが存在します.
イナゴ投資家とは野村證券によると以下のようなものです.
短期で材料株の回転売買を繰り返す個人投資家のこと。
リアルタイムの情報を得た個人投資家が、一斉に取引に参加することで、特定銘柄の株価が急騰・急落を引き起こす。かつては、年末の資金手当てのため、秋に株式の含み益を確定する個人投資家のことを指したが、いずれも個人投資家の投資行動を、稲穂に群がるイナゴに例えた表現。
2013年1月の信用取引の規制緩和に続き、同年11月には空売りの規制緩和が実施されたことや、2014年7月に東証の主力株の値刻みが縮小されたことなどから投資家の利便性が高まり、短期で回転売買を行う投資家が増加する一因となった。
イナゴ投資家の短期売買によって作り出されたチャート形状は「イナゴタワー」と呼ばれている。
調べてみたところこの「材料」は個人投資家のTweetの投稿でもなりえるようです. 実際, Bloombergの分析にも関連を分析するツールが載せられているほどなので, 一定の効果があると推測されます.
==================================================
特定のTwitterアカウントから情報を集めたい
ここまでで特定のTwitterアカウントから情報を取得することの価値がお伝え出来たかと思います. ではどのようにすれば情報を収集することができるでしょうか?
答えはTwitter APIです.
Twitter APIを使用すると簡単に情報を収集・投稿することができます.
(投稿にはElevatedの申請をする必要があります => 詳しくはコチラ)
では追跡するTwitter アカウントはどのように集めればよいでしょうか?
これに関しては他のサイトを利用させていただきましょう.
Webスクレイピングでデータを収集することにします.
作るものの説明
今回は以下のものを作ります
webサイトから株式投資インフルエンサーの情報を取得するコード
Twitter APIを使ってcsvファイルを作成するコード
使用するものの説明
Python(3.7.12)
プログラミング言語のひとつです.
型宣言等が無く, 初心者にも扱いやすい言語だと言われています
近年Deep Learningのライブラリが豊富であることから注目を集めている人気の言語です
Selenium
Webブラウザの操作を自動で行うためのフレームワークです
もともとはWebアプリケーションのテスト等で使うことを目的に開発されましたが, 現在ではWebスクレイピング(Webサイトからデータを取得すること)を目的に利用されることも多いです
試したところ, BeautifulSoup4では今回のサイトはスクレイピングできないため必須です.
Twitter API
TwitterのAPIです.
基本無料で性能を高くするにはお金が必要な所謂Freemiumです.
私たちは無料で十分使えます.
Twitter Developerに登録する必要があります.
Google Coraboratory
Googleが提供するPythonの実行環境
主要なライブラリがインストールされている状態で使うことができる
Chromeでアクセスするだけで利用することができる
環境構築が不要です
無料で使うことができます
Visual Studio Code (任意)
Microsoftが提供するテキストエディタです
非常に人気なエディタの一つでPythonを書く人はPyCharmかVS Codeを使っている印象です
環境構築
Google Colab
!pip install selenium
!apt-get update
!apt install chromium-chromedriver
!cp /usr/lib/chromium-browser/chromedriver /usr/binSelenium (version4) を使えるようにします.
詳しくは下記のリンクをご参照ください.
Loacal
Command Line
/mnt/c/Twitter_User$python3 -m venv env
/mnt/c/Twitter_User$source env/bin/activateOSはUbuntu 20.04のものです.
virtualenvでPython3の仮想環境を立てます.
pip install pandas
pip install tweepy
pip install pytz仮想環境がたったら必要なライブラリを入れます.
==================================================
API_SETTINGS.txt
your_consumer_key
your_consumer_secret
your_access_token
your_access_token_secretTwitter_APIのデータをファイルにまとめておきます.
==================================================
ファイル構成
.
├── API_SETTINGS.txt
├── app.py
├── env
│ ├── bin
│ ├── include
│ ├── lib
│ ├── lib64 -> lib
│ ├── pyvenv.cfg
│ └── share
└── sns_account.txtapp.pyを作成して, 以上のような構成になれば完成です.
プログラムの作成
Google Colab
from selenium import webdriver
from selenium.webdriver.common.by import By
options = webdriver.ChromeOptions()
options.add_argument('--headless') # headlessモードを使用する
options.add_argument('--no-sandbox') # sandboxモードを解除する(クラッシュの回避)
options.add_argument('--disable-dev-shm-usage') # /dev/shmパーティションの使用を禁止にする(クラッシュの回避)
options.add_argument('--disable-extensions') # 拡張機能を無効にする
url = 'https://kabuline.com/twitter/'
driver = webdriver.Chrome('chromedriver', options=options) # Driverを起動
driver.get(url) # データを取得
# CSS セレクターを用いてクラスがrecipe-titlelinkのaタグを取得
# seleniumのversionが3以下だとfind_elements_by_css_selector(selector)なので注意
selector = 'span.sn'
elms = driver.find_elements(by=By.CSS_SELECTOR, value=selector)
twitter_accout = [elm.text[1:] for elm in elms]
f = open('sns_account.txt', 'w')
for account in twitter_accout:
f.write(account+'\n')
f.close()sns_account.txtを確認して, 以下のようなデータ一覧ができていれば成功です.
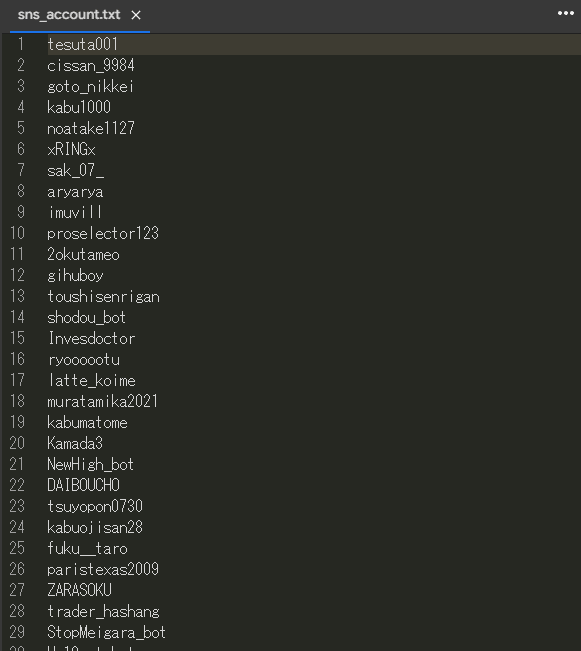
あまり難しい処理をしていないため, こちらの解説は省略します.
もし気になる方がいましたらSeleniumの単体解説の記事をご参照ください.
Local PC
import tweepy
import pytz
from datetime import datetime,timezone
import pandas as pd
def return_twitter_api_object():
# APIのセッティングを読み込む
with open("API_SETTINGS.txt", "r") as API_SETTINGS:
api_settings = API_SETTINGS.read().split('\n')
consumer_key = api_settings[0]
consumer_secret = api_settings[1]
access_token = api_settings[2]
access_token_secret = api_settings[3]
# Twitterオブジェクトの生成
auth = tweepy.OAuthHandler(consumer_key, consumer_secret)
auth.set_access_token(access_token, access_token_secret)
api = tweepy.API(auth)
return api
def change_time_JST(u_time):
#イギリスのtimezoneを設定するために再定義する
utc_time = datetime(u_time.year, u_time.month,u_time.day, \
u_time.hour,u_time.minute,u_time.second, tzinfo=timezone.utc)
#タイムゾーンを日本時刻に変換
jst_time = utc_time.astimezone(pytz.timezone("Asia/Tokyo"))
# 文字列で返す
str_time = jst_time.strftime("%Y-%m-%d_%H:%M:%S")
return str_time
def read_sns_account_txt():
f = open('sns_account.txt', 'r', encoding='UTF-8')
account_list = f.readlines()
f.close()
account_list = [account[:-1] for account in account_list]
return account_list
def get_user_timeline(user_id):
api = return_twitter_api_object()
tweets = api.user_timeline(
screen_name = user_id,
count = 5,
exclude_replies = True,
include_rts = False
)
tweet_list = []
tweet_list_append = tweet_list.append
for tweet in tweets:
print("=============================")
twitter_id = tweet.user.screen_name
name = tweet.user.name
date = change_time_JST(tweet.created_at)
text = tweet.text
print(date)
print(text)
tweet_list_append([twitter_id, name, date, text])
return tweet_list
if __name__ == '__main__':
account_list = read_sns_account_txt()
all_tweet_list = []
all_tweet_list_append = all_tweet_list.append
for account in account_list:
print(account)
user_tweet_list = get_user_timeline(account)
for i in range(len(user_tweet_list)):
all_tweet_list_append(user_tweet_list[i])
df = pd.DataFrame(all_tweet_list, columns=['user_id', 'name', 'date', 'text'])
print(df.head())
df.to_csv('result.csv')tesuta001
=============================
2022-04-04_17:01:20
予告通り今日は18時から!
参加資格はこのツイートをリツイートで🙆♂️OK
みんなで盛り上がりましょう〜🤤
#テスタクイズ
=============================
2022-04-04_15:06:28
4月4日
-2384万円🥲
今日のクイズは詳しい時間はまた書くけど18時頃になる予感です🥺
=============================
2022-04-04_10:44:59
<お知らせ>
本日から東京証券取引所はこれまでの1部、2部、ジャスダック、マザーズの区分からプライム、スタンダード、グロースという3つの市場に再編成されました。
https://t.co/sc1vLDDAut
cissan_9984
=============================
2022-04-04_11:05:58
東証のシステム変わったけど
特に儲かりそうなポイントも見出せずにおやすみモード
=============================
2022-03-16_13:08:07
おやすみモード、、、
=============================
...
user_id name date text
0 tesuta001 テスタ 2022-04-04_17:01:20 予告通り今日は18時から!\n参加資格はこのツイートをリツイートで🙆♂️OK\nみんなで盛...
1 tesuta001 テスタ 2022-04-04_15:06:28 4月4日\n-2384万円🥲\n今日のクイズは詳しい時間はまた書くけど18時頃になる予感です🥺
2 tesuta001 テスタ 2022-04-04_10:44:59 <お知らせ>\n本日から東京証券取引所はこれまでの1部、2部、ジャスダック、マザーズの区分か...
3 cissan_9984 cis@株 先物 FX 仮想通貨 リネレボ 2022-04-04_11:05:58 東証のシステム変わったけど\n特に儲かりそうなポイントも見出せずにおやすみモード
4 cissan_9984 cis@株 先物 FX 仮想通貨 リネレボ 2022-03-16_13:08:07 おやすみモード、、、コードの解説
def return_twitter_api_object():
# APIのセッティングを読み込む
with open("API_SETTINGS.txt", "r") as API_SETTINGS:
api_settings = API_SETTINGS.read().split('\n')
consumer_key = api_settings[0]
consumer_secret = api_settings[1]
access_token = api_settings[2]
access_token_secret = api_settings[3]
# Twitterオブジェクトの生成
auth = tweepy.OAuthHandler(consumer_key, consumer_secret)
auth.set_access_token(access_token, access_token_secret)
api = tweepy.API(auth)
return apiここではTwitter APIのAPIオブジェクトを作成しています.
API Keyが要求されますが, API_SETTINGS.txtに既に記述しているのでそこからロードしています.
def change_time_JST(u_time):
#イギリスのtimezoneを設定するために再定義する
utc_time = datetime(u_time.year, u_time.month,u_time.day, \
u_time.hour,u_time.minute,u_time.second, tzinfo=timezone.utc)
#タイムゾーンを日本時刻に変換
jst_time = utc_time.astimezone(pytz.timezone("Asia/Tokyo"))
# 文字列で返す
str_time = jst_time.strftime("%Y-%m-%d_%H:%M:%S")
return str_timeこの部分は以下の記事を参考にしています.
UTC(世界標準時刻)をJST(日本標準時刻)に変換するための処理です.
def read_sns_account_txt():
f = open('sns_account.txt', 'r', encoding='UTF-8')
account_list = f.readlines()
f.close()
account_list = [account[:-1] for account in account_list]
return account_listaccount[:-1]の部分は奇妙に感じるかもしれません.
これはsns_account_.txtを読み込むときにread_linesで読み込みたかったのでファイル作成時に\nをアカウント名の後に足していることが原因です. \nは読み込まれた後に文字列として判定されるので削除しています.
def get_user_timeline(user_id):
api = return_twitter_api_object()
tweets = api.user_timeline(
screen_name = user_id,
count = 5,
exclude_replies = True,
include_rts = False
)
tweet_list = []
tweet_list_append = tweet_list.append
for tweet in tweets:
print("=============================")
twitter_id = tweet.user.screen_name
name = tweet.user.name
date = change_time_JST(tweet.created_at)
text = tweet.text
print(date)
print(text)
tweet_list_append([twitter_id, name, date, text])
return tweet_list公式ドキュメントを参考に作成しました.
api.user_timelineの引数exclude_repliesとinclude_rtsをそれぞれ設定して, リプライとRTを排除するように設定しています.
引数countはなかなか厄介です.
出力の数ではなく, 排除する前のtweetの数になるようです(???)
公式の設定なので対処ができません.
APIで取得できるTweet数に制限があるので無駄にcountを上げるわけにもいかないです. なんとかしてほしいですね…
if __name__ == '__main__':
account_list = read_sns_account_txt()
all_tweet_list = []
all_tweet_list_append = all_tweet_list.append
for account in account_list:
print(account)
user_tweet_list = get_user_timeline(account)
for i in range(len(user_tweet_list)):
all_tweet_list_append(user_tweet_list[i])
df = pd.DataFrame(all_tweet_list, columns=['user_id', 'name', 'date', 'text'])
print(df.head())
df.to_csv('result.csv')tweetを取得して, csv化しています.
データを保存する前に確認したかったのでpandasを使いましたが, 必ずしもpandasである必要はないです.
おわりに
今回はPythonを使って株式投資インフルエンサーのTweetを収集するプログラムを作成しました! 参考になったという方はぜひハートボタンを押していってください!
モチベーションが上がります!
記事内で不明な点等ございましたら気軽にご連絡ください.
Twitter: @kitahara_devemail: kitahara.main1@gmail.com