
【データの使い方講座】TwitterAPI×NoteAPIで自動広告アプリ制作

はじめに
ご高覧いただきありがとうございます.
ソフトウェアエンジニアのKitaharaです.
本日は先日紹介したNoteAPIとTwitterAPIを使って自動で記事を広告してくれるアプリケーションの制作をしていきます.
完成物
実際のツイート
こんなツイートを自動で送信しています
データ分析本では浮動小数点型のデータがよく取り上げられますが, 実はデータはもっと種類があります!
— Kitahara (@kitahara_dev) February 18, 2022
Pythonで株式情報を収集しMySQLに保存|Kitahara @kitahara_dev #notehttps://t.co/5isJWC0Bav#駆け出しエンジニアと繋がりたい #株 #python
アプリのログ
今回はHerokuというサービスと使ってデプロイするのですが, ログは以下の様な感じで出力されています.
Twitterは文字制限があるので送信できないことがあります.
また, Note APIは予告なく変更される可能性があります.
そのようなときのためにログを出力することは大切です.
2022-02-18T13:00:30.854003+00:00 heroku[scheduler.4608]: Starting process with command `python main.py`
2022-02-18T13:00:31.586863+00:00 heroku[scheduler.4608]: State changed from starting to up
2022-02-18T13:00:33.668325+00:00 app[scheduler.4608]: データ分析本では浮動小数点型のデータがよく取り上げられますが, 実はデータはもっと種類があります!
2022-02-18T13:00:33.668342+00:00 app[scheduler.4608]:
2022-02-18T13:00:33.668344+00:00 app[scheduler.4608]: Pythonで株式情報を収集しMySQLに保存|Kitahara @kitahara_dev #note
2022-02-18T13:00:33.668344+00:00 app[scheduler.4608]: https://note.com/kitahara_note/n/nfa667a2d3dfa
2022-02-18T13:00:33.668344+00:00 app[scheduler.4608]: #駆け出しエンジニアと繋がりたい #株 #python意味としては
schedulerによってmain.pyを実行をはじめました
schedulerによってmain.pyを実行し状態が変化しました
main.py内のprint文による出力の表示
になります.
ちなみに最終実行状況はHeroku Schedulerでも確認できます

ディレクトリの構造
.
├── API_SETTINGS.txt
├── README.md
├── env
│ ├── bin
│ ├── include
│ ├── lib
│ ├── lib64 -> lib
│ ├── pyvenv.cfg
│ └── share
├── import_data.py
├── introduction.txt
├── main.py
├── note_data.csv
└── requirements.txt使用するもの
Note API
NoteのAPIです.
非公式のため予告なく変更が行われる可能性があります.
2022/02/19 現在では利用できています.
Twitter API
TwitterのAPIです.
基本無料で性能を高くするにはお金が必要な所謂Freemiumです.
私たちは無料で十分使えます.
Twitter Developerに登録する必要があります.
Python
プログラミング言語のひとつです.
型宣言等が無く, 初心者にも扱いやすい言語だと言われています
近年Deep Learningのライブラリが豊富であることから注目を集めている人気の言語です
Visual Studio Code (任意)
Microsoftが提供するテキストエディタです
非常に人気なエディタの一つでPythonを書く人はPyCharmかVS Codeを使っている印象です
補足情報
Note APIやTwitter APIの簡単な使い方を過去にまとめています.
必要に応じて参照してみてください.
Note API
Note APIの説明と動くコードを書く記事です.
Twitter API
この記事はR言語の記事ですが, Twitter APIで投稿するイメージをつかむには最適だと思います.
前準備
Twitter APIの取得および, Elevatedの利用申請をしましょう.
英語でのやり取りになりますが, DeepLという翻訳サイトを使えばそんなに難しくありません. 実際私は通っています.
メールは2回~3回きます. そこでは自分の興味関心のある分野やデータをどのように利用されるかが聞かれます. 丁寧に答えてください.
Elevatedアカウントを作れたらアプリを登録するわけですが, ここは適当なURLで問題ありません. (私はHerokuの別アプリにしていました)
登録が終了するとこんな画面に変化します.

アプリの仕様決定
仕様を決めておかないと思っていたものと違うものができてしまうことがあります. 簡単なBotであったとしても何を作りたいのか, どのように実装していくかをある程度まとめることを推奨します.
# Twetter Botを作る
- 仕様
- herokuによって決められた時間にPython Scriptを実行
- Python Script では以下の様にする
- Note APIを使って記事の以下のデータを収集 // import_data.py
- タイトル
- Twitter Share用のテキストデータがあったため不要
- result['tweetText']
- イメージデータのURL
- Twitter Share用のテキストデータがあったため不要
- result['twitterShareUrl']
- 投稿日
- result['publishAt]
- データを加工して以下のフォーマットに変更する // main.py
- 1行目: 幾つかパターンを設定し, それを出力するようにする
- ソフトウェアエンジニアのKitaharaといいます!データの集め方と使い方を発信中です!↓のような記事を作っています.
- Kitaharaです!本日は↓の記事を紹介します!
...
- 二行目:
- result['tweetText']
- 三行目
- result['twitterShareUrl']
- 四行目
- #駆け出しエンジニアと繋がりたい + タグ二つ
- データをTweepyを使用してTwitterに投稿する // main.py
- tweepyを使って設定アプリの制作
環境構築
Pythonでアプリケーションを作る時は仮想環境を使います.
仮想環境に切り替えることでライブラリをまっさらにした環境で開発をすることが出来ます.
Ubuntu20.04の場合以下の様にすることで作成, 有効化することが出来ます.
pip3 install virtualenv
python3 -m venv env # envという名前の仮想環境を作成する
source env/bin/activate # 仮想環境の有効化import_data.py
まずはNote APIで自分の投稿を収集するプログラムを記述します.
今回はデータの集め方講座を取得したいのでタイトルに'データの集め方'が入っているかどうかで選別します.
Note APIのコードに関してはコチラを参照してください
集めたデータはcsvファイルとして保存します.
DBを作ってもいいのですが, そこまでデータもないのでCSVファイルで十分だと思います.
import requests
import time
import pandas as pd
def search_notes(user_name):
data = []
# 0,1番目のデータは同じであるため1始まりに変更
for i in range(1,100):
url = 'https://note.com/api/v2/creators/'+user_name+'/contents?kind=note&page='+str(i)
response = requests.get(url+user_name)
# データが無くなったら実行を停止する
if response.json()['data']['contents'] == []:
print('break!: ',i)
break
time.sleep(2)
# データがあれば実行
results = response.json()
for result in results['data']['contents']:
if result['format'] == '4.0' and result['status'] == 'published':
if 'データの集め方講座' in result['name']:
hashtag_string = ''
for j in range(2):
hashtag_string = hashtag_string + ' ' + result['hashtags'][j]['hashtag']['name']
data.append([result['tweetText'], result['noteUrl'], hashtag_string])
df = pd.DataFrame(data, columns=['Tweet Text', 'URL', 'hashtag'])
df.to_csv('note_data.csv')
def main():
user_name = 'kitahara_note'
search_notes(user_name)
if __name__ == "__main__":
main()API_SETTINGS.txt
Twitter APIの設定をまとめたファイルです.
main.pyのようなファイルを増やしたときに何回も書くことになるのは面倒なので単一のファイルで管理することにしました.※
your_consumer_key
your_consumer_secret
your_access_token
your_access_token_secretIntroduction.txt
投稿内容を入れておくテキストファイルです.
これを更新すれば新しい投稿を作ることができます.
デプロイが大変そうと感じるかもしれませんが, HerokuはGitを使って管理するので文章を変えたら再度 commit & push だけで済みます.
ソフトウェアエンジニアのKitaharaといいます!データの集め方と使い方を発信中です!↓のような記事を作っています.
Kitaharaです!本日は↓の記事を紹介します!
...main.py
データを使ってTwitterに投稿をする実行ファイルです.
Heroku Schedulerで動かします.
投稿データをintroduction.txt, 記事データをnote_data.csv, API KEY等をAPI_SETTINGS.txtから取得し, まとめたあとにTwitterに投稿をしています. 工夫として毎日同じ投稿にならないようにintroduction.txtとnote_data.csvから使うデータをランダムに設定してみました.
try except文は実行が失敗する可能性があるプログラムを動かすときに使用する構文です. tryの部分に実行したいコード, exceptの部分に実行して失敗した際に行う処理を記述します.
この構文を使用する理由はTwitterに投稿する際にツイートの文字数が多すぎると投稿に失敗することがあるからです.
import random
import tweepy
import pandas as pd
def Tweet():
# 広告の文章を決定
with open("introduction.txt", "r") as tf:
introductions = tf.read().split('\n')
index_of_introduction = random.randint(0, len(introductions)-1)
introduction = introductions[index_of_introduction]
df = pd.read_csv('note_data.csv', index_col=0)
# 配信する記事を決定
index_of_article = random.randint(0, len(df)-1)
tweet_text = introduction+'\n\n'+\
df.iloc[index_of_article]['Tweet Text'][11:]+'\n'+\
df.iloc[index_of_article]['URL']+'\n'+\
'#駆け出しエンジニアと繋がりたい '+df.iloc[index_of_article]['hashtag']
# APIのセッティングを読み込む
with open("API_SETTINGS.txt", "r") as API_SETTINGS:
api_settings = API_SETTINGS.read().split('\n')
consumer_key = api_settings[0]
consumer_secret = api_settings[1]
access_token = api_settings[2]
access_token_secret = api_settings[3]
# Twitterオブジェクトの生成
auth = tweepy.OAuthHandler(consumer_key, consumer_secret)
auth.set_access_token(access_token, access_token_secret)
api = tweepy.API(auth)
# Twitterへ投稿(ツイート)
try:
api.update_status(tweet_text)
print(tweet_text)
except:
print('送信に失敗しました')
print(tweet_text)
def main():
Tweet()
if __name__ == "__main__":
main()git ignore
herokuにアップする必要のないディレクトリを入れていきます.
envは仮想環境用のファイルなのでアップロードする必要はないです.
env/デプロイ
アプリ作成が終わりましたらデプロイしていきます.
Heroku CLIをダウンロードしてください
Heroku にデプロイするためにはログインする必要があるのでログインしてみます. ログインが出来たらアプリケーションを作成してみましょう.
$heroku login
$heroku create application_nameログイン出来たらGit コマンドを使ってデプロイします
$pip freeze > requirements.txt # 必要なモジュールの書き出し
$git add .
$git commit -m 'first commit'
$git push heroku origin最後に定期実行の設定を行っていきます.
Herokuのログインした後の右上にある人型のアイコンを押すと設定画面を開くことが出来ます.

そのあとBillingの設定を行ってください
以下のコードを実行します
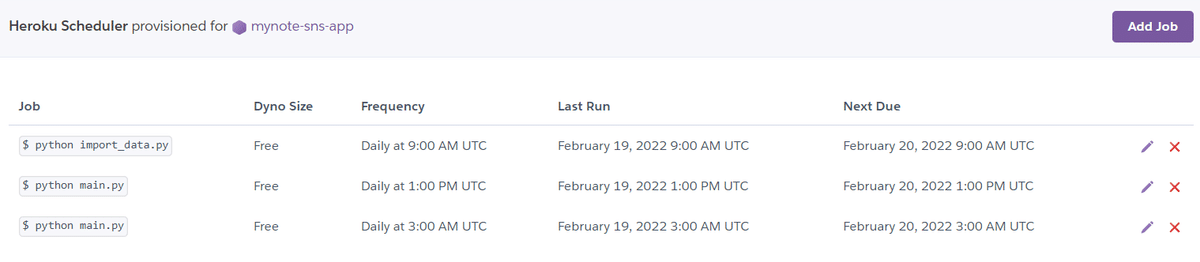
$heroku addons:add scheduler:standardこれでアプリケーションからHeroku Schedulerを使えるようになりました.
後は実行するコマンドと時間を設定すれば完成です!
Add Jobで設定をしてしまいましょう.
おわりに
今回はPythonを使ってNoteの広告をするTwitterBotを作成方法を解説しました!参考になったという方はぜひハートボタンを押してください!
モチベーションが上がります!
記事内で不明な点等ございましたら気軽にご連絡ください.
Twitter: @kitahara_dev
email: kitahara.main1@gmail.com
サムネイルをいつものものとは毛色を変えてみたのですがどうですか…?
意見等ありましたらコメント欄で書いていただけると嬉しいです!
おまけ
Twitter API のElevatedの申請に使った活動を説明するための記事です.
参考
補足
main.pyのようなファイルを増やしたときに何回も書くことになるのは面倒なので単一のファイルで管理することにしました.
プログラミングでは同じ処理を何回もするときは部品化して使うということをします
例えば, クラスや関数といったものです. 今回はファイル形式にすることで複数のプログラムから呼び出すときにテキストファイルをロードするだけで使えるようにしています.
私の例でいうと[Webエンジニアの備忘録]もツイートしたいとなった時やその他投稿やデータ収集を自動化したいとなった時に作業を効率化させることができます.