
KingJoeBot(AI チャットボット)


私の趣味として始めたこのプロジェクトは、GPT-4を使ったLINEチャットボットの開発です。当初はただの興味本位からスタートしたものの、徐々にGPT-4を含むAIの実験プラットフォームとして愛用するようになりました。
経緯
GPT-4の発見
OpenAIによるGPT-4の発表後、そのAPIを利用して何か面白いことができないかと考え始めました。
LINEを利用した理由
GPT-4の機能を探るため、簡単に使えて普及しているLINEプラットフォームを選びました。一からGUIを作るよりも、既存のプラットフォームを利用する方が合理的でした。
Google App Scriptの活用
インターネットで調べた結果、Google App Scriptを使ってLINEボットを簡単に実装できることが分かり、これを利用してプロトタイプを作成しました。
PythonとGoogle Cloud Platform
GPT-4 APIを探求する過程で、Python SDKが多くのAIサービスで提供されていることに気づきました。開発環境としてGoogle Cloud Platformを選択し、すでに持っていたアカウントを活用しました。
LINE-BOT-SDKの活用
LINE-BOT-SDKを使用することで、開発が格段に容易になり、Bard、Gemini、DeepLなどのAI APIをチャットボットに組み込むことができました。
機能
AIとの会話
LINEを介してGPT-4や他のAIと対話できます。
現在、使えるAIは以下の9つを切り替えて使用できます。
ちなみにDeepLとGoogle Cloud Visionは、会話というよりは、LINEの会話形式を利用して各AI機能を呼び出しているだけです。
$$
\text{表:使用可能なAI} \\
\begin{array}{|c|c|c|l|} \hline
No. & \text{AI} & モデル & 説明 \\ \hline
1 & \text{ChatGPT} & \text{gpt-4-turbo} & \text{Open AI}社の最新モデル(2024.5.5現在)\\ \hline
2 & \text{DeepL} & - & \text{DeepL API Free Plan}を使用してAPIを呼び出している。 \\ \hline
3 & \text{Gemini}& \text{gemini-1.5-pro-latest} & 2024年4月に公開されたモデル \\ \hline
4 & \text{Bison}& \text{chat-bison-32k} & \text{Google Cloud Vertex AI}を使ったモデル\\ \hline
5 & \text{LLama3}& \text{llama3-70b-8192} & \text{Groq}サービスで公開されているモデル\\ \hline
6 & \text{Gemma}& \text{gemma-7b-it} & \text{Groq}サービスで公開されているモデル\\ \hline
7 & \text{Mixtral}& \text{mixtral-8x7b-32768} & \text{Groq}サービスで公開されているモデル \\ \hline
8 & \text{DALL-E} & \text{dall-e-3} & \text{Open AI}社の画像生成\text{AI}の最新モデル\\ \hline
9 & \text{Claude 3} & \text{claude-3-opus-20240229} & \text{Anthropic}社の最新モデル(2024.5.5現在) \\ \hline
- & \text{Google Cloud Vision} & - & \text{Google Cloud Platform}で提供されている\text{API}サービス \\ \hline
\end{array}
$$
会話履歴
会話履歴を保持し、より自然なやり取りを実現します。
コンテキストの切り替え
複数のコンテキストを定義し、チャットボットの役割を切り替えることができます。
OCR機能
Google Visionを用いたOCR機能を搭載しています。下記の記事に書いたように、画像からテキストを抽出して他のAIに読み込ませるといった活用方法があります。
音声入出力
音声による入出力に対応しています。
マルチモーダルAI
画像に対するプロンプトを提供するためにGPT-4-VisionやGeminiなどのマルチモーダルAIを組み込んでいます。
長文プロンプト
テキストファイルをアップロードして、長文のプロンプトを実行できます。
DALL-E 3による画像生成
DALL-E 3を使用して、創造的な画像を生成します。
制限
いたずら防止
新規登録後の利用は、初期段階で50回の会話に限られます。
メールアドレス登録
メールアドレスを登録することで、会話回数の制限が緩和されます。
DALL-E 3の利用
DALL-E 3で生成する1画像は、10回の会話分としてカウントされます。(高いので)
このプロジェクトは、個人的な興味からスタートしましたが、次第にAIの実験プラットフォームとしての役割を果たすようになりました。夜な夜なアップデートしているので繋がりにくいこともあるかも。。。
OpenAI APIの実装機能
公開されているAPIのうち、実装した機能をLINEでどのように実装したのかの解説
・Text generation・・・○
・Function calling・・・×
・Embeddings・・・×
・Fine-tuning・・・○
・Image generation・・・○
・Vision・・・○
・Text-to-speech・・・○
・Speech-to-text・・・×
・Moderation・・・×
Text generation
メッセージのやりとりに使ってる。会話履歴も取得送信するので、会話が出来る。でも、単純な履歴なのでトークン数が肥大化するのが悩ましい。要約する方法があるそうだが、AI実験としては次のステップで考えよう。
contextを設定する機能も付けて、応答を変える様にできてます。
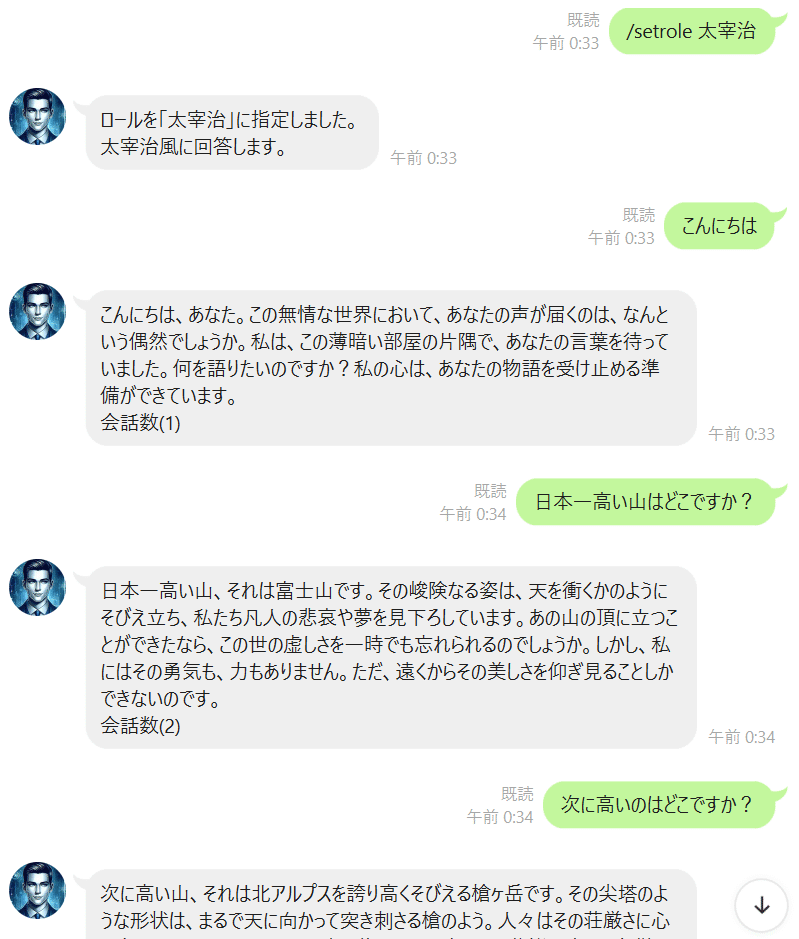
Image generation
DALL-E 3を呼び出して、テキストから画像を生成させます。入力したテキストからDALL-E3用のプロンプトをGPTに生成してもらい、そのプロンプトで画像を生成するようにしてる。(どんなプロンプトで生成されたモノなのかがわかるようにプロンプトも応答するようにした)

Vision
マルチモーダルに対応したAIでは、いったん画像や音声を送付したのちにメッセージを送信することで動作するようにした。
Text-to-speech
回答のテキストをText-to-speechを使って音声ファイルを生成してみた。

Fine-tuning
Playgroundを使って、Fine-tuningを実装してみた。とはいえ、学習データが思いつかなかったので、これを参考に作成してみた。
それなりにコストかかるのね。でも、コンテキスト量を最小にして、それっぽい回答を出すようになったから、tune出来てるんだろうけれど、必ずしも覚えさせたワードを返すという訳ではなく、”近い”、”それっぽい”回答になるというものでした。
